按,本文作者是西北大學葉貴鑫,他爲 AI 科技評論撰寫了關於 CCS 2018 論文《使用少量樣本破解文本驗證碼》的獨家解讀,內容如下,未經許可禁止轉載。
1. 前言
相信大家在日常上網的時候都會遇到「千奇百怪」的驗證碼,而在種類繁多的驗證碼家族中,文本驗證碼是使用最廣泛的一種,也是我們遇到最多的一種驗證碼方案。近年來,隨着深度學習技術的突破性發展,文本驗證碼的安全性也受到了挑戰。通過收集大量目標網站的驗證碼,並訓練一個深度網絡模型,就可以實現對目標網站驗證碼的攻擊。爲了抵抗基於深度學習模型的攻擊,一方面,各大網站都採用諸如字符扭曲、粘連、旋轉,背景混淆,空心字體等多種複雜變換方案來提高文本驗證碼的安全性;另一方面,有些網站採用了諸如前端代碼混淆、關鍵代碼加密等反分析方式來防止驗證碼被惡意收集和自動爬取,進而通過增大攻擊的成本來降低驗證碼被攻擊的可能性。然而,上述兩種方式真的能夠增強驗證碼的安全性嗎?
接下來,我將介紹一篇ACM CCS 2018上的一篇基於少量樣本構建驗證碼求解器的論文:《Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach》,該論文是由中國西北大學的房鼎益、陳曉江教授團隊、北京大學以及英國蘭卡斯特大學聯合發表的。
論文地址:https://dl.acm.org/citation.cfm?doid=3243734.3243754
論文公開了部分源碼:https://github.com/yeguixin/captcha_solver
2. Idea的由來
我們在一次研究小組內關於AI的討論中瞭解到了Generative Adversarial Networks(GANs),當時我們瞭解到GANs不僅可以生成目標數據,而且其改進技術Conditional Generative Adversarial Networks(CGANs)還可以實現圖像自動標註的任務(如圖像風格間的轉換)。

圖 1:「RGB->油畫」轉換效果圖
既然GANs有強大的生成能力,那麼就可能生成海量與目標網站風格類似的驗證碼。CGANs既然可以實現圖像風格間的轉換(如圖1所示),那麼就能夠去掉圖像中的顏色,換句話說,就可以去掉驗證碼圖像中複雜的混淆背景。上述兩點設想對於減少訓練樣本、降低攻擊成本有至關重要的作用。具體地,如果能夠自動生成大量的驗證碼,就直接讓攻擊者從手動收集和標註驗證碼的繁重工作中解脫出來,進而降低攻擊成本;如果能夠去掉驗證碼中的背景,就能夠減少訓練樣本的數量,從而提高模型的識別率。

圖 2:預處理結果示例
然而,事情並沒有我們預想的那樣一帆風順。雖然CGANs可以有效地去除驗證碼的背景(如圖2所示)。但GANs的生成效果卻沒有想象中的好。GANs是通過隨機噪聲或高斯噪聲來生成數據的,並且訓練過程中需要大量的真實數據作爲參考,而當前驗證碼中加入了非常複雜的字符變換,若要訓練驗證碼生成模型,勢必需要更多真實驗證碼作爲參考。
既然使用隨機噪聲生成驗證碼需要大量的真實數據,那麼我們就開始考慮使用傳統驗證碼生成器去生成,將生成的驗證碼替換成隨機噪聲作爲GANs的輸入,讓GANs對生成的驗證碼做微調。然後使用鑑別器評估生成的驗證碼的風格是否與真實驗證碼風格類似,即生成數據與真實數據同分布。於是,我們首先將驗證碼參數化表示,即所用的字符、字符旋轉角度、扭曲程度、所用背景、所用字體等參數化,然後利用網絡自動調整生成參數。這樣就實現了數據的自動生成,減少了人工參與的工作量。利用生成的數據,就可以訓練驗證碼識別模型。爲了進一步降低生成數據與真實數據之間的差別,我們使用了遷移學習技術調優模型,從而提高模型的泛化能力和識別精度。於是,我們的整個Idea就這樣產生了。
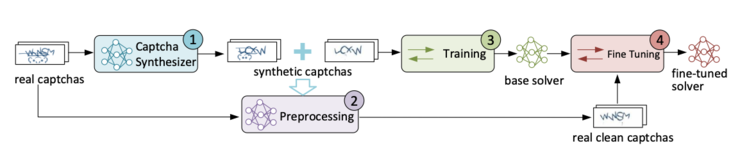
圖 3:系統架構圖
3. 系統架構和各模塊簡介
該系統主要分爲4個模塊(如圖3所示),下面來簡單介紹下各個模塊的功能與作用。
(1)驗證碼合成模塊。合成驗證碼之前,首先需要手動分析組成驗證碼的主要元素(論文中稱爲security features),如由哪些字符或數字組成,字符是否有扭曲和旋轉特徵,由哪些背景組成等,然後將上述元素參數化,並賦予初始值生成初始的驗證碼輸入到GANs裏面。隨着GANs的訓練,生成器不斷調整生成參數,直到鑑別器無法鑑別是生成的還是真實的驗證碼。爲了保證風格的一致性,我們使用了500個真實驗證碼參與到訓練過程中。訓練好生成器後,便可以生成大量的驗證碼用於構建初始的驗證碼求解器。需要說明的是,對於有背景的驗證碼,需要分別生成有背景和無背景的驗證碼,以便進行下一步的預處理。特別地,爲了生成無背景的驗證碼,只需要將背景的那一項參數置爲NULL。
(2)預處理模塊。這一模塊主要針對具有背景或空心字體的驗證碼而設計的,主要目的是去除複雜的混淆背景,或者統一字體類型,以減少使用訓練數據的數量,進而降低模型的複雜度、加快模型收斂速度。我們使用了Pix2Pix模型來完成這一步驟。以複雜混淆背景驗證碼爲例(如圖2所示),訓練時輸入有背景的驗證碼,同時輸入無背景驗證碼作爲參考數據。由於生成器使用了L1 Loss,能夠很好的處理圖像中的低頻部分(圖像的色塊),故根據目標函數,生成器通過調整模型參數,最終能夠將有背景的驗證碼轉換成無背景的驗證碼。
(3)驗證碼識別模型的構建。該驗證碼識別模型使用生成數據來構建,對於每一種類型的驗證碼,我們使用了20萬生成數據,利用LeNet-5來構建驗證碼識別模型,與LeNet-5稍有不同,我們增加了2層卷積層和3層池化層來增強其模型的識別能力。其中,每一層卷積層的卷積核大小爲3*3,在池化層中使用了max-pooling。
(4)模型優化。爲了進一步縮小生成數據與真實數據之間的差異,我們使用了遷移學習,利用少量的真實樣本,將(3)中的模型進行調優。由於CNN模型的後面幾層是更爲抽象的特徵,而由於真實樣本數量的限制,我們的生成器在抽象特徵上面與真實數據存在差異,故需要訓練和調整模型後面幾層的參數,並保持前面幾層的參數不變。
4. 簡單說說實驗
實驗數據方面,共使用了33種驗證碼方案,涉及網站超過50個,其中幾乎全部都是世界主流網站包括Alexa全球排名前50的32個著名網站。對於每一種驗證碼,自動或手動收集和標記1500個真實驗證碼,其中500個用於訓練生成器和調優CNN模型,1000個用於測試。實驗結果表明,我們方法不僅識別率明顯高於state-of-the-arts(如圖5所示),而且時間開銷明顯要小(如圖4所示)。對於有些驗證碼方案,我們的方法的識別率高於了人類的識別率。
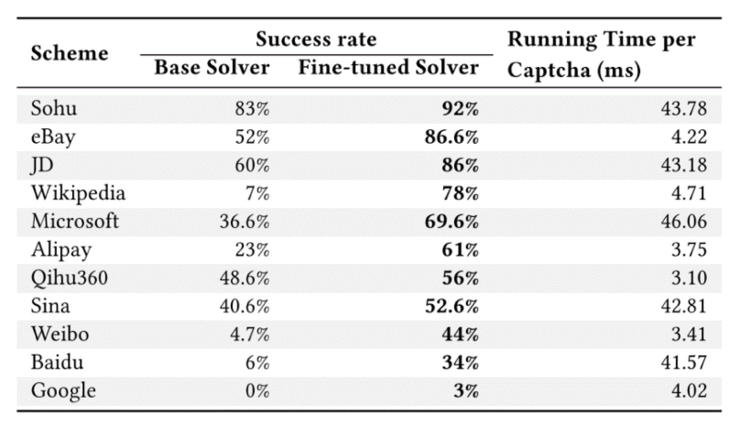
圖 4:當前網站驗證碼識別結果圖
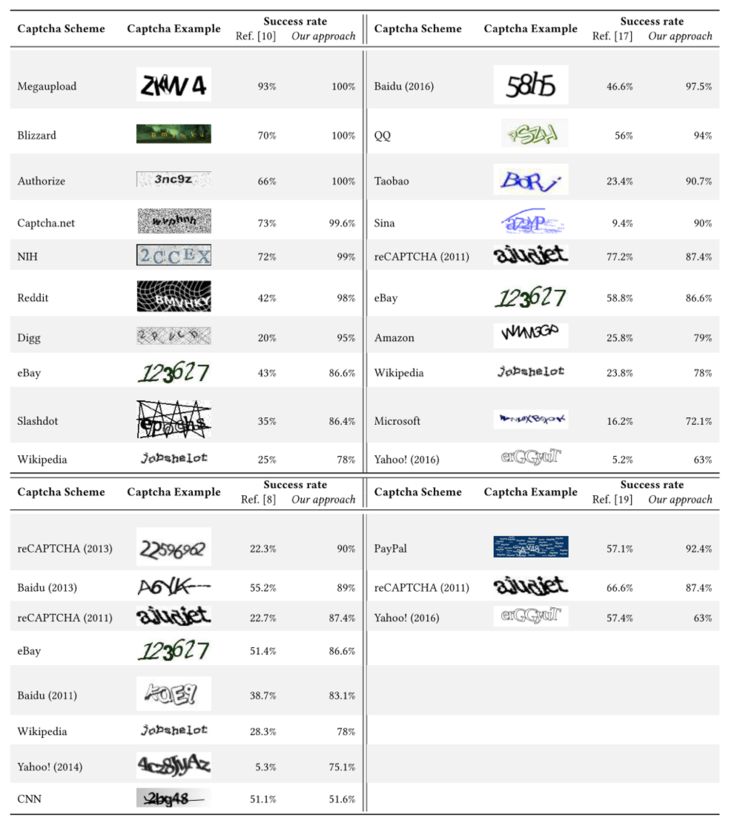
圖 5:與 state-of-the-arts 比較結果圖
5. 如何應對
爲了緩解此類攻擊,建議網站同時使用多套驗證碼方案,驗證碼中每個字符都使用不同的字體和風格,並且需要頻繁的更新(最好更新頻率爲一天)驗證碼方案,以增加攻擊的成本使攻擊難以成功。但這只是暫時的緩解措施,並不能從根源上增強驗證碼的安全性,而且複雜的驗證碼方案由於用戶友好性差並不能很好的推廣使用。我們也相信,資深的攻擊者(或者黑產)會以更高的效率和更短的時間來發起攻擊。目前,我們正致力於新的文本驗證碼生成方案。
6. 對當前網站驗證碼的安全性分析和思考
我們發現,有些網站後臺使用了機器人自動檢測技術,即根據輸入驗證碼時的輸入速度、但應時間等行爲特徵來判斷前端操作是人還是計算機自動程序。然而,我們近期的研究發現,這種檢測技術也可以被騙過。若故意在相鄰的兩個操作之間間隔一定的時間,就可以很輕鬆的繞過這種檢測機制。利用我們訓練好的驗證碼識別模型,在兩個仍然使用文本驗證碼的主流網站(其中一個使用了機器人自動檢測技術)上進行了實驗,大多數情況下攻擊一次就成功了。
我們通過該研究來提高業界對驗證碼安全性的重視和關注,並呼籲業界開發和使用更加安全、用戶更友好的驗證碼方案,也希望能與業界一道,在身份認證技術上,尋求更高的突破。
【延申閱讀】

西北大學-愛迪德物聯網信息安全聯合實驗室(NISL)
2009年7月,西北大學與國際知名的數字電視領先技術提供商愛迪德(Irdeto)公司共同組建了「西北大學-愛迪德物聯網信息安全國際聯合實驗室」,主要開展:
(1)無線網絡、傳感網與物聯網基礎理論、關鍵技術、軟硬件設計及其在大型遺址保護和野生動物監測中的示範應用;
(2)移動互聯網、工業網絡與家庭及個人網絡安全技術;
(3)軟件安全、代碼混淆與虛擬機技術相結合的軟件保護技術。
實驗室先後承擔了國家自然科學基金、中歐國際合作計劃、國家科技支撐計劃等多項國家和省部級科研項目,擁有「WSN非均勻分簇路由方法」、「移動目標定位」、「透明加解密」和「文本信息隱藏」等20餘項發明專利,開發了具有自主知識產權的土遺址監測專用傳感節點、用於野生動物監測的WSN網關和多模數據傳輸基站。已在陝北明長城、西安市含光門、大明宮遺址初步應用。與意大利SALENTO大學、加拿大VITORIA大學和荷蘭Irdeto公司建立了密切合作關係。