選自arXiv
作者:Kristopher De Asis等
在 AAAI 2018 接收論文列表中,來自阿爾伯塔大學強化學習和人工智能實驗室 Richard S. Sutton 等研究者的一篇論文提出一種新的多步動作價值算法 Q(σ),該算法結合已有的時序差分算法,可帶來更好性能。我們對此論文做了簡要介紹,更多詳細內容請查看原文。
時序差分(TD, Sutton, 1988)法是強化學習中的一個重要概念,結合了蒙特卡洛和動態規劃法。TD 允許在缺少環境動態模型的情況下從原始經驗中直接進行學習,這一點與蒙特卡洛方法類似;同時也允許在最終結果未出來時基於其他學得的評估更新評估結果,與動態規劃法類似。TD 法的核心概念提供一個構建多種強大算法的靈活框架,這些算法可用於預測和控制。
TD(λ) 算法結合一步 TD 學習(one-step TD learning)和蒙特卡洛方法(Sutton, 1988)。通過使用 eligibility trace 和 trace-decay 參數,λ ∈ [0, 1],創建了一系列算法。當λ = 1 時,就是蒙特卡洛方法,λ = 0 時,就是一步 TD 學習。
人們通常認爲多步 TD 方法是多個不同長度步長的收益平均值,通常與 eligibility trace 有關,和 TD(λ) 一樣。但是,也可以認爲它們是相關的 n 步備份的第 n 步收益(Sutton & Barto, 1998)。
Q(σ) 是 Sutton 和 Barto 2017 年提出的算法,該算法結合和推廣了現有的多步 TD 控制方法。該算法執行的採樣程度由採樣參數 σ 控制。當 σ = 1 時出現 Sarsa(全採樣),當 σ = 0 時出現樹備份(Tree-backup,純粹預期)。σ 的中間值構建的算法既有采樣也有預期。這篇論文展示了 σ 的中間值構建的算法優於 σ 等於 0 或 1 時的算法。此外,研究者還展示了 σ 可以進行動態調整,以輸出更好的性能。