選自arXiv
作者:施少懷、褚曉文
參與:陳韻竹、李澤南
隨着深度學習應用不斷進入商用化,各類框架在服務器端上的部署正在增多,可擴展性正逐漸成爲性能的重要指標。香港浸會大學褚曉文團隊近日提交的論文對四種可擴展框架進行了橫向評測(Caffe-MPI、CNTK、MXNet 與 TensorFlow)。該研究不僅對各類深度學習框架的可擴展性做出了對比,也對高性能服務器的優化提供了方向。
近年來,深度學習(DL)技術在許多 AI 應用當中取得了巨大成功。在獲得大量數據的情況下,深度神經網絡(DNN)能夠很好地學習特徵表示。但是,深度神經網絡和大規模數據有着很高的計算資源要求。幸運的是,一方面,硬件加速器例如 GPU,FPGA 和 Intel Xeon Phi 可減少模型訓練時間。另一方面,近期的一些研究已經證明,具有非常大的 mini-batch 的 DNN 可以很好地收斂到局部最小值。這對於利用大量處理器或集羣而言是非常重要的。單個加速器的計算資源(比如計算單元和內存)有限,無法處理大規模神經網絡。因此,人們提出了並行訓練算法以解決這個問題,比如模型並行化和數據並行化。這也讓科技巨頭們在雲服務中部署可擴展深度學習工具成爲可能。亞馬遜採用 MXNet 作爲雲服務 AWS 的主要深度學習框架,谷歌採取 TensorFlow 爲谷歌雲提供支持,而微軟爲微軟雲開發了 CNTK。此外,浪潮集團開發了 Caffe-MPI 以支持 HPC 的分佈式部署。
在英偉達高性能 DNN 庫 cuDNN 的幫助下,CNTK,MXNet 和 TensorFlow 除了能在單 GPU 上實現高吞吐率之外,還能在多個 GPU 和多種機器之間實現良好的可擴展性。這些框架爲開發者提供了一個開發 DNN 的簡便方法。此外,嘗試相關算法優化,通過使用多核 CPU、衆核 GPU、 多 GPU 和集羣等硬件來實現高吞吐率。但是,由於軟件開發商的實施方法不盡相同,即使在同一個硬件平臺上訓練相同的 DNN,這些工具的性能表現也不盡相同。研究者已經對各種工具在不同 DNN 和不同硬件環境下進行了評估,但是深度學習框架和 GPU 的升級太過頻繁,導致這些基準無法反映 GPU 和軟件的最新性能。另外,多 GPU 和多機平臺的可擴展性還沒有得到很好的研究,但這是計算機集羣最重要的性能指標之一。
