選自Statsbot
作者:Eduard Tyantov
2017 年只剩不到十天,隨着 NIPS 等重要會議的結束,是時候對這一年深度學習領域的重要研究與進展進行總結了。來自機器學習創業公司的 Eduard Tyantov 最近就爲我們整理了這樣一份列表。想知道哪些深度學習技術即將影響我們的未來嗎?本文將給你作出解答。

1. 文本
1.1 谷歌神經機器翻譯
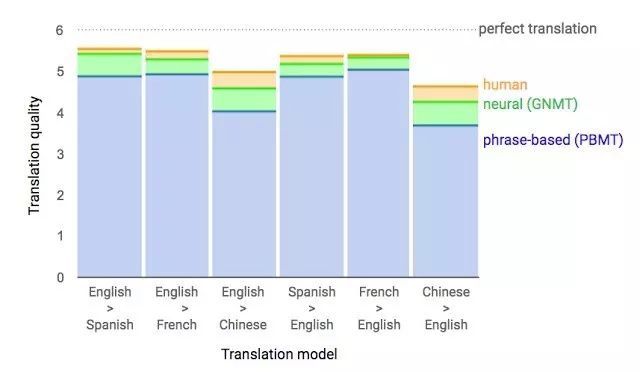
去年,谷歌宣佈上線 Google Translate 的新模型,並詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。
關鍵結果:與人類翻譯準確率的差距縮小了 55-85%(研究者使用 6 個語言對的評估結果)。但是該模型如果沒有谷歌的大型數據集,則很難復現這麼優秀的結果。
參考閱讀:
重磅 | 谷歌翻譯整合神經網絡:機器翻譯實現顛覆性突破(附論文)
專訪 | 谷歌神經網絡翻譯系統發佈後,我們和 Google Brain 的工程師聊了聊
1.2 談判會達成嗎?
你或許聽說過「Facebook 因爲聊天機器人失控、創造自己語言而關閉聊天機器人」的消息。這個機器人是用來進行談判的,其目的是與另一個智能體進行文本談判,然後達成協議:如何把物品(書籍、帽子等)分成兩份。談判中每個智能體都有自己的目標,而對方並不知道。談判不可能出現未達成協議的情況。
研究者在訓練過程中收集人類談判的數據集,訓練監督式循環網絡。然後,讓用強化學習訓練出的智能體自己與自己交流,直到獲得與人類相似的談判模式。
該機器人學會了一種真正的談判策略——對某個交易的特定方面假裝產生興趣,然後再放棄它們,以達到真實目標。這是第一次嘗試此類互動機器人,而且也比較成功。
當然,稱該機器人創造了一種新語言的說法過於誇張了。和同一個智能體進行談判的訓練過程中,研究者無法限制文本與人類語言的相似度,然後算法修改了互動語言。這是很尋常的事。
參考閱讀:
業界 | 讓人工智能學會談判,Facebook 開源端到端強化學習模型
2. 語音
2.1 WaveNet:一種針對原始語音的生成模型
DeepMind 的研究者基於先前的圖像生成方法構建了一種自迴歸全卷積模型 WaveNet。該模型是完全概率的和自迴歸的(fully probabilistic and autoregressive),其每一個音頻樣本的預測分佈的前提是所有先前的樣本;不過研究表明它可以有效地在每秒音頻帶有數萬個樣本的數據上進行訓練。當被應用於文本轉語音時,它可以得到當前最佳的表現,人類聽衆評價它在英語和漢語上比當前最好的參數(parametric)和拼接(concatenative)系統所生成的音頻聽起來都顯著更爲自然。
單個 WaveNet 就可以以同等的保真度捕獲許多不同說話者的特點,而且可以通過調節說話者身份來在它們之間切換。當訓練該模型對音樂建模時,我們發現它可以生成全新的、而且往往具有高度真實感的音樂片段。該研究還證明其可以被用作判別模型,可以爲音速識別(phoneme recognition)返回很有希望的結果。
該網絡以端到端的方式進行訓練:文本作爲輸入,音頻作爲輸出。研究者得到了非常好的結果,機器合成語音水平與人類差距縮小 50%。
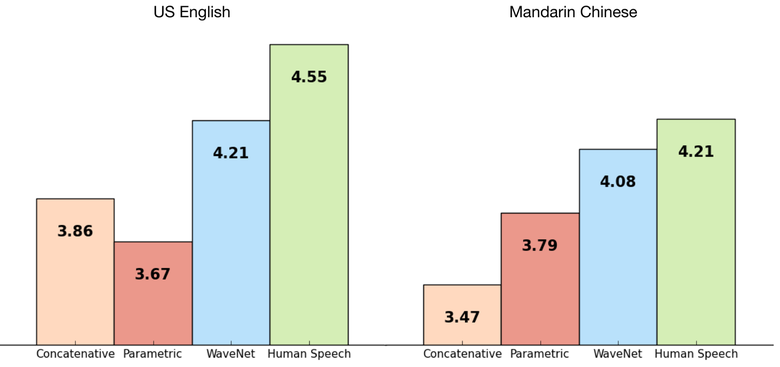
該網絡的主要缺陷是低生產力,因爲它使用自迴歸,聲音按序列生成,需要 1-2 分鐘的時間才能生成一秒音頻。
參考閱讀:
DeepMind WaveNet,將機器合成語音水平與人類差距縮小 50%
2.2 脣讀
脣讀(lipreading)是指根據說話人的嘴脣運動解碼出文本的任務。傳統的方法是將該問題分成兩步解決:設計或學習視覺特徵、以及預測。最近的深度脣讀方法是可以端到端訓練的(Wand et al., 2016; Chung & Zisserman, 2016a)。目前脣讀的準確度已經超過了人類。

