NIPS 2017 將於當地時間12月4日在美國長灘開幕,在此之前我們邀請了多位NIPS 2017 論文作者爲讀者做技術分享。本文是對中山大學-微軟亞洲研究院聯合培養博士吳酈軍分享視頻的回顧與論文解讀。
吳酈軍博士線上分享視頻回顧
論文:Deliberation Networks: Sequence Generation Beyond One-Pass Decoding

論文鏈接:http://papers.nips.cc/paper/6775-deliberation-networks-sequence-generation-beyond-one-pass-decoding.pdf
摘要:編碼器-解碼器框架在許多序列生成任務中都實現了非常好的性能,包括機器翻譯、自動文本摘要、對話系統和圖像描述等。這樣的框架在解碼和生成序列的過程中只採用一次(one-pass)正向傳播過程,因此缺乏推敲(deliberation)的過程:即生成的序列直接作爲最終的輸出而沒有進一步打磨的過程。然而推敲是人們在日常生活中的一種常見行爲,正如我們在閱讀新聞和寫論文/文章/書籍一樣。在該研究中,我們將推敲過程加入到了編碼器-解碼器框架中,並提出了用於序列生成的推敲網絡(Deliberation networks)。推敲網絡具有兩階段解碼器,其中第一階段解碼器用於解碼生成原始序列,第二階段解碼器通過推敲的過程打磨和潤色原始語句。由於第二階段推敲解碼器具有應該生成什麼樣的語句這一全局信息,因此它能通過從第一階段的原始語句中觀察未來的單詞而產生更好的序列。神經機器翻譯和自動文本摘要的實驗證明了我們所提出推敲網絡的有效性。在 WMT 2014 英語到法語間的翻譯任務中,我們的模型實現了 41.5 的 BLEU 分值,即當前最優的 BLEU 分值。
1 引言
基於神經網絡的編碼器-解碼器框架已經在序列生成任務上得到了廣泛的應用,其中包括神經機器翻譯[1]、文本摘要[19]、圖像描述[27]等。在這樣的框架中,編碼器將長度爲 m 的源輸入 x 編碼成一個向量序列 {h1,h2,· · · , hm}。編碼器(通常是一個 RNN)則基於來源的向量表徵和之前生成的詞來逐個詞地生成一個輸出序列。注意機制[1,35]則是在生成每個目標詞時動態地關注 x 的不同部分,該機制可被整合進編碼器-解碼器框架中,從而提升長序列的生成質量 [1]。
儘管該框架已經取得了很大的成功,但還存在一個問題:在生成詞的時候只能利用生成的詞而不是未來的尚未生成的詞。也就是說,當解碼器生成第 t 個詞 y_t 時,只使用了小於 t 的 y,而沒有明確考慮大於 t 的 y。相反,真實的人類認知過程會以一種迭代式刷新的方式利用包含過去和未來部分的全局信息。這裏給出兩個例子:(1) 思考一下當我們在閱讀一個句子時在句子中間遇到了一個不認識的詞。我們不會在此就停止閱讀。相反,我們會繼續讀完這個句子。然後我們回到這個未知詞並試圖使用其上下文(包括該詞之前和之後的詞)來理解它。(2)在書寫一份好的文檔(或段落、文章)時,我們通常首先會創建一個完整的草稿,然後再根據對整個草稿的全局理解來進行潤色。當潤色一個特定部分時,我們不會只看這部分之前的內容,而是會考慮這個草稿的全局,從而評估這裏的局部元素與全局環境的契合程度。
我們將這個潤色過程稱爲推敲(deliberation)。受人類認知行爲的啓發,我們提出了推敲網絡,該網絡通過一個推敲過程可在序列解碼過程中同時檢查前後的內容,從而可以利用全局信息。具體而言,爲了將這樣的過程整合進序列生成框架中,我們精心設計了我們的框架——它由一個編碼器 E 以及兩個解碼器 D1 和 D2 構成;其中 D1 是一個第一階段解碼器(first-pass decoder),D2 是一個第二階段/推敲解碼器(second-pass/deliberation decoder)。給定一個源輸入 x,E 和 D1 會像標準的編碼器-解碼器模型一樣聯合工作,從而生成一個粗略的序列 yˆ 作爲草稿和用於生成 yˆ 的對應的表徵
,其中T_yˆ 是 yˆ 的長度。之後,推敲解碼器 D2 以 x、yˆ 和 sˆ 爲輸入,輸出經過精細處理後的序列 y。當 D2 生成第 t 個詞 y_t 時,還有一個額外的注意模型被用於給每個 yˆ_j 和 sˆ_j 分配一個自適應權重 β_j,其中 j ∈ [T_yˆ];而且 被饋送給 D2。通過這種方式,目標序列的全局信息可以被用於生成過程中的精細處理。因爲在優化推敲網絡的過程中 yˆ 的離散性會帶來困難,所以我們提出了一種基於蒙特卡洛的算法來克服這種困難。
爲了驗證我們的模型的有效性,我們在兩個有代表性的序列生成任務上進行了研究:
(1)神經機器翻譯(NMT),即使用神經網絡來將源語言的句子翻譯到目標語言[1, 33, 32, 34]。標準的 NMT 模型由一個編碼器(用於編碼源句子)和一個解碼器(用於生成目標句子)組成,因爲可以使用我們提出的推敲網絡加以改善。在 WMT' 14 [29] 英語→法語數據集上基於廣泛應用的單層 GRU 模型[1] 上實驗結果表明:相比於沒有使用推敲的模型,使用推敲可以將 BLEU 分值[17]提升 1.7。我們還在漢語→英語翻譯上應用了我們的模型,並且在 4 種不同的測試集上平均實現了 1.26 的 BLEU 提升。此外,在 WMT' 14 英語→法語翻譯任務上,通過將推敲應用於深度 LSTM 模型,我們實現了 41.50 的 BLEU 分值,這個成績是這一任務的全新紀錄。
(2)文本摘要,即將長文章歸納爲短摘要的任務。這個任務可以使用編碼器-解碼器框架,因此也可以使用推敲網絡來精細處理。在 Gigaword 數據集 [6] 上的實驗結果表明推敲網絡可以將 ROUGE-1、ROUGE-2 和 ROUGE-L 分別提升 3.45、1.70 和 3.02。
2 框架
在這一節,我們首先會介紹推敲網絡的整體架構,然後再介紹各個組分的詳細情況,最後還會提出一種用於訓練推敲網絡的端到端的基於蒙特卡洛的算法。
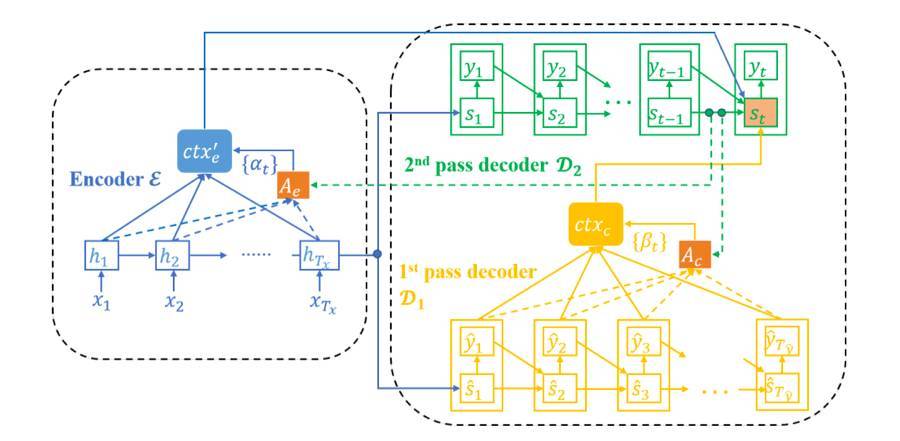
圖 1:推敲網絡的框架:藍色、黃色和綠色部分分別表示編碼器 E、第一階段解碼器 D1 和第二階段解碼器 D2。爲了可讀性,這裏省略了 E 到 D1 的注意模型。

