Q-Learning 是最著名的強化學習算法之一。我們將在本文中討論該算法的一個重要部分:探索策略。但是在開始具體討論之前,讓我們從一些入門概念開始吧。
強化學習(RL)
強化學習是機器學習的一個重要領域,其中智能體通過對狀態的感知、對行動的選擇以及接受獎勵和環境相連接。在每一步,智能體都要觀察狀態、選擇並執行一個行動,這會改變它的狀態併產生一個獎勵。
馬爾科夫決策過程(MDP)
在絕大多數傳統的設置中,RL 解決 MDP。即使在 RL 的核心部分,我們也不會在本文中涉及 MDP 理論。維基百科上有關於 MDP 很好的簡介。
我們將要解決「forest fire」的馬爾科夫決策問題,這個在 python 的 MDP 工具箱(http://pymdptoolbox.readthedocs.io/en/latest/api/example.html)中是可以看到的。
森林由兩種行動來管理:「等待」和「砍伐」。我們每年做出一個行動,首要目標是爲野生動物維護一片古老的森林,次要目標是伐木賺錢。每年都會以 p 的概率發生森林火災(森林正常生長的概率就是 1-p)。

我們將馬爾科夫決策過程記爲 (S, A, P, R, γ),其中:
S 是有限狀態空間:按照樹齡分爲三類:0—20 年,21—40 年,大於 40 年
A 是有限行動空間:「等待」和「砍伐」
P 和 R 是轉換矩陣和獎勵矩陣,它們的閉合形式容易表達出來
γ是表示長期獎勵和短期獎勵之間的區別的折扣因子
策略π是在給定的當前狀態下動作的平穩分佈(馬爾可夫性)
目標就是找到在不瞭解任何馬爾科夫動態特性的情況下來尋找馬爾科夫決策過程的最優策略π*。需要注意的是,如果我們具有這種知識,像最有價值迭代這種算法就可以找到最優策略。
def optimal_value_iteration(mdp, V0, num_iterations, epsilon=0.0001): V = np.zeros((num_iterations+1, mdp.S)) V[0][:] = np.ones(mdp.S)*V0 X = np.zeros((num_iterations+1, mdp.A, mdp.S)) star = np.zeros((num_iterations+1,mdp.S)) for k in range(num_iterations): for s in range(mdp.S): for a in range(mdp.A): X[k+1][a][s] = mdp.R[a][s] + mdp.discount*np.sum(mdp.P[a][s].dot(V[k])) star[k+1][s] = (np.argmax(X[k+1,:,s])) V[k+1][s] = np.max(X[k+1,:,s]) if (np.max(V[k+1]-V[k])-np.min(V[k+1]-V[k])) < epsilon: V[k+1:] = V[k+1] star[k+1:] = star[k+1] X[k+1:] = X[k+1] break else: pass return star, V, X 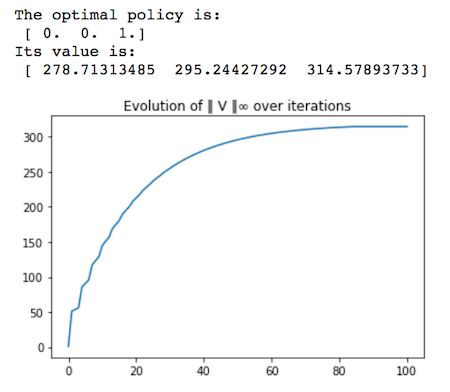
這裏的最優策略是相當符合直覺的,就是等到森林達到最老的樹齡再砍伐,因爲我們把樹齡最老的時候的砍伐獎勵設置成了其成長過程中的 5 倍(r1=10,r2=50)。
Q-LEARNING
Q-Learning 中策略(π)的質量函數,它將任何一個狀態動作組合(s,a)和在觀察狀態 s 下通過選擇行動 a 而得到的期望積累折扣未來獎勵映射在一起。
Q-Leraning 被稱爲「沒有模型」,這意味着它不會嘗試爲馬爾科夫決策過程的動態特性建模,它直接估計每個狀態下每個動作的 Q 值。然後可以通過選擇每個狀態具有最高 Q 值的動作來繪製策略。
如果智能體能夠以無限多的次數訪問狀態—行動對,那麼 Q-Learning 將會收斂到最優的 Q 函數 [1]。
同樣,我們也不會深入討論 Q-Learning 的細節。如果你對它不太熟悉,這裏有 Siraj Raval 的解釋視頻。
下面我們將展示 Q-Learning 的 Python 實現。請注意,這裏所擁的學習率(alpha)遵循 [3] 的結果,使用 w=0.8 的多項式。
這裏用到的探索策略(ε-greedy)在後面會有細節介紹。
