按,本文作者王喆,本文首發於知乎專欄王喆的機器學習筆記
這篇文章主要介紹了 YouTube 深度學習系統論文中的十個工程問題,爲了方便進行問題定位,我們還是簡單介紹一下背景知識,簡單回顧一下 Deep Neural Networks for YouTube Recommendations 中介紹的 YouTube 深度學習推薦系統的框架。(更詳細的信息,請參見重讀 Youtube 深度學習推薦系統論文,字字珠璣,驚爲神文)
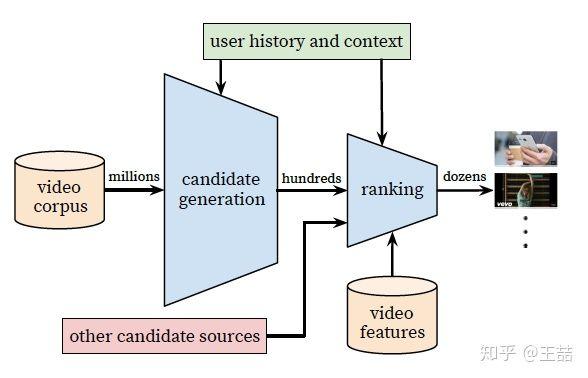
YouTube推薦系統架構
簡單講,YouTube 的同學們構建了兩級推薦結構從百萬級別的視頻候選集中進行視頻推薦,第一級 candidate generation model 負責「初篩」,從百萬量級的視頻庫中篩選出幾百個候選視頻,第二級 ranking model 負責「精排」,引入更多的 feature 對幾百個候選視頻進行排序。
不管是 candidate generation model 還是 ranking model,在架構上都是 DNN 的基本結構,不同的是輸入特徵和優化目標不同。但正如我在上一篇文章中講的,如果你僅讀懂了 YouTube 的模型架構,至多獲得了 30% 的價值,剩下 70% 的價值就在於下面的十大工程問題。廢話不多說,我們進入問題的解答。
1. 文中把推薦問題轉換成多分類問題,在預測 next watch 的場景下,每一個備選 video 都會是一個分類,因此總共的分類有數百萬之巨,這在使用 softmax 訓練時無疑是低效的,這個問題 YouTube 是如何解決的?
這個問題原文的回答是這樣的:
We rely on a technique to sample negative classes from the background distribution ("candidate sampling") and then correct for this sampling via importance weighting.
簡單說就是進行了負採樣(negative sampling)並用 importance weighting 的方法對採樣進行 calibration。文中同樣介紹了一種替代方法,hierarchical softmax,但並沒有取得更好的效果。當然關於採樣的具體技術細節以及優劣可能再開一篇文章都講不完,感興趣的同學可以參考 TensorFlow 中的介紹(https://www.tensorflow.org/extras/candidate_sampling.pdf)以及NLP領域的經典論文 http://www.aclweb.org/anthology/P15-1001
也歡迎有相關經驗的同學在評論中給出簡明的回答。
2. 在 candidate generation model 的 serving 過程中,YouTube 爲什麼不直接採用訓練時的 model 進行預測,而是採用了一種最近鄰搜索的方法?
