雷鋒網按:本文爲雷鋒字幕組編譯的技術博客,原標題 Introducing state of the art text classification with universal language models,作者爲 Jeremy Howard and Sebastian Ruder。
翻譯 | 翟修川 程添傑 整理 | 凡江
這篇文章向零基礎同學介紹我們最新的論文,和以前的方法相比,該論文展示瞭如何採用更高的精度和更少的數據自動地進行文檔分類。我們將使用簡單的方式解釋幾種方法:自然語言處理;文本分類;遷移學習;語言模型以及如何將這些方法有機結合。如果你已經對自然語言處理和深度學習很熟悉,那麼你可以直接跳轉到自然語言分類網頁獲取更多的技術鏈接。
1. 簡介
現在,我們發佈了「面向文本分類的通用語言模型微調」的論文(以下簡稱爲ULMFiT:https://arxiv.org/abs/1801.06146),預訓練的模型和完整的 Python 源代碼。在 2018 年計算語言協會年會上,該論文得到了行業內的評議並受邀演講。相關的鏈接,包括對於該方法深入探討的視頻,所有用到的 Python 模塊,預訓練的模型以及訓練你自己模型的腳本,請參考我們的 NLP 分類頁面(http://nlp.fast.ai/category/classification.html)。
與之前的文本分類方法相比,該方法有着明顯的提升,所有的代碼和預訓練模型允許任何人利用這種新方法更好的解決如下問題:
查找與法律案件相關的文件;
識別垃圾郵件,機器人和讓人反感的評論;
分類某種產品正面和負面的評論;
按政治傾向分類文章;
…...還有其他更多的問題。
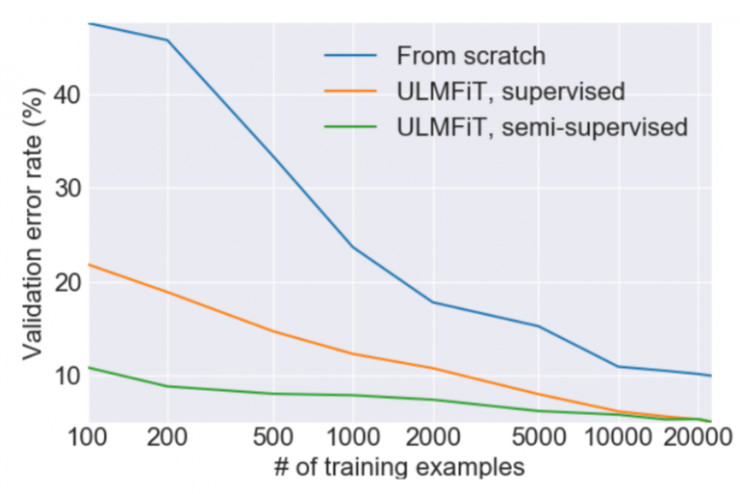
那麼,這項新技術究竟做了什麼呢?首先,讓我們想瀏覽一下論文的概要部分,看看它說了什麼,然後在文章的其他部分,我們逐步解析和學習它的準確含義:
遷移學習以及對計算機視覺產生了極大的影響,但是現有的自然語言處理方法仍然要求從頭開始特定任務的修改和訓練。我們提出了一種有效的遷移學習算法可以應用於任意的自然語言處理任務,並且引入對微調語言模型至關重要的方法。我們的方法在六種分類任務上優勢明顯,可以在大多數數據集上將錯誤率降低 18-24%。此外,這種方法僅僅使用 100 個有標籤的樣本,實現的性能可以媲美從頭開始訓練 100 倍以上數據達到的性能。
2. 自然語言處理,深度學習和分類
自然語言處理(NLP)是計算機科學和人工智能的一個領域,它指的是使用計算機來處理自然語言。自然語言是指我們每天都在交流使用的語言,比如英語或者中文,而不是專業語言,比如計算機代碼或者音樂符號。自然語言處理應用廣泛,比如搜索,個人助手,提取總結,等等。總體而言,自然語言處理具有挑戰性,因爲我們在寫代碼的時候使用的語言並不適合自然語言的細微差別和靈活性。你可能遇到這些有限的場景而感到尷尬,比如嘗試和自動電話應答系統交流,或者和像 Siri 這樣能力有限的早期的對話機器人。
在過去的幾年,我們已經看到了深度學習大舉進入以前計算機鮮有成就的領域。深度學習不是要求程序員定義好的一組固定規則,而是使用神經網絡直接從數據中學習大量的非線性關係。最值得注意的是深度學習在計算機視覺上的成功,例如 ImageNet 競賽上圖像分類的快速發展。
正如這篇的紐約時代雜誌文章廣泛討論的,在自然語言處理領域,深度學習也有一些成功,例如自動翻譯。成功的自然語言處理任務有一個共同點就是使用大量的有標籤數據可用於模型訓練。但是,到目前爲止,這些應用僅限於那些能夠收集和標記龐大數據集並且能夠擁有長時間在計算機集羣上處理的機構。
奇怪的是,在分類這個領域,深度學習在自然語言處理仍然面臨很大挑戰,而在這個領域深度學習在計算機視覺卻成績斐然。這是指將事物(例如圖片或文檔)分組(例如貓 vs 狗,或正面 vs 負面,等等)的問題。大量現實世界中的問題主要是分類問題,這就是爲什麼例如深度學習在 ImageNet 上的成功導致了許多的商業應用。在自然語言處理上,當前的方法能夠很好的識別,比如,當一部電影的評論是證明或者負面的,這就是一個情感分析的問題。然而,一旦事物變得模糊,模型就會混亂,因爲通常沒有足夠的標記數據可供學習。
3. 遷移學習
我們的目標是解決以下兩個問題:(1)在沒有大量數據或者算力的情形下解決 NLP 問題(2)使得 NLP 分類問題更容易。事實證明,我們兩個(Jeremy 和 Sebastian)從事於能夠解決這些問題的領域——遷移學習。遷移學習指的是,基於一個已經訓練好的針對某一特定問題的模型(例如基於 Imagenet 的圖片分類模型),來解決另一個相似的問題。一種常見的遷移學習方法是對原模型進行微調(例如把 CT 掃描結果分類爲癌變的和沒有癌變的——這是 Jeremy 實現的一個遷移學習應用,他據此創建了 Enlitic 公司)。因爲微調後的模型不需要從頭開始訓練,較不使用遷移學習的模型而言,它通常能夠使用更少的數據和算力來達到較高的準確率。
較爲簡單的遷移學習只使用單層的參數(這被稱爲嵌入),這在近些年十分流行,例如谷歌的 word2vec 嵌入。然而,實踐中完整的神經網絡模型包含很多層,因此只在單層使用遷移學習並沒有觸碰到問題的本質。
問題是,爲了解決 NLP 問題,我們應該從哪裏進行遷移學習呢?對這個問題的回答落在了 Jeremy 的手裏。當時他的朋友 Stephen Merity 發佈了 AWD LSTM 語言模型,這個模型較先前的語言建模方法有巨大的改進。語言模型是一個用於預測一句話中的下一個單詞是什麼的自然語言處理模型。例如,如果你的手機鍵盤能夠預測你輸入的下一個單詞是什麼,它就正在使用一個語言模型。語言模型很重要,因爲一個能夠較好地預測你即將要說的話的語言模型,通常具備很多的常識(例如,「I ate a hot」->「dog」;「It is a very hot」->」weather」),同時它也需要對語法、語義和其他自然語言成分有深刻的理解。而這恰恰就是我們在閱讀和分類一個文件時,所下意識使用的知識。
在實踐中我們發現,這種模式的遷移學習具備一些特點,使其能夠成爲自然語言處理領域遷移學習的一般方法:
能夠處理不同大小、數量和標記類型的任務
使用相同的模型結構和訓練過程
不需要認爲的特徵工程和預處理
不需要額外的域內文件或標記
4. 使之生效
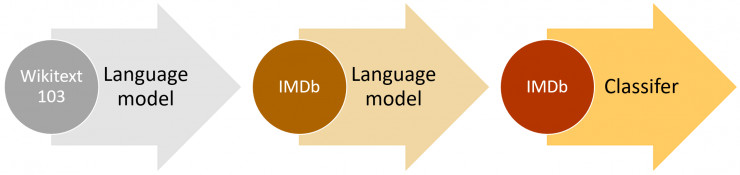
