開放地址:https://github.com/jacobeisenstein/gt-nlp-class/tree/master/notes

Eisenstein 將這一本非常完善的教材稱之爲「Notes」,它是在喬治亞理工大學學習自然語言處理相關領域所需要了解的基礎。例如在介紹自然語言處理理論與方法的課程 CS4650/7650 中,這本開放書籍就作爲標準的課程教材。
CS4650/7650 2018 春季課程需要閱讀 GitHub 目錄下 eisenstein-nlp-notes-jan-10-2018.pdf 文件,而另外一個文件 eisenstein-nlp-notes.pdf 會包含一些章節上的更新,不過它會在整個學期內進行。Eisenstein 表示這本開放書籍也可以用於其它研究或課程,書籍上的任何誤差或反饋都能直接發郵件給作者。
自然語言處理是令計算機能訪問人類語言的一組方法。在過去的十年中,自然語言處理已經深入了我們的日常生活:自動機器翻譯在網站和社交媒體中已經無處不在、文本分類確保了電子郵箱在海量垃圾郵件中屹立不倒、搜索引擎已經不再只是字符匹配與網絡分析,它已經能理解高維度的複雜語言,還有近來對話系統的興起也令信息的分享與交互更高效。
這些強大的應用其實都基於一套通用的思想,即利用算法、語言規則、邏輯和統計知識理解自然語言。這本書的目的是提供這些思想與技術的基礎,並應用於各種實際的任務中。此外,這本書除了詳細的概念與算法,同時還包括一些高階主題,讀者可按需求學習與閱讀。
這本書的主要章節如下可分爲四部分:
學習:這一章節介紹了一套機器學習工具,它也是整本教科書對不同問題建模的基礎。由於重點在於介紹機器學習,因此我們使用的語言任務都非常簡單,即以詞袋文本分類爲模型示例。第四章介紹了一些更具語言意義的文本分類應用。
序列與樹:這一章節將自然語言作爲結構化的數據進行處理,它描述了語言用序列和樹進行表示的方法,以及這些表示所添加的限制。第 9 章介紹了有限狀態自動機(finite state automata)。
語義:本章節從廣泛的角度看待基於文本表達和計算語義的努力,包括形式邏輯和神經詞嵌入等方面。
應用:最後一章介紹了三種自然語言處理中最重要的應用:信息抽取、機器翻譯和文本生成。我們不僅將瞭解使用前面章節技術所構建的知名系統,同時還會理解神經網絡注意力機制等前沿問題。
自然語言處理其實與很多學科都有關係,包括最直接的計算語言學、機器學習和統計學等。其實計算語言學基本上就等同於自然語言處理,它關注於設計並分析表徵人類自然語言處理的算法。而我們熟知的機器學習正好爲這些「表徵」提供算法支持,例如在自然語言建模中,機器學習提供了 n-gram 和循環神經網絡等多種方法預測最自然的語句。
在 Eisenstein 的這本書中,有非常多值得我們仔細探討的主題,例如如何基於簡單的感知機或支持向量機進行線性文本分類、如何使用循環網絡實現語言建模,以及序列標註任務中的維特比算法和隱馬爾科夫鏈等知識。但限於本文只簡要介紹這本書,因此我們主要介紹 Eisenstein 所述的自然語言處理三大主題。
自然語言處理的三大主題
自然語言處理涵蓋了非常多的任務、方法和語言現象。雖然很多任務之間都無法進行比較,但還是有一些公共的主題。基本上,自然語言處理包括學習與知識、搜索和學習以及 NLP 中關係式、組合式和分佈式的觀點。
學習與知識
近來深度模型在計算機視覺和語音識別等方面取得的成果促進了端到端學習方法的發展,傳統機器學習中基於光學和音韻學等經過特徵工程的特定表示方法已經不再流行。但是,很多機器學習基本只逐元素地處理自然語言,語法解析樹等語言學表徵仍然沒有像視覺中的邊緣檢測器那樣有高效的表示方法。語言學家也通常會討論能編碼一組專門用來促進語言理解和生成抽象概念的「語言能力」,但不管這些是不是合理,在訓練數據有限的情況下語言結構尤其重要。
現在其實有很多方法將自然語言處理中的知識與學習結合在一起,很多監督式的學習系統利用工程化的特徵,將數據轉化爲有利於學習的表徵。例如在文本分類任務中,識別每一個詞的詞幹可能會非常有用,因此這樣的學習系統可以更容易概括相關術語,例如鯨魚和捕鯨等。這在很多複雜語言中非常有用,因爲複雜的詞綴通常都添加在詞幹的後面。這些特徵可以從手工處理的數據中獲得,例如將每個單詞映射到單一表單的字典。此外,特徵也可以從一般任務的語言處理系統獲得,例如從建立在有監督機器學習的語法解析或詞性標註等模型獲取。
學習和知識的另一項結合即體現在模型結構:我們建立的機器學習模型架構受語言理論的影響。例如在自然語言中,句子的組織通常描述爲構成性的,語義較小的單位逐漸構成語義較大的單位。這個想法可以加入深度神經網絡體系架構中,並使用當代技術進行訓練(Dyer et al., 2016)。