Google DeepMind 與牛津大學合作的一篇論文《Lip Reading Sentences in the Wild》介紹了他們的模型經過電視數據集的訓練後,性能超越 BBC 的專業脣讀者。
該數據集包含 10 萬個音頻、視頻語句。音頻模型:LSTM,視頻模型:CNN + LSTM。這兩個狀態向量被饋送至最後的 LSTM,然後生成結果(字符)。
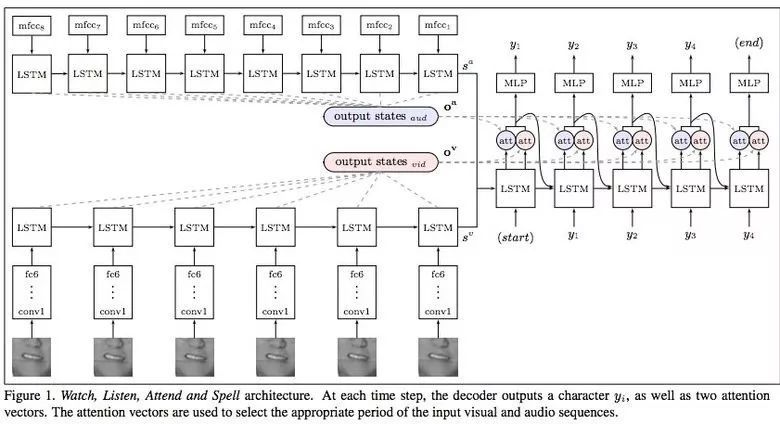
訓練過程中使用不同類型的輸入數據:音頻、視頻、音頻+視頻。即,這是一個「多渠道」模型。

參考閱讀:
如何通過機器學習解讀脣語?DeepMind 要通過 LipNet 幫助機器「看」懂別人說的話
2.3 人工合成奧巴馬:嘴脣動作和音頻的同步
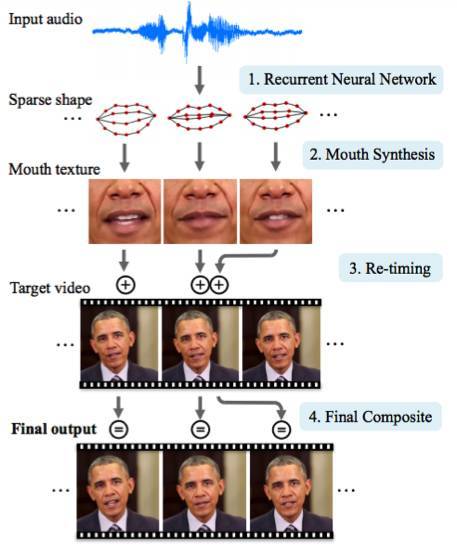
華盛頓大學進行了一項研究,生成美國前總統奧巴馬的嘴脣動作。選擇奧巴馬的原因在於網絡上有他大量的視頻(17 小時高清視頻)。
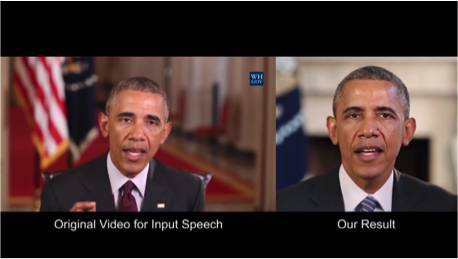
研究者使用了一些技巧來改善該研究的效果。
3. 計算機視覺
3.1. OCR:谷歌地圖與街景
谷歌大腦團隊在其文章中報道瞭如何把新的 OCR(光學字符識別)引擎引入其地圖中,進而可以識別街頭的標誌與商標。


在該技術的發展過程中,谷歌還給出了新的 FSNS(French Street Name Signs),它包含了大量的複雜案例。
爲了識別標誌,網絡最多使用 4 張圖片。特徵通過 CNN 提取,在空間注意力(考慮像素座標)的幫助下縮放,最後結果被饋送至 LSTM。
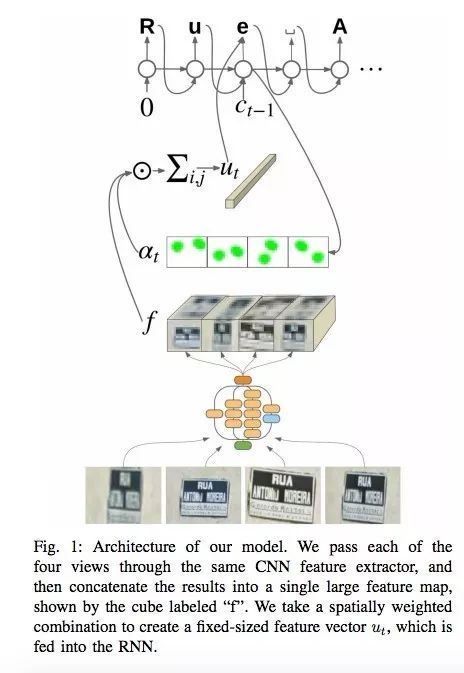
相同方法被用於識別廣告牌上店鋪名稱的任務上(存在大量噪音數據,網絡本身必須關注正確的位置)。這一算法被應用到 800 億張圖片之上。
3.2 視覺推理
視覺推理指的是讓神經網絡回答根據照片提出的問題。例如,「照片中有和黃色的金屬圓柱的尺寸相同的橡膠物體嗎?」這樣的問題對於機器是很困難的,直到最近,這類問題的回答準確率才達到了 68.5%。
爲了更深入地探索視覺推理的思想,並測試這種能力能否輕鬆加入目前已有的系統,DeepMind 的研究者們開發了一種簡單、即插即用的 RN 模塊,它可以加載到目前已有的神經網絡架構中。具備 RN 模塊的神經網絡具有處理非結構化輸入的能力(如一張圖片或一組語句),同時推理出事物其後隱藏的關係。
使用 RN 的網絡可以處理桌子上的各種形狀(球體、立方體等)物體組成的場景。爲了理解這些物體之間的關係(如球體的體積大於立方體),神經網絡必須從圖像中解析非結構化的像素流,找出哪些數據代表物體。在訓練時,沒有人明確告訴網絡哪些是真正的物體,它必須自己試圖理解,並將這些物體識別爲不同類別(如球體和立方體),隨後通過 RN 模塊對它們進行比較並建立「關係」(如球體大於立方體)。這些關係不是硬編碼的,而是必須由 RN 學習——這一模塊會比較所有可能性。最後,系統將所有這些關係相加,以產生場景中對所有形狀對的輸出。