研究者將對 Q(σ) 的討論限制在沒有 eligibility trace 的 atomic 多步情況,但是使用複合備份(compound backup)是其自然擴展,也是未來研究的方向。Q(σ) 通常可用於在策略和離策略學習,但是該論文中的初始實驗僅研究在策略預測和控制問題。
論文:Multi-step Reinforcement Learning: A Unifying Algorithm

論文鏈接:https://arxiv.org/abs/1703.01327
摘要:結合看似完全不同的算法來生成性能更好的算法是強化學習的長久以來的目標。作爲主要示例,TD(λ) 使用 eligibility trace 和 trace-decay 參數 λ 將一步 TD 預測和蒙特卡洛方法結合起來。目前,有大量算法可用於執行 TD 控制,包括 Sarsa、Q-learning 和 Expected Sarsa。這些方法通常用於一步的情況中,但是它們可以擴展到多步以達到更好的性能。其中每一個算法都是針對不同任務的特定算法,沒有一個在所有問題上優於其他算法。本論文研究一種新的多步動作價值算法 Q(σ),該算法結合和推廣了這些已有算法,並對它們進行子求和(subsuming)作爲特殊案例。新參數 σ 被引入作爲算法每一步執行的採樣程度,其備份不斷改變,當 σ = 1 時出現 Sarsa(全採樣),當 σ = 0 時出現 Expected Sarsa(純粹預期)。Q(σ) 通常可用於在策略(on-policy)和離策略(off-policy)學習,但是本論文主要關注在策略的情況。實驗結果顯示 σ 的中間值會帶來現有算法的混合,性能優於 σ 在兩級的情況。該混合可以動態調整,帶來更好的性能。
可視化備份操作的常見方式是使用備份圖示,如圖 1 所示。
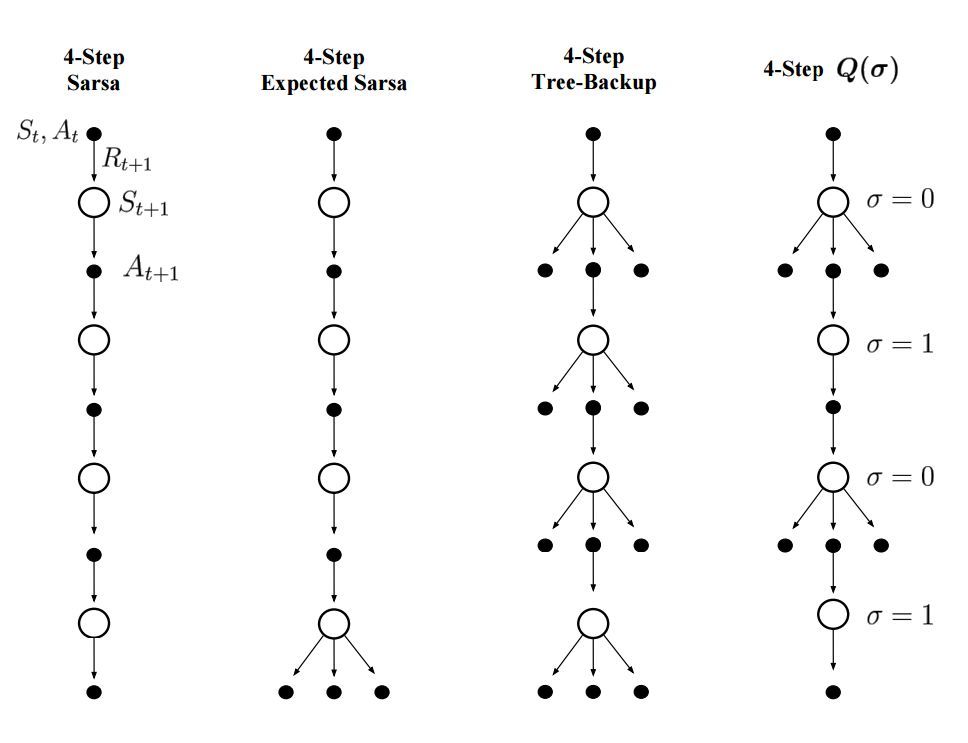
