本文爲廣州火焰科技投稿,作者蘇劍林。以下爲正文內容:
如果問我哪個是最方便、最好用的詞向量模型,我覺得應該是 word2vec,但如果問我哪個是最漂亮的詞向量模型,我不知道,我覺得各個模型總有一些不足的地方。且不說試驗效果好不好(這不過是評測指標的問題),就單看理論也沒有一個模型稱得上漂亮的。
本文討論了一些大家比較關心的詞向量的問題,很多結論基本上都是實驗發現的,缺乏合理的解釋,包括:
這些討論既有其針對性,也有它的一般性,有些解釋也許可以直接遷移到對 glove 模型和 skip gram 模型的詞向量性質的詮釋中,讀者可以自行嘗試。
圍繞着這些問題的討論,本文提出了一個新的類似 glove 的詞向量模型,這裏稱之爲 simpler glove,並基於斯坦福的 glove 源碼進行修改,給出了本文的實現,具體代碼在 Github 上。
爲什麼要改進 glove?可以肯定的是 glove 的思想是很有啓發性的,然而儘管它號稱媲美甚至超越 word2vec,但它本身卻是一個比較糟糕的模型(後面我們也會解釋它爲什麼糟糕),因此就有了改進空間。
一、對語言進行建模
1、從條件概率到互信息
目前,詞向量模型的原理基本都是詞的上下文的分佈可以揭示這個詞的語義,就好比「看看你跟什麼樣的人交往,就知道你是什麼樣的人」,所以詞向量模型的核心就是對上下文的關係進行建模。
除了 glove 之外,幾乎所有詞向量模型都是在對條件概率 P(w|context) 進行建模,比如 Word2Vec 的 skip gram 模型就是對條件概率 P(w2|w1) 進行建模。
但這個量其實是有些缺點的,首先它是不對稱的,即 P(w2|w1) 不一定等於P(w1|w2),這樣我們在建模的時候,就要把上下文向量和目標向量區分開,它們不能在同一向量空間中;其次,它是有界的、歸一化的量,這就意味着我們必須使用 softmax 等方法將它壓縮歸一,這造成了優化上的困難。
事實上,在NLP的世界裏,有一個更加對稱的量比單純的 P(w2|w1) 更爲重要,那就是:

這個量的大概意思是「兩個詞真實碰面的概率是它們隨機相遇的概率的多少倍」,如果它遠遠大於 1,那麼表明它們傾向於共同出現而不是隨機組合的,當然如果它遠遠小於 1,那就意味着它們倆是刻意迴避對方的。這個量在 NLP 界是舉足輕重的,我們暫且稱它爲「相關度「,當然,它的對數值更加出名,大名爲點互信息(Pointwise Mutual Information,PMI):
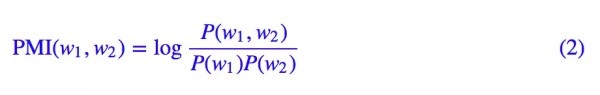
有了上面的理論基礎,我們認爲,如果能直接對相關度進行建模,會比直接對條件概率P(w2|w1) 建模更加合理,所以本文就圍繞這個角度進行展開。在此之前,我們先進一步展示一下互信息本身的美妙性質。
2、互信息的可加性
相關度(等價地,互信息)在樸素假設下,有着非常漂亮的分解性質。所謂樸素假設,就是指特徵之間是相互獨立的,這樣我們就有 P(a,b)=P(a)P(b),也就是將聯合概率進行分解,從而簡化模型。
比如,考慮兩個量 Q,A 之間的互信息,Q,A 不是單個特徵,而是多個特徵的組合:
Q=(q1,…,qk),A=(a1,…,al),現在考慮它們的相關度,即:

用樸素假設就得到:
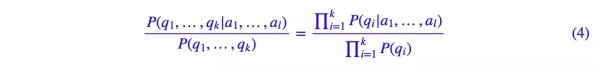
用貝葉斯公式,得到:

