谷歌去年年中推出的 TPUv1 一度讓英偉達感受到威脅將近,而現在的谷歌 TPU 二代 TPUv2 則着着實實得將這份威脅變成了現實,去年的評測中英偉達 Tesla V100 尚能不懼谷歌 TPUv1 的挑戰,但是現在谷歌 TPU 二代來了,英偉達 Tesla V100 尚能戰否?

以下爲 RiseML 對谷歌 TPUv2 和英偉達 Tesla V100 的對比評測,內容編譯如下。
谷歌在 2017 年爲加速深度學習開發了一款的定製芯片,張量處理單元 v2 (TPUv2)。TPUv2 是谷歌在 2016 年首次公開的深度學習加速雲端芯片 TPUv1 的二代產品,被認爲有着替代英偉達 GPU 的潛在實力。RiseML 此前撰寫過一篇谷歌 TPUv2 的初體驗,並隨後收到了大家「將谷歌 TPUv2 與英偉達 V100 GPU 進行對比評測」的大量迫切要求。
但是將這兩款深度學習加速芯片進行公平而又有意義的對比評測並非易事。同時由於這兩款產品的對業界未來發展的重要程度和當前深度詳細評測的缺失,這讓我們深感需要自行對這兩款重磅雲端芯片進行深度評測。我們在評測過程中也儘可能地站在芯片對立雙方傾聽不同意見,因此我們也同時與谷歌和英偉達的工程師建立聯繫並讓他們在本次評測文草稿階段留下各自的意見。以上措施使得我們做出了針對 TPUv2 和 V100 這兩款雲端芯片的最全面深度對比評測。
實驗設置
我們用四個 TPUv2 芯片(來自一個 Cloud TPU 設備)對比四個英偉達 V100 GPU,兩者都具備 64GB 內存,因而可以訓練相同的模型和使用同樣的批量大小。該實驗中,我們還採用了相同的訓練模式:四個 TPUv2 芯片組成的一個 Cloud TPU 來運行一種同步數據並行分佈式訓練,英偉達一側也是同樣利用四個 V100 CPU。
模型方面,我們決定使用圖像分類的實際標準和參考點在 ImageNet 上訓練 ResNet-50 模型。雖然 ResNet-50 是可公開使用的參考實例模型,但是現在還沒有能夠單一的模型實現支持在 Cloud TPU 和多個 GPU 上進行模型訓練。
對於 V100,英偉達建議使用 MXNet 或者 TensorFlow 的實現,可以在 Nvidia GPU Cloud 平臺上的 Docker images 中使用它們。然而,我們發現 MXNet 或者 TensorFlow 實現直接拿來使用的話,在多 GPU 和對應的大訓練批量下並不能很好地收斂。這就需要加以調整,尤其是在學習率的設置方面。
作爲替代,我們使用了來自 TensorFlow 的 基準庫(benchmark repository),並在 tensorflow/tensorflow:1.7.0-gpu, CUDA 9.0, CuDNN 7.1.2 下在 Docker image 中運行它。它明顯快過英偉達官方推薦的 TensorFlow 實現,而且只比 MXNet 實現慢 3%。不過它在批量下收斂得很好。這就有助於我們在同樣平臺(TensorFlow 1.7.0)下使用相同框架,來對兩個實現進行比較。
