雷鋒網(公衆號:雷鋒網) AI科技評論按,本文作者孫奕帆,本文首發於知乎專欄行人重識別,雷鋒網 AI科技評論獲其授權轉載。
文章鏈接: arXiv:1703.05693(https://arxiv.org/abs/1703.05693)
代碼鏈接:syfafterzy/SVDNet-for-Pedestrian-Retrieval(https://github.com/syfafterzy/SVDNet-for-Pedestrian-Retrieval)
一、背景簡介
近年來,行人再識別問題(Person-reID)研究熱度逐漸上升。與人臉識別相比,它在採集圖像時不需要行人主動配合,在安防等領域具有極大的應用潛力。基於深度學習的行人再識別方法,在近幾年快速進步,在絕大部分公開數據集上,深度學習特徵均超過了手工設計特徵。這篇文章的工作主要圍繞利用如何更好地學習的深度特徵,提高行人再識別的準確率進行。然而,這篇文章實際上沒有具體針對行人再識別的特有問題進行分析、優化,筆者認爲該方法在小數據集問題上,該方法具有一般性意義,並且,該方法對CNN特徵的物理意義開展了一些有趣的思考。
二、Motivation
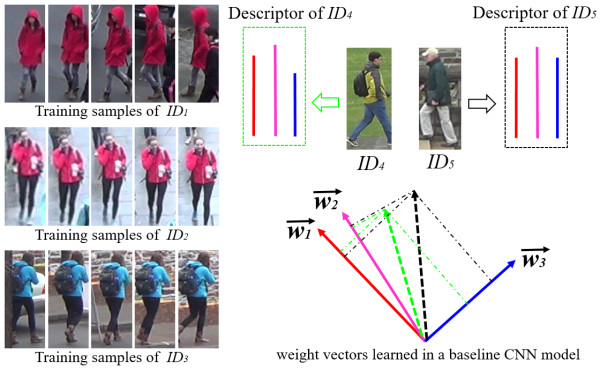
首先需要說明的是,SVDNet基於這樣一個對CNN權向量的簡單解讀:假設CNN的一層網絡,其輸入是I,輸出是O,權矩陣是W,那麼O=W'*I運算是在做線性投影,而W中所含的權向量則是一組投影基向量。當訓練一個用於提取re-ID問題中行人特徵的深度卷積神經網絡(CNN)時,與在其它所有典型的深度學習訓練一樣,通常所學到的權向量是「雜亂無章」的,這種雜亂無章體現在,網絡同一層中的權向量,通常是存在較強的相關性(注意不是線性相關linear dependent)。這種相關性,對於特徵表達可能會造成不必要甚至是非常有害的冗餘。例如下圖中,假設網絡用於提取特徵的特徵層含有3個權向量,紅色和粉色所代表的的權向量幾何上更靠近,而藍色的權向量相對較遠,那麼,當一個行人圖像進入網絡中後,它會最終投影到這3個權向量上,形成一個3維的特徵,而在紅色和粉色上的投影結果將會非常接近。這就使得,在藍色上的投影結果相較之下無足輕重了,很有可能造成一些誤判。
因此,我們希望對於特徵表達層(該層的輸出作爲行人圖像的特徵),它的權向量是正交的。這裏說遠一點關於深度學習中的正交約束。其實,正交約束在深度學習中近幾年並不少見。例如ICLR2016年的Reducing Overfitting in Deep Networks by Decorrelating Representations(arXiv:1511.06068),以及同樣ICCV2017年的一篇工作arXiv:1511.06068。此外,諸如whitened network,以及ICML2017年的generalized whitened network,也都可以認爲利用了正交化在深度學習種可能帶來的好處。