目前的機器學習系統在 CLEVR 上標準問題架構上的回答成功率爲 68.5%,而人類的準確率爲 92.5%。但是使用了 RN 增強的神經網絡,DeepMind 展示了超越人類表現的 95.5% 的準確率。RN 增強網絡在 20 個 bAbI 任務中的 18 個上得分均超過 95%,與現有的最先進的模型相當。值得注意的是,具有 RN 模塊的模型在某些任務上的得分具有優勢(如歸納類問題),而已有模型則表現不佳。
下圖爲視覺問答的架構。問題在經過 LSTM 處理後產生一個問題嵌入(question embedding),而圖像被一個 CNN 處理後產生一組可用於 RN 的物體。物體(圖中用黃色、紅色和藍色表示)是在卷積處理後的圖像上使用特徵圖向量構建的。該 RN 網絡會根據問題嵌入來考慮所有物體對之間的關係,然後會整合所有這些關係來回答問題。
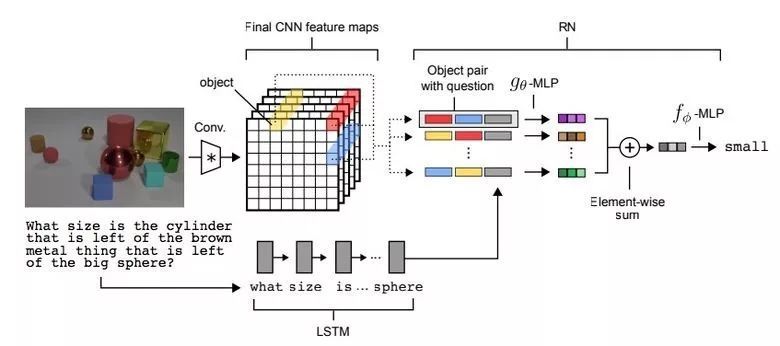
參考閱讀:
關係推理水平超越人類:DeepMind 展示全新神經網絡推理預測技術
3.3 Pix2Code
哥本哈根的一家初創公司 UIzard Technologies 訓練了一個神經網絡,能夠把圖形用戶界面的截圖轉譯成代碼行,成功爲開發者們分擔了部分網站設計流程。令人驚歎的是,同一個模型能跨平臺工作,包括 iOS、Android 和 Web 界面,從目前的研發水平來看,該算法的準確率達到了 77%。
爲了實現這一點,研究者們需要分三個步驟來訓練,首先,通過計算機視覺來理解 GUI 圖像和裏面的元素(按鈕、條框等)。接下來模型需要理解計算機代碼,並且能生成在句法上和語義上都正確的樣本。最後的挑戰是把之前的兩步聯繫起來,需要它用推測場景來生成描述文本。

雖然該工作展示了這樣一種能自動生成 GUI 代碼的潛力系統,但該研究只是開發了這種潛力的皮毛。目前的 Pix2Code 模型由相對較少的參數組成,並且只能在相對較小的數據集上訓練。而構建更復雜的模型,並在更大的數據集上訓練會顯著地提升代碼生成的質量。並且採用各種正則化方法和實現注意力機制(attention mechanism [1])也能進一步提升生成代碼的質量。同時該模型採用的獨熱編碼(one-hot encoding)並不會提供任何符號間關係的信息,而採用 word2vec [12] 那樣的詞嵌入模型可能會有所好轉。因此將圖片轉換爲 UI 代碼的工作仍處於研究之中,目前尚未投入實際使用。
項目地址:https://github.com/tonybeltramelli/pix2code
參考閱讀:
深度學習助力前端開發:自動生成 GUI 圖代碼(附試用地址)
3.4 SketchRNN:教機器畫畫
你可能看過谷歌的 Quick, Draw! 數據集,其目標是 20 秒內繪製不同物體的簡筆畫。谷歌收集該數據集的目的是教神經網絡畫畫。

