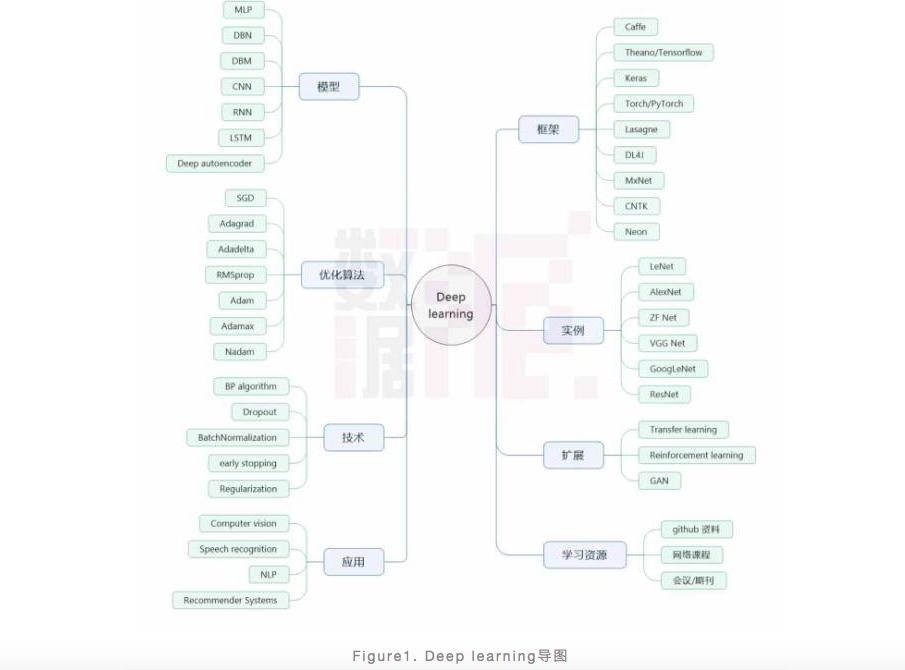
深度學習(deep learning)的概念最早可以追溯到1940-1960年間的控制論(cybernetics),之後在1980-1990年間發展為連接主義(connectionism),第三次發展浪潮便是2006年由人工神經網絡(Artificial neural network)擴展開來並發展成為今天十分火熱的深度學習(Figure2)。實際上,深度學習的興起和發展是非常自然的,人們在應用經典的機器學習方法時,需要對具體的問題或者數據相當地了解並從中人工地提取特徵才能很好的解決問題,然而人工提取特徵是非常複雜耗時的。因此,能夠自動從數據中學習特徵的方法就具有非常大的發展潛力,這類方法也就是一類被稱為表征學習(Representation learning)的方法。
緊接著,研究者們發現,深層次的表征學習模型可以從簡單的特徵中抽象出更為複雜的特徵並且更有利於最終的分類判別,由此便發展出了深度學習框架。當然,深度學習的發展也離不開BP等算法、計算硬體、數據規模等的發展。深度學習可以理解成是機器學習的一種框架,與經典的淺層學習(Shallowlearning)如SVM,LR等相對應,可以認為是機器學習發展的第二大階段。目前,深度學習在人工智慧領域發揮著非常重要的作用,甚至可以說人工智慧的發展正是得益於深度學習的發展,由於它們之間有著密不可分的關係,非專業人士常常會將深度學習、人工智慧、表示學習、機器學習等概念混為一談。
另外,最近幾年,由於人工智慧、網際網路等火速發展,它們背後的技術也備受學術界和業界人員的推崇,其中深度學習由於其強大的威力以及較低的門檻而受到最多的關注。本文致力於從模型、技術、優化方法、常用框架平台、應用、實例等多個方面來向讀者介紹深度學習,闡述深度學習到底有哪些威力,並且文末會給讀者推薦一些深度學習的學習資源。
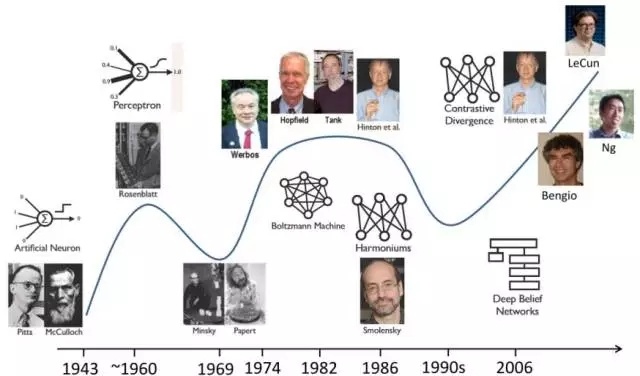
Figure 2. Neural network發展歷程
深度學習是什麼?
如前言所述,深度學習是機器學習的一種框架,是人工智慧的基礎技術之一,其與人工智慧、表示學習以及機器學習的關係由Figure 3可見,即機器學習是實現人工智慧的一種方法,而表示學習又是一種機器學習的框架,深度學習包含在表示學習中。
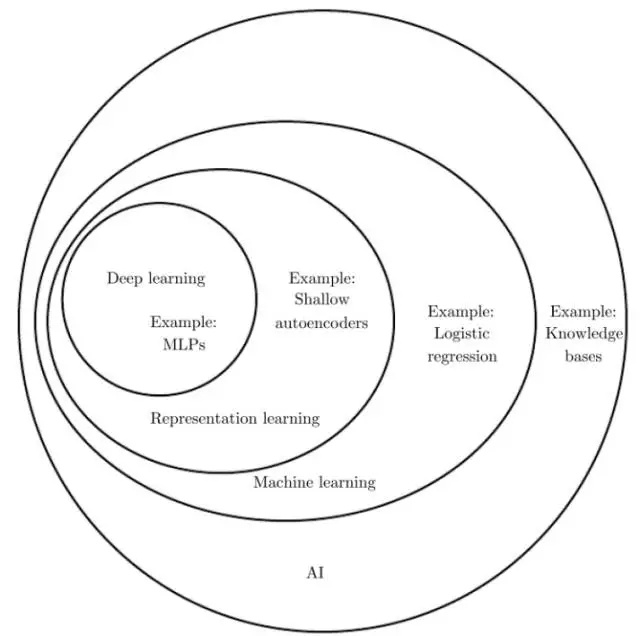
Figure 3. Deep learning定位(圖片來源:Ian Goodfellow et al. Deep learning.)
