
按:強化學習(RL)是當下機器學習最活躍的研究方向之一,其中智能體在做正確的事情時獲得獎勵,否則獲得懲罰。這種「胡蘿蔔加大棒」的方法簡單、通用,且能夠幫助 DeepMind 教 DQN 算法玩經典的 Atari 遊戲和 AlphaGo Zero 下圍棋,同樣 OpenAI 也利用 RL 教它的 OpenAI-Five 算法打電子遊戲 Dota,Google 通過強化學習讓機器人手臂去抓取物體。然而,儘管強化學習取得了一些成功,但要使其成爲一種有效的技術仍存在許多挑戰。
對智能體的反饋稀疏的環境使得標準 RL 算法使用起來舉步維艱,至關重要的是,反饋稀疏這種情況在現實世界中很常見。舉個例子,想象一下怎樣在一個大型迷宮式超市中學習如何找到自己喜歡的奶酪。你找啊找,但奶酪區仍無處可尋。如果在每一步的行進中你都沒有得到「胡蘿蔔」或「棒子」,那就無法判斷你是否正朝着正確的方向前進。在沒有獎勵機制的情況下,什麼阻止你在圈子裏徘徊?除了你的好奇心機制外別無他法,好奇心會激勵你進入一個看起來不熟悉的產品部分,來尋找你所追求的奶酪。
關於好奇心的文章,我們此前也曾有過一些,比如關於迷宮裏的智能體的《利用好奇心做稀疏反饋任務的學習》,以及論述好奇心概念本身的《好奇心驅動學習,讓強化學習更簡單》。此次谷歌也提出了一種新的好奇心的實現並撰寫了介紹博客。全文編譯如下。
好奇心的新實現方式
在論文《基於可及性實現情景式的好奇心》《Episodic Curiosity through Reachability》中,谷歌大腦、DeepMind 和蘇黎世聯邦理工學院共同提出了一種新的基於情景記憶(episodic memory)的模型,它可以爲強化學習提供獎勵,類似於可以探索環境的好奇心機制。由於我們希望智能體不僅能夠探索環境而且還要解決原始任務,因此我們將模型提供的獎勵值添加到原始的稀疏任務獎勵中。合併後的獎勵不再稀疏,這使得標準強化算法可以從中學習。因此,谷歌的新的好奇心方法擴展了強化學習的適用範圍。
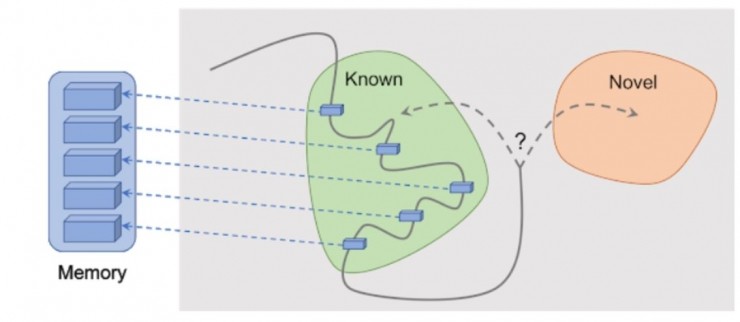
基於可及性的情景好奇心:觀察被添加到記憶中,獎勵是根據當前的觀察與記憶中最相似的觀察的距離來計算的。由於獲得了在記憶中還沒有出現的觀察結果,智能體將會獲得更多的獎勵。
谷歌方法的關鍵思想是將智能體對環境的觀察結果存儲在情景記憶中,同時對智能體得到記憶體中沒有的觀察結果也給予獎勵。「記憶中沒有」就是谷歌的這個方法中對新穎性的定義,尋求記憶中沒有的觀察結果意味着尋求不熟悉的東西。尋找陌生場景的這種動力使得人工智能體到達新的位置,從而防止它在圈內徘徊並最終幫它在偶然中發現目標。正如稍後將討論的,這項的方法可以使智能體避免一些其他方法容易出現的不良行爲 —— 令谷歌的研究人員們驚訝的是,這些不良行爲在外行眼中很像是「拖延」。
先前的好奇心方法
儘管在過去[1] [2] [3] [4]工作中都有許多好奇心方法的嘗試,但在這篇文章中谷歌更關注的是一種在近期文章《Curiosity-driven Exploration by Self-supervised Prediction》中探討的非常流行的自然方法:基於預測驚訝的好奇心(通常稱爲 Intrinsic Curiosity Module,本徵好奇心模塊,ICM)。爲了說明驚訝如何引起好奇,讓我們回到「在超市尋找奶酪」的例子。
當你在整個市場漫步時,你試着預測未來(「現在我在肉類區,所以我認爲拐角處的部分是生鮮區,因爲在超市連鎖店中這些區域通常相鄰」)。如果你的預測是錯誤的,你會感到驚訝(「不,它實際上是蔬菜區。我沒想到!」)因而得到回報。這使您接下來更有動力搜索角落,探索新的位置,看看您對它們的期望是否符合現實(並且希望偶遇奶酪)。
類似地,ICM 方法建立了動態的世界預測模型,並在模型未能做出良好預測時(如給出驚訝或新奇的標記時)給予智能體獎勵。請注意,探索未知的位置並不屬於 ICM 好奇心方式的一部分。對於 ICM 方法,訪問它們只是獲得更多「驚訝」的方式,從而最大化整體獎勵。事實證明,在某些環境中可能存在其他方式造成驚訝,從而導致無法預料的結果。

