雷鋒網消息,近期,CMU發佈了一篇新的論文,由一作作者Sainbayar Sukhbaatar和Ilya Kostrikov以及Arthur Szlam,Rob Fergus提出了一種新的學習方法,內在驅動學習,或稱異步自我學習。論文介紹了該學習方式的優越性,並與RL方法做了比較,顯示出了在複雜計算下內在驅動學習的效率類似於或更高於RL方法。本文簡要介紹了這種創新方法的原理。
內在驅動學習的原理非常簡單好理解,如下圖:
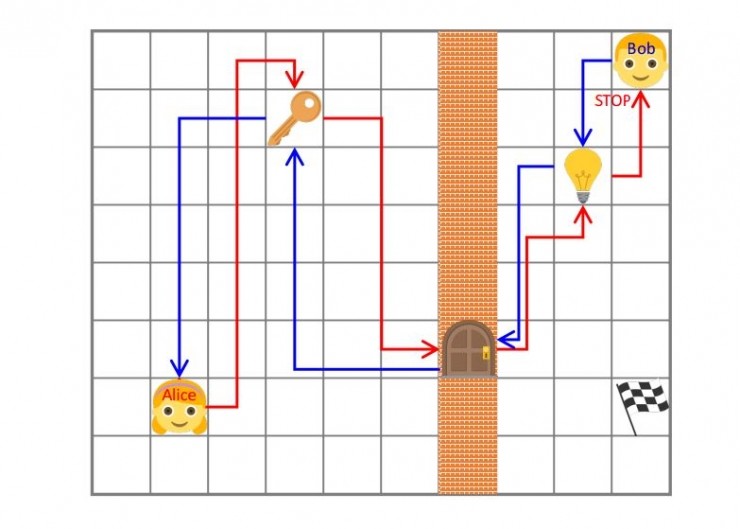
論文中使用同一個代理的兩個不同版本,並用Alice和Bob形象的對其進行命名。通過Alice和Bob的對抗學習,來實現代理對環境認知的無監督學習。
這種學習方式的實現簡單概括爲,Alice提出需要Bob實現的任務;並讓Bob去實現任務。特別提出的是,這種機制着眼於可回退(或近似可回退)的環境,意味着環境狀態允許重置,Alice將會「提出」任務,任務由幾個步驟完成。
然後,Bob將會進行部分步驟回退,或某種意義上的對Alice已經完成的部分進行重複。
雷鋒網(公衆號:雷鋒網)瞭解到,通過適當的獎勵機制,Alice和Bob將會自動的生成一個環境探索課程,從而實現代理的無監督學習。
比如圖片中的例子就介紹了在Mazebase任務中實現的自我學習。由Alice提出Bob必須完成的任務。
在這幅圖片中,Alice首先撿起了鑰匙,開了門後,經過大門,然後關了燈,於是進入到STOP狀態。
這時,智能體由Bob管控。Bob需要將環境恢復到初始狀態,以獲取內部獎勵。於是,Bob必須先把燈打開,走過大門,放下鑰匙,才能回到Alice的START狀態。
這個過程需要Bob去學習環境中所有變量的作用。並且,例子中的鑰匙、門、燈和其順序都只是Alice可設計的諸多任務中的一種,
在內在驅動學習的原理中,Alice可自動產生很多的並且難度逐漸提高的任務。通過這些任務的訓練,Bob可以逐漸的並且快速完成學習。當Bob收到一個新的任務的時候,比如走向途中的旗子,由於Bob已經充分認識了環境的情況,他可以很快完成任務並拿到外部獎勵。
當使用RL任務來實驗這種新的方法時,論文介紹道,內在驅動學習可以大大減少需要學習的內容。
原文鏈接:https://arxiv.org/pdf/1703.05407.pdf,雷鋒網編譯