研究者使用 RNN 訓練序列到序列的變分自編碼器(VAE)作爲編解碼機制。
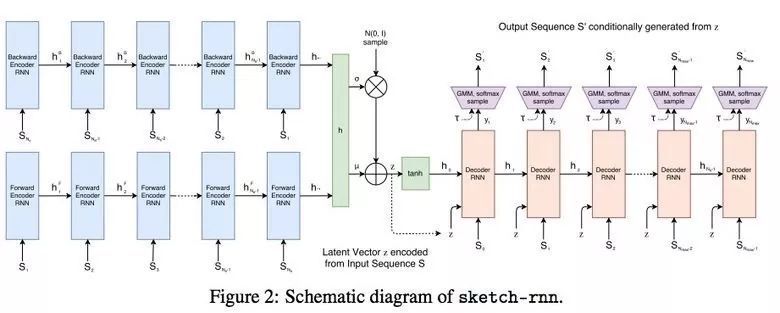
最終,該模型獲取表示原始圖像的隱向量(latent vector)。
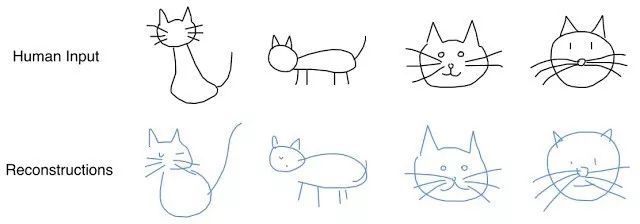
解碼器可從該向量中提取圖畫,你可以改變它,生成新的簡筆畫。

甚至使用向量算術來繪製貓豬(catpig):
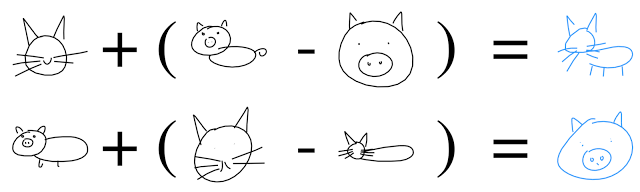
參考閱讀:
谷歌發佈 Quick Draw 塗鴉數據集:5000 萬張矢量圖,345 個類別
3.5 GAN
GAN 是深度學習領域裏的一個熱門話題。目前這種方法大多用於處理圖像,所以本文也主要介紹這一方面。GAN 的全稱爲生成對抗網絡,是 2014 年由 Ian Goodfellow 及其蒙特利爾大學的同事們率先提出的。這是一種學習數據的基本分佈的全新方法,讓生成出的人工對象可以和真實對象之間達到驚人的相似度。
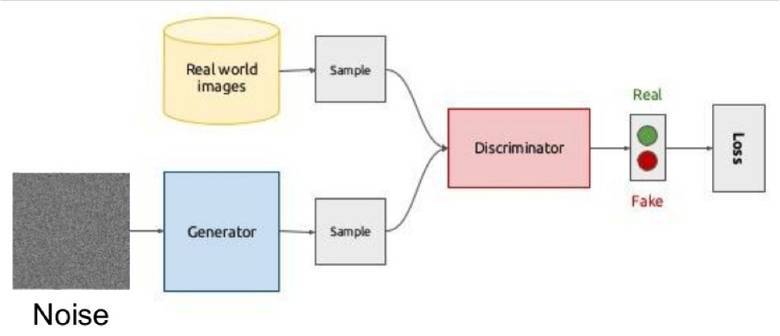
GAN 背後的思想非常直觀:生成器和鑑別器兩個網絡彼此博弈。生成器的目標是生成一個對象(比如人的照片),並使其看起來和真的一樣。而鑑別器的目標就是找到生成出的結果和真實圖像之間的差異。鑑別器通常會從數據集中給出圖像用於對比。
由於很難找出兩個網絡之間的平衡點,訓練通常難以連續進行。大多數情況下鑑別器會獲勝,訓練陷入停滯。儘管如此,由於鑑別器的設計可以幫助我們從損失函數設定這樣的複雜問題中解決出來(例如:提升圖片質量),所以 GAN 獲得了衆多研究者的青睞。
典型的 GAN 訓練結果——臥室和人臉。


在此之前,我們通常會考慮使用自編碼器(Sketch-RNN),讓其將原始數據編碼成隱藏表示。這和 GAN 中生成器所做的事情一樣。
你可以在這個項目中(http://carpedm20.github.io/faces/)找到使用向量生成圖片的方法。你可以自行嘗試調整向量,看看生成的人臉會如何變化。

