選自Medium
作者:Alex Honchar
2017 年是機器學習領域最有成效、最具創意的一年。現在已經有很多博文以及官方報道總結了學界和業界的重大突破。本文略有不同,Alex Honchar在Medium發文,從研究者的角度分享機器學習明年發展的走向。我們對此行了編譯和整理。
本文的預測基於 2012 年以來我關注的學術界和科技巨頭實驗室的研究思路演變。我所選擇的領域,從我的觀點來看,都多多少少尚處於發展的初級階段,但是已經爲研究做足了準備,且在 2018 年可能獲得良好的結果,並在 2019-2020 年能投入實際應用。請閱讀吧!
開放科研
來自其他學科的學術界人士正在自問:
人工智能研究的進展爲何如此之快?
首先,在機器學習領域,大多數文章並不在期刊中發表,而是以即時 arXiv 預印本的形式提交到會議論文中。因此,人們無需在論文提交之後等待數月,就能很快地看到最新進展。第二,我們並不發表「順勢療法」的文章:如果你想讓文章被髮表的文章,必須確保在文中展現最先進的技術,或是展示和現有最先進技術性能相近的新方法。而且,新方法必須在不同的指標中有所改進——其中包括速度、準確率、並行執行效率、數學證明的質量、處理不同大小數據集的能力等——即大大提高整體質量。最後,所有的主要文章都是開源實現的,因此別人可以使用你的代碼進行二次檢查甚至改進。
以「博客」爲形式的出版新格式,是當代人工智能研究中最棒的事情之一。我們可以關注各種博客,比如:
DeepMind blog(https://deepmind.com/blog/)
OpenAI blog(https://blog.openai.com/)
Salesforce blog(https://www.salesforce.com/products/einstein/ai-research/)
IBM Research blog(http://www.research.ibm.com/ai/)
在其中,結果得以清晰展現,所以即使是不諳於研究的人也能看出這有多「酷」。就個人而言,我非常喜歡 Distill Pub(https://distill.pub/)。
Distill Pub 是一本真正的科學期刊,不過文章看起來更像博文,有着很棒的插圖。當然,這需要大量的工作,但是現在只有這種研究形式才能吸引更多的人——基本上,你可以同時向以下三種人同時展現成果:
研究者,他們可以評估你的數學成果;
開發者,他們可以從可視化圖像中瞭解你的研究意圖;
投資者,他們可以瞭解你的研究,懂得它該如何應用。
我相信,在接下來的幾年裏,最佳研究就是這樣發佈的。如果科技巨頭正在這麼做——你不妨也試試!
無平行語料庫的語言模型
讓我們考慮一個簡單的問題:
使用 50 本阿拉伯語書、16 本德語書、7 本烏克蘭語書,學習阿拉伯語到烏克蘭語的翻譯,以及烏克蘭語到德語的翻譯。
你能做到嗎?我打賭你不行。但是現在機器已經可以做到。2017 年,兩篇突破性的文章發表了,它們是「Unsupervised Machine Translation Using Monolingual Corpora Only」和「Unsupervised Neural Machine Translation」。基本上,研究想法是訓練一些通用人類語言表達空間,其中將相似的句子連接在一起。這個想法並不新鮮,但是現在,它卻能在無顯式德語-阿拉伯語句子對的情況下實現翻譯:
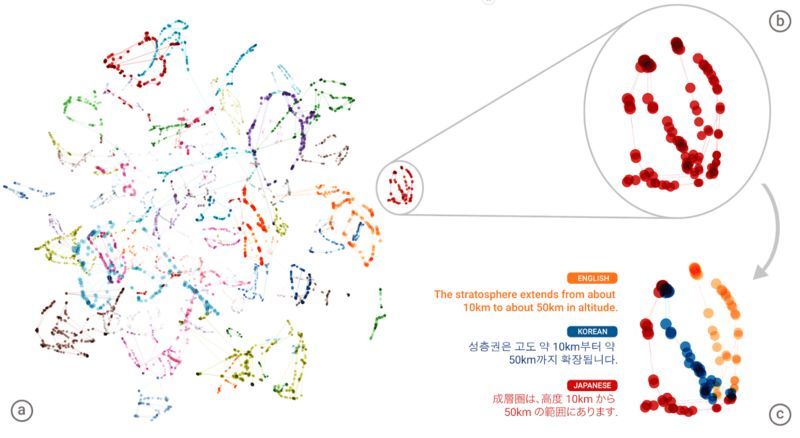
多語種表徵空間的圖示