目前,有關機器學習與語言知識相對重要性的爭論愈演愈烈。沒有機器學習研究者願意聽到他們的工程學方法是不科學的鍊金術,語言學家也不希望聽到他們所尋找的一般語言學結構與原理和大數據無關。然而這兩種類型的研究顯然都各有發展空間,我們需要知道端到端的學習還能走多遠,同時還需要繼續研究能泛化到各種應用、場景和語言的語言學表徵。
搜索和學習
很多自然語言處理問題在數學上都可以表述爲最優化問題的形式:
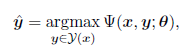 其中 x 是屬於集合 X 的輸入;y 是屬於集合 Y 的輸出;φ是評分函數,將集合 X*Y 映射到實數上;θ是φ的參數向量;y hat 是預測輸出,其值的選擇需要使評分函數最大化。這種形式化定義在通常的監督機器學習問題中是很普遍的,而在自然語言處理中,輸入-輸出對可能是文本-情感,或不同語言的翻譯等。
其中 x 是屬於集合 X 的輸入;y 是屬於集合 Y 的輸出;φ是評分函數,將集合 X*Y 映射到實數上;θ是φ的參數向量;y hat 是預測輸出,其值的選擇需要使評分函數最大化。這種形式化定義在通常的監督機器學習問題中是很普遍的,而在自然語言處理中,輸入-輸出對可能是文本-情感,或不同語言的翻譯等。
在這種形式化定義下,語言處理算法有兩個不同的模塊,即搜索和學習:
搜索模塊即找到使評分函數φ最大化的預測輸出,當搜索空間足夠小(即數據量較小)或評分函數能分解成幾個較容易處理的部分時,這很容易。但通常情況下,評分函數的結構複雜得多,並且在語言處理算法中,輸出通常是離散型的,這時搜索通常依賴於組合優化機制。
學習模塊即尋找參數向量θ,一般通過處理標記數據對得到。和搜索一樣,學習也是通過優化框架進行。但由於參數通常是連續的,因此學習算法依賴於數值優化。
將自然語言處理算法分成兩種不同的模塊可以使我們能重用多種不同任務和模型的通用算法,既聚焦於模型設計,同時又能利用過去在搜索、優化和學習問題的研究成果。
當模型能分辨細微的語言差異時,稱爲具有表達性(expressive)。表達性通常需要在學習和搜索的效率之間進行權衡。很多自然語言處理的重要問題都需要表達性,其計算複雜度隨收入數據的增加指數式增長。在這些模型中,確定性的搜索通常是不可行的。其難解性使得明確分離搜索和學習模塊變得很困難:如果搜索需要一系列啓發式近似,那麼學習在這些特定的啓發式下工作良好的模型會更有利。這啓發了一些研究者在搜索和學習中採用更加集成化的方法。
關係式、組合式和分佈式的觀點
任何語言元素(例如單詞、句子、段落甚至發音)都可以至少用三個觀點來描述。考慮單詞「記者」:「記者」是「職業」的子範疇,「主持人」是「記者」的子範疇;此外,記者執行的是「新聞工作」,這又是「寫作」的子範疇。這種對意義的關係式的觀點是語義本體論的基礎,例如 Word-Net 枚舉了單詞和其它基本語義單元之間的關係。關係式的觀點具有強大的推理能力,但在計算上很難形式化,通常單詞的含義是不獨立於具體場景的。
某些單詞之間的關係可以通過書寫上的相似性和組合性而互相聯繫,例如複數形式、組合型單詞等。進一步,在對句子和段落的分析中,通過單詞的組合和句子的組合來得到完整含義。此即組合式的觀點。組合觀點的威力在於它爲理解完整文本和對話提供了路線圖,通過單一的解析透鏡,從最小的部分開始逐步得到完整的含義。
對於某些不可分解的單詞,組合觀點不能提供很多幫助,但可以通過上下文來確定其含義。此即分佈式的觀點。它還可以幫助找到意義相似的不同單詞。分佈式的觀點可以從未標記的數據中學習含義。和關係式以及組合式的語義不同,其並不需要手動標註或專家知識。因此,分佈式語義覆蓋了很大範圍的語言現象,但是精確度不高。
關係式、組合式和分佈式的觀點對於語言含義的理解都有貢獻,三者對於自然語言處理都是很重要的。目前,它們之間的協作並不容易,各自使用的表徵和算法較難兼容。
最後,Eisenstein 表示閱讀這本書也需要一些背景知識:
數學與機器學習:這本書需要多元微分學和線性代數的基礎知識,包括函數微分、偏微分與向量和矩陣的運算等。讀者也應該熟悉概率論與統計學,包括基本分佈、數字特徵、參數估計和假設檢驗等。
語言學:除了語法基本概念,如名詞和動詞等,這本書並不要求我們接受過語言學方面的訓練。整本書會根據需要在各章節中引入語言學概念,包括形態和句法學(第 9 章)、語義學(第 12、13 章)和語篇學(第 16 章)。
計算機科學:這本書主要面向計算機科學的學生與研究者,讀者應該瞭解一些關於算法和複雜性理論分析的入門課程。此外,讀者也需要了解一些算法時間和內存成本的漸進分析,即簡單的動態規劃內容。