這種算法在隱空間上同樣適用:「一個戴眼鏡的男人」減去「男人」加上「女人」就等於「一個戴眼鏡的女人」。

參考閱讀:
深入淺出:GAN 原理與應用入門介紹
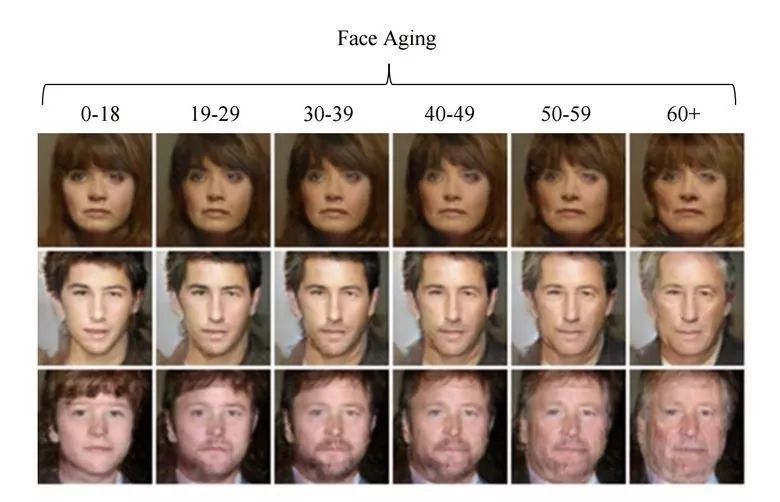
3.6 使用 GAN 改變面部年齡
如果在訓練過程中獲得一個可控制的隱向量參數,我們就可以在推斷階段修改這個向量以控制圖像的生成屬性,這種方法被稱爲條件 GAN。
論文 Face Aging With Conditional Generative Adversarial Networks 的作者使用在 IMDB 數據集上預訓練模型而獲得年齡的預測方法,然後研究者基於條件 GAN 修改生成圖像的面部年齡。
參考閱讀:
解讀 | 藝術家如何藉助神經網絡進行創作?
3.7 專業攝影作品
谷歌已經開發了另一個非常有意思的 GAN 應用,即攝影作品的選擇和改進。開發者在專業攝影作品數據集上訓練 GAN,其中生成器試圖改進照片的表現力(如更好的拍攝參數和減少對濾鏡的依賴等),判別器用於區分「改進」的照片和真實的作品。
訓練後的算法會通過 Google Street View 搜索最佳構圖,獲得了一些專業級的和半專業級的作品評分。
參考閱讀:
谷歌「虛擬攝影師」:利用深度學習生成專業級攝影作品
3.8 pix2pix
伯克利人工智能研究室(BAIR)在 2016 年非常引人注目的研究 Image-to-Image Translation with Conditional Adversarial Networks 中,研究人員解決了圖像到圖像的生成問題。例如需要使用衛星圖像創建地圖,或使用素描創建逼真的目標紋理等。
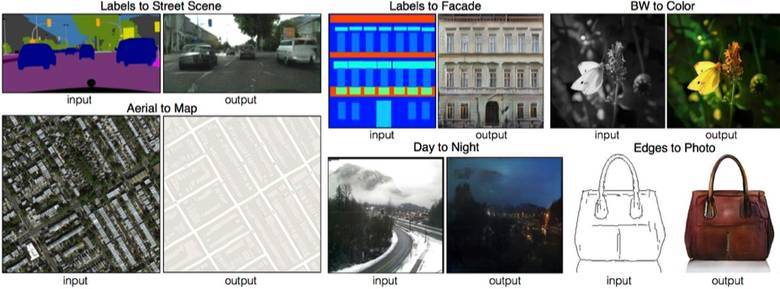
這裏有另一個非常成功的條件 GAN 應用案例。在該情況下,條件將變爲整張圖像。此外,UNet 在圖像分割中十分受歡迎,經常用於生成器的體系結構,且該論文使用了新型 PatchGAN 分類器作爲處理模糊圖像的判別器。
該論文的作者還發布了他們網絡的在線演示:https://affinelayer.com/pixsrv/
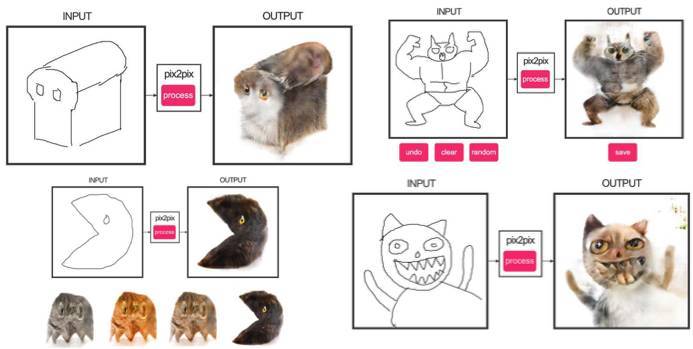
源代碼:https://github.com/phillipi/pix2pix
參考閱讀:
教程 | 你來手繪塗鴉,人工智能生成「貓片」:edges2cats 圖像轉換詳解
3.9 CycleGAN
爲了應用 Pix2Pix,我們需要包含了不同領域圖像對的數據集。收集這樣的數據集並不困難,但對於更復雜一點的轉換目標或風格化目標等操作,原則上是找不到這樣的目標對。
因此,Pix2Pix 的作者爲了解決這樣的問題提出了在不同圖像領域之間轉換而不需要特定圖像對的 CycleGAN 模型,原論文爲《Unpaired Image-to-Image Translation》。

該論文的主要想法是訓練兩對生成器-判別器模型以將圖像從一個領域轉換爲另一個領域,在這過程中我們要求循環一致性。即在序列地應用生成器後,我們應該得到一個相似於原始 L1 損失的圖像。因此我們需要一個循環損失函數(cyclic loss),它能確保生成器不會將一個領域的圖像轉換到另一個和原始圖像完全不相關的領域。
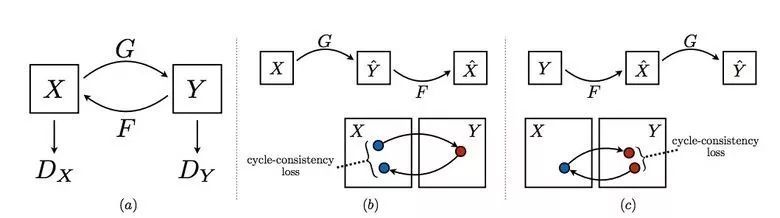
這個方法允許我們學習將馬映射到斑馬。

這樣的轉換通常是不穩定的,並且經常創建一些不成功的案例:

源代碼:https://github.com/junyanz/CycleGAN
參考閱讀:
學界 | 讓莫奈畫作變成照片:伯克利圖像到圖像翻譯新研究
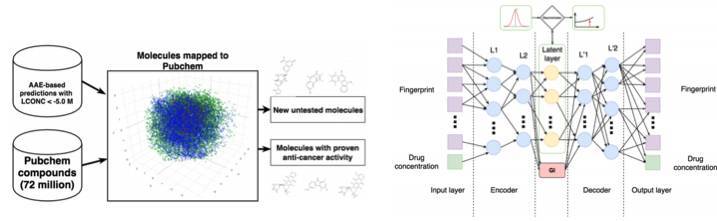
3.10 腫瘤分子學的進展
機器學習正在幫助改善醫療的手段,它除了在超聲波識別、MPI 和診斷等方面的應用,還能尋找對抗癌症的性藥物。
簡單來說,在對抗自編碼器(AAE)的幫助下,我們可以學習藥物分子的潛在表徵,並用來搜索新的藥物結構。該項研究中,研究者發現了 69 個分子,且有一半的分子可用來治療癌症和其它一些比較嚴重的疾病。
參考閱讀:
深入淺出:GAN 原理與應用入門介紹
3.11 對抗性攻擊
對抗性樣本這一領域也有非常大的活力,研究者希望找到這種令模型不穩定的因素而提升識別性能。例如在 ImageNet 中,訓練的模型在識別加了一些噪點的樣本會完全識別錯誤,這樣加了噪點的圖像可能在我們人眼看來是沒有問題的。這一問題展現在下圖中,熊貓的圖像加了一點噪聲就會被錯誤識別爲長臂猿。
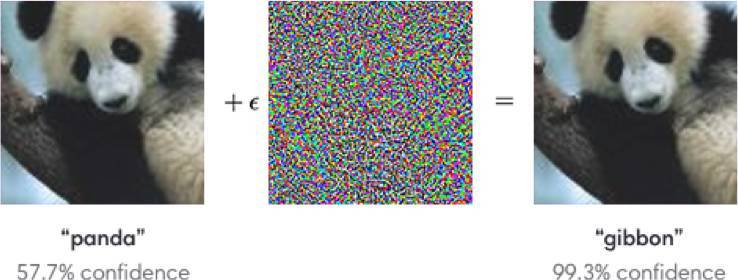
Goodfellow et al. (2014b) 表明,出現這些對抗樣本的主要原因之一是模型過度線性化。神經網絡主要是基於線性模塊而構建的,因此它們實現的整體函數被證明是高度線性的。雖然這些線性函數很容易優化,但如果一個線性函數具有許多輸入,那麼它的值可以非常迅速地改變。如果我們用 ϵ 改變每個輸入,那麼權重爲 w 的線性函數改變可以達到 ϵ∥w∥_1,如果 w 的維度較高,那麼這會是一個非常大的數值。對抗訓練通過鼓勵網絡在訓練數據附近的局部區域恆定來限制這一高度敏感的局部線性行爲。這可以被看作是一種明確地向監督神經網絡引入局部恆定先驗的方法。
下面一個例子表示特殊的眼鏡可以欺騙人臉識別系統,所以在訓練特定的模型時,我們需要考慮這種對抗性攻擊並使用對抗性樣本提高模型的魯棒性。

這種使用符號的方法也不能被正確地識別。

參考閱讀:
學界 | OpenAI 探討人工智能安全:用對抗樣本攻擊機器學習
4 強化學習
強化學習(RL)或使用了強化機制的學習也是機器學習中最有趣和發展活躍的方法之一。
該方法的本質是在一個根據經驗給予獎勵(正如人類的學習方式)的環境中學習智能體的成功行爲。
RL 在遊戲、機器人和系統控制(例如,交通)中被廣泛應用。
當然,每個人都已經聽說了 AlphaGo 在遊戲中擊敗過多個頂尖專業選手。研究者使用 RL 訓練 AlphaGo 的過程是:讓機器通過自我對弈提升決策能力。
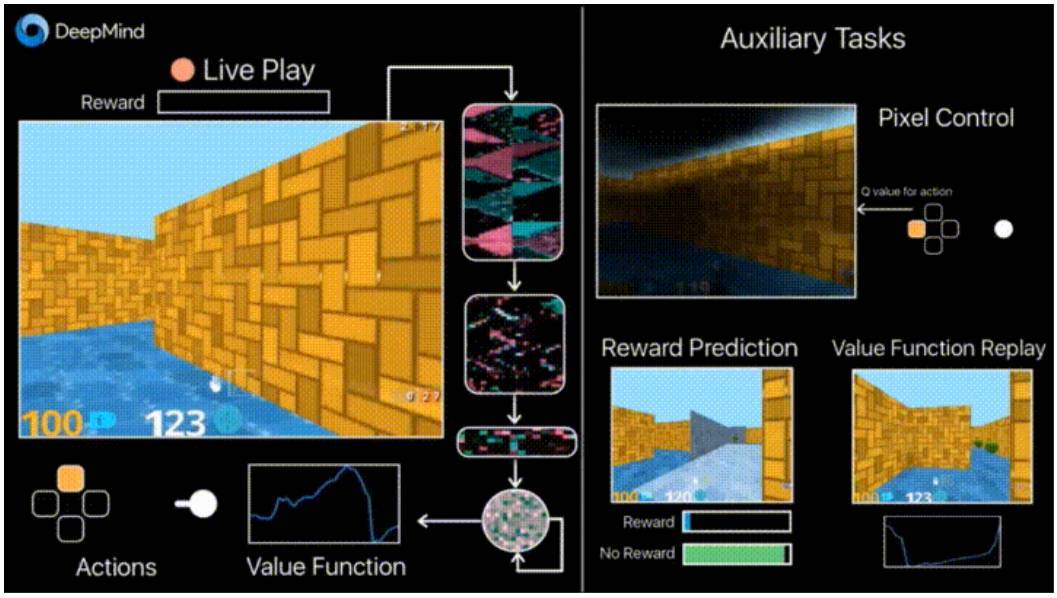
4.1 結合非受控輔助任務的強化訓練
去年,DeepMind 通過使用 DQN 玩電子遊戲取得了超越人類的表現。最近,人們已經開發出了能讓機器玩更加複雜的遊戲(如 Doom)的算法。
大多數研究關注於學習加速,因爲學習智能體與環境交互的經驗需要在現代 GPU 上執行很長時間的訓練。
DeepMind 的博客(https://deepmind.com/blog/reinforcement-learning-unsupervised-auxiliary-tasks/)中報告了引入附加損失(輔助任務)的辦法,例如預測幀變化(像素控制)使智能體更充分地理解動作的後果,可以顯著加快學習過程。
參考閱讀:
突破 | DeepMind 爲強化學習引入無監督輔助任務,人工智能的 Atari 遊戲水平達到人類的 9 倍
4.2 學習機器人
OpenAI 對在虛擬環境中訓練智能體進行了積極的研究,相比在現實世界中進行實驗要安全得多。
在其中一個研究中(https://blog.openai.com/robots-that-learn/),他們證明了一次性學習(one-shot learning)是可能實現的:在 VR 中的一個人展示如何執行任務,並且算法只需要一次展示就能學會然後在實際條件下將其重現。