這些文章作者表示,翻譯質量可以在少量監督下得到大幅上升。我預計這項研究將一直持續到明年夏天,並在 2018 年年底得到產品應用。而這種有監督卻並非傳統意義的監督學習的總體思路,可以並且必定會擴展到其他領域。
更好地理解視頻
現在計算機視覺系統已在視覺方面超越人類。這要歸功於不同深度、廣度和連接密集度的網絡:
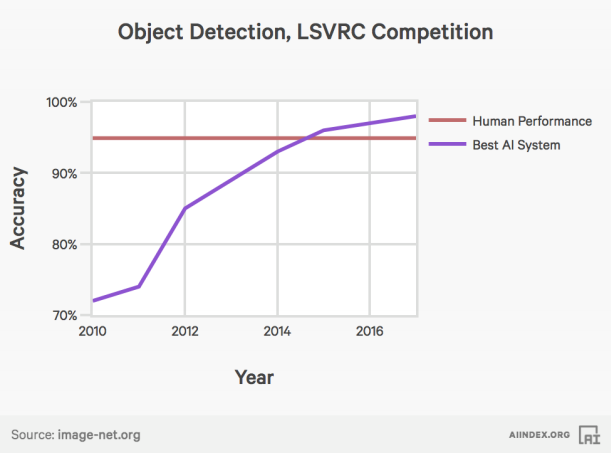
來源: http://aiindex.org/2017-report.pdf
但是現在,我們只在靜止圖像上進行了性能基準測試。這很不錯,但是我們習慣於用眼睛觀察圖像的序列、視頻、或是真實世界的改變——所以,我們需要將這些計算機視覺的成果轉化到視頻領域,並使其能工作得和在靜止圖片中一樣快。
老實說,在靜止的圖像中檢測 1000 個物體簡直是太無聊了。
在最近的 NIPS 2017 中,發表了關於下一幀預測的有趣結果(Temporal Coherency based Criteria for Predicting Video Frames using Deep Multi-stage Generative Adversarial Networks),我們可以看到這與用 RNN 網絡進行文本生成的聯繫,其中預測下一個詞的訓練的神經網絡可作爲一種語言模型。此外,還發布了關於從視頻中進行表徵學習的結果(Unsupervised Learning of Disentangled Representations from Video)。以下是可供使用的數據集,以改善注意力模型、將光流概念添加到視頻中、使用循環架構以使其在大型視頻中更加高效:
Moments in Time(http://moments.csail.mit.edu/)
Youtube-8M(https://research.google.com/youtube8m/)
多任務/多模式學習
當我觀察周圍的世界時,不僅看到了移動的圖像:我聽到聲音、感受到外界的溫度、感知一些情緒。這說明我能從不同的來源「觀察」這個世界,我想稱之爲「多模態」。而且,即使我只「觀察」一種形式,比如聽到別人的聲音——我不會像語音識別系統那樣只是將其翻譯爲文字,我還能瞭解說話人的性別、年齡、以及說話人的感情——我在同一時刻了解了很多不同的東西。我們希望機器也有相同的能力。
人類能夠從一個圖像中得到成百個結論,爲什麼機器做不到呢?
目前並沒有很多關於解決多任務問題的數據集,通常在創建額外的任務之前,我們將這些數據集用作正則項。但是,最近牛津大學在多模態圖像識別方面發佈了很不錯的數據集,向人們提出了挑戰性的問題。我希望明年在語音應用方面會出現更多的數據集和結果(例如年齡、聲音),詳見「Visual Decathlon Challenge」(http://www.robots.ox.ac.uk/~vgg/decathlon/)。
人類能處理 10 餘種模態,爲什麼機器不能呢?
這是一個令人震驚的環境,在其中你能教你的機器人在一個接近全真的房間內去看、聽、感受所有事。參見「HoME: a Household Multimodal Environment」(https://home-platform.github.io/)
我們能同時做這些事情嗎?
如果我們能構建令人震驚的的多模態-多任務模型,那麼就可以根據完全不同的輸入來解決不同的任務——Google Reasearch 就做到了。他們構建了一個可將圖片和文本作爲輸入的體系結構,並用單個神經網絡解決圖像識別、圖像分割、文本翻譯、文本解析等問題。這不算是解決這類問題最聰明的方法,但這是一個很好的開始!
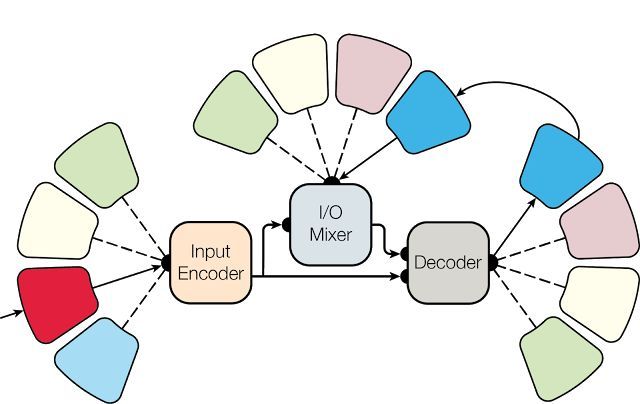
來源:https://research.googleblog.com/2017/06/multimodel-multi-task-machine-learning.html
參考閱讀:
強化學習:還在遊戲領域
強化學習是令我最興奮、也最懷疑的領域之一——強化學習可以在自我博弈、不知道任何規則的情況下學習複雜的遊戲,並在圍棋、象棋和牌類等遊戲中取勝。但是同時,我們幾乎看不到強化學習在真實世界中的應用,最多也只是一些 3D 玩具人物在人造環境當中攀爬或是移動機器手臂。這也就是爲什麼我認爲明年強化學習還會繼續發展。我認爲,明年將會有兩個重大突破:
Dota 2(https://blog.openai.com/dota-2/)
星際爭霸 2(https://deepmind.com/blog/deepmind-and-blizzard-open-starcraft-ii-ai-research-environment/)
是的,我非常確定,Dota 和 星際爭霸 2 的人類冠軍將被 OpenAI 和 DeepMind 機器人所擊敗。目前已經可以使用 OpenAI Gym 環境(https://github.com/alibaba/gym-starcraft)自己玩星際穿越 2。
看看 OpenAI 機器人是怎麼玩 Dota 遊戲的:https://www.youtube.com/watch?v=x7eUx_Ob4os
對於那些沒有玩多少遊戲的研究人員而言,可能想改進一些 OpenAI 所獲得的的有趣結果:競爭性的自我博弈、從其他模型中學習、學習溝通和合作,以及 Facebook 引導的學習談判。我希望 1-2 年內能在聊天機器人中看到上述結果,但是目前還需要完成更多研究。
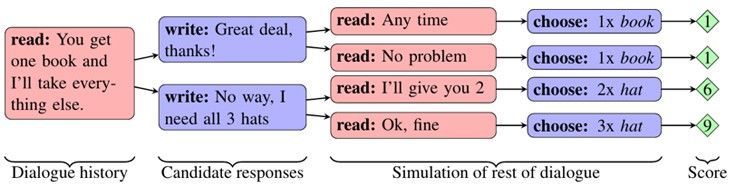
上圖表明 Facebook 機器人正在學習談判(來源:https://code.facebook.com/posts/1686672014972296/deal-or-no-deal-training-ai-bots-to-negotiate/)
參考閱讀:
人工智能需要自我解釋
使用深度神經網絡當然很贊。你能憑藉層數、連接密度和在 ImageNet 上 0.05 的改善來自我吹噓,或者可以將其應用到醫療放射學中。但是,如果神經網絡無法實現自我解釋,我們怎麼能真正依賴它呢?
我想知道的是,爲什麼我的神經網絡會認爲圖像中出現的是一隻狗,或者爲什麼它認爲有一個人在笑,又何以判斷我患有一些疾病。
但不幸的是,深度神經網絡即便能給出準確的結果,卻無法給我們上述問題的答案。
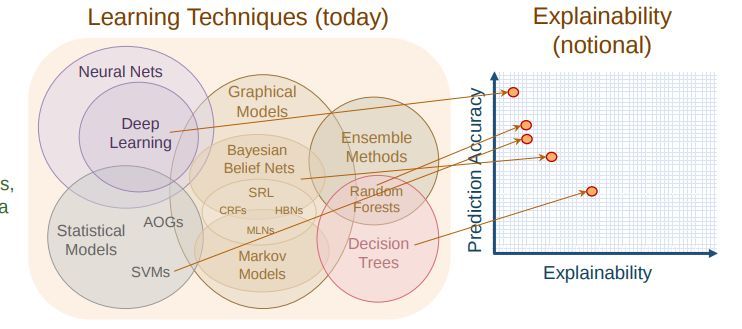
圖片來自演講展示「DARPA Explainable AI—Performance vs. Explainability」
即使我們已經有了一些成功的應用,比如:
從深度網絡提取基於樹的規則:https://www.ke.tu-darmstadt.de/lehre/arbeiten/master/2015/Zilke_Jan.pdf
卷積神經網絡層的可視化:http://cs231n.github.io/understanding-cnn/
以及一些更加有難度的想法如:
隱概念:http://www-nlpir.nist.gov/projects/tvpubs/tv14.papers/sri_aurora.pdf
與-或圖訓練:http://www.cnbc.cmu.edu/~tai/microns_papers/zhu_AOTpami.pdf
生成視覺解釋:https://arxiv.org/pdf/1603.08507.pdf
然而,這個問題仍然是開放性的。

來源:https://arxiv.org/pdf/1603.08507.pdf
最近的當前最佳 InterpretNet:
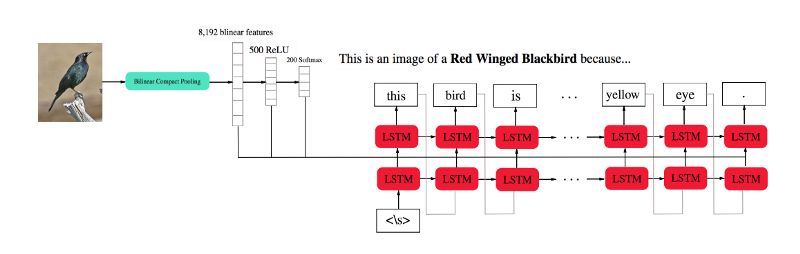
來源: https://arxiv.org/pdf/1710.09511.pdf
我們還應關注貝葉斯方法,它可以跟蹤預測的準確性。對於已有的神經網絡,這在明年將是機器學習中一個非常熱門的話題。
參考閱讀:
人工智能安全:不再是小問題
在人工智能可解釋性之後,要解決的第二個重要任務就是當代機器學習算法的脆弱性——他們很容易被對抗樣本、預測 API 等愚弄:
Hype or Reality? Stealing Machine Learning Models via Prediction APIs(https://blog.bigml.com/2016/09/30/hype-or-reality-stealing-machine-learning-models-via-prediction-apis/)
Attacking Machine Learning with Adversarial Examples(https://blog.openai.com/adversarial-example-research/)
對於這些事,Ian Goodfellow 有一個名爲 CleverHans(http://www.cleverhans.io/security/privacy/ml/2017/06/14/verification.html)的驚人創舉。關於數據的隱私和加密數據的訓練,請看看牛津大學博士生的精彩文章「Building Safe A.I.」(https://iamtrask.github.io/2017/03/17/safe-ai/),其中展示了構建簡單同態加密神經網絡的例子。
我們應當保護人工智能的輸入(私人數據)、內在結構(使其免於攻擊),以及它所習得的東西(其行動的安全性)。
以上所述仍非如今人工智能所面臨的全部問題。從數學的角度來看(特別是在強化學習中),算法仍然不能安全地探索環境,這也就意味着如果我們現在讓物理機器人自由地探索世界,他們仍然不能在訓練階段完全避免錯誤或不安全的行爲;我們仍然不能使我們的模型適用於新的分佈和情況——例如,用在真實世界中的對象中訓練的神經網絡識別繪製的對象仍然很困難;此外還有許多問題,你可以在如下文章中查看:
Concrete AI Safety Problems(https://blog.openai.com/concrete-ai-safety-problems/)
Specifying AI safety problems in simple environments | DeepMind(https://deepmind.com/blog/specifying-ai-safety-problems/)
優化:超越梯度,還能做什麼?
我是優化理論的忠實粉絲,而且我認爲 2017 年最佳的優化方法發展綜述是 Sebastian Ruder 所撰寫的「Optimization for Deep Learning Highlights in 2017」。這裏,我想回顧一下改進一般隨機梯度下降算法+反向傳播的方法:
和其他方式以避免深度學習中高成本的鏈式法則(https://deepmind.com/research/publications/understanding-synthetic-gradients-and-decoupled-neural-interfaces/)
,可用於強化學習、不可微損失函數問題,可能避免陷入局部最小值(https://blog.openai.com/evolution-strategies/)
,學習率和批調度(http://ruder.io/deep-learning-optimization-2017/)
——將優化問題本身視爲學習問題(http://bair.berkeley.edu/blog/2017/09/12/learning-to-optimize-with-rl/)
不同空間的優化——如果我們可以在 Sobolev 空間中訓練網絡呢?(https://papers.nips.cc/paper/7015-sobolev-training-for-neural-networks.pdf)
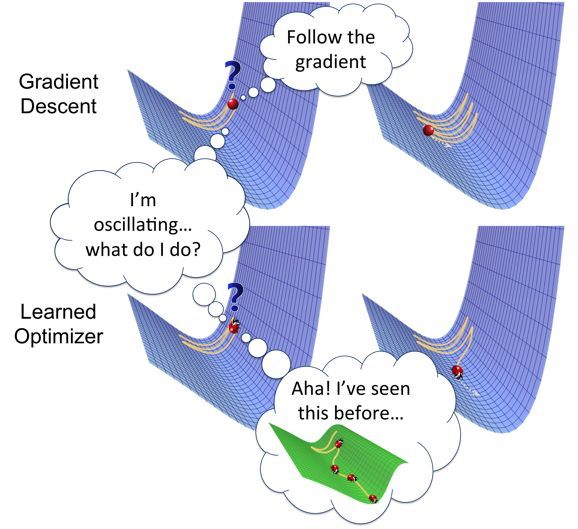
來源:http://bair.berkeley.edu/blog/2017/09/12/learning-to-optimize-with-rl/
我相信,通過進化方法解決不可微函數優化問題帶來的進展,強化學習和學習優化技術將幫助我們更有效地訓練人工智能模型。
3D 和圖形的幾何深度學習
在 NIPS 的一份演說「Geometric Deep Learning on Graphs and Manifolds」之前,我並沒有真正意識到這個話題的重要性。當然,我明白現實數據比 R^d 更困難,實際上數據和信息本身就有自己的幾何和拓撲結構。三維物體可以被看作點雲,但事實上它是一個表面(流形),一個特別是在運動中具有自身局部和全局數學(微分幾何)的形狀。或者,考慮一下圖形,你當然可以用一些鄰接矩陣的形式描述它們,但是你會忽視一些你真想看作圖形的局部結構或圖形(例如分子)。其他多維的對象,例如圖像、聲音、文本也可以且必須從幾何角度考慮。我相信,我們會從這個領域的研究中得到許多有趣的見解。讓我們堅信:
所有數據都有着我們無法避免的局部和全局幾何結構。
查看下列連接,以獲取更多細節:
Geometric Deep Learning(http://geometricdeeplearning.com/)
結論
我本來還可以談談知識表示、遷移學習、單樣本學習、貝葉斯學習、微分計算等領域,但是說實話,這些領域在 2018 年還沒有充足的準備能有巨大的發展。貝葉斯學習中,我們仍然沒有解決抽樣的數學問題。微分計算聽起來很酷,但有何用?神經圖靈機、DeepMind 的差分神經計算機——又該何去何從?知識表示學習已是所有深度學習算法的核心,已經不值得再寫它了。單樣本學習和少樣本學習也不是真正的已開發領域,而且目前也沒有明確的指標或數據集。我希望本文提到的主題能在一些熱門或成熟的領域發展,並且在 2019-2020 年能有大量實際應用。
另外,我想分享一些重要的實驗室,從中你可以瞭解最新的研究新聞:
OpenAI(http://openai.com/)
DeepMind(https://deepmind.com/)
IBM AI Research(http://www.research.ibm.com/ai/)
Berkley AI(http://bair.berkeley.edu/)
Stanford ML Group(https://stanfordmlgroup.github.io/)
Facebook Research(https://research.fb.com/)
Google Research(https://research.googleblog.com/)
原文鏈接:https://blog.goodaudience.com/ai-in-2018-for-researchers-8955df0caaf9