機器學習的構建和部署通常需要非常多的工作與努力,這對於軟件開發者和入門者造成了很多困難。本文介紹瞭如何使用軟件庫 Lore 快速而高效地構建機器學習模型,並從數據預處理到模型部署等七個步驟介紹構建的經驗。
一般問題
Python 或 SQL 等高級語言編寫代碼時,模型性能很容易出現瓶頸。
代碼複雜性在增長,因爲有價值的模型需要通過許多次迭代才能得到。當代碼以非結構化的方式演化時,難以保證與傳達最初的想法。
對數據和函數庫的依賴不斷變化,從而導致性能再現受到影響。
當人們試圖理解最新的論文、軟件包、特徵和問題時,信息過載使得人們很容易錯過唾手可得的成果,這一問題對於剛入行的人來說更爲嚴重。
爲了解決這些問題,我們標準化了 Lore 中的機器學習方法,並使用 Lore 開發新的機器學習模型。此外,我們 Instacart 也在產品中運行着十幾個 Lore 模型。
如果您想在沒有上下文的情況下看一下快速的演示,可以從 GitHub 上覆制 my_app。如果您想看到完整工程介紹,請跳至大綱。
$ pip3 install lore$ git clone https://github.com/montanalow/my_app.git$ cd my_app $ lore install # caching all dependencies locally takes a few minutes the first time$ lore server & $ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Banana&department=produce"特徵說明
瞭解該項目最好的方法是在十五分鐘內開始我們自己的深度學習項目。如果你想在開始新項目前瞭解本文所述模型的特性,請參閱以下簡要概述:
模型支持使用估計器搜索超參數,它們將採用幾個不同的策略有效地利用多個 GPU(如果條件允許的話),因此可以分佈式地搜索超參數分佈。
支持使用多個軟件庫的估計器,包括 Keras、XGBoost 和 SciKit Learn 等。這些包都可以通過構建、擬合或預測進行分類,完整地覆蓋了用戶的算法和架構類型。
數據處理流程避免了信息在訓練集和測試集間泄露的風險,且一條流程允許許多不同的估計器進行試驗。如果您在實驗過程中超出了可用 RAM,那麼您可以使用基於磁盤處理流程。
轉換標準化的高級特徵工程。例如,使用美國人口普查數據可以將美國人的姓轉換爲年齡或性別的統計學特徵;或是從任意格式的電話號字符串中提取地域編碼。此外,pandas 包可以支持一般的數據、時間和字符串的轉化操作。
編碼器則爲您的評估器提供魯棒性的輸入,並能避免常見的缺失和長尾問題。
對流行的(非)關係型數據庫而言,IO 連接在應用程序中以一種標準的方式進行配置和彙集。這種方式對批量數據進行任務管理和讀寫優化,而非傳統的 ORM 單行操作。IO 連接除了用加密的 S3 buckets 分配模型和數據集外,還共享了可配置的查詢緩存。
對每個獨立開發中的 APP 而言,依賴項管理都可以將對應包完整地複製到產品中去。因此我們無需瞭解 venv、pyenv、pyvenv、virtualenv、virtualenvwrapper、pipenv 和 conda 依賴項管理工具。
這樣的工作流程可以讓您選擇是使用命令行、python 控制檯、jupyter notebook 或者是其它 IDE。每個環境都可以在產品開發和配置過程中生成可讀的日誌記錄。
15 分鐘開啓機器學習
您只需基礎的 python 知識即可開始。如果您的模型沒有開始進行學習,那您可以用省出來的時間繼續探索機器學習的複雜性。
1. 創建一個新的 app(3 分鐘)
2. 設計一個模型(1 分鐘)
3. 生成架構(2 分鐘)
4. 鋪設流程(5 分鐘)
5. 測試代碼(1 分鐘)
6. 訓練模型(1 分鐘)
7. 部署產品(2 分鐘)
上述時間有些言過其實,只用作博客宣傳。沒有一個機器學習研究人員可以只用一分鐘就設計出一個模型,但是一旦你開始跟着學,並且將過程中得到的一切都做上筆記,那麼你也可以在 15 分鐘內高效地構建一個自定義的 AI 項目,在你的朋友和同事中一鳴驚人。
1. 創建一個新的 APP
Lore 獨立管理每個項目,這是爲了避免與系統中的 python 或其他項目發生衝突。我們可以將 Lore 作爲一個標準的 pip 包安裝:
# On Linux$ pip install lore# On OS X use homebrew python 2 or 3$ brew install python3 && pip3 install lore當你無法複製他人環境時,是很難復現他人的工作。Lore 保護系統中 python 項目的方式可以避免依賴項錯誤和項目衝突。每一個 Lore 的應用程序都有自己的字典和安裝目錄,它特定需要的依賴庫會鎖定在文件 runtime.txt 和 requirements.txt 中。這使 Lore 的應用程序共享起來更加高效,也讓我們離復現這個機器學習項目更近一步。
在安裝 Lore 之後,我們可以在閱讀本文後創建一個新的深度學習項目的 app。Lore 默認是模塊化的,所以我們需要指定——keras 來爲這個項目安裝深度學習的依賴項。
$ lore init my_app --python-version=3.6.4 --keras2. 設計一個模型
爲了演示,我們將建立一個預測模型,這個模型將基於產品名字及其所在部門,預測出 Instacart 網站的產品能有多流行。世界各地的製造商零售時會在不同的人羣間測試產品名字,看什麼樣的名字能得到最多的關注,我們這個簡單的 AI 項目也可以提供相同的服務。
機器學習中最難的一部分是獲得良好的數據。幸運的是,Instacart 以匿名的方式公佈了 300 萬份雜貨訂單。基於此,我們可以將問題調整爲建立一個有監督的迴歸模型,該模型可以基於兩個特點預測年均銷量:產品名稱和產品類別。實際上,該模型的表現並不好,因此後文會繼續討論更加強大的模型。
3. 生成架構
$ cd my_app$ lore generate scaffold product_popularity --keras --regression --holdout每一個 Lore 模型都包含一條用於加載數據和編碼數據的流程,還包含一個可以實現特定機器學習算法的估計器。模型最有趣的部分在於類別生成中的實現細節。
流程從左側的原始數據開始,將原始數據編碼爲右側所需格式。估計器可以用編碼數據訓練模型,並根據驗證集的性能確定是否終止訓練,最後再用測試集評估。所有內容都可以被序列化存在模型存儲區,然後用一個單線程再次加載進行部署。
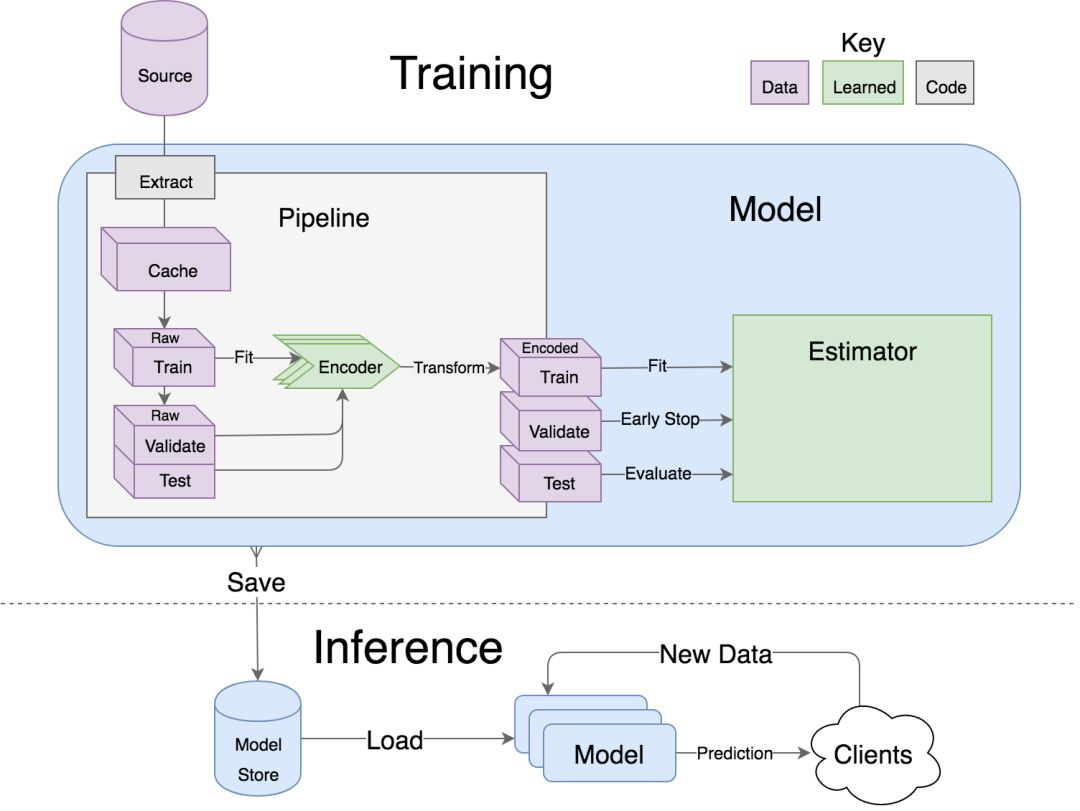
4. 鋪設流程
得到很適合機器學習算法的原始數據是很難的。我們通常會從一個數據集中加載數據或是下載 CSV 文件,將其編碼爲適合算法的格式,然後再將其分割爲訓練集和測試集。lore.pipelines 將這一預處理邏輯封裝起來,成爲標準的工作流程。
lore.pipelines.holdout.Base 可以將數據分爲訓練集、驗證集和測試集,並可以編碼數據,使數據適用於我們的機器學習算法。我們的子類將定義三種方法:get_data、get_encoders 和 get_output_encoder。
Instacart 公佈的數據分爲了多個 csv 文件,如下表所示。
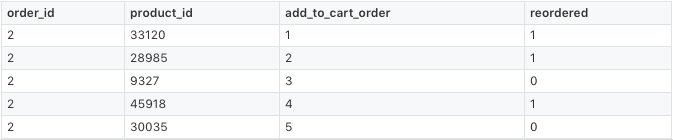
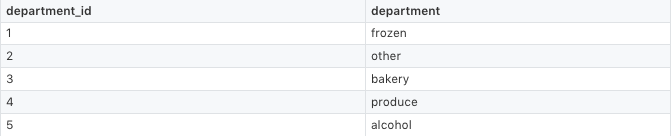
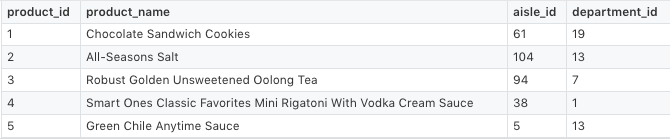
get_data 可以下載 Instacart 的原始數據,使用 pandas 可以將帶有所需特徵(product_name,department)的數據加入 DataFrame,還可將預測量(sales)合併在一起。如下所示:
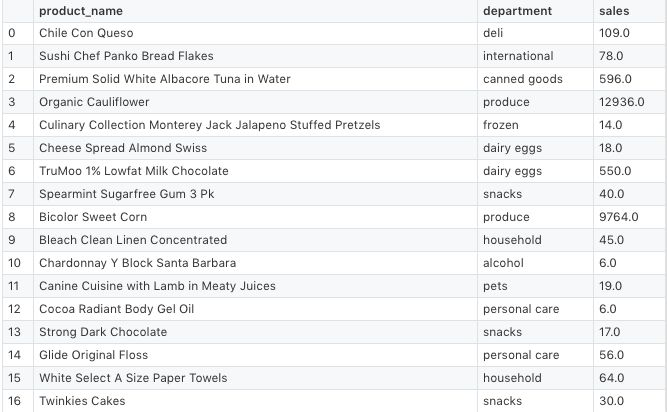
下列代碼展示瞭如何實現 get_data :
# my_app/pipelines/product_popularity.py part 1import osfrom lore.encoders import Token, Unique, Normimport lore.ioimport lore.pipelinesimport lore.envimport pandasclass Holdout(lore.pipelines.holdout.Base): # You can inspect the source data csv's yourself from the command line with: # $ wget https://s3.amazonaws.com/instacart-datasets/instacart_online_grocery_shopping_2017_05_01.tar.gz # $ tar -xzvf instacart_online_grocery_shopping_2017_05_01.tar.gz def get_data(self): url = 'https://s3.amazonaws.com/instacart-datasets/instacart_online_grocery_shopping_2017_05_01.tar.gz' # Lore will extract and cache files in lore.env.data_dir by default lore.io.download(url, cache=True, extract=True) # Defined to DRY up paths to 3rd party file hierarchy def read_csv(name): path = os.path.join( lore.env.data_dir, 'instacart_2017_05_01', name + '.csv') return pandas.read_csv(path, encoding='utf8') # Published order data was split into irrelevant prior/train # sets, so we will combine them to re-purpose all the data. orders = read_csv('order_products__prior') orders = orders.append(read_csv('order_products__train')) # count how many times each product_id was ordered data = orders.groupby('product_id').size().to_frame('sales') # add product names and department ids to ordered product ids products = read_csv('products').set_index('product_id') data = data.join(products) # add department names to the department ids departments = read_csv('departments').set_index('department_id') data = data.set_index('department_id').join(departments) # Only return the columns we need for training data = data.reset_index() return data[['product_name', 'department', 'sales']]接下來,我們需要爲每一列指定一個編碼器。計算機科學家可能認爲編碼器是使機器學習更高效的方法。一些產品的名字太長,所以我們將其名稱限定爲前 15 個單詞。
# my_app/pipelines/product_popularity.py part 2 def get_encoders(self): return ( # An encoder to tokenize product names into max 15 tokens that # occur in the corpus at least 10 times. We also want the # estimator to spend 5x as many resources on name vs department # since there are so many more words in english than there are # grocery store departments. Token('product_name', sequence_length=15, minimum_occurrences=10, embed_scale=5), # An encoder to translate department names into unique # identifiers that occur at least 50 times Unique('department', minimum_occurrences=50) ) def get_output_encoder(self): # Sales is floating point which we could Pass encode directly to the # estimator, but Norm will bring it to small values around 0, # which are more amenable to deep learning. return Norm('sales')這就是預處理流程。我們起初用的評估器是 lore.estimators.keras.Regression 的一個簡單子類,可以用默認值實現簡單的深度學習架構。
# my_app/estimators/product_popularity.pyimport lore.estimators.kerasclass Keras(lore.estimators.keras.Regression): pass最後,我們的模型可以通過將其委託給估計器來改變深度學習架構的高級屬性,還可從我們構建的處理流程中提取數據。
# my_app/models/product_popularity.pyimport lore.models.kerasimport my_app.pipelines.product_popularityimport my_app.estimators.product_popularityclass Keras(lore.models.keras.Base): def __init__(self, pipeline=None, estimator=None): super(Keras, self).__init__( my_app.pipelines.product_popularity.Holdout(), my_app.estimators.product_popularity.Keras( hidden_layers=2, embed_size=4, hidden_width=256, batch_size=1024, sequence_embedding='lstm', ) )5. 測試代碼
當搭建架構時模型會自動運行通煙測試(smoke test),第一次運行時會花一些時間下載一個 200 MB 的數據集進行測試。您還可以對緩存在 ./tests/data 中的文件進行修改,將其移入回收站以加快測試速度。
$ lore test tests.unit.test_product_popularity6. 訓練模型
訓練模型需要 ./data 中的緩存數據,並將工作保存在 ./models 中。
$ lore fit my_app.models.product_popularity.Keras --test --score查閱終端日誌可以瞭解 Lore 的時間都花在了哪裏。
$ tail -f logs/development.log嘗試添加更多隱藏層以瞭解這一操作是否有助於提高您模型的性能。您可以編輯模型文件或者直接通過命令行調用合適的屬性,如 --hidden_layers=5。
檢驗模型特性
您可以在 lore 環境下運行 jupyter notebooks。Lore 將安裝一個可自定義的 jupyter 內核,該內核將爲 lore notebook 和 lore console 提供應用程序虛擬環境。
$ lore notebook瀏覽 notebooks/product_popularity/features.ipynb 或「運行所有」可以瞭解您模型的可視化分析。
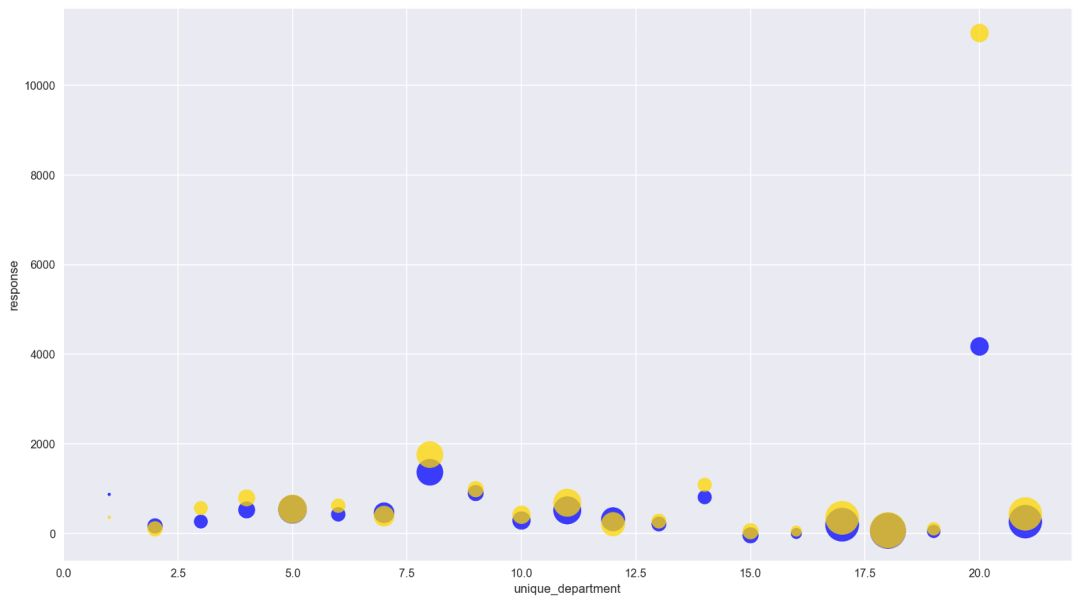
「生產」類被編碼到「20」,這是很大的銷售量了。
彙總特定特徵時您就可以瞭解到模型的預測結果(藍色)和測試結果(黃色)有多一致。在本例中,有 21 類重合程度相當高。「生產」類是例外,模型沒有充分說明其逸出值。
您還可以通過運行 notebooks/product_popularity/architecture.ipynb 中的筆記了解生成的深層學習架構。

縮減爲 15 個字符的名字通過左邊的 LSTM 運行,類名輸入到右邊的嵌入中,然後一起通過隱藏層。
發佈模型服務
Lore 的應用程序可以作爲 HTTP API 在本地運行。默認情況下模型會通過 HTTP GET 端點公開其「預測」方法。
$ lore server &$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Banana&department=produce"$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Organic%20Banana&department=produce"$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Green%20Banana&department=produce"$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Brown%20Banana&department=produce"結果表明,在「香蕉」中加入「有機」,將會在「生產」類賣出超過兩倍的水果。預測得出,「綠香蕉」比「棕香蕉」銷量更差。如果您需要果汁的記錄,則應該選擇「有機黃香蕉」。
7. 部署產品
Lore 的應用程序可以通過任何支持 Heroku buildpack 的基礎架構進行部署。Buildpacks 將 runtime.txt 和 requirements.txt 的依賴項在容器中安裝以供模型部署。
您可以在 ./models/my_app.models.product_popularity/Keras/ 中瞭解每一次運行 lore fit 指令的結果。這個字典和 ./data/ 都默認在 .gitignore 中,您的代碼隨時可以重建路徑。您可以在發佈前檢查要發佈的模型版本,這是一個簡單的部署策略:
$ git init .$ git add .$ git add -f models/my_app.models.product_popularity/Keras/1 # or your preferred fitting number to deploy$ git commit -m "My first lore app!"Heroku 使發佈一個應用程序變得非常簡單,您可以點擊鏈接瀏覽其入門介紹:https://devcenter.heroku.com/articles/getting-started-with-python#introduction。
下面是「太長不看」版:
$ heroku login$ heroku create$ heroku config:set LORE_PROJECT=my_app$ heroku config:set LORE_ENV=production$ git push heroku master$ heroku open$ curl 「`heroku info -s | grep web_url | cut -d= -f2`product_popularity.Keras/predict.json?product_name=Banana&department=produce」現在您可以用 heroku 應用的名字替代 http://localhost:5000/,並在任何地方獲取預測結果。
原文鏈接:https://tech.instacart.com/how-to-build-a-deep-learning-model-in-15-minutes-a3684c6f71e