選自arXiv
參與:蔣思源、路雪
本論文對強化學習頂尖試驗結果的復現性進行了詳細的探討,並討論了超參數和隨機種子等變量對強化學習模型復現性的重要影響。除此之外,作者還對復現實驗所面臨的挑戰和實驗技巧做出了詳細的論述。我們簡要介紹了該論文。
論文地址:https://arxiv.org/abs/1709.06560

近年來,深度強化學習(RL)被用於解決很多領域中的難題,並取得了令人矚目的成績。爲了保持快速發展的局面,復現(Reproducing)已有的研究並準確評估新方法所帶來的進步是很重要的。可惜,頂尖的深度強化學習方法很少能被簡單的復現。尤其是,標準基準環境中的不確定性和不同方法之間的內在差異導致研究中的結果難以理解。如果實驗過程缺乏顯著性的度量和嚴格的標準化,則我們很難確定先前頂尖技術取得的進展是否有意義。在這篇論文中,我們研究了復現實驗所面臨的挑戰、合適的實驗技巧和報告流程。通過與常見基準進行對比,我們闡釋了報告中度量方法和結果的可變性,同時提出了使深度強化學習未來的研究成果更易復現的指南。我們希望減小研究人員在不可復現和易誤解的結果上花費精力,並引起大家對如何使該領域持續發展進行討論。
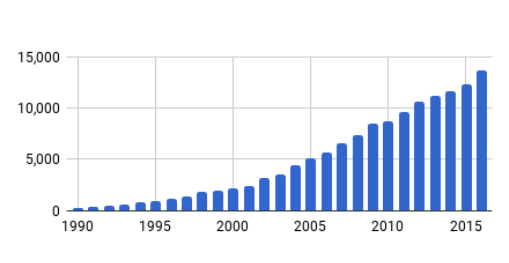
圖 1:已發佈的強化學習論文增長趨勢圖,展示了每年(x 軸)強化學習相關論文(y 軸)的數量。
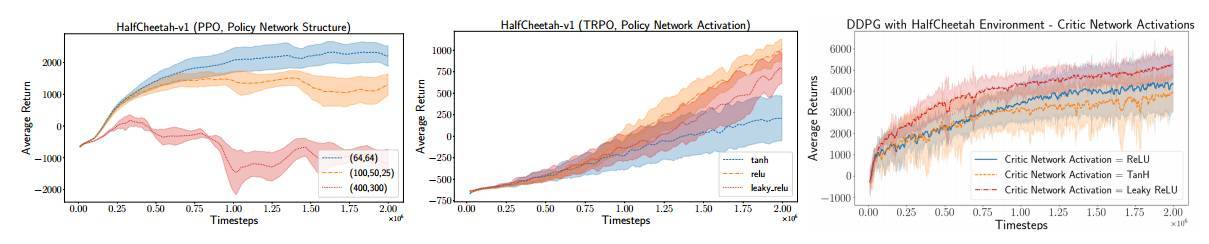
圖 2:策略網絡結構(Policy Network Structure)和激活函數 PPO(左)和 DDPG(右)的作用。
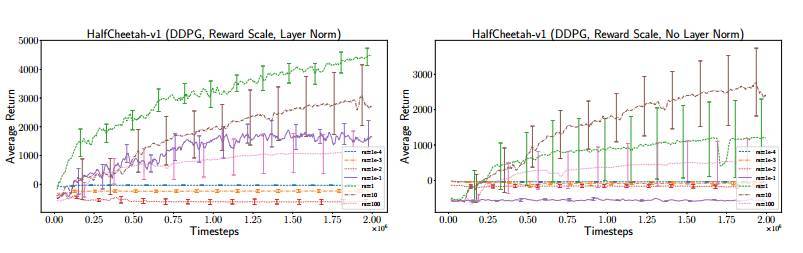
圖 3:DDPG 在 HalfCheetah-v1 上的獎勵尺度,左圖有層範數(layer norm),右圖無層範數。
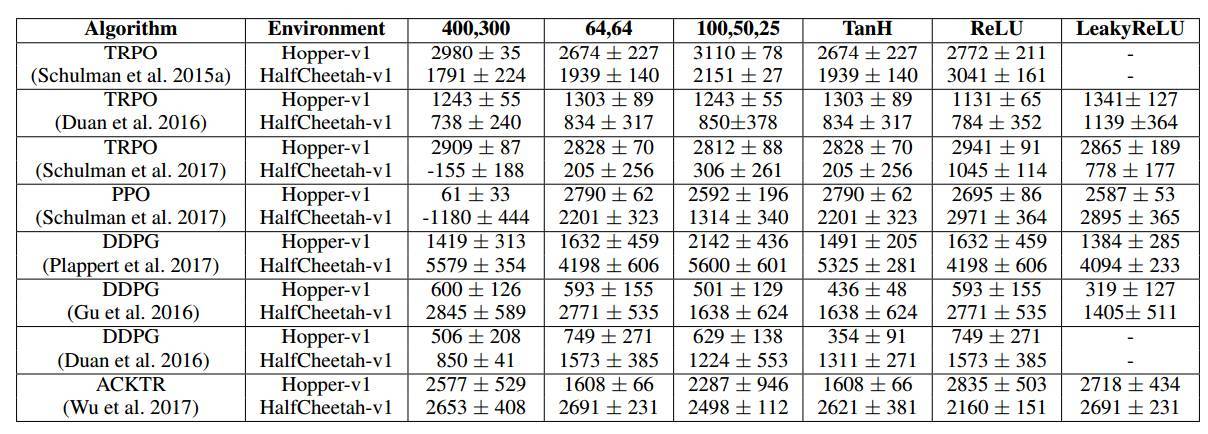
表 1:我們的策略架構在不同的實現和算法中的排列結果。圖中爲 5 個返回試驗結果的最終平均值 ± 標準誤差。在 ACKTR 中,我們使用 elu 激活函數代替 leaky relu。