深度學習模型可以自動從輸入數據中學習特徵並用於訓練,模型的淺層結構提取簡單的特徵,深層結構則基於淺層結構獲取的特徵提取更為抽象的特徵,這是深度學習區別於傳統機器學習以及普通表征學習模型的學習方式。Figure 4展示了不同機器學習方法的學習方式。
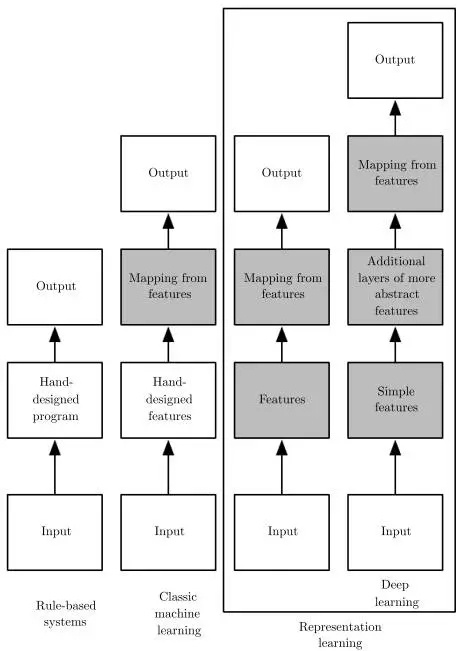
Figure 4. Deep learning特徵學習過程(圖片來源:Ian Goodfellow et al. Deep learning.)
那麼,深度學習的深度到底體現在什麼方面呢?對於這個問題,目前主要有兩種觀點:第一種觀點認為,深度學習的深度是由於計算圖的長度決定的,也就是模型將輸入映射到輸出的過程中,計算的路徑長度。對於該觀點,如何定義計算單元至關重要,而目前又沒有統一的關於計算單元的定義;第二種觀點則認為深度學習的深度是由描述輸入到輸出之間概念關係圖的深度決定的,也就是所定義模型的結構深度,然而這種結構上的深度往往與計算的深度不一致。以上兩種觀點提供了兩種理解深度學習的角度,我們既可以將其理解為模型結構的深度也可以理解為計算的深度,筆者認為這對於理解深度學習的本質並無影響。
常見模型
前面多次提到深度學習是一種機器學習框架,那麼該框架下的具體的模型有哪些呢?下面為大家介紹幾種常見的深度學習模型。
MLP:
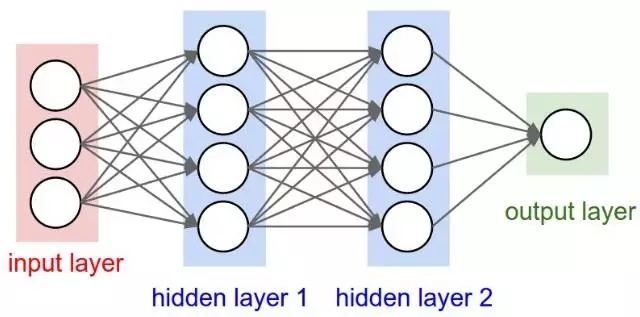
MLP (Multilayer perceptron)是一個典型的深度學習模型,也叫前向深度網絡(Feedforward deep network),主要由多層神經元構成的神經網絡組成(Figure5),包括輸入層、中間層和輸出層,層與層之間是全連接的,除了輸入層,其他層每個神經元包含一個激活函數,因此,MLP可以看成是一個將輸入映射到輸出的函數,這個函數包括多層乘積運算和激活運算。MLP通過前向傳播計算最終的損失函數值,再通過反向傳播算法(BP)計算梯度,利用梯度下降來對模型參數進行優化。MLP的出現解決了感知器無法學習XOR函數的問題,使得人們對神經網絡重拾信心。
DBN與DBM:
DBN(Deep belief network)也是一種比較經典的較早提出的深度學習模型。DBN是基於RBM(Restricted BoltzmannMachine)模型建立的,更具體地,DBN模型可以看成是由多個RBM結構和一個BP層組成的,其訓練過程也是從前到後逐步訓練每一個RBM結構,使得每一個RBM的隱層達到最優,從而最優化整體網絡。值得注意的是,在DBN的結構中,只有最後兩層之間是無向連接的,其餘層之間均具有方向性,這是DBN區別與後面DBM的一個重要特徵。
DBM(Deep Boltzmann machine)模型也是一種基於RBM的深度模型,其與RBM的區別就在於它有多個隱層(RBM只有一個隱層)。DBM的訓練方式也是將整個網絡結構看成多個RBM,然後從前到後逐個訓練每個RBM,從而優化整體模型。在DBM模型中,所有相鄰層之間的連接是無向的。DBN與DBM模型中層間節點之間均無連接,且節點之間相互獨立。
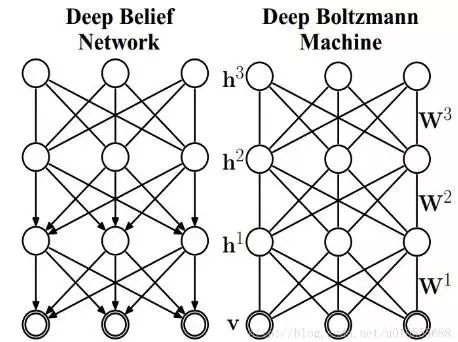
Figure 6. DBN與DBM模型示意圖(Hinton et al. 2006)
CNN:
CNN(convolutional neural network)是一種前向人工神經網絡模型,由Yann LeCun等人在1998年正式提出,其典型的網絡結構包括卷積層、池化層和全連接層。下圖(Figure7)所示就是一種典型的CNN結構(LeNet-5),給定一張圖片(一個訓練樣本)作為輸入,通過多個卷積算子分別依次掃描輸入圖片,掃描結果經過激活函數激活得到特徵圖,然後再利用池化算子對特徵圖進行下採樣,輸出結果作為下一層的輸入,經過所有的卷積和池化層之後,再利用全連接的神經網絡進行進一步的運算,最終結果經輸出層輸出。
CNN模型強調的是中間的卷積過程,該過程通過權值共享大幅度降低了模型的參數數量,使得模型在不失威力條件下可以更為高效地得到訓練。CNN模型是非常靈活的,其結構可以在合理的條件下任意設計,比如可以在多個卷積層之後加上池化層,正是由於這種靈活性,CNN被廣泛地應用在各種任務中並且效果非常顯著,比如後面將要介紹的AlexNet、GoogLeNet、VGGNet以及ResNet等。
當然,這種靈活性使得CNN的結構本身也成為了一種超參,這就難以保證針對特定任務所採用的模型是否是最優模型。在現實的應用中,CNN更多的用於處理一些網格數據,例如圖片,對於這類數據CNN的卷積過程能發揮的作用相對更大。當然,CNN是可以完成多種類型的任務的,包括圖片識別、自然語言處理、視頻分析、藥物挖掘以及遊戲等。
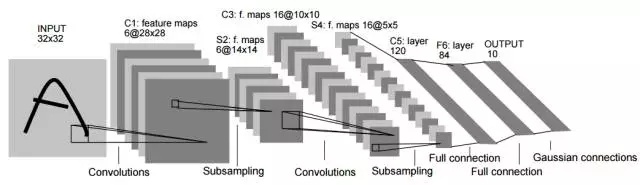
Figure 7. CNN典型結構及運算過程(Yann LeCun et al. 1998)