這個問題的答案是一個經典的工程和學術做 trade-off 的結果,在 model serving 過程中對幾百萬個候選集逐一跑一遍模型的時間開銷顯然太大了,因此在通過 candidate generation model 得到 user 和 video 的 embedding 之後,通過最近鄰搜索的方法的效率高很多。我們甚至不用把任何 model inference 的過程搬上服務器,只需要把 user embedding 和 video embedding 存到 redis 或者內存中就好了。
但這裏我估計又要求助場外觀衆了,在原文中並沒有介紹得到 user embedding 和 video embedding 的具體過程,只是在架構圖中從 softmax 朝 model serving module 那畫了個箭頭(如下圖紅圈內的部分),到底這個 user vector 和 video vector 是怎麼生成的?有經驗的同學可以在評論中介紹一下。
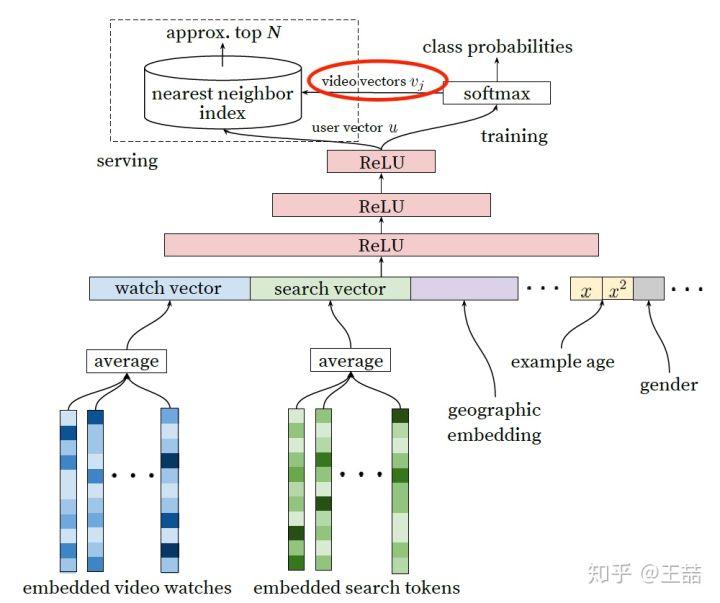
Candidate Generation Model, video vector是如何生成的?
3. Youtube 的用戶對新視頻有偏好,那麼在模型構建的過程中如何引入這個 feature?
爲了擬合用戶對 fresh content 的 bias,模型引入了「Example Age」這個 feature,文中其實並沒有精確的定義什麼是 example age。按照文章的說法猜測的話,會直接把 sample log 距離當前的時間作爲 example age。比如 24 小時前的日誌,這個 example age 就是 24。在做模型 serving 的時候,不管使用哪個 video,會直接把這個 feature 設成 0。大家可以仔細想一下這個做法的細節和動機,非常有意思。
當然我最初的理解是訓練中會把 Days since Upload 作爲 example age,比如雖然是 24 小時前的 log,但是這個 video 已經上傳了 90 小時了,那這個 feature value 就是 90。那麼在做 inference 的時候,這個 feature 就不會是 0,而是當前時間每個 video 的上傳時間了。
我不能 100% 確定文章中描述的是哪種做法,大概率是第一種。還請大家踊躍討論。
文章也驗證了,example age 這個 feature 能夠很好的把視頻的 freshness 的程度對 popularity 的影響引入模型中。
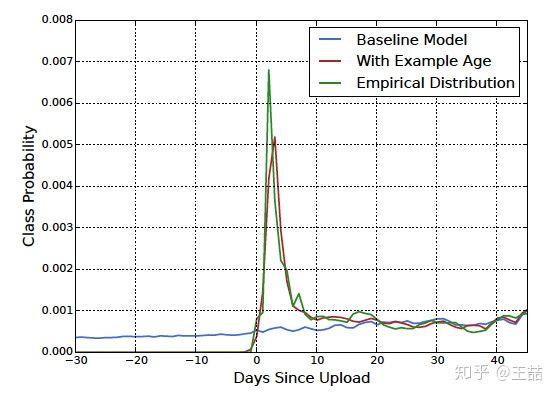
從上圖中我們也可以看到,在引入「Example Age」這個 feature 後,模型的預測效力更接近經驗分佈;而不引入 Example Age 的藍線,模型在所有時間節點上的預測趨近於平均,這顯然是不符合客觀實際的。
4. 在對訓練集的預處理過程中,YouTube 沒有采用原始的用戶日誌,而是對每個用戶提取等數量的訓練樣本,這是爲什麼?
原文的解答是這樣的:
Another key insight that improved live metrics was to generate a xed number of training examples per user, e ectively weighting our users equally in the loss function. This prevented a small cohort of highly active users from dominating the loss.