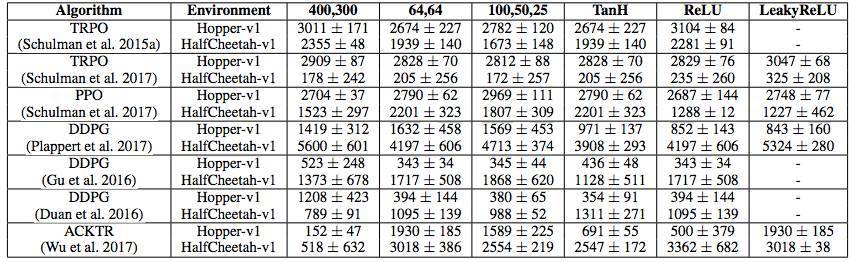
表 2:我們的價值函數(Q 或 V)架構在不同的實現和算法中的排列結果。圖中爲 5 個返回試驗結果的最終平均值 ± 標準誤差。在 ACKTR 中,我們使用 elu 激活函數代替 leaky relu。
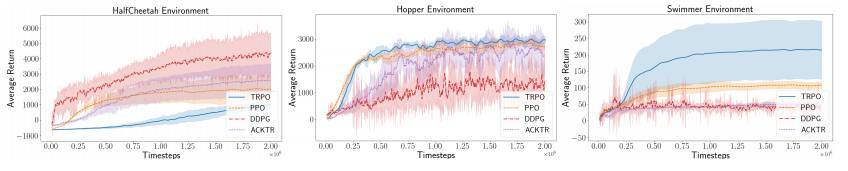
圖 4:多個策略梯度算法在基準 MuJoCo 環境組中的表現。

表 3:bootstrap 平均值和環境實驗子集的 95% 置信界限。使用了 10k bootstrap 迭代和樞軸法(pivotal method)。
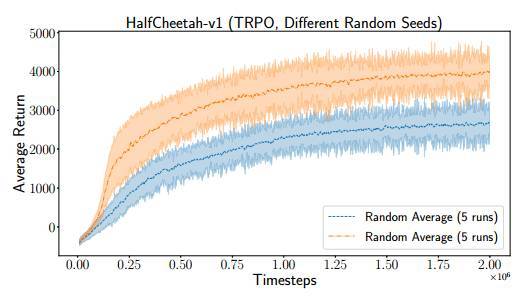
圖 5:在 HalfCheetah-v1 運行的兩個不同 TRPO 實驗,兩個實驗具備同樣的超參數,並在 5 個隨機種子的兩次中取平均值。
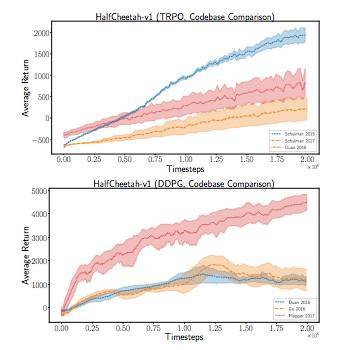
圖 6:使用默認的超參數集對比 TRPO 代碼庫。
結語
通過對連續控制的 PG 方法進行實驗和研究,我們探討了 RL 中的復現性(reproducibility)問題。我們發現非確定性的內在源(如隨機種子和環境屬性等)和外在源(如超參數和代碼庫等)都可能導致復現基線算法出現困難。此外,我們發現由於內在源(intrinsic source)而產生的高度多樣性結果加大了使用適當顯著性分析的需要。我們提出了多種方法,並在實驗子集上展示了它們的值。
我們能從這項實驗中得到什麼建議?
基於實驗結果和調研,我們可以提出一些通用建議。不同的超參數在相同的算法和環境中可以產生截然不同的影響,因此通過標準優化和超參數搜索找出與原報告中基線算法性能匹配的工作集非常重要。同理,新的基線代碼庫(baseline codebase)需要匹配原代碼庫的結果。總體而言,由於強化學習算法的試驗與隨機種子有很大的差異性,在比較性能時,許多試驗必須使用不同的隨機種子運行。通過不同隨機種子平均多次運行可以深入瞭解環境中算法性能的總體分佈(population distribution),除非隨機種子的選擇是算法的明確部分。