不過,值得注意的是,這些工作都是讓把feature不同維度的值當成一個變量,希望不同維度上的變量是相互獨立的。而SVDNet這篇工作避開了這個做法,希望權向量是正交的。在paper中,出於嚴謹的考慮,沒有解釋這兩種做法的差異。筆者認爲,這樣做實際上是有巧妙意義的。受限於深度學習的訓練方式,對特徵施加正交約束時,只能在一個minibatch裏去求feature的協方差矩陣,並要求該矩陣是對角陣,這種做法本身是無奈之舉。而SVDNet這種做法避開了這個困難,它其實藉助了這樣一個思想:每一個權向量,都是相應特徵相應維度上的模板(exemplar)或者代理(agent)。這種解讀在最近的很多工作中都有所體現。
三、訓練方法RRI
——如何在CNN訓練中,對權向量施加正交約束
先說怎麼做的,後面再解釋爲什麼這麼做。
做法非常簡單,分爲3步,稱之爲Restraint and Relaxation Iteration (RRI):
1、去相關——每次訓練模型收斂之後,對特徵表達層的權矩陣W進行奇異值分解,即W=USV',然後,用US去取代原來的W,這時,W變成了一個正交陣(每個權向量彼此正交),且新的權向量是原來權矩陣WW'的本徵向量。經過這樣一次去相關之後,原本已經收斂的模型偏離原先的局部最優解、在訓練集上的分類損失變大了。
2、緊張訓練(Restraint)——固定住步驟1中的W不更新,學習其它層參數,直至網絡重新收斂。需要注意的是,在這種情況下,網絡會收斂到一個次優解:因爲它有一層的W是受限制。因此,在接下來,我們會取消這個限制,繼續訓練。
3、鬆弛訓練(Relaxation)——在步驟2之後,取消W固定的限制,這個時候,網絡會發現對於擬合訓練樣本會這個目標會有一個更好的解:請注意,僅僅是針對擬合訓練樣本這個目標。我們實驗發現,這個模型使用在訓練集上(包含全新的ID)時,它的泛化能力是相對較弱的。
而在步驟3之後,W裏的權向量重新變的相關起來。因此,我們把這3步迭代起來,形成RRI,直最終收斂。
四、RRI中發生了什麼?
在RRI中,每個Restraint階段後,權向量被去相關了、W變成了正交矩陣、ReID的準確度提升了;而在每個Relaxation階段後,權向量重新相關起來,ReID的準確度停滯甚至略微降低(相較於上一個Restraint)。但是,比較Relaxation階段,我們可以發現,W正交度S(W)在提升,而Reid的準確度也在提升,直到二者幾乎同時達到了收斂狀態。見下圖:
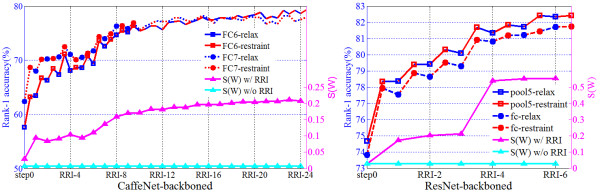
上圖是本文最重要、最有趣的一張圖,它對SVDNet這個方法的原理起到了一種「知其然、知其所以然「意義上的證明。圖中S(W)——用來衡量W正交度的變量定義本文不再敘述,非常簡單直觀,關心的同學可以去查看論文。有趣的地方在於:緊張訓練階段,reID性能提升;而放鬆訓練階段,reID性能降低。這似乎與我們人類的學習規律類似:提倡張弛結合,緊張時進步,而交替地放鬆,是爲了積累。
