選自arXiv
參與:朱乾樹、蔣思源
斯坦福視覺與學習實驗室與加州大學提出神經任務編程(NTP),它可以將指定任務作爲輸入,並遞歸地將該任務分解成更精細的具體子任務而進行學習。

論文地址:https://arxiv.org/abs/1710.01813
摘要: 在本篇論文中,我們提出一個新的稱爲神經任務編程(Neural Task Programming/NTP)的機器人學習框架,它支持從演示和神經網絡程序歸納中進行 few-shot 學習。NTP 以指定任務(例如,任務的視頻演示)作爲輸入,並將這一任務遞歸地分解成更精細的具體子任務。這些特定子任務被饋送到分級神經網絡程序(hierarchical neural program),其中底層程序是與環境交互的可調用子程序。我們通過三個機器人任務來檢驗我們的方法。NTP 通過顯式分層結構和組合結構的序列任務實現了模型的強泛化能力。實驗結果表明,NTP 學習可以通過不斷增加的長度,可變拓撲(variable topologies)和多變的目標來應用於未知的任務。
複雜操作任務中的自主性,如目標分類、裝配和整理,需要通過機器人與環境之間的長時間交互進行一系列的決策。在複雜的任務中進行規劃,適應新任務目標和初始條件絕對是是機器人領域長期面臨的挑戰 [6,13]。
實驗表明 NTP 囊括了三種任務結構的變化:
1)任務長度:因問題大小的增加而改變步數(例如,具有更多的傳送對象);