這種想法已經有人嘗試過了,但是需要數百萬的文件才能達到較好的性能。我們發現,通過更聰明地微調我們的語言模型,就能做的更好。特別地,我們發現,如果我們能夠控制模型訓練的速度,並對預訓練模型進行更新,使其不會遺忘它先前學習的特徵,從而模型能夠更好地適應新的數據集。讓我們感到驚喜的是,我們發現這個模型甚至能從非常有限的樣本中學習。在一個二元的文本分類問題中,我們發現,僅使用 100 個有標記樣本(以及 50000 個無標記樣本),就能達到和使用 10000 個有標記樣本從頭開始訓練一樣的效果。
另一個重要發現是,我們能夠使用任何大型語言的語料庫來創造一個通用的語言模型。這意味着我們能夠針對任何特定的語料庫進行微調。我們決定使用 Stephen Merity 的 Wikitext 103 數據集,該數據集爲一個經過預處理過的英文維基百科的較大子集。
自然語言處理的研究主要集於英語,在其他的語言上訓練模型會遇到相對應的困難。一般來說,非英語語言的公開數據集的數量很少。如果你想要在像泰語這樣的語言上訓練一個文本分類模型,你無疑需要自己蒐集數據。在非英語語言上搜集數據,通常意味着你需要自己標註數據,或者找到標註者來處理它們,就像 Amazon Mechanical Trurk 僱傭了很多說英語的標註者做衆包服務那樣。
有了 ULMFiT,我們就能更容易地訓練非英語語言的文本分類模型,我們唯一需要的就是維基百科(維基百科現在支持 301 種語言),以及少量的能夠被手動標記的文件,或者額外可選的非標記文件。爲了讓建模更容易一些,我們即將發佈一個 model zoo,裏面包含了很多語言的預訓練模型。
5. ULMFiT 的未來
我們已經發現了,在相同的設定下,這種方法在很多不同的任務中表現良好。除了文本分類之外,還有很多重要的自然語言處理問題,例如序列標記和自然語言生成,這些都是我們希望 ULMFiTz 在將來能夠幫助處理的問題。在完成了這些領域的實驗和建模之後,我們會更新這個頁面。
遷移學習的成功,以及基於 Imagenet 的預訓練模型的易獲得性,已經徹底改變了計算機視覺領域。很多人,包括創業者、科學家和工程師在內,正在使用微調後的預訓練模型來解決涉及計算機視覺的很多重大問題,包括提高非洲的作物產量和建造用於分類樂高積木的機器人。現在,相同的工具在 NLP 領域也出現了,我們希望類似的爆炸性增長在這個領域也能出現。
儘管我們已經展示了最先進的文本分類結果,爲了充分利用 NLP 遷移學習,還有很多工作要做。在計算機視覺領域,已經有很多重要的文章深度分析了遷移學習。特別地,Yosinski 等人試圖回答「深度神經網絡中的特徵可遷移性」問題;Hub 等人研究了「爲什麼 ImageNet 適合遷移」;Yosinski 甚至建立了一個可視化工具箱來幫助實踐者更好地理解他們模型中的特徵(見下面的視頻)
如果你在一個新的問題或數據集上嘗試了 ULMFiT 模型,我們十分高興能夠聽到這個消息!訪問深度學習論壇(deep learning forums),告知我們進展如何(如果在建模過程中遇到了問題,務必讓我們知曉)。
原文鏈接:http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html

雷鋒網(公衆號:雷鋒網)雷鋒網