選自Nicolo Blog
作者:Nicolò Valigi
幾個月前,TensorFlow 發佈了梯度提升方法的調用接口,即 TensorFlow 提升樹(TFBT)。不幸的是,描述該接口的論文並沒有展示任何測試效果和基準的對比結果,所以 Nicolò Valigi 希望能對 TFBT 和 XGBoost 做一個簡要的對比,並分析它們之間的性能差異。我們介紹了該測試與 TFBT 的原論文,且 TF 1.4 及以上的版本也可測試該提升樹模型。
本文將先介紹 Nicolò Valigi 的對比試驗結果,然後再簡述谷歌新提出來的 TensorFlow 提升樹。此外,該試驗之所以選擇 XGBoost,是因爲自從它發佈以來,它就是許多數據挖掘問題的首選解決方案。而且因爲 XGBoost 對未歸一化或缺失數據的高效處理方式,以及快速和準確的訓練過程,它很適合與 TFBT 進行基準測試。
該測試的源代碼和結果地址:https://github.com/nicolov/gradient_boosting_tensorflow_xgboost
試驗
作者使用適當大小的航線數據集以測試兩個解決方案,該數據集包含了從 1987 到 2008 年的美國商業航班記錄,共計 1.2 億個數據點。它的特徵包含始發站、目的地、登記時間與日期、航線和飛行距離等,而作者嘗試使用這些特徵做一個二元分類器,以判斷航班是否會延誤超過 15 分鐘。
數據集地址:http://stat-computing.org/dataexpo/2009/
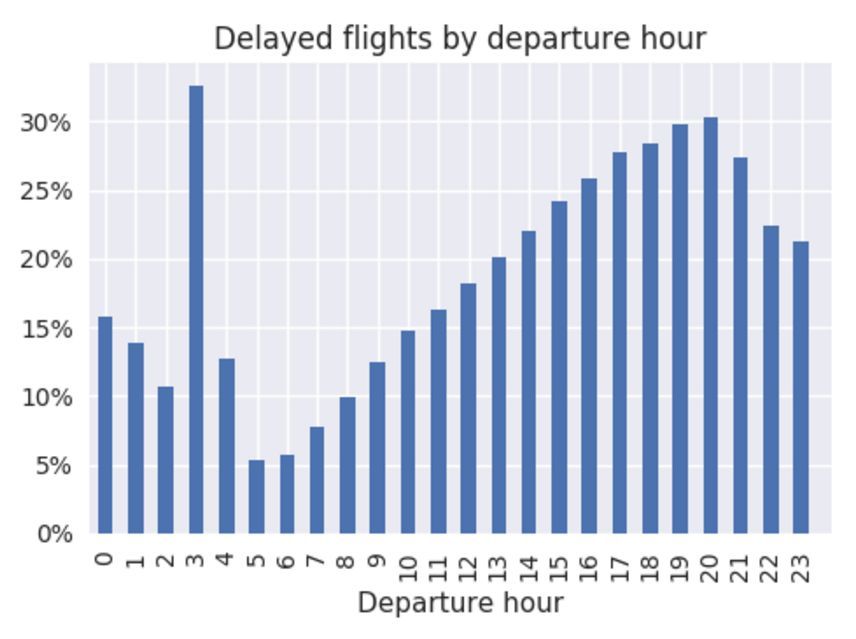
作者從 2006 年抽取 10 萬個航班以作爲訓練集,並從 2007 年抽取 10 萬個航班作爲測試集。大約有 20% 的航班延誤是超過 15 分鐘的,這和當前的航班延誤情況有些不一樣。下圖展示了該數據集航班延遲情況和起飛時間的關係:
作者並沒有執行任何特徵工程,因此採用的特徵都十分基礎:
- Month
- DayOfWeek
- Distance
- CRSDepTime
- UniqueCarrier
- Origin
- Dest
