雷鋒網按:喜歡機器學習和人工智能,卻發現埋頭苦練枯燥乏味還殺時間?這裏是,雷鋒字幕組編譯的Arxiv Insights專欄,從技術角度出發,帶你輕鬆深度學習。
原標題 Variational Autoencoders
翻譯 | 趙萌 陳世杰 字幕 | 凡江 整理 | 林尤添 編輯 | 吳璇
今天視頻內容主要圍繞變分自動編碼器展開。
一般的自動編碼器
首先介紹一般的自動編碼器,對於自動編碼器,它是輸入某種數據,例如說圖片或者高維向量,只要運行起來,數據通過神經網絡運算就會被儘量壓縮成更小的特徵值。
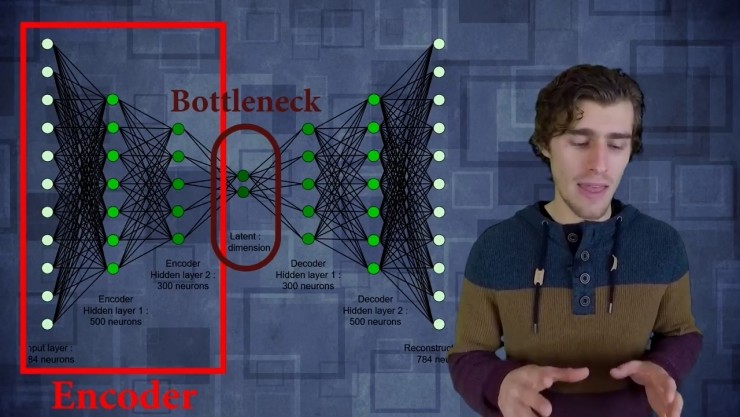
這個過程有兩個主要部分組成。
第一部分叫做編碼器:編碼器只是一層層的,它們可以是完全連接的層或者是卷積層。卷積層把輸入數據壓縮成特徵值,這就比輸入的數據具有更低的維度,這個就是bottleneck(瓶頸)。然後從bottleneck開始再一次用完全連接層或者卷積層來重構輸入數據。
然後是訓練的第二個部分:自動編碼器會簡單地根據解碼網絡重構數據,並簡單計算重構損失。然後通過輸入數據跟輸出數據進行逐個像素之間的對比,我們可以創建一個損失函數然後訓練網絡來壓縮圖片。顯然你可以使用全連接的簡單編碼器,但你也可以用卷積層置換出來,比如在處理圖片或者音頻的時候。這樣做的作用是,當訓練一個卷積網絡去編碼,解碼一堆圖像,實際上在創建一種全新的壓縮算法。
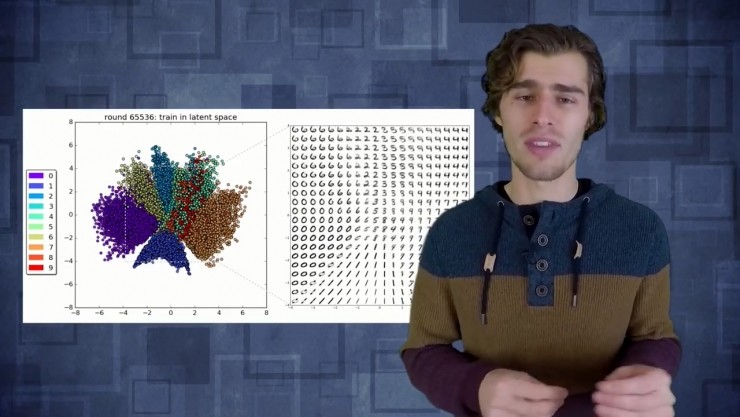
如果把這項技術用於MNIST手寫數字識別那將會很有趣,你會看到一些隱藏的特徵值節點實際上學到了什麼。如果我們改變隱含層特徵規模,我們只用2個特徵,意味着網絡中間的bottleneck只有2個變量,似乎我們能夠重構它們,但它們失真嚴重。失真的原因是你強行把整個圖片所有的信息壓縮成僅有的2個變量,那當你重構的時候就會失去一些細節。如果用更高維度的隱含層就可以重構一個更加清晰,更具銳度的圖片,但在bottleneck裏需要更多信息。
在自動編碼器裏有一些小技巧可以用來實現一些奇妙的東西。想象一下,本來是普通的MNIST手寫數字識別的數據集,它清晰又明瞭,但加入一系列噪音以後,再對噪音圖像進行計算,經過編碼網絡和bottleneck然後嘗試重構圖像,但不是重構噪音的圖像,而是重構原始的清晰圖像。用這些噪音跟清晰的數字訓練這個網絡,讓編碼器準確地得到噪音的邊緣,這就是我們所說的降噪自動編碼器。
舉個例子,在一個無噪音輸入圖像中簡單截取一個矩形區域刪去這個區域,把這個圖像輸入網絡裏,嘗試重構這個原始的完整圖像,這個技術就是所謂的神經網絡修復。也就是說你可以選取一小部分圖像然後刪掉再要求網絡重構在原來的圖像裏是什麼東西,用這個方法你可以做一些簡單的事情例如移除圖像水印,而且當你在拍一部電影的時候你也可以用這個網絡移除入鏡的汽車。