五、性能
SVDNet 方法的性能,在2017年初接近當時的state of the art。而且,爲了方法的純粹性,SVDNet沒有采用除了「鏡像」之外的任何圖像增強,輸入圖像也是採用baseline模型的默認尺寸。具體性能比較見論文,這裏僅展示一下在market-1501數據集上的對比。
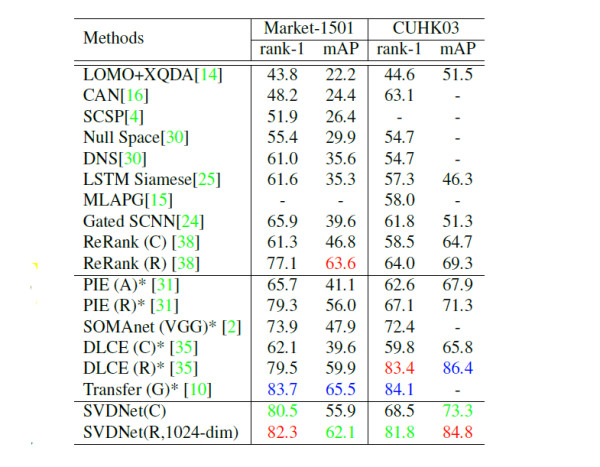
採取時下常用的一些預處理及數據增強後,SVDNet水平進一步提高。例如在market-1501上,在採用256✖️128這樣的圖像尺寸之後,resnet-backboned SVDNet能夠達到約84+%的rank-1準確度、65+%的mAP。進一步採用random crop數據增強後,能夠達到88% R-1 accuracy和 68%的mAP。在DukeMTMC-reID數據集上,SVDNet的表現相對更爲搶眼。
另外,值得一提的是,SVDNet在caffenet這種老古董網絡結構上也取得非常不錯的性能。這個特點在其他方法中通常是難以做到的(當然,知識蒸餾等方法或許也能達到)。
六、有趣的關鍵
——爲什麼用SVD來對W去相關
關於爲什麼用SVD來對W進行去相關,文中簡單做了一些證明:任意兩個樣本x1和x2,給定它們在EigenLayer之前的特徵h,考察它們在線性投影后的距離,用W(=USV‘)和US作爲線性投影層的權矩陣,兩種情況下,樣本間的距離是嚴格保持不變的。而用其它一些去相關方法,樣本間的距離發生改變,且實驗驗證均降低了「去相關操作」後的reid性能。詳細實驗和推導證明見論文。
文中關於上述保距去相關的證明公式非常明瞭,然而,「想」一個做法比「證明」一個做法遠遠要難的多。作者這個做法其實最早來自於一個直觀解讀:CNN的每個線性層把輸入投影到了新的特徵空間,CNN在訓練過程中,學到了很有鑑別力的投影基向量,也就是W中的各個權向量。以及一個思考:如果CNN告訴我們,一組權向量非常好,但是,CNN有點語無倫次、重複累贅,能不能讓CNN清晰地告訴我們,這組權向量所代表的那些投影基向量,其等效的本質(正交基)是什麼?
舉個極端的例子,假設某一層的權向量有3個,並且是是2維的,分別是v1=(0,1),v2=(0,1),v3=(1,0),顯然,這個權向量結果是不合理的,因爲肯定只需要2個權向量就足夠了,那麼,問題來了,CNN認爲(0,1)和(1,0)兩個投影方向上的結果是否同樣重要呢?我們是否可以簡單地保留v1和v3,直接丟掉v2呢?我們直覺上會覺得,不是這樣的,CNN試圖告訴我們,在(0,1)上的投影結果更重要,SVDNet中的這個去相關方法,就是將CNN學到的投影向量轉換到一組正交基上、並完全尊重、採納CNN學到的知識本質的方法。
PCA代替SVD,會更好嗎?
