近日,FAIR 研究工程師吳育昕和研究科學家何愷明聯名著作的一篇論文 Group Normalization 提到了一種新的訓練神經網絡的方法。該方法稱爲羣組歸一化(Group Normalization),試圖以羣組方式實現快速訓練神經網絡,這種方法對於硬件的需求大大降低,並在實驗中超過了傳統的批量歸一化方法。
批量歸一化和羣組歸一化
批量歸一化(Batch Normalization,以下簡稱 BN)是深度學習發展中的一項里程碑式技術,可讓各種網絡並行訓練。但是,批量維度進行歸一化會帶來一些問題——批量統計估算不準確導致批量變小時,BN 的誤差會迅速增加。在訓練大型網絡和將特徵轉移到計算機視覺任務中(包括檢測、分割和視頻),內存消耗限制了只能使用小批量的BN。在這篇論文中,作者巧妙提出了羣組歸一化 Group Normalization (簡稱 GN) 作爲 BN 的替代方案。

GN 將通道分成組,並在每組內計算歸一化的均值和方差。GN 的計算與批量大小無關,並且其準確度在各種批量大小下都很穩定。在 ImageNet 上訓練的 ResNet-50 上,GN 使用批量大小爲 2 時的錯誤率比 BN 的錯誤率低 10.6%;當使用典型的批量時,GN 與 BN 相當,並且優於其他標歸一化變體。而且,GN 可以自然地從預訓練遷移到微調。在進行 COCO 中的目標檢測和分割以及 Kinetics 中的視頻分類比賽中,GN 可以勝過其競爭對手,表明 GN 可以在各種任務中有效地取代強大的 BN。在最新的代碼庫中,GN 可以通過幾行代碼輕鬆實現。
背景介紹
批量歸一化已被證實爲深度學習中非常有效的組成部分,在很大程度上推動了計算機視覺領域的發展。許多實踐都證明了這一點,BN 使用(小)批計算的均值和方差對特徵進行歸一化,以簡化優化使非常深的網絡能夠融合。批量統計的隨機不確定性也可以作爲一個正則化器,它可以適用於泛化。BN 一直是許多最先進的計算機視覺算法的基礎。
儘管 BN 取得了巨大的成功,但其存在的弊端也是由於其獨特的歸一化行爲造成的。
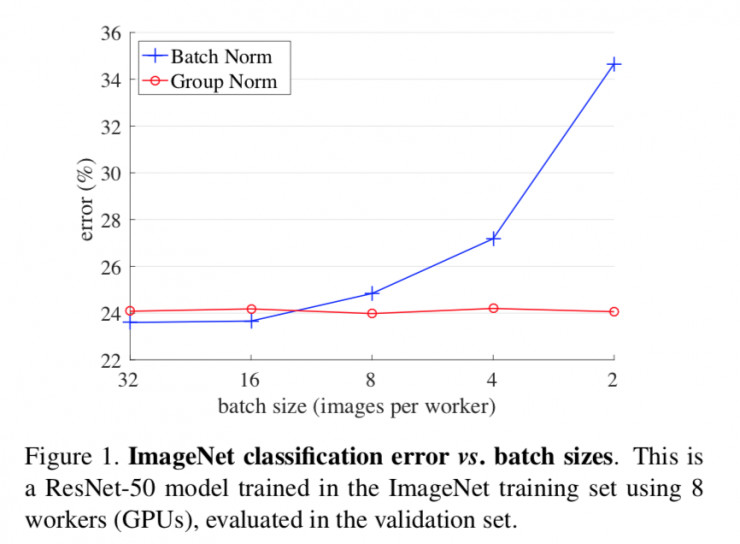
圖1. ImageNet分類錯誤與批量大小的對比圖,這是一個ResNet-50模型,使用8張GPU卡在ImageNet訓練集中進行訓練,並在驗證集中進行評估。
特別是,BN 要求有足夠大的批量才能工作。小批量會導致批量統計數據的估算不準確,並且減少 BN 的批量大小會顯著增加模型誤差(圖 1)。因此,最近的許多模型都是用較大的批量來進行訓練的,這些大批量都是很耗費內存的。反過來,訓練模型時對 BN 有效性的高度依賴性阻礙了人們用有限內存探索更高容量的模型。
計算機視覺任務(包括檢測、分割、視頻識別和其他基於此的高級系統)對批量大小的限制要求更高。例如,Fast / er 和 Mask R-CNN 框架使用批量爲 1 或 2 的圖像,爲了更高的分辨率,其中 BN 通過變換爲線性層而被「固定」;在 3D 卷積視頻分類中,時空特徵的出現導致在時間長度和批大小之間需要作出權衡。BN 的使用通常要求這些系統在模型設計和批大小之間作出妥協。
本文提出羣組歸一化(GN)作爲 BN 的替代方案。作者注意到像 SIFT 和 HOG 這樣的許多經典特徵是分組特徵並且包括分組規範化。例如,HOG 矢量是幾個空間單元的結果,其中每個單元由歸一化方向直方圖表示。同樣,作者提出 GN 作爲一個層,將通道劃分爲組,並對每個組內的特徵進行歸一化(圖 2)。GN 不用批量維度,其計算與批量大小無關。
GN 在大範圍的批量下運行都非常穩定(圖 1)。在批量大小爲 2 的樣本中,GN 比 ImageNet 中的 ResNet-50 的 BN 對應的誤差低 10.6%。對於常規的批量規格,GN 與 BN 表現相當(差距爲 0.5%),並且優於其它歸一化變體 。此外,儘管批量可能會發生變化,但 GN 可以自然地從預訓練遷移到微調。在 COCO 目標檢測和分割任務的 Mask R-CNN 上,以及在 Kinetics 視頻分類任務的 3D 卷積網絡上,相比於 BN 的對應變體,GN 都能獲得提升或者超越的結果。GN 在 ImageNet、COCO 和 Kinetics 上的有效性表明 GN 是 BN 的有力競爭者,而 BN 在過去一直在這些任務上作爲主導方法。
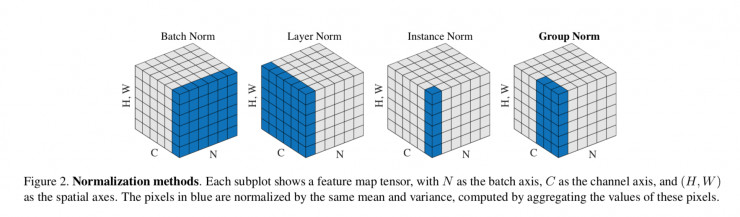
圖2
已有的方法,如層次歸一化(LN)和實例歸一化(IN)(圖 2),也避免了沿着批量維度進行歸一化。這些方法對訓練序列模型(RNN / LSTM )或生成模型(GANs)是有效的。但正如論文中通過實驗表明的那樣,LN 和 IN 在視覺識別方面取得的成功是有限的,GN 可以提供了更好的性能表現。甚至,GN 可以用來替代 LN 和 IN,來適用於有序或生成模型。這超出了本文的研究重點,但它對未來的研究提供了啓示。
視覺表現的通道並不完全獨立。SIFT ,HOG 和 GIST 的典型特徵是按設計分組表示的,其中每組通道由某種直方圖構成。這些功能通常通過每個直方圖或每個方向上的分組歸一化進行處理。VLAD 和 Fisher Vector(FV)等更高級的特徵也是羣組特徵,其中一組可以被認爲是相對於一個羣集計算的子向量。
類似地,沒有必要將深層神經網絡特徵看作非結構化向量。例如,對於網絡的 conv1(第一卷積層),期望濾波器及其水平翻轉在自然圖像上呈現類似的濾波器響應分佈是合理的。如果 conv1 碰巧近似學習這一對濾波器,或者如果通過設計將水平翻轉(或其他變換)設計爲架構 ,則可以將這些濾波器的相應通道一起歸一化。
越高層的圖層越抽象,它們的行爲也不那麼直觀。然而,除了方向(SIFT ,HOG )之外,還有許多因素可能導致分組,例如頻率,形狀,光照度和質地,它們的係數可以相互依存。事實上,神經科學中廣爲接受的計算模型是在細胞反應中歸一化 ,「具有各種感受野中心(包括視野)和各種時空頻率音調;這不僅可以發生在初級視覺皮層,而且可以發生在「整個視覺系統」。受到這些研究的啓發,我們提出了新的泛神經網絡的泛型歸一化。

圖3
GN 可以通過 PyTorch 和 TensorFlow 中的幾行代碼輕鬆實現,圖 3 顯示了基於 TensorFlow 的代碼。事實上,只需要指定如何計算均值和方差(「矩」),用歸一化方法定義的適當的座標軸。
實驗部分
在三個不同類型的數據集上做了實驗對比。分別是 ImageNet 中的圖像分類,COCO 中的對象檢測和分割,Kinetics 中的視頻分類。具體的實驗方法、實驗步驟,以及實驗結果,原論文中有詳細描述。
GN 在檢測,分割和視頻分類方面的改進表明,GN 對於當前處於主導地位的 BN 技術而言是強有力的替代。
總結
論文中把 GN 作爲一個有效的歸一化層且不用開發批量維度,同時也評估了 GN 在各種應用中的行爲表現。不過,論文作者也注意到,由於 BN 之前擁有很強的影響力,以至於許多先進的系統及其超參數已被設計出來。這對於基於 GN 的模型可能是不利的,不過也有可能重新設計系統或搜索 GN 的新超參數將會產生更好的結果。
此外,作者表明,GN 與 LN 和 IN 有關,LN 和 IN 兩種歸一化方法在訓練循壞(RNN / LSTM)或生成(GAN)模型中特別成功。這表明將來 GN 也會研究這些領域。另外作者還將探索 GN 在強化學習(RL)任務學習表徵方面的表現,其中 BN 在訓練非常深的模型中起着重要作用 。
論文地址:https://arxiv.org/abs/1803.08494