變分自動編碼器
在有了常規自動編碼器的基本概念之後,接下來介紹一下變分自動編碼器。變分自動編碼器的作用不是重構一個輸入的圖像,變成固定的向量,也不是把輸入數據變成某種分佈。在變分自動編碼器裏有一點不同的就是,你的常規深度向量C被兩個獨立的向量代替,一個代表分佈的平均值,另一個代表分佈的標準偏差,你需要一個向量聯通。所以你的編碼網絡唯一要做的就是在分佈裏提取樣本輸入解碼器。然後訓練變分自動編碼器的損失函數。

函數實際上包括2部分,第一部分代表重構損失這幾乎跟自動編碼器一樣,只是多了個期望值運算符,因爲我們要從分佈裏採樣。損失函數的另一部分是相對熵,需要確定的是要學習的分佈跟一般正態分佈的情況不要差太遠,然後嘗試讓你隱含層的數據分佈平均值接近0標準差接近1。
分離變分自動編碼器
在進行下一步之前,看一下使用變分自動編碼器能得到的可見結果。有一類新的變分自動編碼器有很多有價值的結果,它們叫分離變分自動編碼器。分離的含義是,當你想確定在隱含層分佈中不同神經節點的差異時,會發現它們不相關,因爲它們都在學習關於輸入數據不同的東西。所以爲了實現這一步,你唯一要改變的就是在損失函數里加一個超參數,衡量這個相對熵能在損失函數裏佔多大分量,所以在分離版本里自動編碼器將會只用一個有價值的特別的隱藏參數,如果對壓縮沒價值就仍然依照着原來的模式。

作者在Deepmind實驗室環境用的變分自動編碼器,讓你看到三維世界裏一個agent發揮了作用,它們壓縮輸入圖像,在兩個隱藏空間裏能看到agent,它們會重構這個空間,但你也可以開始改變隱藏變量然後看看對重構有什麼影響。結果就是,如果你用分離變分自動編碼器改變隱藏變量,實際上相當於一些非常有解釋性的東西。能看到改變第一個隱藏變量,實際上改變了樓面的顏色,但僅此而已,然後另一個隱藏變量對應於轉向左邊還是轉向右邊甚至能改變旋轉量,跟對象的特徵agent形成了對比。如果不分離的情況下改變了任何隱藏特徵值,圖片裏所有東西都開始燃燒這樣並不知道隱藏向量正在編碼什麼。
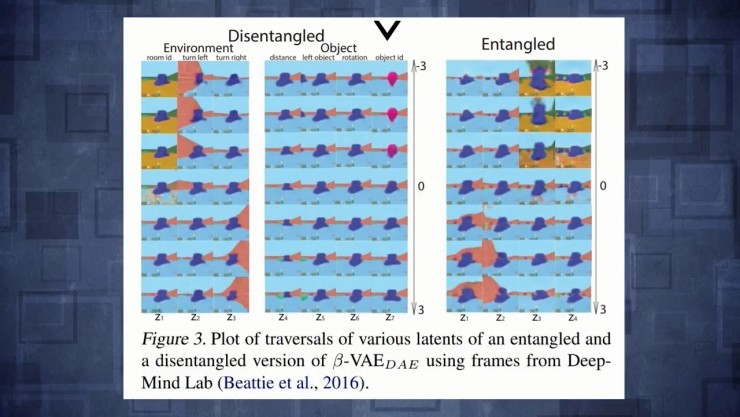
這裏是另一個例子如果你改變前面提到的隱藏空間的第一個變量臉部就會旋轉。如果你對普通變量做同樣的事或者對臉編碼,也會旋轉但會看到很多其他性質也會改變。

所以分離變分自動編碼器的必殺技就是,有一種網絡可以從高維空間提取有用的常規特徵並且利用起來,對於某些學習性任務想做的就是這些學到的特徵,將對訓練數據的框架形成概念。
一個人們常用的領域,例如說強化學習,因爲強化學習的整個問題就是你有非常稀疏的獎勵,它耗費很多時間去訓練,所以通過使用這個變分自動編碼器作爲某種特徵提取工具,希望能夠真正地在隱藏層上運行agent達到壓縮特徵值的目的,而不是在整個輸入空間所以在實踐中這樣做是非常平衡的。

如果你把隱藏空間分得太細你的網絡就會過擬合因爲你給它太多的自由,它可以學習如何重構你輸入的訓練數據,但它無法概念化一些在新情況下看不到的數據,另一方面,如果你分的太粗你實際上失去了許多在輸入數據中準確定義的細節,它們會在很多應用中損害性能。因爲最後我們希望訓練一個agentagent能夠通過壓縮大量信息理解世界,然後在隱藏空間學習有用的行爲。
參考文獻:
Disentangled VAE's (DeepMind 2016)
https://arxiv.org/abs/1606.05579
Applying disentangled VAE's to RL: DARLA (DeepMind 2017)
https://arxiv.org/abs/1707.0847
Original VAE paper (2013)
https://arxiv.org/abs/1312.6114
雷鋒網相關文章:
Yann LeCun最新研究成果:可以幫助GAN使用離散數據的ARAE
更多文章,關注雷鋒網(公衆號:雷鋒網)
添加雷鋒字幕組微信號(leiphonefansub)爲好友
備註「我要加入」,To be an AI Volunteer !