算法 1:用於訓練推敲網絡的算法
3 將推敲網絡應用於神經機器翻譯
我們使用兩種不同的網絡結構評估了推敲網絡:(1)淺模型,基於名爲 RNNSearch [1,12] 的有廣泛應用的單層 GRU 模型;(2)深度模型,基於類似於 GNMT [31] 的深度 LSTM 模型。這兩類模型都是在 Theano [24] 中實現的。

表 1:英語→法語翻譯的 BLEU 分值

表 2:漢語→英語翻譯的 BLEU 分值

表 3:漢語→英語翻譯的案例研究。注意第二個例子中的「……」表示一個常見句子「(the two sides will discuss how to improve the implementation of thecease-fire agreement)雙方將討論如何改進落實停火協議」。

表 4:推敲網絡與不同的深度 NMT 系統(英語→法語)之間的比較
4 將推敲網絡應用於文本摘要
我們進一步驗證了推敲網絡在文本摘要上的有效性,這是編碼器-解碼器框架得到了成功應用的另一種真實應用 [19]。
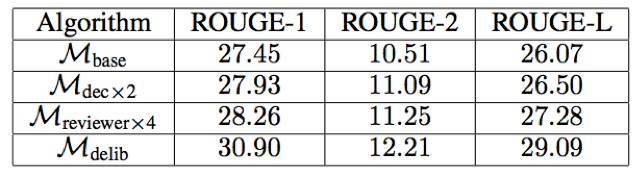
表 5:文本摘要的 ROUGE-{1, 2, L} 分值
5 結論和未來工作
在這項研究中,我們提出了用於序列生成任務的推敲網絡,其中會使用一個第一階段解碼器來生成一個原始序列,然後再使用一個第二階段解碼器來潤色這個原始序列。實驗表明我們的方法在機器翻譯和文本摘要任務上可以實現比幾種基準方法遠遠更優的結果,而且我們的方法還在 WMT' 14 英語→法語翻譯任務上實現了新的單個模型的當前最佳結果。
未來還有多個可以探索的有潛力的研究方向。首先,我們將研究如何將推敲的思想應用於序列生成之外的任務,比如改善 GAN [5] 生成的圖像的質量。其次,我們將研究如何細化/潤色不同層級的神經網絡,比如 RNN 中的隱藏狀態或 CNN 中特徵圖。第三,我們還很好奇如果解碼器有更多階段(即多次打磨潤色生成的序列),生成的序列是否還會更好。第四,我們還將研究如何加速推敲網絡的推理以及縮短它們的推理時間。