雷鋒網(公衆號:雷鋒網) AI 科技評論按:生成式對抗性網絡 GANs 是近幾年最熱門的機器學習範式之一,它「圖像生成效果好」和「訓練困難、效果不穩定」的特點吸引了許許多多研究者付出精力進行 GANs 的研究。雖然它在大尺寸圖像和圖像逼真程度方面的表現仍然有限,但仍然是目前最好的圖像生成範式。

所以當看到如此逼真的高分辨率生成圖像的時候,我們幾乎要以爲這是 GANs 的新突破。雖然圖中還有一些扭曲和不自然,但是細節和物體的結構已經比較完善。然而定睛一看,這樣的效果居然是一個單向的端到端網絡完成的!
介紹這項成果的論文「Photographic Image Synthesis with Cascaded Refinement Networks」(用級聯優化網絡生成照片級圖像)已被 ICCV 2017 收錄,這篇論文是斯坦福大學博士陳啓峯(第一作者)和英特爾實驗室視覺組主管 Vladlen Koltun 共同完成的;兩人此前也有合作。陳啓峯初中時就開始學習信息學,不僅2008年全獎就讀香港科技大學,2012年時更同時被斯坦福大學、哈佛大學、MIT、普林斯頓大學、UC 伯克利、UCLA等9所高校全獎錄取碩士博士學位,最終選擇了斯坦福大學,並於今年6月獲得計算機博士學位。
以下雷鋒網 AI 科技評論就對這篇論文做詳細的介紹。