如果只有人類有這個能力就好了。:)
參考閱讀:
學界 | OpenAI 推出機器人新系統:機器可通過 VR 演示自主學習新任務
4.3 學習人類的偏好
這是 OpenAI(https://blog.openai.com/deep-reinforcement-learning-from-human-preferences/)和 DeepMind 都曾研究過的課題。基本目標是智能體有一個任務,算法爲人類提供兩個可能的解決方案,並指出那個更好。該過程需要重複迭代,並且算法接收來自學習如何解決問題的人類的 900 比特大小的反饋(二進制標記)。
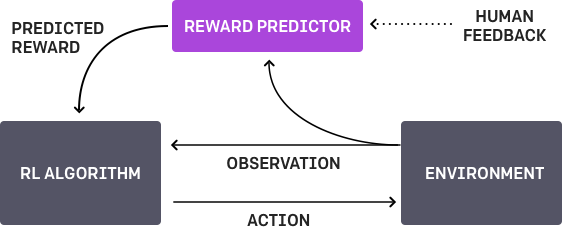
一如既往,人類必須謹慎判斷,思考他教給機器究竟是什麼。例如,評估器得出算法確實想要拿到某個物體,但實際上,人類只是想進行一次模擬實驗。
參考閱讀:
OpenAI 聯合 DeepMind 發佈全新研究:根據人類反饋進行強化學習
4.4 在複雜環境中的運動
這是 DeepMind 的另一項研究(https://deepmind.com/blog/producing-flexible-behaviours-simulated-environments/)。爲了教會機器人執行復雜的行爲(行走、跳躍,等),甚至達到類似人體的動作,你需要非常重視損失函數的選擇,以獲得想要的行爲。然而,讓算法自身通過簡單的獎勵機制學習複雜的行爲或許會有更好的效果。
爲了達到這個目標,研究者通過構建一個包含障礙物的複雜環境教智能體(人體模擬器)執行復雜的動作,結合簡單的獎勵機制提高動作質量。