理由很簡單,這是爲了減少高度活躍用戶對於 loss 的過度影響。
5. YouTube 爲什麼不採取類似 RNN 的 Sequence model,而是完全摒棄了用戶觀看歷史的時序特徵,把用戶最近的瀏覽歷史等同看待,這不會損失有效信息嗎?
這個原因應該是 YouTube 工程師的「經驗之談」,如果過多考慮時序的影響,用戶的推薦結果將過多受最近觀看或搜索的一個視頻的影響。YouTube 給出一個例子,如果用戶剛搜索過「tayer swift」,你就把用戶主頁的推薦結果大部分變成 tayer swift 有關的視頻,這其實是非常差的體驗。爲了綜合考慮之前多次搜索和觀看的信息,YouTube 丟掉了時序信息,將用戶近期的歷史紀錄等同看待。
但 RNN 到底適不適合 next watch 這一場景,其實還有待商榷,@嚴林 大神在上篇文章的評論中已經提到,YouTube 已經上線了以 RNN 爲基礎的推薦模型, 參考論文如下:https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46488.pdf
看來時隔兩年,YouTube 對於時序信息以及 RNN 模型有了更多的掌握和利用。
6. 在處理測試集的時候,YouTube 爲什麼不採用經典的隨機留一法(random holdout),而是一定要把用戶最近的一次觀看行爲作爲測試集?
這個問題比較好回答,只留最後一次觀看行爲做測試集主要是爲了避免引入 future information,產生與事實不符的數據穿越。
7. 在確定優化目標的時候,YouTube 爲什麼不採用經典的 CTR,或者播放率(Play Rate),而是採用了每次曝光預期播放時間(expected watch time per impression)作爲優化目標?
這個問題從模型角度出發,是因爲 watch time 更能反映用戶的真實興趣,從商業模型角度出發,因爲 watch time 越長,YouTube 獲得的廣告收益越多。而且增加用戶的 watch time 也更符合一個視頻網站的長期利益和用戶粘性。
這個問題看似很小,實則非常重要,Objective 的設定應該是一個算法模型的根本性問題,而且是算法模型部門跟其他部門接口性的工作,從這個角度說,YouTube 的推薦模型符合其根本的商業模型,這是非常好的經驗。
我之前在領導一個算法小組的時候,要花大量時間與 Business 部門溝通 Objective 的設定問題,這是路線方針的問題,方向錯了是要讓組員們很多努力打水漂的,一定要慎之又慎。
8. 在進行 video embedding 的時候,爲什麼要直接把大量長尾的 video 直接用 0 向量代替?
這又是一次工程和算法的 trade-off,把大量長尾的 video 截斷掉,主要還是爲了節省 online serving 中寶貴的內存資源。當然從模型角度講,低頻 video 的 embedding 的準確性不佳是另一個「截斷掉也不那麼可惜」的理由。
當然,之前很多同學在評論中也提到簡單用 0 向量代替並不是一個非常好的選擇,那麼有什麼其他方法,大家可以思考一下。
9. 針對某些特徵,比如 #previous impressions,爲什麼要進行開方和平方處理後,當作三個特徵輸入模型?
這是很簡單有效的工程經驗,引入了特徵的非線性。從 YouTube 這篇文章的效果反饋來看,提升了其模型的離線準確度。
10. 爲什麼 ranking model 不採用經典的 logistic regression 當作輸出層,而是採用了 weighted logistic regression?
因爲在第 7 問中,我們已經知道模型採用了 expected watch time per impression 作爲優化目標,所以如果簡單使用 LR 就無法引入正樣本的 watch time 信息。因此採用 weighted LR,將 watch time 作爲正樣本的 weight,在線上 serving 中使用 e(Wx+b) 做預測可以直接得到 expected watch time 的近似,完美。
十個問題全部答完,希望對大家有幫助。其實在上一篇文章拋出這十個問題的時候,已經有諸位大神做出了很好的回答,感謝
@做最閒的鹹魚
@嚴林
@吳海波
最後增加一個思考環節,大家可以討論一下下面的問題:
本論文中,用於 candidate generation 網絡 serving 部分的 user embedding vector 和 video embedding vector 是怎麼生成的?
Example age 這個 feature 的定義到底是什麼?
除了用 0 向量 embedding 替代長尾內容,有沒有其他好的方法?