基於驚訝的好奇心的智能體,遇到電視機之後呆住不動了
「拖延」的危險
在《Large-Scale Study of Curiosity-Driven Learning》[5]一文中,ICM 方法的作者和 OpenAI 的研究人員共同展示了一種最大化「驚訝」的隱藏危險:智能體可以學會放縱拖延的行爲,而不是做一些對於完成手頭任務有用的事情。爲了追根溯源,我們來看一個常見的思維實驗,作者稱之爲「噪聲電視問題」(noisy TV problem):一個智能體被置於一個迷宮中並負責找到一個非常有價值的物體(類似於我們之前的超市案例中的「奶酪」)的實驗。環境還包含一個電視,頻道數量有限(每個頻道都有不同的節目),智能體擁有電視的遙控器,每次按下遙控器都會隨機切換到任意頻道,在這樣的環境中,智能體表現如何呢?
對於基於驚訝的好奇心方法的表述,改變頻道會產生巨大的回報,因爲每次變化都是不可預測和令人驚訝的。重要的是,即使在所有可用頻道循環播放之後,隨機頻道選擇仍是令人驚訝的新變化,智能體正在預測頻道改變後電視上會發生什麼,很可能會出錯,導致驚訝。重要的是,即使智能體已經看過每個頻道的每個節目,這種變化仍然是不可預測的。因此,充滿驚訝的好奇心的智能體最終將永遠留在電視機前,而不是尋找一個非常有價值的節目,跟「拖延」一模一樣。那麼,怎樣定義好奇心纔不會導致這種行爲呢?
情景好奇心
在論文《基於可及性實現情景式的好奇心》中,谷歌的研究人員們探究了一種基於記憶的情景好奇心模型,結果證明此模型不太容易使智能體產生「自我放縱」的即時滿足感。原因何在呢?對於剛纔一樣的電視的例子,在切換頻道一段時間後,所有節目將儲存在記憶中。即使屏幕上出現的節目順序是隨機且不可預測的,所有這些節目已經在內存中,因此,電視將不再具有吸引力。與基於驚訝的好奇心方法的主要區別是,谷歌的方法甚至沒有試圖對可能很難(甚至不可能)預測的未來下注。相反,智能體會回顧過去,以瞭解它是否已經看到類似於當前情景的觀察結果。因此,谷歌的智能體不會被電視節目提供的即時滿足所吸引,它必須去探索已知節目之外場景才能獲得更多獎勵。
但是,要如何定義智能體看到的東西與記憶裏的東西一致呢?完全匹配搜索可能毫無意義,因爲在現實環境中,智能體很少看到兩次完全一致的物體。例如,即使智能體返回到完全相同的房間,它仍然會從異於記憶的不同角度看到這個房間。
谷歌通過訓練深度神經網絡來測量智能體兩個觀察結果的相似程度,而不是通過對記憶的精確匹配搜索的方式。爲了訓練這個網絡,谷歌猜測兩個觀察結果具有時間相關性,在時間上緊密相連,或者相距甚遠。時間接近度是兩個結果是否應該被判斷爲一致的良好特徵。這種訓練導致了一種基於可及性(reachability)的新穎的通用概念,如下圖所示。
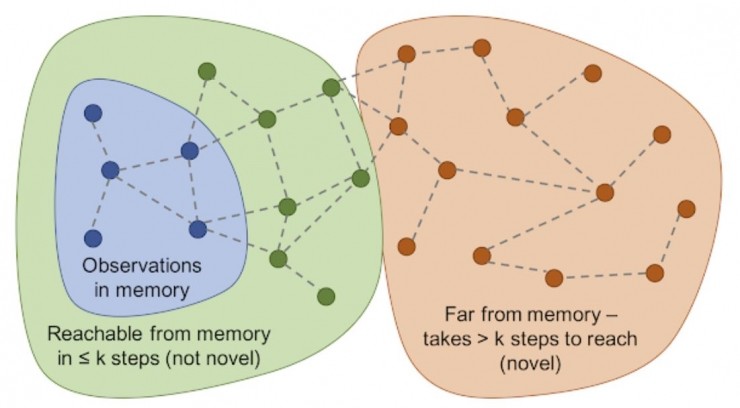
可及性圖決定新穎性。在模型的實際運行中這樣的圖是無法繪製出來的,所以需要訓練一個神經網絡逼近器來估計觀察結果之間的一些步驟。
實驗結果
爲了比較不同好奇心模型方法的性能,谷歌在兩個視覺豐富的 3D 環境 —— ViZDoom 和 DMLab 中測試了它們。在那些環境裏,智能體有很多不同的任務,比如在迷宮中尋找目標或者收集好的並避免壞的東西。
DMLab 環境剛好會給智能體提供一個類似激光發射器的科幻小工具。在之前的研究中,DMLab 的標準設置是在所有任務中爲智能體裝備這個工具;如果在某個特定任務中智能體不需要這個工具,它也可以不用。有趣的是,與之前描述的噪聲 TV 實驗類似,基於好奇心模型的 ICM 方法實際上在大多數任務中都使用了這個工具,即使它對手頭的任務沒有幫助!當任務是在迷宮中尋找高回報物品時,智能體似乎更喜歡花時間標記牆壁,因爲這樣會產生很多「好奇心」獎勵。理論上來說,預測標記結果是可能的,但實際上卻很難,因爲這樣做需要更多的物理知識,而現有的標準智能體還達不到這個標準。