由於這些影響,進行適當的顯著性檢驗(significance testing)是非常重要的,因爲它可以確定更高的平均獎勵是否能夠代表實際上更優的性能。我們強調了幾種顯著性檢驗的形式,發現在考慮到置信區間時,它們能給出普遍預期的結果。此外,我們展示了 bootstrapping 和 power analysis 作爲了解試驗運行次數的可行方法,以對算法性能增益的顯著性做出明智的決定。然而一般來說,復現性最重要的步驟是報告所有基線對比方法和前沿工作的超參數、實現細節、實驗設置和評估方法等。如果沒有發佈與實現相關的具體細節,那麼在復現頂尖研究工作上浪費精力會給研究社區帶來困擾,並減緩研究進度。
未來的調研線路是什麼?
由於超參數對性能的極大影響力(特別是獎勵尺度/reward scaling),未來比較重要的調研路線就是構建超參數不可知(agnostic)的算法。這種方法可以確保在比較獎勵尺度、批量大小或網絡結構等算法未知的參數時,從外部源不會引入不公平性。此外,雖然我們調研了一系列顯著性度量(significance metrics),但它們可能並不是比較 RL 算法的最佳方法。
我們如何確保深度強化學習的重要性?
我們討論了影響強化學習算法復現性的多種不同因素。然而,RL 算法是以優化預先指定的獎勵函數爲中心的。這些獎勵函數類似於機器學習中的成本函數,而 RL 算法就是一種優化方法。由於某些算法特別容易受到獎勵尺度和環境動力學(environment dynamics)的影響,也許我們更需要強調 RL 算法在現實任務中的適應性,就像成本優化(cost-optimization)方法那樣。
也許新方法應該回答這樣的問題:哪些設定使該研究有用?在研究社區中,我們必須使用公平的對比確保結果是可控的和可復現的,但是我們同樣還需要用什麼方法能夠確保強化學習保持其重要性。