關於SVD去相關,還有另一個有趣的討論,是在paper 得到初審結果之後,一位審稿人提出的,而這個問題,也被不少讀者提出:那就是,如果對W進行PCA,也能得到一個正交的矩陣,而且在其它數據處理的地方,經驗通常是:PCA總是優於SVD。那麼,對W進行PCA到底行不行?用W進行PCA會不會更好?筆者認爲這是一個非常棒的問題。
首先,用PCA對權向量進行去相關,本身是完全可以的,正如文中對比的QR分解等方法一樣。而且PCA去相關,同樣可以嵌入到RRI之中,不斷提高SVDNet的性能。筆者在rebuttal中,做了實驗,用PCA代替SVD,能夠獲得僅僅輕微低於SVDNet方法的性能。但是,大家應該注意到,PCA和SVD雖然數學意義非常不同,但是,二者在具體運算上,是很相似的:PCA多一個0-均值化運算。而實際上,權向量本身是非常接近0均值的,因此,兩種方法在最終效果上比較接近,其實是非常自然的。
然而,筆者還想指出,在SVDNet的去相關操作中,只有使用SVD是嚴格的、具有數學意義的,而PCA不是。首先,簡單地來看文中的公式:用US去替代W是保證替換權矩陣後、任意兩個樣本的距離不發生改變,因此保留了CNN原有的鑑別能力,這是非常嚴格的。更重要的是,PCA和SVD在去相關時的數學意義完全不同,看如下的示意圖:
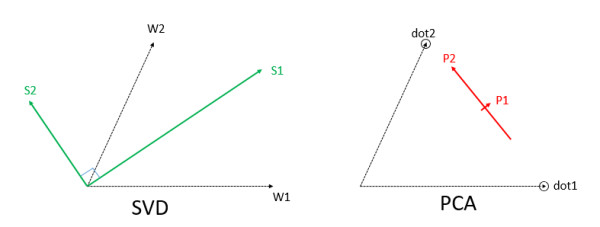
假設CNN學到了一個2X2的權矩陣,即有2個權向量,分別是W1和W2。現在,我們分別用SVD和PCA對W這個矩陣進行處理,SVD會得到左邊所示的兩個綠色正交向量S1和S2,S1方向上的投影結果將會被乘以相對較大的權係數;PCA則會得到右圖所示的兩個紅色正交向量(實際上,P1的向量長度會是0,即P1方向上的投影結果無足輕重)。在這個示意圖中,顯然,PCA是不合理的:如果CNN認爲黑色的W1和W2是重要的投影方向,那麼,直觀上我們也能感受到,S1(或者P1)方向上的投影結果將是非常重要的。而且,PCA在得到P1和P2時,實際上不是把W1和W2當成兩個向量來處理。PCA實際上是把W1和W2當成兩個點的座標,求這兩個點散佈最大的方向(P2>P1),這樣做是缺乏數學意義的。
七、另一個直觀解讀
本文對CNN得權向量,除了做空間上的投影解讀外,還暗示了一種解讀,在文中受篇幅限制未能展示,那就是——權向量實際上是用於產生特徵的模板。以caffenet爲例,當我們採用FC7的輸出作爲特徵時,實際上是在拿FC6的特徵去與FC7的4096個模板進行相似性比較(向量內積運算),並將4096個相似值作爲最終的特徵。在這個意義上,SVDNet可以認爲是讓獲取特徵的模板變得更爲豐富。利用Yosinski在2015年ICML[1311.2901] Visualizing and Understanding Convolutional Networks中提供的深度特徵可視化工具,我們可以對最大激活指定神經元的輸入進行可視化,從何直觀感受一下這些潛在模板的真面目。

上圖中,第一行展現的是5個高度相關的權向量所代表的的神經元所對應的模板圖像,第二行展現的是正常訓練方法中,挑選出的5個不相關權向量所代表的神經元所對應的的模板圖像,第三行則是通過SVDNet訓練方法後,任意的5個權向量對應的模板圖像。一個直觀感受是:在baseline方法中,隱含了大量高度相似的模板圖像,而經過SVDNet之後,所有的模板變得不相像,因此特徵更加豐富了起來。
八、在其它視覺任務上的推廣
到這裏,大家應該同意,SVDNet並沒有專門針對行人的固有特點做量身定製的分析與優化。從上圖,我們也可以直觀感受到,SVDNet訓練得到的神經元更加豐富,達到了的降低過擬合的作用。這種機制在其它視覺任務上或許也有一定的效果。我們還在探究之中。從目前的實驗結果來看,SVDNet在分類任務上有一定的提高效果。在Cifar-10分類任務中,用resnet-20做baseline,rank-1 accuracy從91.8%提高到了93.5%。