def q_learning(mdp, num_episodes, T_max, epsilon=0.01): Q = np.zeros((mdp.S, mdp.A)) episode_rewards = np.zeros(num_episodes) policy = np.ones(mdp.S) V = np.zeros((num_episodes, mdp.S)) N = np.zeros((mdp.S, mdp.A)) for i_episode in range(num_episodes): # epsilon greedy exploration greedy_probs = epsilon_greedy_exploration(Q, epsilon, mdp.A) state = np.random.choice(np.arange(mdp.S)) for t in range(T_max): # epsilon greedy exploration action_probs = greedy_probs(state) action = np.random.choice(np.arange(len(action_probs)), p=action_probs) next_state, reward = playtransition(mdp, state, action) episode_rewards[i_episode] += reward N[state, action] += 1 alpha = 1/(t+1)**0.8 best_next_action = np.argmax(Q[next_state]) td_target = reward + mdp.discount * Q[next_state][best_next_action] td_delta = td_target - Q[state][action] Q[state][action] += alpha * td_delta state = next_state V[i_episode,:] = Q.max(axis=1) policy = Q.argmax(axis=1) return V, policy, episode_rewards, N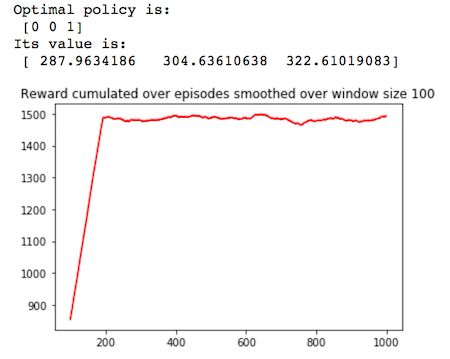
Exploration/Exploitation 權衡
連續學習算法會涉及到一個基本的選擇:
Exploitation: 在目前已經給定的信息下做出最佳選擇
Exploration: 通過做出其他選擇收集更多的信息
成功的平衡 exploration 和 exploitation 對智能體的學習性能有着重要的影響。太多的 exploration 會阻止智能體最大化短期獎勵,因爲所選的 exploration 行動可能導致來自環境的不良獎勵。另一方面,在不完全的知識中 exploiting 會阻止智能體最大化長期獎勵,因爲所選的 exploiting 行動可能一直不是最優的。
ε-greedy exploration 策略
這是一個很樸素的 exploration 策略:在每一步都以概率 ε選擇隨機的動作。
這也許是最常用的、也是最簡單的 exploration 策略。在很多實現中,ε都被設置爲隨時間衰減,但是在一些例子中,ε也被設置爲定值。
def epsilon_greedy_exploration(Q, epsilon, num_actions): def policy_exp(state): probs = np.ones(num_actions, dtype=float) * epsilon / num_actions best_action = np.argmax(Q[state]) probs[best_action] += (1.0 - epsilon) return probs return policy_exp「樂觀面對不確定性」的 exploration 策略
這個概念首次在隨機多臂賭博機(SMAB)環境中被首次提出,這是一個古老的決策過程,爲了最大化機器給出的期望折扣獎勵,賭徒在每一步都要決定搖動哪一個機器。
賭徒面臨着一個 exploration/exploitation 權衡,使用具有最高平均獎勵的機器或者探索其他表現並不是很好的機器以得到更高的獎勵。
SMAB 和 Q-Learning 中的 exploration 問題很相似。
Exploitation: 在給定的狀態下選擇具有最高 Q 值的動作
Exploration: 探索更多的動作(選擇沒有被足夠得訪問或者從未被訪問的動作)
 圖片來自微軟研究院
圖片來自微軟研究院
「面對不確定性的樂觀」(OFU)狀態:無論什麼時候,我們都對老虎機的輸出結果是不確定的,所以我們預計環境是最好的,然後選擇最好的老虎機。
OFU 背後的直覺是:
如果我們處於最好的處境:OFU 會選擇最佳的老虎機(沒有遺憾)
如果我麼不在最好的處境中:不確定性會減少(最佳)
最著名的 OFU 算法之一是 UCB(置信區上界)[2]。我們按照下面的方法將它用在 Q-learning 中。
定義:
Q(s, a): 狀態 s 下采用動作 a 的 Q 值
N(t, s, a):在時間 t,動作 a 在狀態 s 被選擇的次數
智能體的目標是:Argmax {Q(s, a)/ a ∈ A}。代表在狀態 s 下選擇具有最大 Q 值的動作。但是時間 t 的實際 Q(s, a) 是未知的。
我們有:Q(s,a) =
Hoeffding 不等式是限制這個誤差的一種方式,我們可以證明:
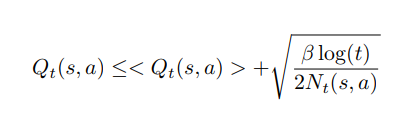 最優策略可以被寫成:
最優策略可以被寫成:
Argmax {Q+(t, s, a)/ a ∈ A}
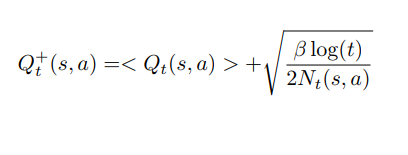 其中β ≥ 0 調節 exploration。當β=0 的時候,該策略僅僅利用過去的估計(遵循 leader 策略)。
其中β ≥ 0 調節 exploration。當β=0 的時候,該策略僅僅利用過去的估計(遵循 leader 策略)。
這個範圍是該領域最常用的。還有很多其他改進這個範圍的工作(UCB-V、UCB、KL-UCB、Bayes-UCB、BESA 等)。
這裏是我們對經典 UCB exploration 策略的實現,以及它在 Q-Learning 中使用的結果。
def UCB_exploration(Q, num_actions, beta=1): def UCB_exp(state, N, t): probs = np.zeros(num_actions, dtype=float) Q_ = Q[state,:]/max(Q[state,:]) + np.sqrt(beta*np.log(t+1)/(2*N[state])) best_action = Q_.argmax() probs[best_action] = 1 return probs return UCB_expUCB exploration 似乎能夠快速地達到很高的獎勵,然而訓練過程還是受到早期 exploration 的干擾,對於更復雜的馬爾科夫決策過程而言,這是有優勢的,因爲智能體可以免於非最優的解決方案。
我們來更加仔細地比較這兩種策略。
總結及展望
Q-learning 是最常用的強化學習算法之一。在這篇文章中,我們討論了 exploration 策略的重要性以及 UCB exploration 策略的使用,而並非最出名的ε-greedy exploration 策略。爲了平衡 exploration 和 exploitation,更多的改進樂觀策略可能會被用到。
參考文獻
[1] T. Jaakkola, M. I. Jordan, and S. P. Singh,「On the convergence of stochastic iterative dynamic programming algorithms」Neural computation, vol. 6, no. 6, pp. 1185–1201, 1994.
[2] P. Auer,「Using Confidence Bounds for Exploitation-Exploration Trade-offs」, Journal of Machine Learning Research 3 397–422, 2002.
[3] E. Even-Dar, Y. Mansour,「Learning Rates for Q-learning」, Journal of Machine Learning Research 5 1–25, 2003.
原文鏈接:https://medium.com/sequential-learning/optimistic-q-learning-b9304d079e11