2)任務拓撲:靈活的排列和子任務的組合達到相同的終極目標(例如,以不同的順序操縱對象);
3)任務語義:不同的任務定義和完成條件(例如,將對象放入不同的容器)
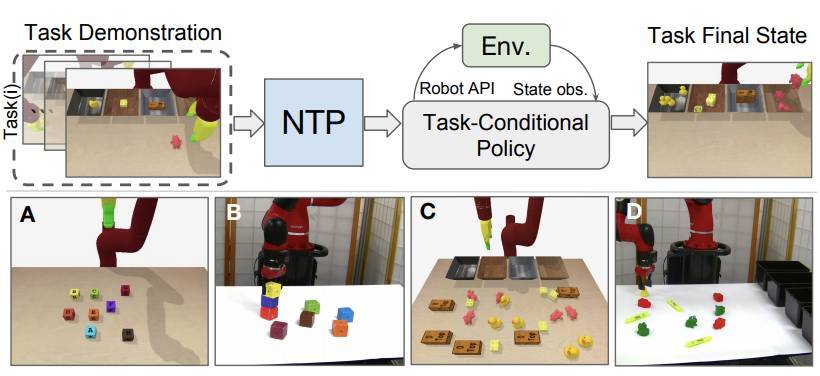
圖 1:(上)測試時,NTP 實例化一個條件任務策略(一個神經網絡程序),通過解釋示範任務來執行指定的任務。策略與環境通過機器人 API 相互作用。(下)我們通過模擬和真實的環境中的塊堆疊(A,B),目標分類(C,D)和清理桌子(圖 8)任務評估 NTP。
成果總結:
1)我們的主要貢獻是提出一個新穎的建模框架:NTP,其可以實現層次化任務的元學習(meta-learning)。
2)我們在模擬和實際機器人實驗中對單臂操作任務建模以評估 NTP,這些任務包括:塊堆疊(Block Stacking),目標分類(Object Sorting)和清理桌子(Table Clean-up)。
3)實驗表明,NTP 使知識傳播和基於泛化的一次性演示適用於長度增加、拓撲和語義改變的新任務,而不受限於初始配置。
4)我們還表明 NTP 可以通過視覺輸入(圖像和視頻)進行端到端的訓練。
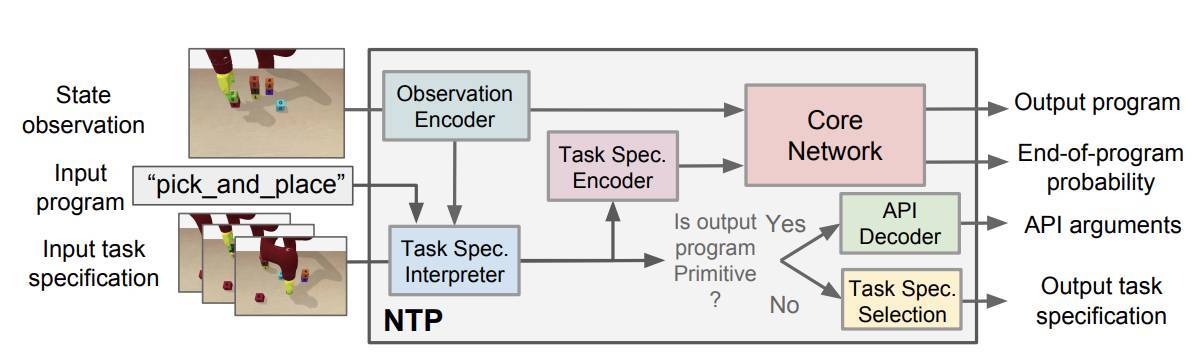
圖 2: 神經任務編程(NTP)給定一個輸入程序,一個指定任務,結合當前環境評測,NTP 模型預測子程序是否繼續運行,以特定任務的順序子程序作爲輸入,還是應該停止當前程序。