圖 1. atomic 4 步 Sarsa、Expected Sarsa、Tree-backup 和 Q(σ) 的備份圖示。我們可以看到 Q(σ) 基於 σ 的設置包含其他三種算法。
算法 1 展示了在策略 Q(σ) 的僞代碼:

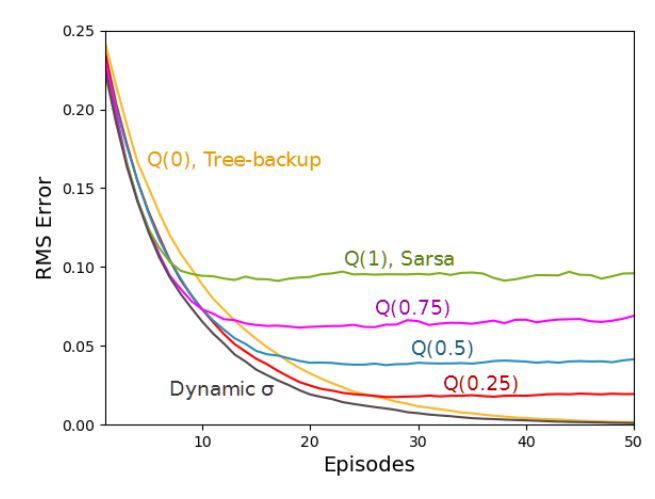
圖 3. 帶有 19 個狀態的隨機遊走結果。上圖從價值函數的 RMS 誤差的角度展示了 Q(σ) 的性能。結果是 100 次運行的平均值,標準誤差全部小於 0.006。Q(1) 具備最優初始性能,Q(0) 具備最優漸近性能,動態 σ 優於所有的固定 σ 值。
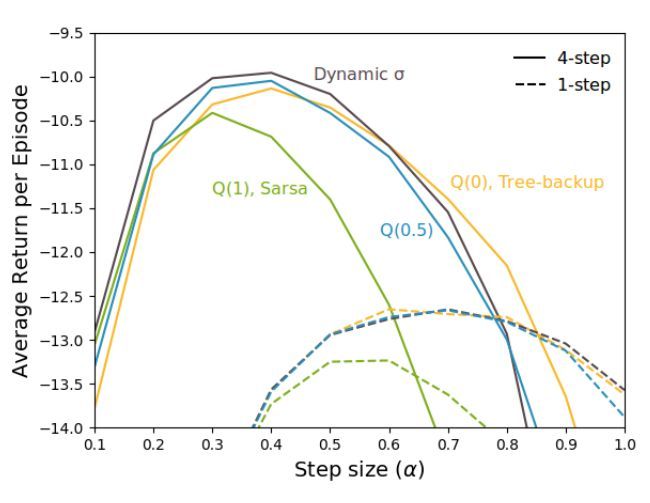
圖 5. Stochastic windy gridworld 結果。上圖通過對於不同 σ 值和α值的函數運行 100 episode 的平均收益展示了 Q(σ) 的性能。結果首先是選定 α 值的結果,然後是直線,之後是 1000 次運行的平均值。標準誤差低於 0.05,差不多是線的寬度。4 步算法的性能優於 1 步算法,σ 爲動態值的 Q(σ) 性能最好。
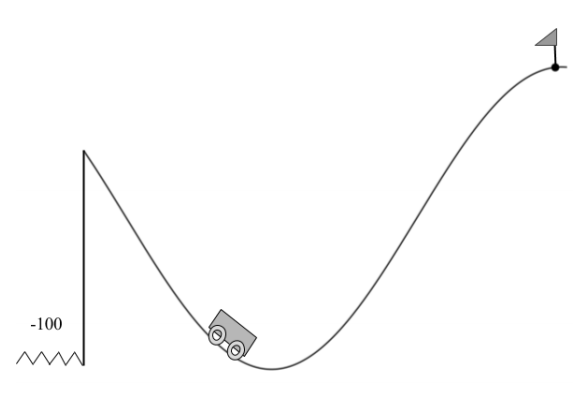
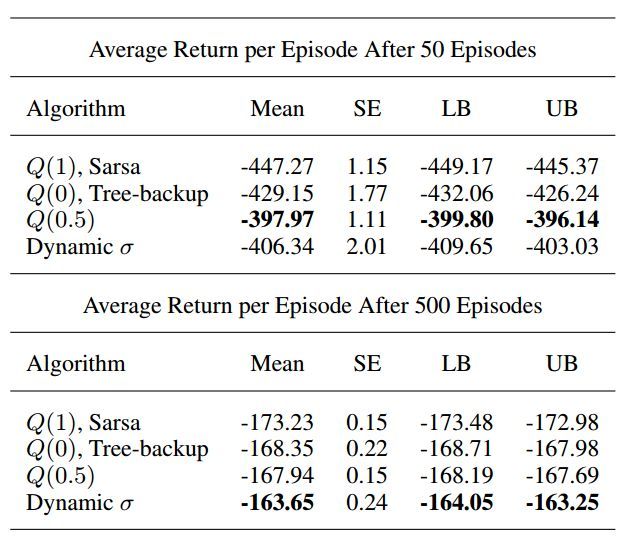
圖 6. 山崖環境。智能體的目標是在不掉下山崖的前提下駛過小旗。該智能體每一個時間步收到的獎勵爲 -1,而掉下山崖就會在山谷的隨機初始位置得到 -100 的獎勵。
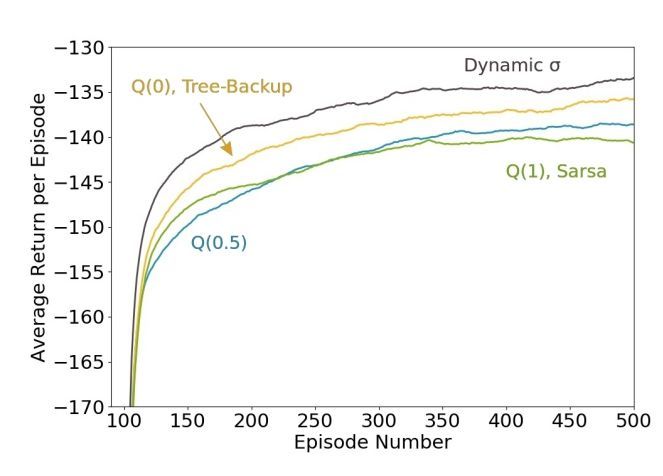
圖 7:山崖結果。上圖通過每個 episode 的平均回報展示了每個 atomic 多步算法的性能。爲了平滑結果,採用了適當均值的移動平均數,其帶有 100 個連續 episode 的窗口。σ 爲動態值的 Q(σ) 性能最好。