對於 XGBoost 來說,作者使用 scikit 風格的封裝,這令訓練和預測只需要使用幾行代碼和幾個 NumPy 數組。對於 TensorFlow,他使用 tf.Experiment、tf.learn.runner 方法和 NumPy 輸入函數以節省一些代碼。
試驗結果
作者從 XGBoost 開始測試,並採用適當的超參數。很快我們就能得到非常不錯的 AUC 曲線。但是作者表明 TFBT 訓練較慢,可能我們需要耐心等一段時間。當他爲這兩個模型設置超參數 num_trees=50 和 learning_rate=0.1 後,作者不得不使用一個留出的數據子集以調整 TensorFlow 提升樹的 TF Boosted Trees 和 examples_per_layer 兩個超參數。這很可能與 TFBT 論文中提到的新型逐層學習算法相關,但我們並不詳細探討這個問題。作爲對比的出發點,作者選擇了兩個值(1K 和 5K),它們在 XGBoost 中有相似的訓練時間和準確度。
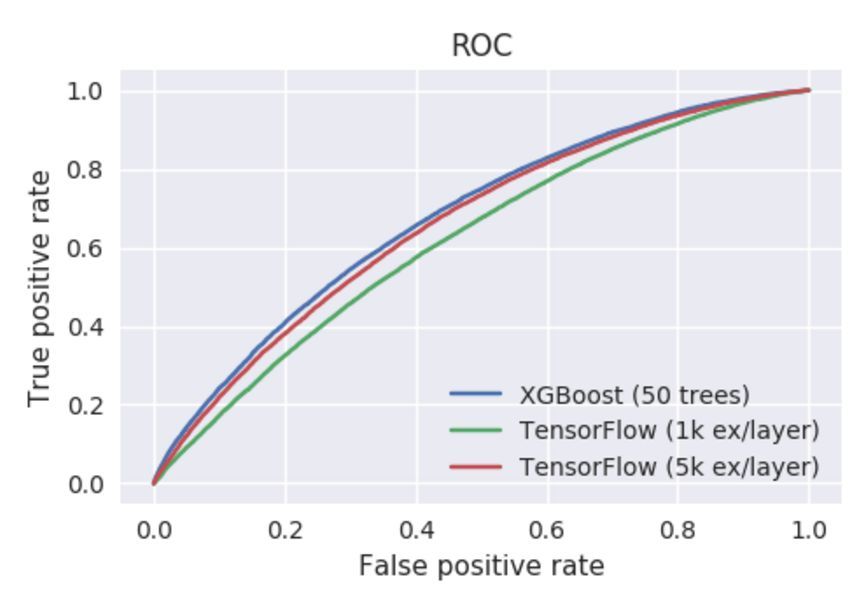
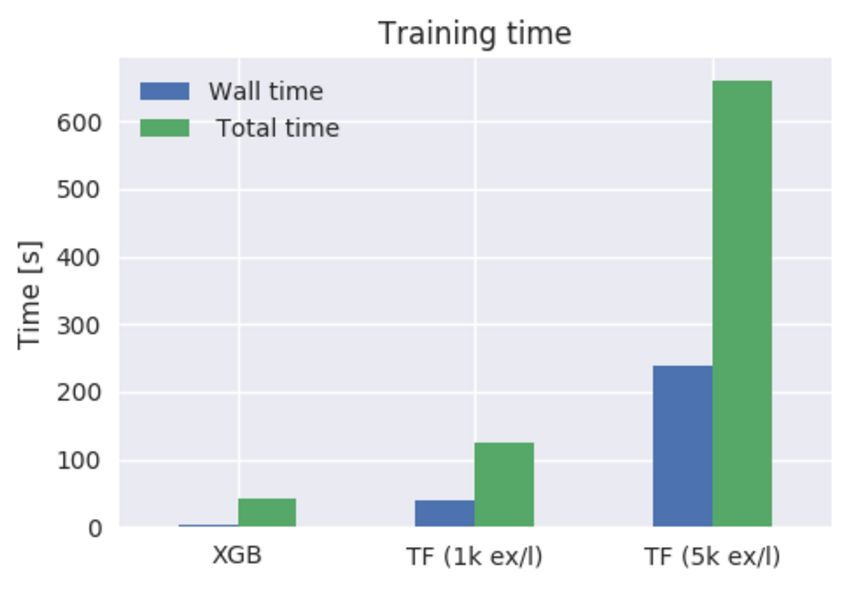
準確度數值:
- Model AUC score
- -----------------------------------
- XGBoost 67.6
- TensorFlow (1k ex/layer) 62.1
- TensorFlow (5k ex/layer) 66.1
訓練運行時:
- ./do_xgboost.py --num_trees=50
- 42.06s user 1.82s system 1727% cpu 2.540 total
- ./do_tensorflow.py --num_trees=50 --examples_per_layer=1000
- 124.12s user 27.50s system 374% cpu 40.456 total
- ./do_tensorflow.py --num_trees=50 --examples_per_layer=5000
- 659.74s user 188.80s system 356% cpu 3:58.30 total