基於驚訝的 ICM 智能體會不斷給牆上打標記,而不是探索這個迷宮
而谷歌的新方法在相同的環境下就能學習到合理的探索行爲。這是因爲它沒有試圖預測其行爲的結果,而是尋找那些從現有情景記憶中難以實現的觀察。換句話說,智能體暗中追求那些需要更多努力才能從內存中獲取而不僅僅是單個標記操作的目標。

谷歌新方法的智能體就展示出了合理的探索行爲
有趣的是,谷歌給予獎勵的方法會懲罰那些兜圈子的智能體。因爲在完成第一圈後,智能體不會遇到除記憶中的觀察結果之外的新觀察,因此不會得到任何獎勵:

智能體得到反饋的可視化演示:紅色表示負反饋,綠色表示正反饋。從左到右三幅圖依次表示:地圖和反饋,地圖和記憶中包含的位置,第一人稱視角
谷歌的新方法就會帶來不錯的探索行爲:

谷歌的研究人員們希望這項的工作將有助於引領新的探索方法浪潮,超越驚訝機制並學習到更智能的探索行爲。有關這個方法的深入分析,請查看論文原文 https://arxiv.org/abs/1810.02274 。
參考文獻
[1] "Count-Based Exploration with Neural Density Models", https://arxiv.org/abs/1703.01310 , Georg Ostrovski, Marc G. Bellemare, Aaron van den Oord, Remi Munos
[2] "#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning", https://arxiv.org/abs/1611.04717, Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
[3] "Unsupervised Learning of Goal Spaces for Intrinsically Motivated Goal Exploration", https://arxiv.org/abs/1803.00781, Alexandre Péré, Sébastien Forestier, Olivier Sigaud, Pierre-Yves Oudeyer
[4] "VIME: Variational Information Maximizing Exploration", https://arxiv.org/abs/1605.09674 , Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
[5]Large-Scale Study of Curiosity-Driven Learning, https://pathak22.github.io/large-scale-curiosity/resources/largeScaleCuriosity2018.pdf , Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, Alexei A. Efros
via ai.googleblog.com,
相關文章:
多任務智能體的一大步:DeepMind 一次搞定 57 種 Atari 遊戲的 PopArt
100:0!Deepmind Nature論文揭示最強AlphaGo Zero,無需人類知識
雖又擊敗了人類選手,但我們認爲 OpenAI 的 5v5 DOTA AI 不過如此