本文擴展了我們之前的工作,嘗試評估 4 個分佈式深度學習框架(即 Caffe-MPI、CNTK、MXNet 和 TensorFlow)的性能。我們使用四臺由 56 Gb 的 InfiniBand 架構網絡連接的服務器,其中每一個都配備了 4 塊 NVIDIA Tesla P40,以測試包括單 GPU,單機多 GPU,和多機在內的 CNN 架構的訓練速度。我們首先測試了隨機梯度下降(SGD)優化的運行性能,然後關注跨多 GPU 和多機的同步 SGD(S-SGD)的性能,以分析其細節。我們的主要研究發現如下:
對於相對淺層的 CNN(例如 AlexNet),加載大量訓練數據可能是使用較大 mini-batch 值和高速 GPU 的潛在瓶頸。有效的數據預處理可以降低這一影響。
爲了更好地利用 cuDNN,我們應該考慮自動調優以及輸入數據的格式(例如 NCWH,NWHC)。CNTK 和 MXNet 都對外顯露了 cuDNN 的自動調優配置,這都有利於在前向傳播和反向傳播中獲得更高的性能。
在擁有 multiple GPU 的 S-SGD 當中,CNTK 不會隱藏梯度通信的開銷。但是,MXNet 和 TensorFlow 將當前層的梯度聚合與前一層的梯度計算並行化處理。通過隱藏梯度通信的開銷,擴展性能會更好。
所在四個高吞吐量的密集 GPU 服務器上,所有框架的擴展結果都不是很好。通過 56Gbps 網絡接口的節點間梯度通信比通過 PCIe 的節點內通信慢得多。
論文:Performance Modeling and Evaluation of Distributed Deep Learning Frameworks on GPUs

論文鏈接:https://arxiv.org/pdf/1711.05979.pdf
深度學習框架已經被廣泛部署於 GPU 服務器上,已爲學術界和工業界的深度學習應用提供支持。在深度學習網絡(DNN)的訓練中,有許多標準化過程或算法,比如卷積運算和隨機梯度下降(SGD)。但是,即使是在相同的 GPU 硬件運行相同的深度學習模型,不同架構的運行性能也有不同。