兩套配置都顯示 TensorFlow 提升樹的結果不能匹配 XGBoost 的性能,包括訓練時間和訓練準確度。除了 CPU 使用時間過長的缺點外,TFBT 似乎在多核並行訓練的效率上也不高,因此導致了總運行時的巨大差別。XGBoost 可以輕鬆加載 32 個核心中的 16 個,這在使用更多樹的時候會有更好的效果,而 TFBT 只能使用 4 個核。
Nicolò Valigi 最後表明,即使通過幾個小時的調整,他也無法使用 TFBT 實現與 XGBoost 相匹配的結果,無論訓練時間還是準確性。而並行訓練的實現也有限制,這意味着它也不能擴展到大型數據集。
前面 Nicolò Valigi 的試驗表明 TensorFlow 提升樹接口仍然達不到 XGBoost 的性能,但在 TensorFlow 上構建提升樹的調用接口很有意義。因爲這也意味着即使是傳統的數據分析和機器學習算法,我們也可以直接調用 TensorFlow 完成。以下是提出 TFBT 的論文,我們對此作了簡要介紹。
論文:TF Boosted Trees: A scalable TensorFlow based framework for gradient boosting

論文地址:https://arxiv.org/abs/1710.11555
TF 提升樹(TFBT)是一種用於分佈式訓練梯度提升樹的新型開源框架。該框架基於 TensorFlow,並且它獨特的特徵還包括新穎的架構、損失函數自動微分、逐層級(layer-by-layer)的提升方法、條理化的多類別處理和一系列可以防止過擬合的正則化技術,其中逐層級的提升方法可以減少集成的數量以更快地執行預測。
1. 前言
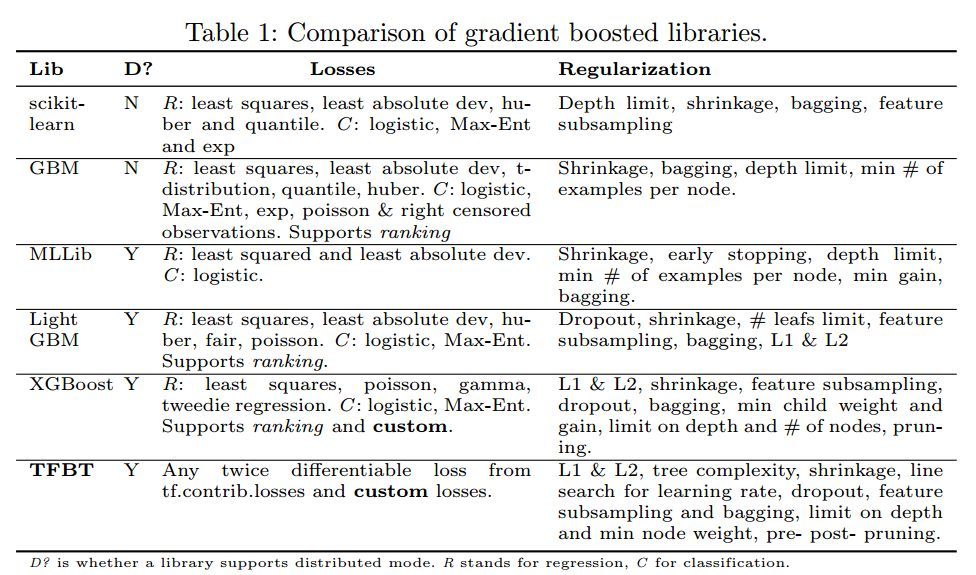
梯度提升樹是最受歡迎的機器學習模型之一,自從梯度提升樹算法被提出以來,它就主宰了許多帶有真實數據的競賽,包括 Kaggle、KDDCup[2] 等頂尖競賽。除了出色的準確度,提升方法同樣很容易使用,因爲它們擅長處理非歸一化、共線性或異常感染的數據。該算法同樣支持自定義損失函數,並且通常要比神經網絡或大型線性模型更具可解釋性。由於梯度提升樹非常受歡迎,目前有非常多的實現庫,包括 scikit-learn [7]、R gbm [8]、Spark MLLib [5]、LightGBM [6] 和 XGBoost [2] 等。