再用一次樸素假設,得到:
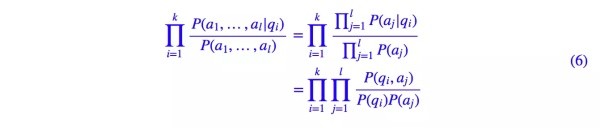
這表明,在樸素假設下,兩個多元變量的相關度,等於它們兩兩單變量的相關度的乘積。如果兩邊取對數,那麼結果就更加好看了,即:
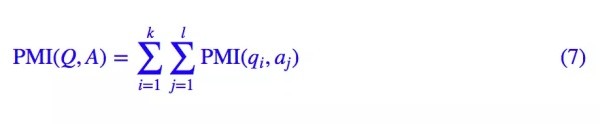
也就是說,兩個多元變量之間的互信息,等於兩兩單變量之間的互信息之和,換句話說,互信息是可加的。
3、插播:番外篇
爲了讓大家更直觀地理解詞向量建模的原理,現在讓我們想象自己是語言界的「月老」,我們的目的是測定任意兩個詞之間的「緣分」,爲每個詞尋找最佳的另一半鋪路。
所謂「有緣千里來相會,無緣見面不相識」,對於每個詞來說,最佳的另一半肯定都是它的「有緣詞」。怎樣的兩個詞纔算是「有緣」呢?那自然是「你的眼裏有我,我的眼裏也有你」了。
前面已經說了,skip gram 模型關心的是條件概率 P(w2|w1),導致的結果是「w1 的眼裏有w2,w2 的眼裏卻未必有 w1」,也就是說,w2 更多的是詞語界的「花花公子」,如「的」、「了」這些停用詞,它們跟誰都能混在一起,但未必對誰都真心。
因此,爲了「你中有我,我中有你」,就必須同時考慮 P(w2|w1) 和 P(w1|w2),或者考慮一個更加對稱的量——也就是前面說的「相關度」了。所以「月老」決定用相關度來定量描述兩個詞之間的「緣分」值。
接下來,「月老」就開始工作了,開始逐一算詞與詞之間的「緣分」了。算着算着,他就發現嚴重的問題了。
首先,數目太多了,算不完。要知道詞語界可是有數萬甚至數十萬、將來還可能是數百萬的詞語,如果兩兩的緣分都算一次並記錄下來,那將要一個數十億乃至數萬億的表格,而且這工作量也不少,也許月老下崗了也還不能把它們都算完,但從負責任的角度,我們不能忽略任意兩個詞在一起的可能性呀!
其次,詞與詞之間的 N 次邂逅,相對於漫漫歷史長河,也不過是滄海一粟。兩個詞沒有碰過面,真的就表明它們毫無緣分了嗎?現在沒有,可不代表將來沒有。作爲謹慎的月老,顯然是不能這麼武斷下結論的。
詞與詞之間的關係錯綜複雜,因此哪怕兩個詞沒有碰過面,也不能一刀切,也得估算一下它們的緣分值。
二、描述相關的模型
1、幾何詞向量
上述「月老」之雲雖說只是幻想,但所面臨的問題卻是真實的。按照傳統 NLP 的手段,我們可以統計任意兩個詞的共現頻率以及每個詞自身的頻率,然後去算它們的相關度,從而得到一個「相關度矩陣」。
然而正如前面所說,這個共現矩陣太龐大了,必須壓縮降維,同時還要做數據平滑,給未出現的詞對的相關度賦予一個合理的估值。
在已有的機器學習方案中,我們已經有一些對龐大的矩陣降維的經驗了,比如 SVD 和 pLSA,SVD 是對任意矩陣的降維,而 pLSA 是對轉移概率矩陣 P(j|i) 的降維,兩者的思想是類似的,都是將一個大矩陣 A 分解爲兩個小矩陣的乘積 A≈BC,其中 B 的行數等於 A 的行數,C 的列數等於 A 的列數,而它們本身的大小則遠小於 A 的大小。如果對 B,C 不做約束,那麼就是 SVD;如果對 B,C 做正定歸一化約束,那就是 pLSA。
但是如果是相關度矩陣,那麼情況不大一樣,它是正定的但不是歸一的,我們需要爲它設計一個新的壓縮方案。借鑑矩陣分解的經驗,我們可以設想把所有的詞都放在 n 維空間中,也就是用 n 維空間中的一個向量來表示,並假設它們的相關度就是內積的某個函數(爲什麼是內積?因爲矩陣乘法本身就是不斷地做內積)。