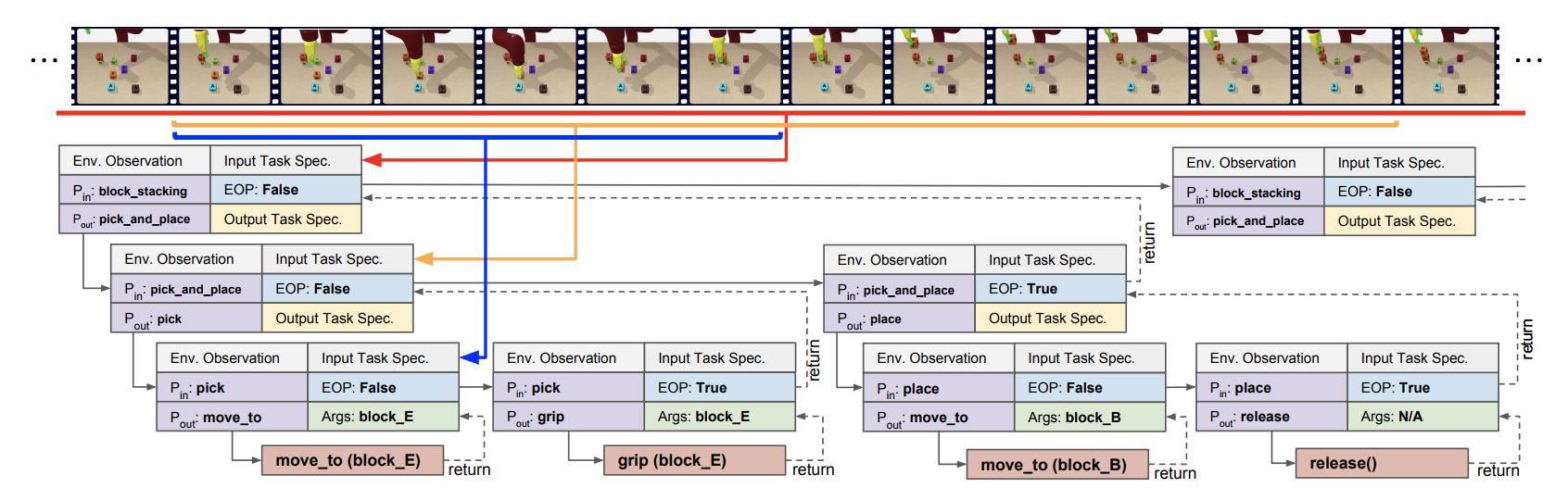
圖 3:塊堆疊任務中 NTP 的樣本執行軌跡圖。任務是按指定要求堆疊字母塊(block_D 堆在 block_E 之上,block_B 堆在 block_D 之上,等等)。頂層程序 block_stacking 作爲輸入參與整個演示(紅色窗口),並預測下一個運行的子程序是 pick_and_place,它應該是將橙色窗口標記爲特定輸入作爲指定任務的一部分。底層 API 調用機器人移動並關閉/打開手指。當程序結束符(EOP)爲 True,當前程序停止並返回其調用方程序。
環境配置
我們的實驗評價的目的是爲了回答以下問題:
(1)NTP 是否概括了變化的所有三個維度:長度、拓撲和語義,如圖 4 所示。
(2)NTP 是否直接以圖像作爲輸入而不必使用標註真值。
(3)NTP 是否適用於複雜多變的現實任務。我們用三個機器人操作任務評估了 NTP:目標分類、塊堆疊、清理桌子。每個任務需要完成多個步驟,並且可以遞歸地分解爲重複的子任務。
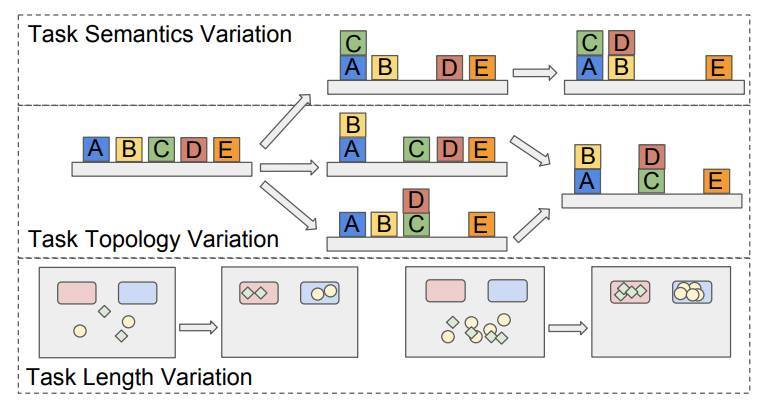
圖 4:任務結構的變化包括改變完成條件(任務語義),可變子任務排列(任務拓撲)和更大的任務容量(任務長度)。我們評估 NTP 模型對這三個變體類型的泛化能力。
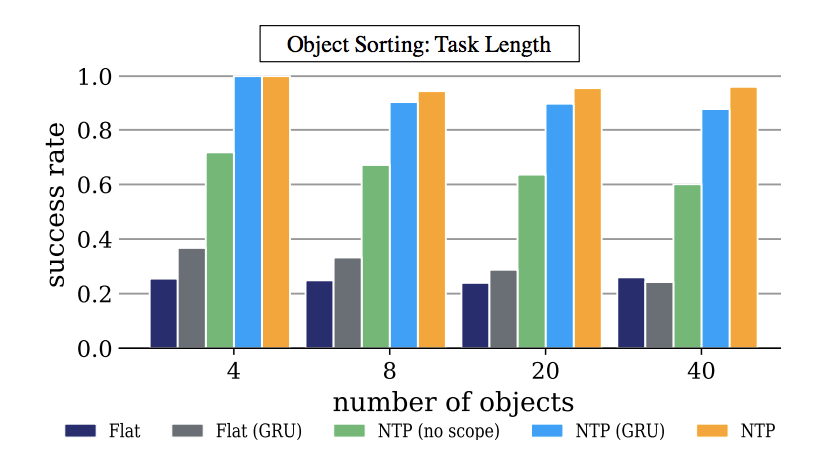