雲端 TPU 這邊,谷歌官方推薦使用來自 TensorFlow 1.7.0 TPU repository 的 bfloat16 實現。TPU 和 GPU 實現利用各個架構的混合精度訓練計算以及使用半精度存儲最大張量。
針對 V100 的實驗,我們在 AWS 上使用了四個 V100 GPU(每個 16 GB 內存)的 p3.8xlarge 實例(Xeon E5-2686@2.30GHz 16 核,244 GB 內存,Ubuntu 16.04)。針對 TPU 實驗,我們使用了一個小型 n1-standard-4 實例作爲主機(Xeon@2.3GHz 雙核,15GB 內存,Debian 9),併爲其配置了由四個 TPUv2 芯片(每個 16 GB 的內存)組成的雲端 TPU(v2-8)。
我們進行了兩種不同的對比實驗,首先,我們在人工合成自然場景(未增強數據)下,觀察了兩者在每秒圖像處理上的原始表現,具體來說是數據吞吐速度(每秒處理的圖像數目)。這項對比與是否收斂無關,而且確保 I / O 中無瓶頸或無增強數據影響結果。第二次對比實驗,我們觀察了兩者在 ImageNet 上的準確性和收斂性。
數據吞吐速度結果
我們在人工合成自然場景(未增強數據)下,以每秒圖像處理的形式觀測了數據吞吐速度,也就是,在不同批量大小下,訓練數據也是在運行過程中創造的。同時需要注意,TPU 的官方推薦批量大小是 1024,但是基於大家的實驗要求,我們還在其他批量大小下進行了兩者的性能測試。
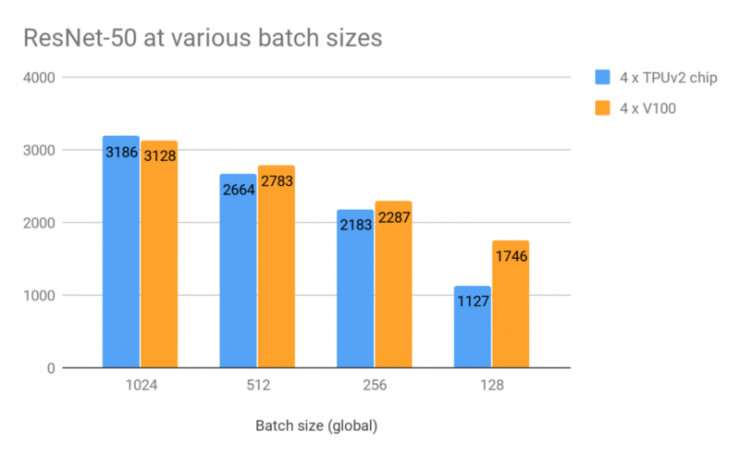
在生成的數據和沒有數據增強的設置下,在各種批量大小下測試兩者的每秒圖像處理性能表現。批量大小爲「global」總計的,即 1024 意味着在每個步驟中每個 GPU / TPU 芯片上的批量大小爲 256
當批量大小爲 1024,兩者在數據吞吐速度中並無實際區別!谷歌 TPU 有約 2% 的輕微領先優勢。大小越小,兩者的性能表現會越降低,這時 GPU 就表現地稍好一點。但如上所述,目前這些批量大小對於 TPU 來說並不是一個推薦設置。
根據英偉達的官方建議,我們還在 MXNet 上使用 GPU 做了一個實驗,使用的是 Nvidia GPU Cloud 上提供的 Docker image (mxnet:18.03-py3) 內的 ResNet-50 實現。在批量大小爲 768 時(1024 太大),GPU 能每秒處理 3280 張圖像。這比上面 TPU 最好的性能表現還要快 3%。但是,就像上面那樣,在批量大小同爲 168 時,多 GPU 上 MXNet 收斂得並不好,這也是我們爲什麼關注兩者在 TensorFlow 實現上的表現情況,包括下面提及的也是一樣。
雲端成本
現在 Google Cloud 已經開放了雲端 TPU(四個 TPUv2 芯片)。只有在被要求計算時,雲端 TPU 纔會連接到 VM 實例。雲端測試方面,我們考慮使用 AWS 來測試英偉達 V100(因爲 Google Cloud 當前仍不支持 V100)。基於上面的測試結果,我們總結出了兩者在各自平臺和 provider 上的每秒處理圖像數量上的花費成本(美元)。
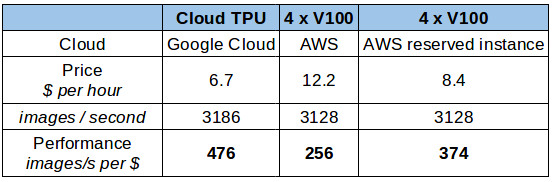
每秒圖像處理上的成本(美元)
在上表所示的成本下,雲端 TPU 顯然是個贏者。然而,當你考慮長期租用或者購買硬件(雲 TPU 現在還沒有辦法買到),情況可能會不同。以上情況還包括當租用 12 個月時的情況(在 AWS 上的 p3.8xlarge 保留實例的價格(無預付款))。這種租用情況將明顯得將價格降低至每 1 美元處理 375 張圖像的成本。
GPU 這邊有一個更有意思的購買選項可以考慮,例如 Cirrascale 就提供了四個 V100 GPU 服務器的月租服務,月租金 7500 美元(約 10.3 美元/小時)。但是由於硬件會因 AWS 上的硬件配置(CPU 種類,內存以及 NVLink 支持等等)的不同而改變,而以 benchmarks 爲基準的對比評測要求的是直接的對比(非雲端租用)。
正確率和收斂
除報告兩者的原始性能之外,我們還想驗證計算(computation)是「有意義」的,也就是指,實現收斂至好的結果。因爲我們比較的是兩種不同的實現,所以一些誤差是在預料之中的。因此,這是一項不僅僅是關於硬件速度,還會涉及到實現質量的對比評測。TPU 的 ResNet-50 實現中加入了非常高計算強度的圖像預處理過程,這實際上犧牲了一部分數據吞吐速度。谷歌給出的實現中就是這樣設計的,稍後我們也會看到這種做法確實獲得了回報。
我們在 ImageNet 數據集上訓練模型,訓練任務是將一張圖像分類至如蜂鳥,墨西哥捲餅或披薩的 1000 個類別。這個數據集由訓練用的 130 萬張圖像(約 142 GB)以及 5 萬張用於驗證的圖像(約 7 GB)組成。
我們在批量大小爲 1024 的情況下,對模型進行了 90 個時期的訓練,並將數據驗證的結果進行了比較。我們發現,TPU 實現始終保持每秒處理 2796 張圖像的進程,同時 GPU 實現保持每秒處理 2839 張。這也是根據上面數據吞吐速度結果所得的區別,我們是在未進行數據增強和使用生成的數據的情況下,對 TPU 和 GPU 進行的原始速度比較。
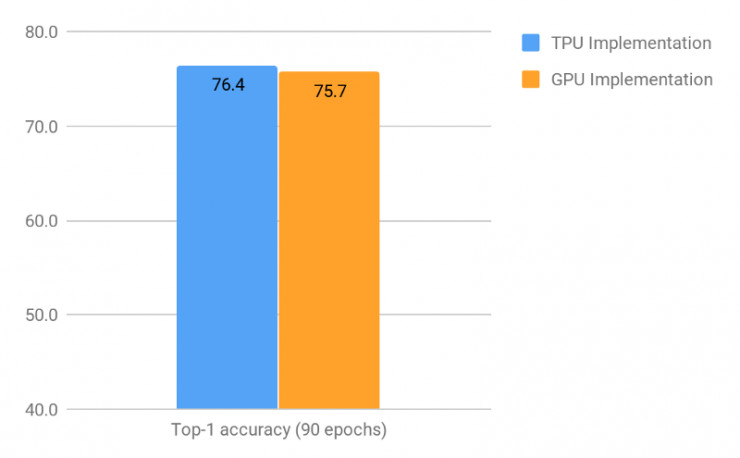
兩個實現在進行了 90 個時期訓練後的首位準確率(即只考慮每張圖像具有最高可信度的預測情況下)
如上圖所示,TPU 實現 進行了 90 個時期訓練後的首位準確率比 GPU 多 0.7%。這在數值上可能看起來是很小的差別,但是在兩者已經非常高的水平上進行提升是極度困難的,以及在兩者在實際應用場景中,即便是如此小差距的提升也將最終導致在表現產生天壤之別。
讓我們來看一下在不同的訓練時期模型學習識別圖像的首位準確率。
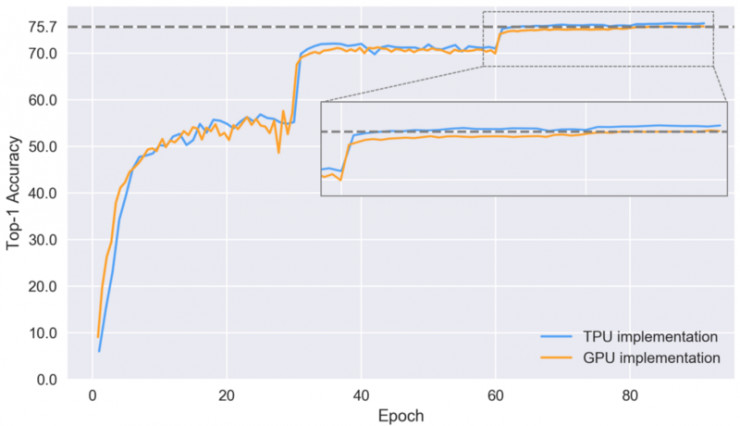
設置了驗證的兩個 實現的首位準確率
上表中放大圖部分首位準確率的劇烈變化,與 TPU 和 GPU 這兩個 實現上模型的學習速率是相吻合的。TPU 實現上的收斂過程要好於 GPU,並在 86 個時期的模型訓練後,最終達到 76.4% 的首位準確率,但是作爲對比,TPU 實現則只需 64 個模型訓練時期就能達到相同的首位準確率。TPU 在收斂上的提升貌似歸功於更好的預處理和數據增強,但還需要更多的實驗來確認這一點。
基於雲端的解決方案成本
最後,在需要達到一定的精確度的情況下,時間和金錢成本最爲關鍵。我們假設精確度 75.7%(GPU 實現可實現的最高精確度)爲可接受的解決方案,我們就可以計算出,基於要求的模型訓練時期和模型圖像每秒處理的訓練速度,達到該精確度的所需成本。這還包括計算模型在某個訓練時期節點上花費的時間和模型初始訓練所需的時間。
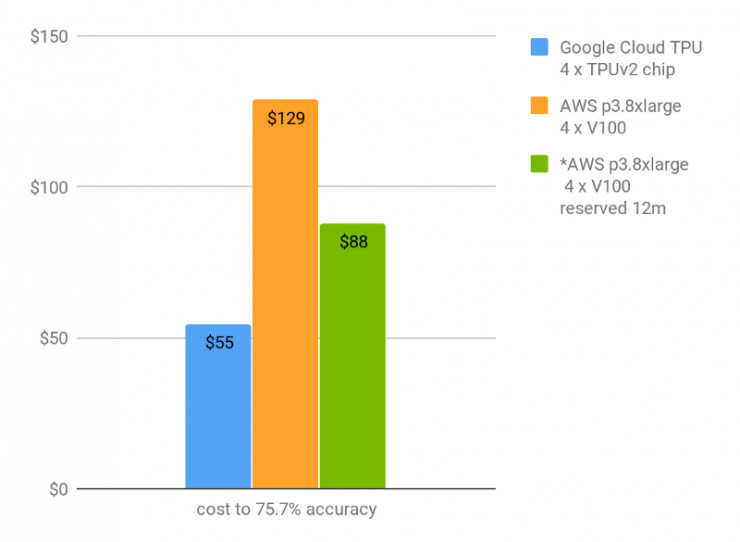
首位準確率達到 75.7% 的金錢成本(保留 12 個月的使用週期)
正如上表所示,雲端 TPU 允許用戶在 9 個小時內並且花費 55 美元,就能在 ImageNet 上從零開始訓練模型精確度至 75.7%,花費 73 美元能將模型收斂訓練至 76.4%。雖然V100 與 TPU 的運行速度同樣,但V100 花費價格過高以及其收斂實現更慢,所以採用 TPU是明顯更具性價比的解決方案。
需要再一次說明的是,我們本次所做的對比評測的結果取決於實現的質量以及雲端服務器的標價。
另外一項兩者的有趣對比將會是基於兩者在能量功耗上的比較。然而,我們現在還無法得知任何公開的 TPUv2 能量功耗信息。
總結
基於我們的實驗標準,我們總結出,在 ResNet-50 上四個 TPUv2 芯片(即一個雲端 TPU)和四個 GPU 的原始運行速度一樣快(2% 的實驗誤差範圍內)。我們也期待將來能通過對軟件(TensorFlow 或 CUDA)優化來提升兩者在平臺上的運行性能和改善實驗誤差。
在特定問題實例上達到特定的精確度的兩者實際運用中,時間和雲端成本最爲關鍵。以目前的雲端 TPU 定價,配合高水平的 ResNet-50 實現,在 ImageNet 上達到了令人欽佩的準確率對時間和金錢成本(僅花費 73 美元就能訓練模型達到 76.4%的精確度)。
將來,我們還將採用來自其他領域的不同網絡架構作爲模型的基準以進行更深度的評測。還有一個有趣的實驗點是,對於給定的硬件平臺,想要高效地利用硬件資源需要花費多少精力。舉例來說,混合精度的計算可以帶來明顯的性能提升,然而在 GPU 和 TPU 上的實現和模型表現卻是迥異的。
最後,感謝弗萊堡大學的 Hannah Bast、卡耐基梅隆大學的 David Andersen、Tim Dettmers 和 Mathias Meyer 對本次對比評測草稿文的研讀與矯正。
via RiseML Blog,