其中加粗的 vi,vj 表示詞 wi,wj 對應的詞向量。從幾何的角度看,我們就是把詞語放置到了 n 維空間中,用空間中的點來表示一個詞。
因爲幾何給我們的感覺是直觀的,而語義給我們的感覺是複雜的,因此,理想情況下我們希望能夠通過幾何關係來反映語義關係。下面我們就根據我們所希望的幾何特性,來確定待定的函數 f。
事實上,glove 詞向量的那篇論文中做過類似的事情,很有啓發性,但 glove 的推導實在是不怎麼好看。請留意,這裏的觀點是新穎的——從我們希望的性質,來確定我們的模型,而不是反過來有了模型再推導性質。
2、機場-飛機+火車=火車站
詞向量最爲人津津樂道的特性之一就是它的「詞類比(word analogy)」,比如那個經典的「國王-男人+女人=女王」(這項性質是不是詞向量所必需的,是存在爭議的,但這至少算是個加分項)。然而中英文語境不同,在中文語料中這個例子是很難復現的,當然,這樣的例子不少,沒必要死摳「洋例子」,比如在中文語料中,就很容易發現有「機場-飛機+火車=火車站」,準確來說,是:
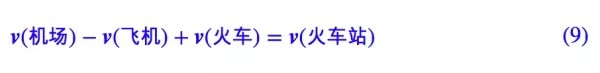
爲什麼詞向量會具有這種特性呢?最近一篇文章《Skip-Gram – Zipf + Uniform = Vector Additivity》對這個現象做了理論分析,文章中基於一些比較強的假設,最後推導出了這個結果。現在我們要做的一件可能比較驚人的事情是:把這個特性直接作爲詞向量模型的定義之一!
具體來說,就是詞義的可加性直接體現爲詞向量的可加性,這個性質是詞向量模型的定義。我們是要從這個性質出發,反過來把前一部分還沒有確定下來的函數 f 找出來。這樣一來,我們不僅爲確定這個 f 找到了合理的依據,還解釋了詞向量的線性運算特性——因爲這根本是詞向量模型的定義,而不是模型的推論。
既然是線性運算,我們就可以移項得到「機場+火車=火車站+飛機」。現在我們來思考一下,單從語義角度來理解,這個等式究竟表達了什麼?
文章開頭已經提到,詞向量模型的假設基本都是用上下文的分佈來推導詞義,既然「機場+火車=火車站+飛機」,那麼很顯然就是說,「機場」與「火車」它們的共同的上下文,跟「火車站」與「飛機」的共同的上下文,兩者基本是一樣的。
說白了,語義等價就相當於說「如果兩個人的擇偶標準是很接近的,那麼他們肯定也有很多共同點」。到這裏,f 的形式就呼之欲出了!
3、模型的形式
因爲詞與詞的相關程度用相關度來描述,所以如果「機場+火車=火車站+飛機」,那麼我們會有:

這裏的 w 是上下文的任意一個詞,由於我們不特別關心詞序,只關心上下文本身的平均分佈,因此,我們可以使用樸素假設來化簡上式,那麼根據式(6)得到:

代入前面假設的式(8),得到:
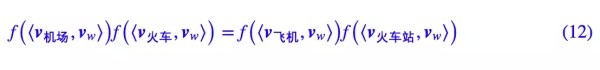
這裏 vw 是任意的,因此上式等價於成立
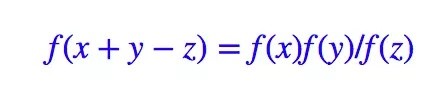
加上連續性條件的話,那麼上述方程的通解就是(求解過程在一般的數學分析書籍應該都可以找到)
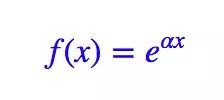
也就是指數形式。現在我們就得到如下結果。爲了讓最後得到的詞向量具有可加性,那麼就需要對相關度用指數模型建模:

等價地,對互信息進行建模:

至此,我們完成了模型的形式推導,從形式上看類似對互信息矩陣的 SVD 分解。
4、忘記歸一化
我們沒有像通常的概率模型那樣,除以一個歸一化因子來完成概率的歸一化。這樣造成的後果是:對於本文的模型,當然也包括 glove 模型,我們不能討論任意有關歸一化的事情,不然會導致自相矛盾的結果。
事實上,這是一種以空間換取時間的做法,因爲我們沒有除以歸一化因子來歸一化,但又必須讓結果接近歸一化,所以我們只能事先統計好所有的共現項的互信息並存好,這往往需要比較大的內存。
而這步驟換來的好處是,所有的共現項其實很有限(「詞對」的數目總比句子的數目要少),因此當你有大規模的語料且內存足夠多時,用 glove 模型往往比用 word2vec 的 skip gram 模型要快得多。
此外,既然本文的模型跟 word2vec 的 skip gram 模型基本上就是相差了一個歸一化因子,那麼很顯然,本文的一些推導過程能否直接遷移到 word2vec 的 skip gram 模型中,基本上取決於 skip gram 模型訓練後它的歸一化因子是否接近於 1。