RNN:
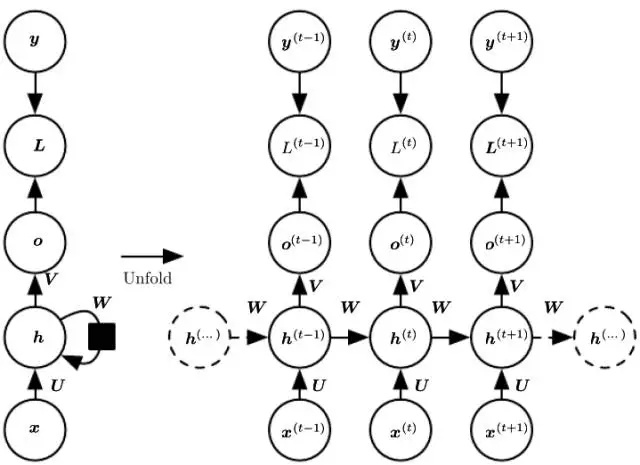
RNN(Recurrent neuralnetwork)是一類用於處理序列數據的神經網絡模型。典型的RNN模型通常是由三類神經元組成,分別是輸入、隱藏和輸出,其中輸入單元只與隱藏單元相連,隱藏單元則與輸出、上一個隱藏單元以及下一個隱藏單元相連,輸出單元只接受隱藏單元的輸入。在RNN訓練過程中,一般需要學習優化三種類參數,即輸入映射到隱層的權重、隱層單元之間轉換權重以及隱層映射到輸出的權重。
如圖(Figure8)是典型的RNN結構以及計算過程。在RNN的計算過程中,序列數據前面部分的信息通過隱藏單元傳遞到後面的部分,因此在後面部分的計算過程中,前面部分的信息也考慮進來,這就模擬了序列不同部分之間的依賴關係。顯然,RNN模型更適用於序列性的數據,尤其是上下文相關的序列,這使得RNN在情感分析、圖像標註、機器翻譯等方面應用十分廣泛。值得注意的是在不同的任務中,RNN的結構有所差異,比如在圖像標註的場景中RNN是一對多的結構,而在情感分析的場景中則是多對一的結構(Figure9)。
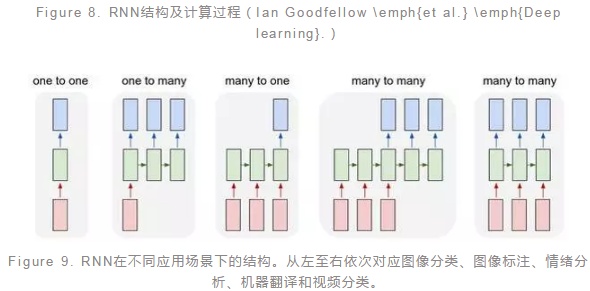
LSTM:
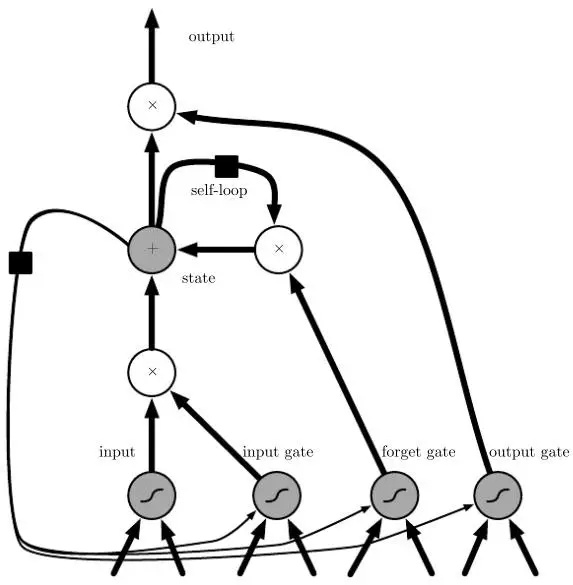
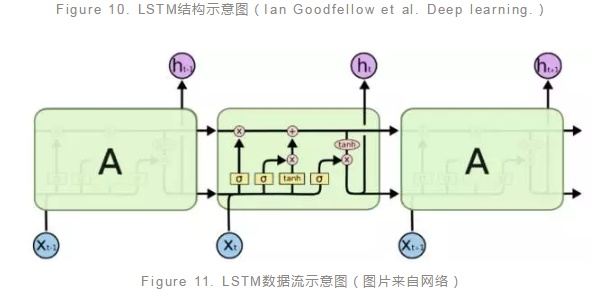
LSTM(Long short-term memory)模型本質上也是一種RNN模型,它與RNN的區別在於它引入了元胞狀態(Cell state)的概念,並且可以通過門(gate)來向元胞狀態加入或者刪除信息,另外,LSTM還可以通過門構成封閉的迴路(Figure 10),這使得LSTM得以克服RNN無法有效記憶長程信息的弱點。如圖(Figure10)是一種常見的LSTM單元,其中包含輸入、輸入門、遺忘門、狀態、輸出門、輸出等組成單元。
在LSTM模型中所謂的門其實就是一個函數運算,例如輸入門可以是所有輸入經過權重乘積運算之後的sigmoid函數運算。對於一個序列型數據樣本,當前輸入節點會綜合上一個節點的隱層輸出信息,分別通過多個不同門運算之後輸出作為當前節點的隱層輸出信息,並且同時與上一個節點的元胞狀態信息進行綜合輸出作為當前節點的元胞狀態信息輸出(Figure 11)。LSTM既然是一種特殊的RNN模型,那麼很多可以應用RNN的場景LSTM也適用,例如情感分析、圖像標註等等。當然,LSTM也具有非常多的變種,它們在不同的任務中表現不同,這也需要應用的時候有一些了解。
Autoencoder是一種神經網絡,其輸入層與輸出層表示相同的含義並且具有相同數量的神經元。Autoencoder的學習過程就是將輸入編碼然後再解碼重構輸入作為輸出的過程,將輸入編碼生成的中間表示的作用類似於對輸入進行降維,因此autoencoder常常用於特徵提取、去噪等。
普通的autoencoder一般是指中間只有一層隱層的網絡模型,而deep autoencoder則是中間有多層隱層的網絡模型。Deep autoencoder的訓練與DBM訓練類似,每兩層之間利用RBM進行預訓練,最終通過BP來調整參數。同樣地,deep autoencoder也有非常多的變種(例如sparse autoencoder,denoiseautoencoder等),分別對應於不同的任務。
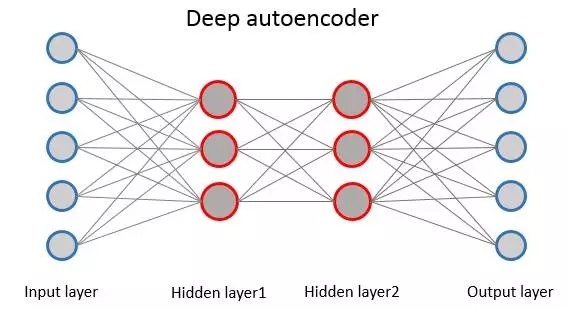
Figure 12. Deep autoencoder結構示意圖
深度網絡的優化方法
前面例舉了一些深度學習比較常見的一些模型,那麼這些模型都是如何進行優化的呢?本節將介紹一些比較常用的深度網絡優化的方法。
SGD:
SGD(Stochastic Gradient Descent)即隨機梯度下降算法,是機器學習中最常用的優化方法之一。SGD的工作原理就是梯度下降,也就是以一定的步長(learning rate)沿著參數梯度的方向調整參數,只不過在SGD中是對隨機抽取的一個樣本通過梯度下降更新一次參數。在實際應用SGD的時候有多個參數可以調節,主要包括學習率、權值衰減(weightdecay)係數、動量以及學習率衰減係數,通過調整這幾個參數,可以使得模型以較快的速率收斂且不易過擬合。SGD參數更新過程如下:




Adamax:
Adamax是Adam的一種變體,它在學習率的限制上做了一些改動,即利用累積梯度和前一次梯度中的最大值來對學習率進行歸一化。這樣的限制在計算上相對簡單。
Nadam:
Nadam也是Adam的一種變體,它的變動在於它帶有Nesterov動量項。一般來說,Nadam的效果會比RMSprop和Adam要好,但是在計算上比較複雜。
深度網絡中常用的技術
在實際的應用中,深度學習模型在數據量不是足夠大的條件下是非常容易過擬合的,因此需要通過一些技術和技巧來控制訓練過程,減弱甚至防止嚴重的過擬合現象。那麼,有哪些類似的常用的技術呢?接下來我們就介紹一些比較有用的進一步優化模型訓練的技術。
BP algorithm:
BP(Backpropagation)算法其實只是一種訓練神經網絡模型的方法,主要是通過鏈式求導法則對目標函數求關於參數的導數,求導的過程從輸出層一直反向傳遞至輸出層,根據求出的導數利用前一節介紹的優化算法對參數進行更新,從而優化模型。在應用BP算法優化模型的過程中,常常會出現梯度消失、陷入局部最優以及梯度不穩定等問題,這些問題會導致模型收斂緩慢、泛化能力降低等後果。當然,這些問題的出現也與模型中選擇的激活函數有一定的關係,因此合理選擇激活函數會一定程度上弱化以上問題。目前,應用比較多的激活函數主要有sigmoid、tanh、ReLu、PReLu、RReLU、ELU、softmax等等,根據具體的問題選擇激活函數有利於BP算法的高效執行。
Dropout:
前面提到深度學習模型是非常容易過擬合的,主要的原因在於深度學習模型是非常複雜的,具有大量的參數,在樣本量不是足夠多的情況下是很難保證模型的泛化能力的。因此,一種防止過擬合的方法dropout被提出,dropout的主要思想是在訓練的過程中隨機使一些神經元失活來降低模型的複雜度,當然這個過程是並不影響BP的執行。Dropout的具體執行過程如圖(Figure13)所示,通過比較相同的網絡在使用dropout前後的分類效果,發現在MNIST、CIFAR-10、CIFAR-100、ImageNet、TIMIT等數據集上使用dropout的預測效果更好。
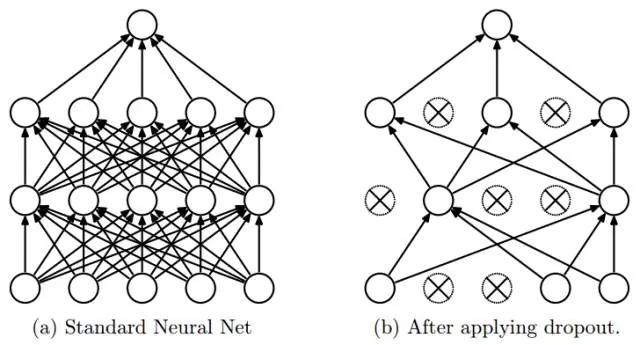
Figure 13. Dropout過程示意圖(Nitish Srivastava et al. 2014)
Batch Normalization:
深度學習網絡在訓練的過程中有一個很大問題是數據流經每層時分布會隨著參數的變化而發生變化,也就是常說的內部協變量漂移現象(internal covariate shif),這種現象會導致模型的訓練非常緩慢,並且對參數的初始化有較高的要求。BatchNormalization的出現則很大程度上解決了這一問題,其作用的原理是直接在每層的輸入上加上一層歸一化層,先對輸入進行歸一化再傳遞至激活函數。經過Batch Normalization處理之後,就可以使用較大的學習率從而加快訓練速度,並且降低初始化的要求。加入Batch Normalization來訓練深度網絡的過程如圖(Figure 14)。Sergey Ioffe etal.通過實驗發現加入Batch Normalization的網絡在ImageNet數據集上表現更好。

Figure 14. 加入Batch Normalization的網絡的訓練過程(Sergey Ioffe et al. 2015)
Early stopping:
Early stopping也是一項在實際應用深度學習模型時防止過擬合的技術,該技術主要通過控制訓練的輪數(epoch)來防止過擬合,也就是在validation loss不再持續下降時自動停止訓練。實際上,early stopping可以應用在很多機器學習問題上,例如非參回歸、boosting等。另外,early stopping也可以看成是一種正則化的形式。
Regularization:
這裡所說的regularization是指狹義上像L1、L2等對控制權重的正則化,不包括前面提及的Dropout和early stopping等。對網絡的權重參數加上L1或L2正則項也是一種比較常用的防止過擬合的手段,L1/L2正則化的方法在機器學習中應用非常廣泛,這裡也不再贅述。
深度學習常見的實現平台和框架
深度學習模型由於其複雜性對機器硬體以及平台均有一定的要求,一個好的應用平台可以使得模型的訓練事半功倍。那麼,針對深度學習有哪些比較流行好用的平台和框架呢?下面就向大家介紹一些比較常用的深度學習平台以及它們的優缺點。
Caffe:
Caffe是由美國加州伯克利分校視覺與學習中心在2013年開發並維護的機器學習庫,它對卷積神經網絡具有非常好的實現(http://caffe.berkeleyvision.org )。Caffe是基於C/C++開發的,所以模型計算的速度相對較快,但是Caffe不太適合文本、序列型的數據的處理,也就是在RNN的應用方面有很大的限制,其優缺點可以簡單的總結如下:
優點:適合圖像處理;版本穩定,計算速度較快
缺點:不適合RNN應用;不可擴展;不便於在大型網絡中使用;C/C++編程難度較大,不夠簡潔;幾乎不再更新
Theano/Tensorflow:
Theano和Tensorflow都是比較底層的機器學習庫,並且都是一種符號計算框架,它們都適用於基於卷積神經網絡、循環神經網絡以及貝葉斯網絡的應用,它們都提供Python接口,Tensorflow還提供C++接口。Theano是在2008年由蒙特婁理工學院LISA實驗室開發並維護的(http://deeplearning.net/software/theano/),非常適合數值計算優化,並且支持自動計算函數梯度,但它不支持多GPU的應用。Tensorflow是由Google Brain團隊開發的,目前已經開源,由Google Brain團隊以及眾多使用者們共同維護(https://www.tensorflow.org )。
Tensorflow通過預先定義好的數據流圖,對張量(tensor)進行數值計算,使得神經網絡模型的設計變得非常容易。與Theano相比,Tensorflow支持分布式計算和多GPU的應用。就目前來看,Tensorflow是在深度學習模型的實現上應用最為廣泛的庫。
Keras:
Keras是一個基於Theano和Tensorflow的,高度封裝的深度學習庫(https://keras.io/ )。它是由是由谷歌軟體工程師FrancoisChollet開發的,在開源之後由使用者共同維護。Keras具有非常直觀的API,使用起來非常的簡潔,一般只需要幾行代碼便可以構建出一個神經網絡模型。目前,Keras已經發布2.0版本,支持使用者從底層自定義網絡層,這很大程度上彌補了之前版本在靈活性上不夠的缺陷。
Torch/PyTorch:
Torch是基於Lua語言開發的一個計算框架(http://torch.ch/ ),可以非常好的支持卷積神經網絡。在Torch中網絡的定義是以圖層的方式進行的,這導致它不支持新類型圖層的擴展,但是新圖層的定義相對比較容易。Torch運行在LuaJIT上,速度比較快,但是目前Lua並不是主流程式語言。另外,值得注意的是Facebook在2017年1月公布了Torch 的PythonAPI,即PyTorch的原始碼。PyTorch支持動態計算圖,方便用戶對變長的輸入輸出進行處理,另外,基於python的庫將大幅度增加Torch的集成靈活性。
Lasagne:
Lasagne是一個基於Theano計算框架(http://lasagne.readthedocs.io/en/latest/index.html ),它的封裝程度不及Keras,但它提供小的接口,這也使得代碼與底層的Theano/Tensorflow比較為簡潔。Lasagne這種半封裝的特性,平衡了使用上的便捷性和自定義的靈活性。
DL4J:
DL4J(Deeplearning4j)是一個基於Java的深度學習庫(https://deeplearning4j.org/)。它是由Skymind公司在2014年發布並開源的,其包含的深度學習庫是商業級應用的開源庫,由於是基於Java的,所以可以與大數據處理平台Hadoop、Spark等集成使用。DL4J依靠ND4J進行基礎的線性代數運算,計算速度較快,同時它可以自動化並行,因此十分適合快速解決實際問題。
MxNet:
MxNet是一個由多種語言開發並且提供多種語言接口的深度學習庫(http://mxnet.io/ )。MxNet支持的語言包括Python,R,C++,Julia,Matlab等,提供C++, Python, Julia, Matlab, JavaScript,R等接口。MxNet是一個快速靈活的學習庫,由華盛頓大學的PedroDomingos及其研究團隊開發和維護。目前,MxNet已被亞馬遜雲服務所採用。
CNTK:
CNTK是微軟的開源深度學習框架(http://cntk.ai ),是基於C++開發的,但是提供Python接口。CNTK的特點是部署簡單,計算速度比較快,但是它不支持ARM架構。CNTK的學習庫包括前饋DNN、卷積神經網絡和循環神經網絡。
Neon:
Neon是Nervana公司開發的一個基於Python的深度學習庫(http://neon.nervanasys.com/docs/latest/ )。該學習庫支持卷積神經網絡、循環神經網絡、LSTM以及Autoencoder等應用,目前也是開源狀態。有報導稱在某些測試中,Neon的表現要優於Caffe、Torch和Tensorflow。
深度學習網絡實例
通過前面的介紹,讀者對於深度學習已經有了比較詳細的了解,那麼實際應用中深度學習網絡究竟是怎麼樣設計的呢?本節我們向大家介紹幾種應用效果非常好的深度學習網絡,從中我們可以體會到神經網絡設計的一些技巧。
LeNet:
LeNet是由Yann LeCun等最早提出的一種卷積神經網絡,我們在介紹CNN的時候已經提到過該網絡(Figure 7)。LeNet網絡總共有7層(不包括輸入層),分別是C1、S2、C3、S4、C5、F6以及OUTPUT層,其中C1、C3為卷積層,S2、S4為下採樣層,C5、F6為全連接層。該網絡的輸入時32 X 32的圖片,C1包含6個特徵圖(featuremaps),C3包含16個特徵圖,兩個全連接層的神經元數量分別是120和84,最終的輸出層含有10個神經元,對應十個類別。這個網絡在訓練過程中總共需要優化大約12000個參數,在手寫數字識別(MNIST數據集)的任務上效果遠優於傳統的機器學習方法。這一網絡的提出提供了一個卷積神經網絡應用的範例,也就是將卷積層與採樣層(後來的池化層)交替連接,最後在展開連接全連接層。實踐證明在很多任務中這一網絡結構具有較好的表現。
AlexNet:
AlexNet是Alex和Hinton參加ILSVRC2012比賽時所使用的卷積神經網絡,該網絡可以說是更深層次的CNN在大數據集上應用的開山之作,隨後諸多應用均是在此網絡的基礎上發展而來。AlexNet由5個卷積層和3個全連接層組成,其中第1,2,5卷積層後加入了池化過程(Figure15),各層神經元的數目分別是253440、186624、64896、64896、43264、4096、4096和1000,總計涉及的參數達到6千萬。該網絡的訓練集是來自ImageNet的140萬包含1000個類別的高解析度圖片,其中有5萬作為驗證集,15萬作為測試集。在訓練該網絡的過程中,採用ReLu作為激活函數,並且對圖片數據通過水平翻轉等方法進行了擴增,為了防止過擬合,該網絡中還使用了dropout技術,網絡的優化採用了批量梯度下降並加入了動量和權值衰減。整個訓練過程在兩個GTX580的GPU上持續了5-6天。最終的結果是該網絡在ILSVRC2012比賽中取得了最好的成績,並且遠遠由於其他方法。
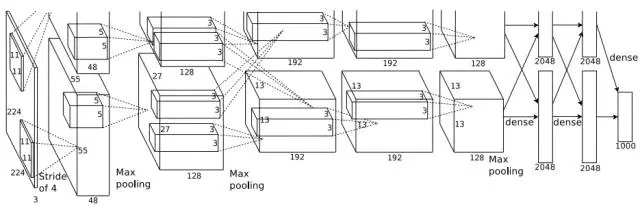
Figure 15. AlexNet的網絡結構(Alex Krizhevsky et al. 2012)
ZF Net:
ZF Net是在ILSVRC2013比賽中由Zeiler和Fergus根據AlexNet提出的網絡。實際上,該網絡只是對AlexNet做了一些修改和調整,因此二者之間的網絡結構差別不大(Figure 16)。主要的改動體現在ZF Net中第一個卷積層使用了較小的卷積核並且將卷積步幅減少為原來的一半,這種改動保留了前兩層中更多的圖片特徵信息。ZFNet最後的表現勝於AlexNet,在錯誤率上下降了1.7個百分點。另外,通過ZF Net作者們提出了一種可視化卷積層特徵的方法。
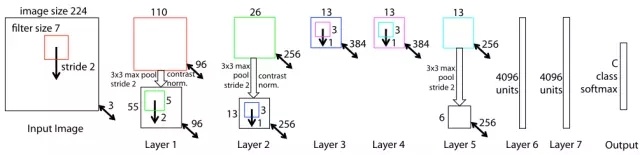
Figure 16. ZF Net的網絡結構(Matthew D. Zeiler et al. 2013)
VGG Net:
VGG Net是ILSVRC2014比賽中表現非常突出的卷積神經網絡模型,其特點就是小卷積核,更深的卷積層次。該網絡總共有19層,16個卷積層,3個卷積層,所有卷積核的大小均為3,多個卷積層疊加再插入池化層(Figure 17; E)。相比於ZF Net,該網絡分類錯誤率下降了9%,分類效果顯著提升。VGGNet的出現具有重要意義,它為人們提供了一個高效設計和利用CNN的方向,即層次更簡單更深更有利於深層次特徵的挖掘。
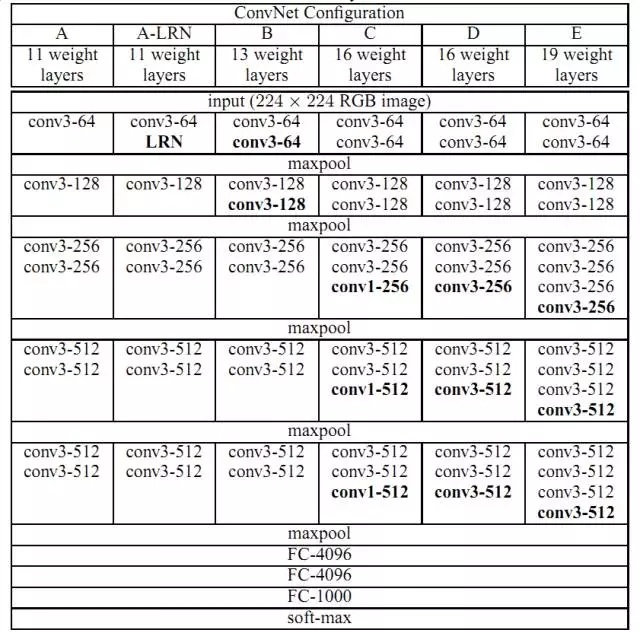
Figure 17. VGG Net的網絡結構(Karen Simonyan et al. 2014)
GooLeNet:
GooLeNet也是ILSVRC2014比賽中出現的卷積神經網絡模型,該模型在此次比賽取得最佳成績。GooLeNet的層次比VGG Net更深,總共有22層,其中21個卷積層,1個softmax輸出層(Figure 18)。值得注意的是,該網絡中應用了多個(9個)Inception(network innetwork)模塊,也就是該網絡並非是層與層之間按順序依次疊加的,而是有很多並聯的連接,並且模型的最後也沒有應用全連接層。Inception模塊的使用使得更多的特徵信息被收集,去掉了全連接層減少了大量的參數,一定程度上降低了過擬合的可能。GooLeNet最終的分類結果相比於VGGNet提高了0.6%。GooLeNet的意義在於它提供了一種新的層間並聯連接方式,這對以後CNN網絡結構的設計具有非常大的啟發作用。
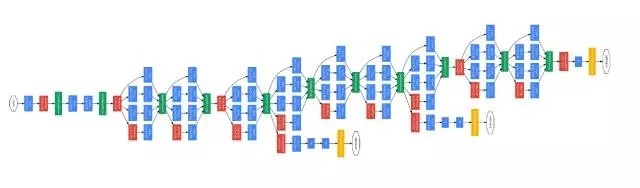
Figure 18. GooLeNet的網絡拓撲結構(Christian Szegedy et al. 2015)
ResNet:
ResNet是ILSVRC2015比賽中的冠軍模型,是由微軟亞洲研究院的研究人員提出的,該網絡深達152層,151個卷積層,1個softmax輸出層,每隔兩層加入殘差(Figure 19)。該網絡模型將分類錯誤率降低至3.6%,其意義在於提出了一種新的網絡結構,即殘差神經網絡。殘差神經網絡的提出一定程度上解決了深度網絡無法訓練的問題,為將來的應用提供非常好的改進方向。

深度學習的應用
計算機視覺:
計算機視覺是深度學習應用最為火熱的領域之一,前面例舉的幾個網絡結構都是應用在計算機視覺領域的圖片分類問題上的,解決這類問題一般都會選擇CNN模型。然而,對於計算機視覺領域有很多其他方面的問題,單純應用CNN模型效果往往並不佳,例如圖像標註、圖像生成等問題,還需要進一步設計針對特定類型問題的模型。
目前,計算機視覺領域前沿研究最為火熱的問題主要有:
圖像分類,將不同類型的圖像分開,類似於ILSVRC比賽的任務;
圖像檢測,把圖像中不同的物體用框框出來;
圖像分割,把圖像中不同的物體邊界描繪出來;
圖像標註,也就是看圖說話,把對應的圖像用文字描述出來;
圖像生成,就是根據文字描述生成圖像;
視頻預測,推測下時間圖像中物體將會如何移動。
語音識別:
語音識別的目的就是將聲音信息轉化成文字,這一任務是人機互動的基礎。對於這一任務,傳統的解決方法一般是依賴序列模型來對語音序列建模,例如隱馬爾可夫模型、高斯混合模型等,這些傳統的方法單詞識別的錯誤率較高。語音識別的過程一般涉及語音特徵提取和聲學建模兩個方面,研究者發現利用CNN來提取語音特徵可以大幅降低(6%-10%)單詞識別錯誤率(Ossama Abdel-Hamid et al.2014),而利用CNN進行聲學建模同樣具有更強的適應能力。隨後,研究者們發現更深的卷積神經網絡具有更好的表現,同時在解碼搜索階段將CNN、RNN以及LSTM聯合起來使用會進一步提高語音識別的準確率。目前,IBM沃森研究中心報導稱將ResNet與多個LSTM結合起來會使得語音識別的單詞錯誤率降低至5.5%。實際上,蘋果公司的Siri、微軟的Cortana以及科大訊飛的語音識別技術都採用了最新的技術。
自然語言處理:
自然語言處理涵蓋多種具體的應用,主要包括:
詞性標註,給定句子文本,標註出句子每個詞的詞性;
句法分析,分析句子文本的語法;
文本分類,把內容想接近或者主題相關的文本歸為相同的類別;
自動問答,人機互動的一種,人提供問題,機器反饋答案;
機器翻譯,不同語言之間相互轉譯;
自動摘要,給定一個文檔,自動生成該文章的內容梗概,即摘要。
目前,深度學習網絡已經被廣泛應用在以上任務中,早在2014年Nal Kalchbrenner等人用一種動態卷積神經網絡來對語句建模(Nal Kalchbrenner et al. 2014),Baotian Hu等人利用CNN來處理語義匹配的問題,ChenxiZhu等人則利用雙向LSTM模型來解決文本匹配問題。值得注意的是,2014年ACL的最佳論文中,Devlin等人將神經網絡模型引入機器翻譯過程,隨後便湧現出一大批解決機器翻譯問題的深度學習模型,這使得機器翻譯的準確率大幅提高。
推薦系統:
推薦系統是一類根據用戶的歷史數據來向用戶推送用戶可能感興趣的信息。深度學習在推薦系統中的應用主要包括音樂推薦、電影推薦、廣告投放以及新聞推送等。例如,BalazsHidasi等人提出了一種基於RNN的推薦系統,很好的解決了傳統推薦系統只能基於短期會話做推薦的問題;2014年Google利用類似MLP的網絡實現了音樂語音的排名,取得了很不錯的效果;Spotify利用一種典型的CNN模型進行音樂推薦。
深度學習延伸
深度學習的快速發展,不僅使得其在很多實際應用中脫穎而出,而且還帶動了很多利用深度學習很容易實現的應用或者機器學習模式的發展。深度學習在人工智慧領域的影響是大家公認的,但是單純的只靠深度學習是無法讓人工智慧快速發展下去的。因此,新的機器學習方式和網絡結構被提出,本節著重介紹幾種最近非常流行的學習方式。
遷移學習:
遷移學習(transfer learning)是指利用已經訓練好模型的參數來幫助訓練需要訓練的模型。當深度學習網絡比較深的時候,訓練模型就會相對很複雜耗時,通過遷移學習就可以利用之前別人已經訓練好的深度網絡的參數來指導自己模型的訓練,這樣可以提高大網絡訓練的效率。
如圖(Figure 20)所示,Task A, B, C 是三個不同的任務,但是它們的數據存在一定的相關性,因此它們之間可以共用網絡前面的幾層,也就是說在任務A中訓練好的前面幾層網絡的參數可以指導B和C任務的訓練。遷移學習典型例子就是谷歌公司DeepMind做的一篇文章(Andrei A. Rusu et al. 2016),文章中訓練網絡模型來玩三個遊戲,Pong, Labyrinth和Atari,然後利用其中一個遊戲訓練好的網絡來玩另外兩個遊戲,發現結果表現很好。目前,基於深度學習的遷移學習應用已經非常廣泛,例如,利用基於RBM和CNN混合模型的遷移學習框架來對圖像進行分類,這種方法在Pascal VOC2007和Caltech101數據集上取得了較高的分類準確率。
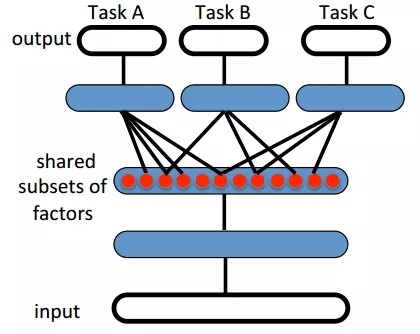
Figure 20. 遷移學習示意圖(Yoshua Bengio et al. 2014)
強化學習(reinforcementlearning)是機器學習的一個重要分支,主要思想是目標隨著環境的改變而行動,保證最終最大化預期利益。一個強化學習模型一般包括環境、對象、動作和反饋幾個基本組件,強化學習模型適合用於控制物理系統(例如無人機)、與用戶交互(例如優化用戶體驗)、解決邏輯問題、學習序列性算法以及玩遊戲等,最典型的強化學習的例子就是DeepMind開發的AlphaGo,它通過自己與自己不斷地的對弈的方式來強化自己的落子準確性。另外,還有一種將強化學習和深度學習結合起來的學習框架DQN,在自然語言處理中已經應用得比較多,例如利用DQN學習對話策略、信息檢索等。
對抗生成網絡:
對抗生成網絡(generative adversarial network, GAN)是2014年由IanGoodfellow等人首次提出的機器學習模型,其主要思想就是有G和D兩個模型,G負責學習產生數據的分布,D負責判別數據是否來自真實的分布,G的目標就是儘量生成可以瞞過D的數據,而D的目標是竭力將G生成的數據判別出來,這個對抗過程經過不斷地疊代訓練最終就會得到數據的生成模型G。GAN在最近兩年被研究得非常火熱,目前已經有各種各樣變種出現,例如基於CNN的DCGAN、基於LSTM的GAN(FangZhao et al. 2016)、基於autoencoder的GAN(Alireza Makhzani et al. 2015)以及基於RNN的C-RNN-GAN(Olof Mogren et al. 2016)等等。這些不同變種的GAN模型已經被廣泛應用在各個領域,例如圖像修復、超級解析度、去遮擋、語義分析、物體檢測以及視頻預測等。
學習資源
在文章的最後,我們列出一些深度學習相關的學習資源,希望對讀者有幫助。
github資料:
深度學習相關資源,包含論文、模型、書、課程等等 https://github.com/endymecy/awesome-deeplearning-resources
跟對抗網絡模型相關的papers: https://github.com/zhangqianhui/AdversarialNetsPapers
Ian Goodfellow等編著的Deep learning書籍: https://github.com/HFTrader/DeepLearningBook
LISA實驗室提供的深度學習教程:
Udacity深度學習課程的代碼:
另一個深度學習資源庫:
還有一個awesome深度學習資源庫,也非常全面: https://github.com/ChristosChristofidis/awesome-deep-learning
非常全面的公開數據集:
在線課程:
斯坦福李飛飛CS231n:
斯坦福Richard Socher關於NLP的課程CS224d:
伯克利Sergey Levine等教授的深度強化學習課程CS294:
牛津大學Nando de Freitas的機器學習課程:
LeCun的深度學習課程:
http://cilvr.cs.nyu.edu/doku.php?id=courses:deeplearning2014:start
Hinton的神經網絡課程:
神經網絡的有一個教學視頻:
https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH
會議/期刊:
會議:ICLR, NIPS, ICML, CVPR, ICCV, ECCV, ACL
期刊:JMLR, MLJ, Neural Computation, JAIR, Artificial Intelligence
本文主要參考資料:
[1]. Ian Goodfellow et al. Deep learning. 2016
[2]. Yoshua Bengio et al. Representation Learning: A Review and New Perspectives. 2014
[3]. Yann LeCun et al. Gradient-based learning applied to document recognition. 1998
[4]. Alex Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. 2012
[5]. Matthew D Zeiler et al. Visualizing and Understanding Convolutional Networks. 2013
[6]. Nitish Srivastava et al. Dropout: A Simple Way to Prevent Neural Networks from overfitting. 2014
[7]. Sergey Ioffe et al. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. 2015
[8]. 侯一民,周慧瓊,王政一. 深度學習在語音識別中的研究進展綜述。2016
[9]. 劉樹傑,董力,張家俊等. 深度學習在自然語言處理中的應用。2015
[10]. Understanding LSTM Networks. colah's blog
作者:軒轅(筆名),數據派研究部志願者,清華大學研究生,喜歡機器學習、大數據相關話題。