圖 5:任務長度:對模擬目標分類的評估。y 軸代表進行 100 次評估的平均成功率和 x 表示未知任務實例中的目標數。NTP 適用於日益增長的任務,而這是基準程序做不到的。
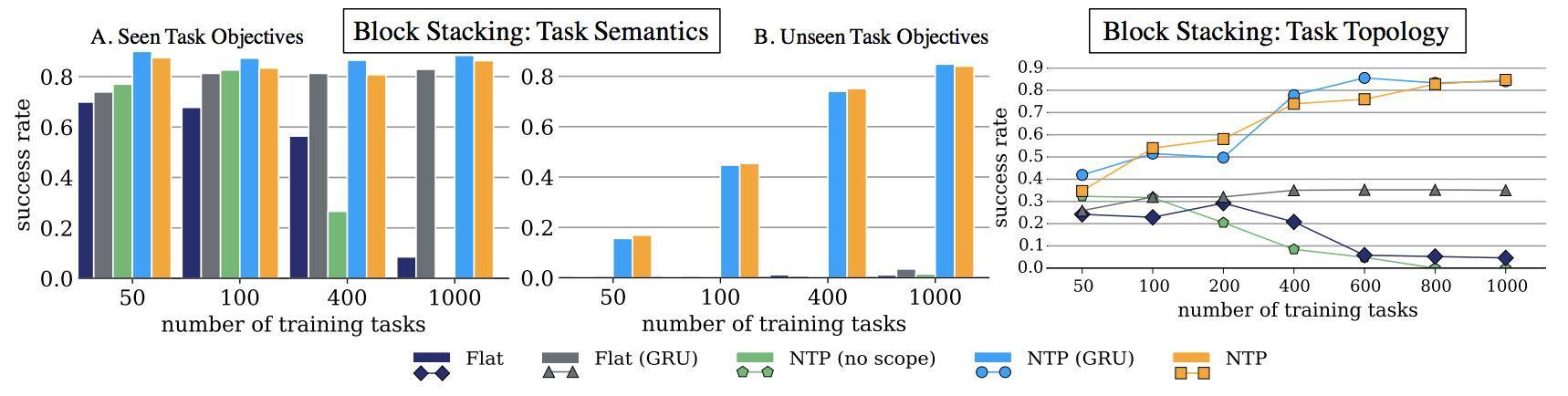
圖 6:語義任務:塊堆疊的模擬評估。x 軸是用於訓練的任務數量。y 軸是整體成功率。圖 A 和圖 B 展示了隨着任務數量的增加,NTP 和其變量能爲新的任務示範和目標生成更好的結果。
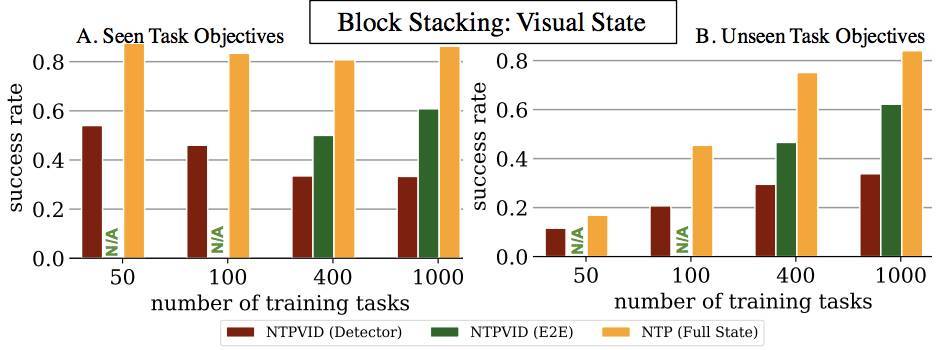
圖 7:可視化的 NTP:NTPVID(檢測器)對圖片使用對象檢測器用於生成下一步的運行狀態。NTP(E2E)是一種端到端模型,完全針對沒有低級狀態信息的圖像進行訓練。我們注意到,在部分觀測案例(僅視頻)中,與完全觀察到的樣例(NTP(全態))相比,可以看到類似的學習趨勢,儘管性能有些損失。

表 1:機器人實例評估:鋸木機器人在模擬訓練的 NTP 模型中 20 個未知的塊堆疊任務和 10 個未知分類任務的結果。NTP 失敗表示算法錯誤,Manip 表示硬件交互錯誤(例如,抓取失敗與碰撞)
表 2:動態對抗:在模擬對抗環境中塊堆疊任務的評估結果。我們發現,使用 GRU 的 NTP 會發生間歇性故障,表現更差。
圖 8:清理桌子:模擬及真實情況。右表模擬狀態下叉子和碗個數對應的成功率。
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: