因爲手抖或焦點選擇等問題,相機拍攝的圖像中常常存在模糊狀況。消除圖像模糊,呈現圖像細節是計算機視覺領域內的一個重要研究主題。香港中文大學、騰訊優圖實驗室和曠視科技的研究者合作提出的 SRN-DeblurNet 能更高效地實現比之前最佳方法更好的結果。該論文已被將在當地時間 6 月 18-22 日於美國猶他州鹽湖城舉辦的 CVPR 2018 接收。
圖像去模糊一直以來都是計算機視覺和圖像處理領域內的一個重要問題。給定一張因運動或失焦而模糊(由相機搖晃、目標快速移動或對焦不準而造成)的圖像,去模糊的目的是將其恢復成有清晰的邊緣結構和豐富真實的細節的圖像。
單圖像去模糊在數學上是一個高度病態(ill-posed)問題。傳統方法是通過對模糊的原理進行簡化和建模(比如均勻模糊/非均勻模糊/考慮深度的模糊),並使用不同的自然圖像先驗 [1, 3, 6, 14, 26, 37, 38] 來約束解空間。這些方法大多數都涉及到大量的(有時是試驗式的)參數調整和成本高昂的計算。此外,簡化後的模糊模型往往有礙它們在真實拍攝樣本上的表現。在真實世界中,模糊比建模的情況要複雜很多,甚至還涉及到相機內部的圖像處理過程。
也有研究者爲去模糊提出了基於學習的方法。早期的方法 [28, 32, 35] 是藉助外部訓練數據,用一組可學習的參數替代傳統框架中的一些模塊或步驟。更近期的工作則開始使用端到端的可訓練網絡來進行圖像 [25] 和視頻 [18,31] 去模糊。其中,Nah et al.[25] 使用一種多尺度卷積神經網絡(CNN)達到了當前最佳水平。他們的方法從非常小尺度的模糊圖像開始,然後逐漸恢復更高分辨率的清晰圖像,直到達到完整分辨率。這一框架遵循傳統方法中的多尺度機制,其中「由粗到精」流程在處理大的模糊核時很常見 [6]。
在本論文中,我們探索了一種用於多尺度圖像去模糊的更有效的網絡結構。我們提出了一種新的尺度循環網絡(SRN:scale-recurrent network),它討論和解決了基於 CNN 的去模糊系統中兩個重要的一般性問題。
尺度訓練結構
在現有的多尺度方法中,求解器及其每個尺度的參數通常是一樣的。直觀上看,這是一種自然的選擇,因爲在每個尺度上,我們的目標都是求解同樣的問題。還可以發現,每個尺度上使用不同的參數可能會引入不穩定性並帶來非限制性解空間的額外問題。另一個問題是輸入圖像可能會有不同的分辨率和運動尺度。如果允許每個尺度上都進行參數調節,那麼這個解可能會在特定圖像分辨率或運動尺度上過擬合。
基於同樣的原因,我們相信這個方案也應該被應用於基於 CNN 的方法。但是,近期的級聯網絡 [4, 25] 仍然爲每個尺度使用了獨立的參數。在本研究中,我們提出在不同尺度上共享網絡權重,從而顯著降低訓練複雜度以及引入明顯的穩定性優勢。
這種做法有兩種好處。首先,這能顯著減少可訓練參數的數量。即使用同樣數目的訓練數據,在共享權重的循環利用下的效果也像是有多倍數據來學習參數,這實際上相當於在尺度上進行的數據增強。其次,我們提出的結構可以利用到循環模塊,其狀態傳遞能隱含地獲取各個尺度上的有用信息並幫助圖像恢復。
編碼器-解碼器 ResBlock 網絡
編碼器-解碼器結構在多種計算機視覺任務上有效應用 [23, 31, 33, 39],我們探索了將其應用於圖像去模糊任務的有效方法。在本論文中,我們將表明直接應用已有的編碼器-解碼器結構不能得到最優結果。相對而言,我們的編碼器-解碼器 ResBlock 網絡會放大各種 CNN 結構的優勢並實現訓練的可行性。同時,這還會產生非常大的感受野,這對運動模糊很大的圖像的去模糊至關重要。
我們的實驗表明,使用循環結構並結合上述優勢,我們的端到端深度圖像去模糊框架可以極大地提升訓練效率(大約 [25] 的四分之一的訓練時間就能實現近似的恢復效果)。我們只使用了不到三分之一的可訓練參數以及遠遠更少的測試時間。除了訓練效率,我們的方法在定量和定性比較上都能得到比已有方法更高質量的結果,如圖 1 所示。我們將這個框架稱爲尺度循環網絡(SRN)。