想法提出
作者們的目標是生成大尺寸的、質量接近照片的圖像。這個目標有足夠的難度,現有的基於 GANs 的方法生成的圖像在尺寸和逼真程度上都有各種問題,而 GANs 本身訓練困難的特點更是雪上加霜。所以 GANs 的方法不適用。
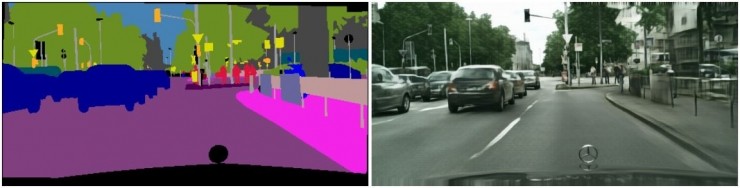
作者們想到了這樣一個點子,假如給定一個街道佈局,比如左圖這樣,不同的物體也做出了語意級別的區分,一個熟練的畫手可以很快根據這樣的佈局畫出一幅畫,專業的藝術家甚至可以可以據此創造出像照片一樣真實的畫作。那麼,能否把這樣的能力賦予一個計算模型呢?就是給定一個帶有語意物體佈局的場景(左圖),能否讓一個人工智能系統生成一張這個場景對應的照片級的圖像(右圖)呢?
另一方面,這個任務也有現有的成果可以類比,那就是圖像的語意分割。「從一張真實世界的圖像生成語義分割佈局圖像」,就和作者們的想法「從語義佈局圖像生成照片級圖像」互爲逆任務。既然圖像分割可以用端到端卷積網絡來做,那麼從「分割結果」生成圖像也就可以用端到端卷積網絡來做。
圖像生成任務有哪些特點
不過端到端網絡的總體結構還不足以保證圖像的質量。所以作者們在根據其它現有的網絡結構做了很多實驗以後,列舉出了三項他們認爲非常重要的特點,模型要滿足這三點纔能有足夠好的表現。
全局的協調性: 照片中物體的結構要正確,許多物體的結構都不是在局部獨立存在的,它們可能有對稱性。比如如果一輛車左側的剎車燈亮了,那右側的剎車燈也要亮。
高分辨率:爲了達到足夠高的分辨率,模型需要具有專門的分辨率倍增模塊。
記憶力 (Memory):網絡需要有足夠大的容量才能復現出圖像中物體足夠多的細節。一個好的模型不僅在訓練集中要有好的表現,也要有足夠的泛化能力,都需要網絡容量足夠大。
巧妙的網絡結構設計
爲了同時達到以上的三個特點,作者們設計了一個由多個分辨率倍增模塊組成的級聯優化網絡 CRN。
模型一開始生成的圖像分辨率只有 4x8,通過串接的多個分辨率倍增前饋網絡模塊,分辨率逐步翻番,最終達到很高的圖像分辨率(比如最後一個模塊把512x1024的圖像變成1024x2048)。這就是論文標題的「Cascaded Refinement Networks」的體現。這樣做的好處是,
1. 覆蓋大範圍的物體特徵一開始的時候都是在很小的臨近範圍內表示的,它們的總體特徵在一開始就是協調的,在分辨率逐步升高的過程中也能夠保持下來,就達到了「全局的協調性」。
2. 在提高分辨率的過程中,使用串接的多個前饋網絡模塊就可以對整個模型做端到端的訓練,如果這部分用 GANs 就沒辦法端到端訓練,而且分辨率選擇的靈活性也變差了。這樣就保證了「高分辨率」。
3. 增加更多的分辨率倍增模塊可以提高網絡容量,作者們表示只要硬件能夠支持就可以增加更多的模塊,現在他們實驗中用到的網絡有超過1億個參數,已經用盡了GPU的顯存空間,但是有明確的證據表明繼續增大網絡容量可以繼續提高圖像質量。這樣模塊化的網絡也就非常方便在硬件資源充足的情況下拓展網絡容量。
每個分辨率增倍模塊都在各自的分辨率下工作,它們的輸入有兩部分,一部分是降採樣到當前模塊分辨率的輸入語義佈局圖像 L,另一部分是上一級模塊的輸出特徵層 Fi-1 (最初的模塊沒有這一項輸入),其中包含若干個 feature map。輸出的 Fi 分辨率在輸入 Fi-1 的基礎上長寬都爲2倍。
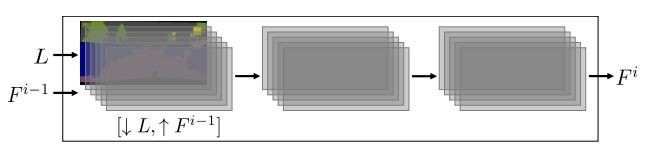
單個模塊的示意圖,L 和 Fi-1 爲模塊輸入;語義佈局圖像 L 需要降採樣,來自上一個模塊的 Fi-1 需要升採樣。
每個模塊都由輸入、中間、輸出三個特徵層組成,其中在輸入層直接翻倍分辨率,並且沒有使用升倍卷積,因爲那樣會帶來特徵的瑕疵。除了最後一個模塊要輸出最終結果外,每個模塊的每個層後都跟着一個 3x3 卷積層、正則化層和LReLU非線性層。
對於論文中測試的輸出分辨率爲 1024 x 2048 的模型,一共用到了9個分辨率增倍模塊。在每個模塊的特徵層中包含 feature map 數目的選擇上,第一個到第五個模塊爲1024,第六到第七爲512,第八個爲128,最後一個爲32。
訓練損失和訓練過程
「從語義佈局圖像生成照片級圖像」其實是一個約束不完全的問題,同一個佈局圖像對應的足夠真實的照片級圖像可以有許多種。所以即便在訓練時,作者們也是把佈局對象對應的照片稱爲「參考圖像」而已。
損失函數設計
對於約束不完全的訓練問題,作者們希望找到一個最適合的損失函數。若直接對訓練輸出和參考圖像做像素對像素的對比,會對足夠真實的內容也造成很大的懲罰,比如生成的車顏色不同的時候就會有很大懲罰,但這其實是不必要的。所以作者們選擇了內容表徵的方法,或者說是感知損失、特徵匹配的方法,跟視覺網絡中的特徵匹配激活對應,這樣就與參考圖像的低級特徵保持了足夠的距離。
具體的做法上作者們另闢蹊徑,藉助一個 VGG-19 圖像感知模型,提取它識別的圖像特徵中高低不同的某幾層作爲計算訓練損失的依據,從而同時涵蓋了圖像特徵中邊緣、顏色等低級細粒度特徵和物體、類別等高級總體佈局特徵,從而構建了全面、強力的損失函數。
生成多樣化的圖像
作者們認爲,既然「從語義佈局圖像生成照片級圖像」本身就會帶來多種結果,所以他們應當讓模型也生成多種不同的結果。他們首先嚐試了讓網絡生成多張不同的圖像然後從中選出最好的一張;然後最終更換爲了一個更強大的損失函數,它起到的作用類似於在所有生成圖像中分別選擇每個語義類別對應的圖像中最真實的那部分, 然後把它們全部拼在一起,從而讓最終的輸出圖像得到了非常高的真實度。下圖即爲加入多樣性損失之後,讓模型從同一個輸入生成的9張不同圖像。
 效果測試
效果測試
作者們把所提的CRN網絡與在同樣的測試條件下與其它網絡做了對比,包括 GANs(修改了鑑別器加入了語意分割損失)、全分辨率網絡(中間層也是全分辨率,與 CRN 相同損失函數)、自動編解碼器、只使用低級圖像空間損失的CRN、以及 圖到圖轉換GAN(論文中以Isola et al.指代)。
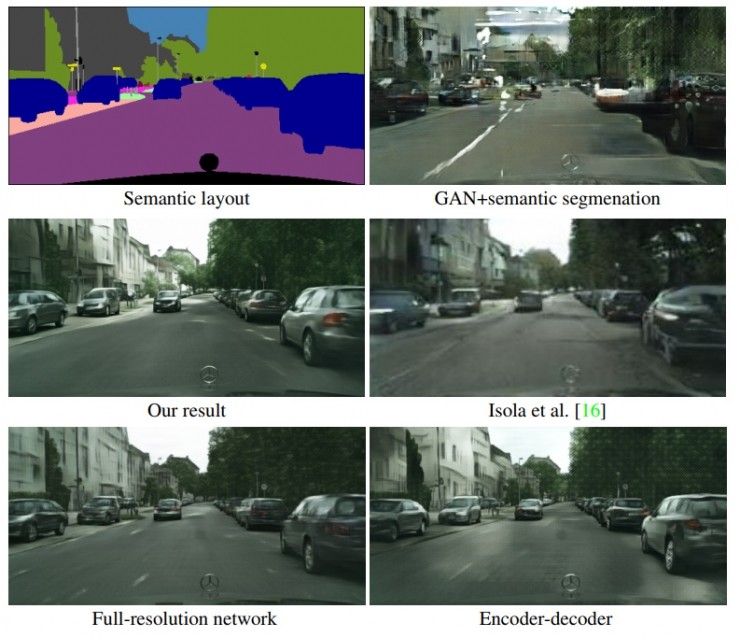
另一組對比

圖中可以看到,基於 Cityscapes 和 NYU 兩個數據集的測試中,論文中提出的 CRN 都取得了非常好的觀感,與其它的相比,簡直就像是真實的照片;所用到的訓練樣本數目也僅僅分別爲 3000 張和 1200張而已。
作者們也通過 Amazon MTurk 衆包平臺平臺進行了量化對比測試:每次給被試者提供兩張圖像,一張來自 CRN,一張來自其它網絡,看看他們有多高的比例認爲 CRN 的圖像更真實。

結果非常有說服力,只有採用了相同的損失函數的全分辨率網絡取得了與 CRN 接近的成績。這首先說明了作者們選擇的損失函數效果非常好,準確地訓練出了網絡構建重要特徵的能力;而另一方面因爲全分辨率網絡的中間層特徵太多,導致足夠 CRN 訓練 1024x2048 分辨率的顯存只夠全分辨率網絡訓練 256x512,這也體現了級聯優化模塊結構的優點。CRN 同時在分辨率和真實度上取勝。
泛化能力
我們可以看到,對於高質量的語義佈局輸入,CRN表現出了很高的水平。那麼模型的泛化能力如何呢?在與論文作者陳啓峯博士取得聯繫並表達了我們的疑問後,陳啓峯博士介紹了兩項模型泛化的結果。
粗粒度語義佈局輸入

可以看到,對於粗粒度的語義佈局圖像輸入,模型也維持了相當的表現,並沒有因此造成嚴重的細節損失;物體結構的完整和清晰程度有所下降的。
從GTA5遊戲生成圖像
作者們的另一個想法是把這項技術用來給遊戲生成真實的畫面,成爲一種新的渲染逼真遊戲畫面的方式。他們嘗試的遊戲是 GTA5,用 Cityscapes 數據集訓練模型以後,從 GTA5 抓取語義佈局作爲模型輸入,得到的結果同樣充實、逼真,單獨看畫面根本想不到和 GTA5 有任何聯繫。陳啓峯博士表示,「語義佈局圖很容易在遊戲裏抓取,這對未來遊戲或電影畫面生產可能會有深刻影響」。

總結
作者們也剪輯了一個視頻,集中展示了生成的畫面效果。
這篇論文用精彩的方法生成了高分辨率、高真實度的圖像,其中衡量真實度和提高生成圖像豐富性的方法有很高的借鑑價值。所提的方法很好地完成了「從語義佈局圖像生成照片級圖像」的任務,而且具有一定的泛化能力。我們期待論文中的技術在未來的研究中進一步得到發揚光大。
雷鋒網 AI 科技評論編譯。感謝陳啓峯博士對本文的補充!
論文地址:https://arxiv.org/abs/1707.09405v1
陳啓峯個人主頁:https://web.stanford.edu/~cqf/
項目地址:https://github.com/CQFIO/PhotographicImageSynthesis