可以通過視頻查看研究取得的令人印象深刻的結果。
最後,我給出 OpenAI 近日發佈的應用強化學習的算法的鏈接(https://github.com/openai/baselines)。這個解決方案比標準的 DQN 方法更好。
參考閱讀:
學界 | DeepMind論文三連發:如何在仿真環境中生成靈活行爲
5 其它
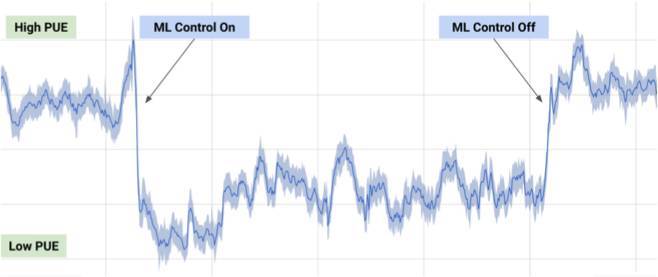
5.1 數據中心冷卻系統
在 2017 年 7 月,谷歌報告稱他們利用 DeepMind 的機器學習研究成果降低了數據中心的能耗。
基於來自數據中心的幾千個傳感器的信息,谷歌開發者訓練一個神經網絡集成預測能量利用效率(PUE)以及更高效的數據中心管理方法。這是機器學習中非常令人印象深刻和重要的實際應用案例。
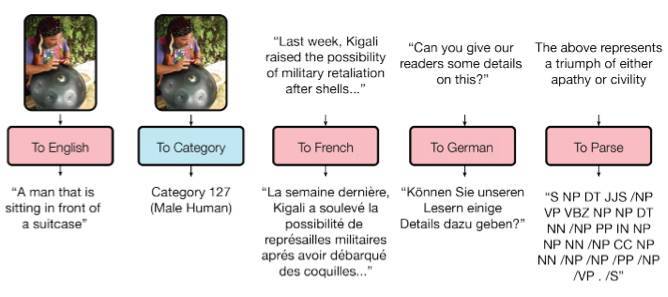
5.2 通用模型
如你所知,已訓練模型的任務遷移性能很差,因爲每個模型都是爲特定的任務而設計的。谷歌大腦的一篇論文(https://arxiv.org/abs/1706.05137)在通用模型的研究上跨出了一小步。
研究者訓練了一個模型,可以執行 8 個不同領域(文本、語音和圖像)的任務。例如,不同語言的翻譯、文本解析,以及圖像、語音識別。
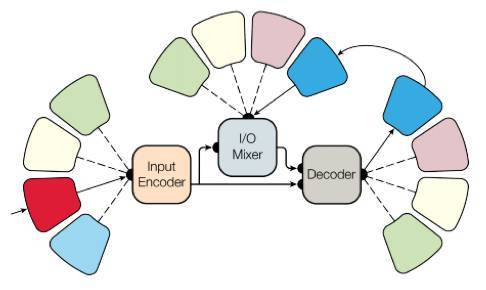
爲了達到這個目的,他們使用多種不同的模塊構建了一個複雜的網絡架構以處理不同的輸入數據並生成結果。編碼器/解碼器模塊包含三種類型:卷積、注意和 MoE(https://arxiv.org/abs/1701.06538)。
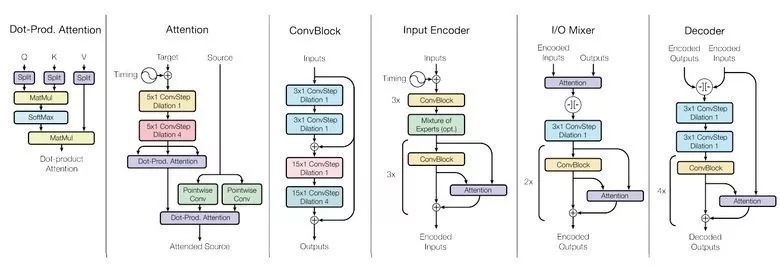
他們幾乎得到了完美的模型(作者並沒有細調超參數)。
模型中存在不同領域知識的遷移,即,相比使用大量數據訓練的任務(無遷移),該模型能獲得幾乎相同的性能。並且這個模型在小數據任務上表現得更好(例如,文本解析)。
不同任務所需的模塊之間並不會互相干擾,有時甚至能互相輔助,例如,MoE 可以輔助 ImageNet 圖像識別任務。
模型的 GitHub 地址:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/multimodel.py
參考閱讀:
一個模型庫學習所有:谷歌開源模塊化深度學習系統 Tensor2Tensor
5.3. 一小時訓練 ImageNet
Facebook 在其博文中告訴我們其工程師能夠用 1 小時的時間通過 Imagenet 教會 ResNet-50 模型,不過其實現需要 256 塊 GPU (Tesla P100)。
他們通過 Gloo 和 Caffe2 實現分佈式學習。爲了更有效,採用大批量的學習策略很有必要:梯度平均、特定學習率等。
結果,當從 8 塊 GPU 擴展到 256 塊時,效率可高達 90%。現在,Facebook 可以更快地進行實驗。
參考閱讀:
Facebook「1小時訓練ImageNet」論文與MXNet團隊發生爭議,相關研究介紹
6. 新聞
6.1. 自動駕駛
自動駕駛領域正密集地發展,測試也在積極地開展。從最近事件中我們注意到英特爾收購 MobilEye,Uber 從谷歌剽竊自動駕駛技術的醜聞,以及首個自動駕駛死亡案例等等。
這裏我提醒一件事:谷歌 Waymo 推出了 beta 版。谷歌是該領域的先驅者,可以假定他們的技術很好,因爲其自動駕駛汽車裏程已超過 300 萬英里。
更近的事件則有自動駕駛汽車已在美國所有州允許上路測試。
6.2. 醫療
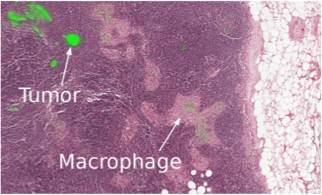
就像我說的,現代機器學習正開始應用於醫療。比如,谷歌與某醫療中心展開合作提升診斷。DeepMind 甚至還爲此成立了一個獨立部門。
在今年的 Data Science Bowl 上,有一個獎金高達 100 萬美元的競賽,根據標註圖像預測一年之中的肺癌情況。
6.3. 投資
正如之前的大數據,機器學習當下也涌入了大量資本。中國在 AI 領域的投資高達 1500 億美元,從而成爲行業領導者之一。
相比之下,百度研究院擁有 1300 名員工,而 Facebook FAIR 則只有 80 名。在今年閉幕的 KDD 2017 上,阿里巴巴介紹了其參數服務器鯤鵬,它帶有萬億個參數,並使得運行 1000 億個樣本成爲常規任務。

人工智能仍處於起步階段,入門學習機器學習永遠不嫌晚。不管怎樣,所有開發者會慢慢用起機器學習,這項技術會成爲程序員的必備技能之一,就像現在每個人都會使用數據庫一樣。
原文鏈接:https://blog.statsbot.co/deep-learning-achievements-4c563e034257