這篇文章分別在單 GPU,多 GPU 和多節點環境下評估了四種先進的分佈式深度學習框架(即 Caffe-MPI、CNTK、MXNet 和 TensorFlow)的運行性能。首先,我們構建了使用 SGD 訓練深度神經網絡的標準過程模型,然後用 3 種流行的卷積神經網絡(AlexNet、GoogleNet 和 ResNet-50)對這些框架的運行新能進行了基準測試。通過理論和實驗的分析,我們確定了可以進一步優化的瓶頸和開銷。文章的貢獻主要分爲兩個方面。一方面,對於終端用戶來說,針對他們的場景,測試結果爲他們選擇合適的框架提供了參考。另一方面,被提出的性能模型和細節分析爲算法設計和系統配置而言提供了更深層次的優化方向。

表 2 針對數據並行化的實驗硬件配置
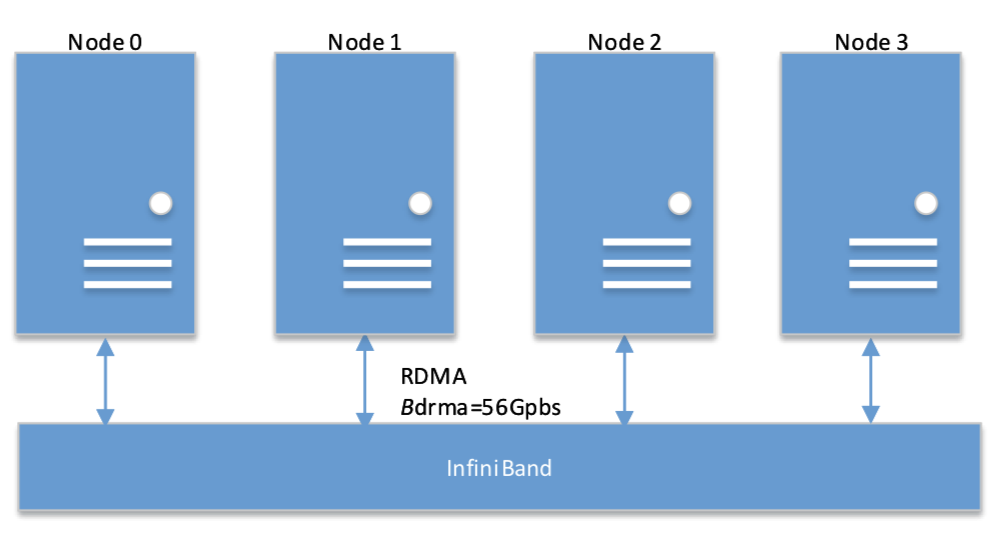
圖 1 GPU 集羣的拓撲
表 3 實驗所用的軟件

表 4 試驗中神經網絡的設置
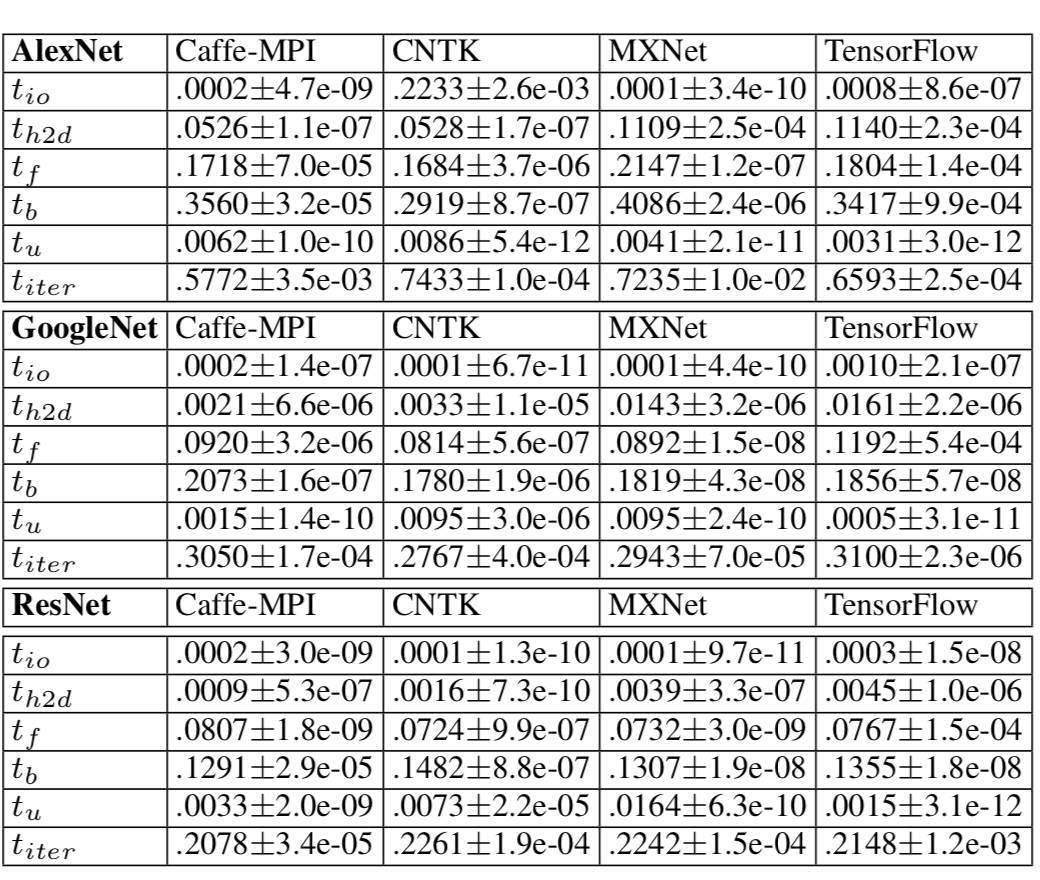