圖 1:一個真實拍攝的示例。(a)輸入的模糊圖像,(b)Sun et al. [32] 的結果,(c)Nah et al. [25] 的結果,(d)我們的結果
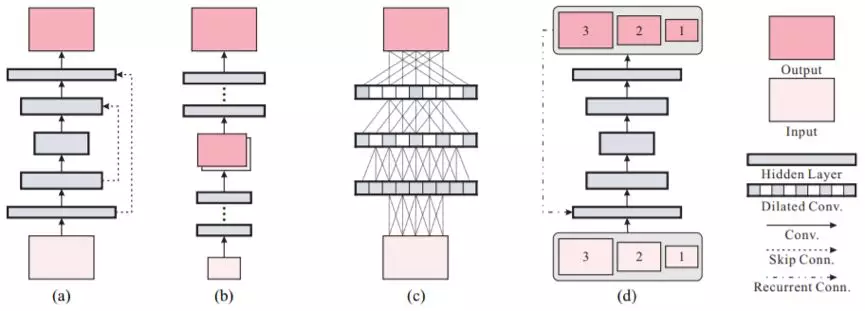
圖 2:用於圖像處理的不同 CNN。(a)U-Net [27] 或編碼器-解碼器網絡 [24],(b)多尺度 [25] 或級聯細化網絡 [4],(c)擴張卷積網絡 [5],(d)我們提出的尺度循環網絡(SRN)。
網絡架構
我們將我們提出的網絡的整體架構稱爲 SRN-DeblurNet,如圖 3 所示。其以在不同尺度上從輸入圖像下采樣的一個模糊圖像序列爲輸入,然後得到一組對應的銳利圖像。在全分辨率下的銳利圖像即爲最終輸出。
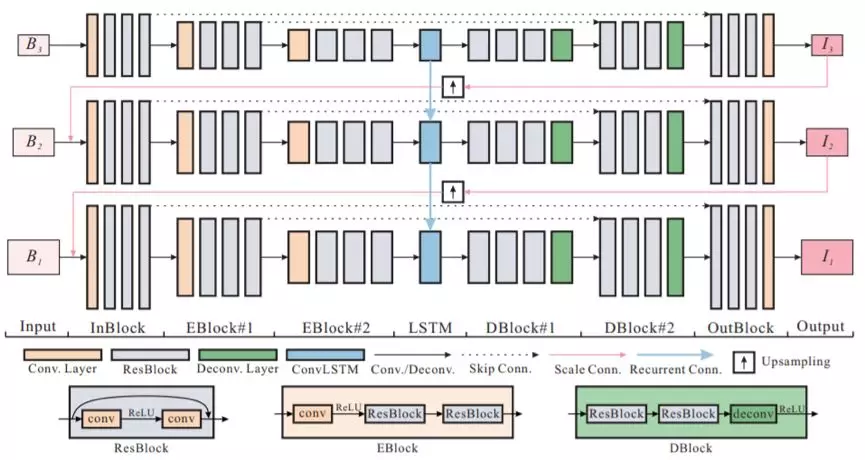
圖 3:我們提議的 SRN-DeblurNet 框架
實驗
我們的實驗是在一臺 PC 上執行的,其配置有英特爾 Xeon E5 CPU 和一塊英偉達 Titan X GPU。我們在 TensorFlow 平臺 [11] 上實現了我們的框架。我們全面評估了多種網絡結構,以驗證不同的結構對於效果的影響。爲了公平起見,除非另有說明,所有實驗都是在同一數據集上,使用同樣的訓練配置完成的。
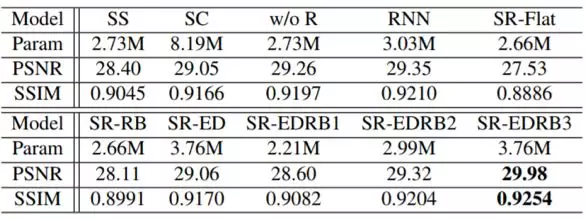
表 1:基準模型的定量結果
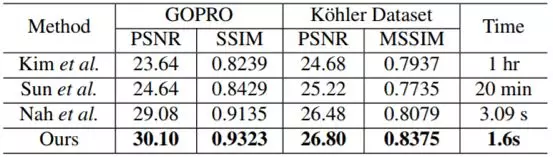
表 2:在測試數據集上的定量結果(PSNR/SSIM)

圖 5:在測試數據集上的視覺比較。從上到下:輸入、Whyte et al. [34]、Sun et al. [32]、Nah et al. [25] 和我們的方法。
論文:用於深度圖像去模糊的尺度循環網絡(Scale-recurrent Network for Deep Image Deblurring)

論文地址: http://www.cse.cuhk.edu.hk/leojia/papers/scaledeblur_cvpr18.pdf
摘要:在單圖像去模糊中,「粗糙到精細」方案(即以金字塔的形式在不同分辨率上逐步恢復銳利圖像)在傳統的基於優化的方法和近期的基於神經網絡的方法中都非常成功。在本論文中,我們研究了這一策略並提出了一種用於去模糊任務的尺度循環網絡(SRN-DeblurNet)。相比於 [25] 中很多近期的基於學習的方法,它的網絡結構更簡單,參數數量更少,訓練更容易。我們在帶有複雜運動的大規模去模糊數據集上評估了我們的方法。結果表明,在定量和定性比較上,我們的方法能得到比之前最佳結果更高質量的結果。