表 5 SGD 不同階段的時間(單位:秒)
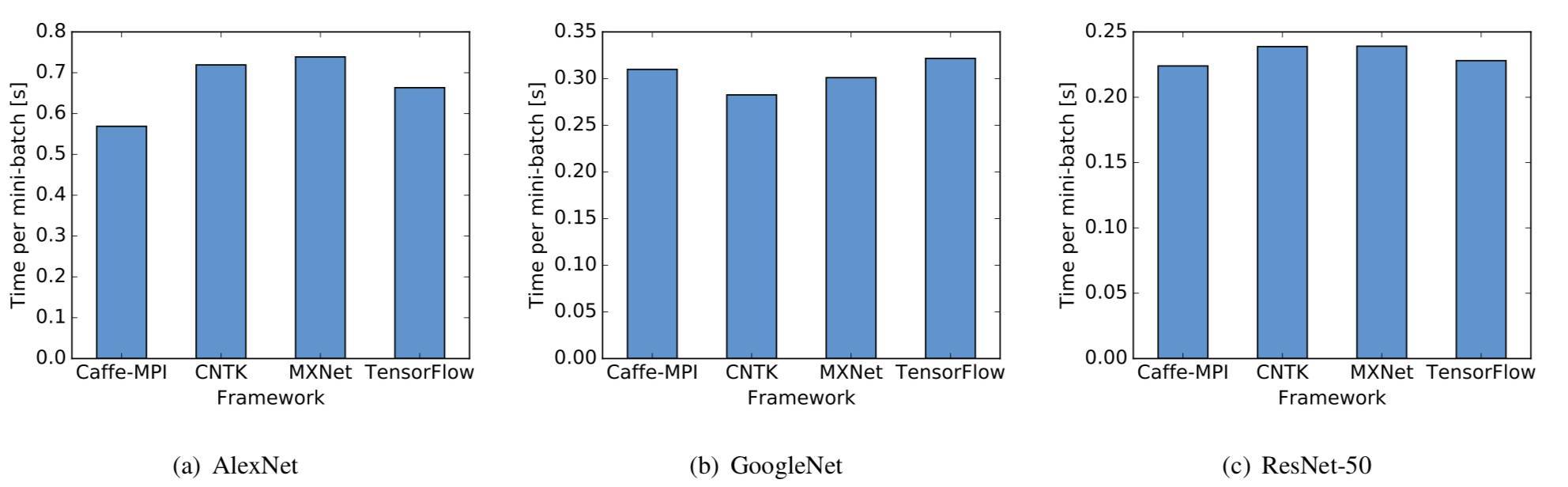
圖 3 三種神經網絡在單 GPU 上的性能比較(數值越低越好)
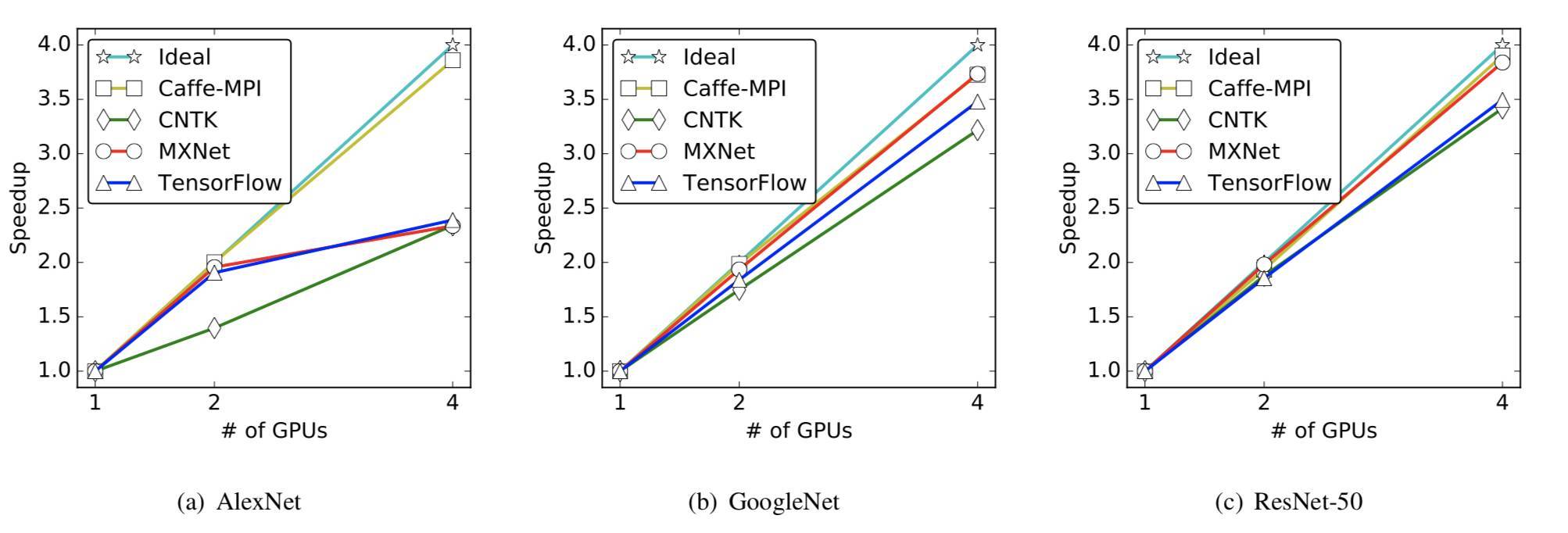
圖 4 三種神經網絡在單節點多 GPU 上的擴展性能
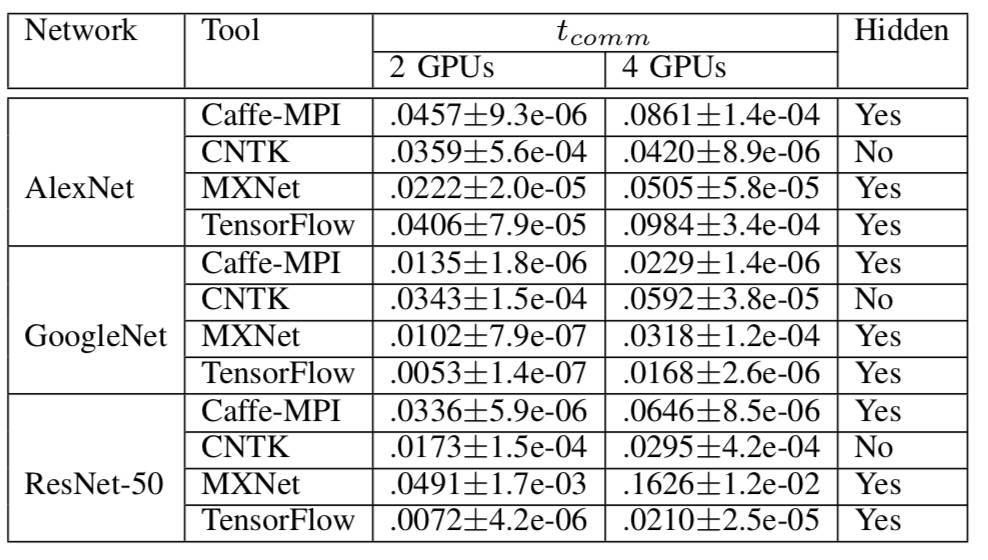
表 6 多 GPU 前端節點梯度聚合的數據通信開銷
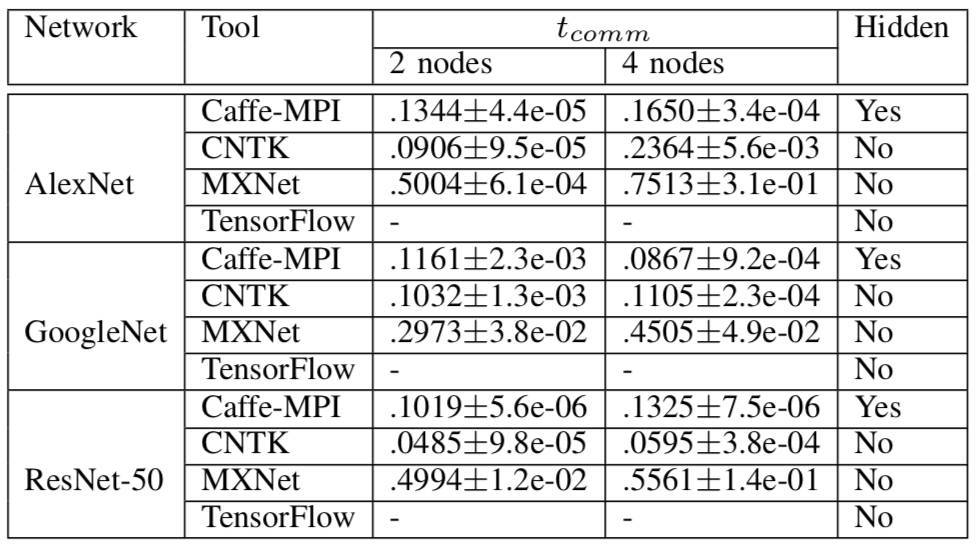
表 7 多機梯度聚合的數據通信開銷
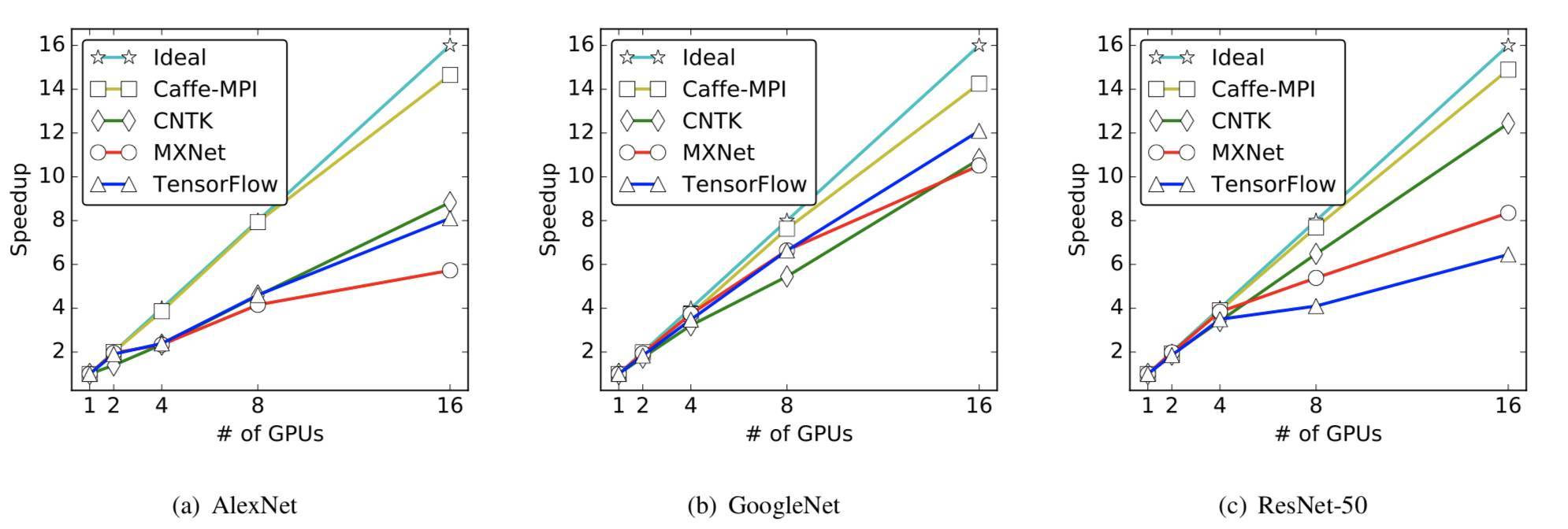
圖 5 多機環境下三種神經網絡的擴展性能。請注意,每臺機器 4 塊 GPU,8 塊 GPU 和 16 塊 GPU 的情況是分別跨 2 個與 4 個機器的。
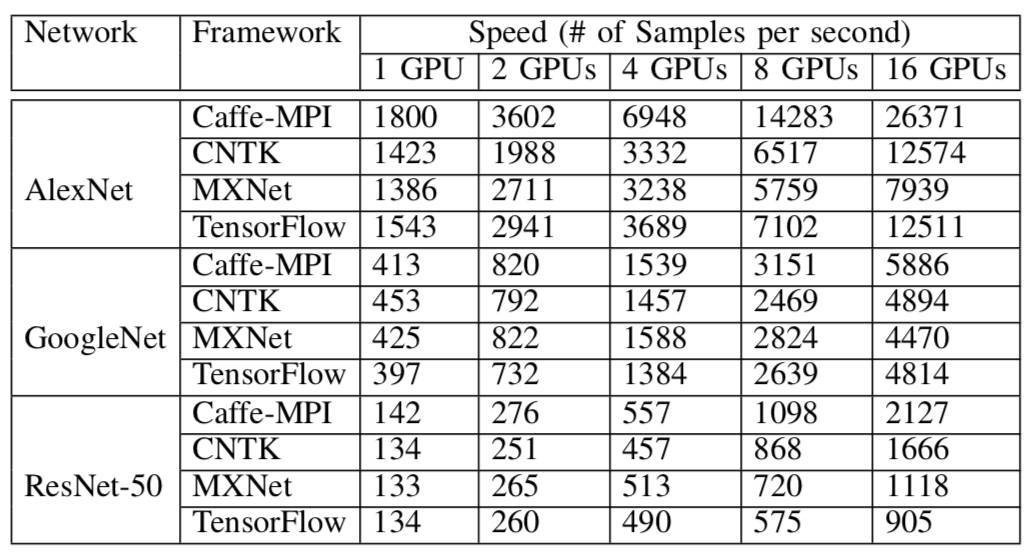
表 8 所有測試案例的速度