在本論文中,我們介紹了另外一個可優化和可擴展的梯度提升樹軟件庫,即 TF 提升樹(TFBT),該算法庫構建在 TensorFlow 框架 [1] 的頂層。TFBT 合併了一組新穎的算法以提升梯度提升樹的性能,包括使用新的逐層提升過程提高一些問題的性能。TFBT 是一個開源的庫,它可以在 TensorFlow 主流發行版的 contrib/boosted_trees 下找到。
2.TFBT 特徵
在表 1 中,我們提供了一個簡要地對比,從上可以瞭解當前主流梯度提升樹軟件庫的特性:
除了上述描述的分佈式訓練、損失函數形式和正則化技術等特徵以外,TF 梯度提升樹主要還有以下兩個特徵:
- 逐層的提升方法(Layer-by-layer boosting):TFBT 支持兩種樹型構建的模式,即標準的方式和新穎的逐層提升方式。其中標準模式即使用隨機梯度的方式構建提升樹序列,而逐層提升的方式允許構建更強的樹和更深的模型。
- 多類別支持:TFBT 支持一對多(one-vs-rest)的方式,此外它還通過在每一個葉結點上儲存每一個類別的分數而減少樹的數目要求,這和其它一些變體一樣。
因爲 TFBT 是使用 TensorFlow 實現的,所以所有 TensorFlow 具體的特徵都是可獲取的:
- 易於編寫自定義的損失函數,因爲 TensorFlow 提供了自動微分工具 [1],而其它如 XGBoost 那樣的庫要求使用者提供一階導數和二階導數。
- 我們能無縫轉換和對比 TFBT 與其它 TensorFlow 封裝模型,還能通過其它 TensorFlow 模型生成的特徵輕鬆組合梯度提升樹模型。
- 很容易通過 TensorBoard 進行調試。
- 模型能多塊 CPU/GPU 和多個平臺上運行,包括移動端,它們都很容易通過 TF serving[9] 進行部署。
3.TFBT 系統設計
TFBT 架構如下,我們的計算模型基於以下需求:
- 能夠在數據集中訓練且不需要適配工作站的內存。
- 能夠處理特徵數目衆多的深度樹模型。
- 支持不同模式構建提升樹:標準的 one-tree-perbatch 模式和逐層提升樹模式。
- 極小化平行化損失。
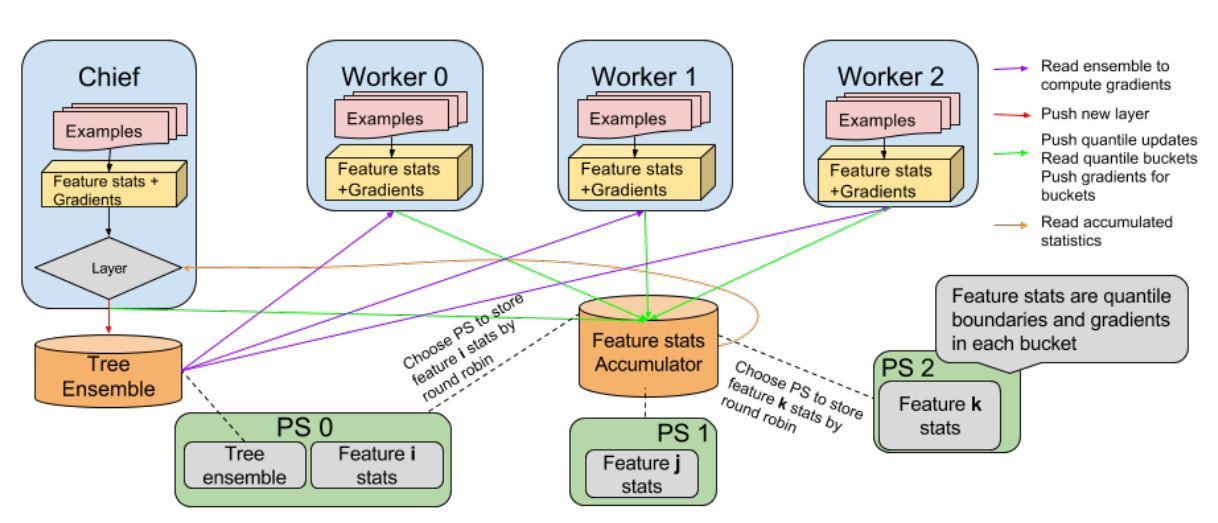
圖 1:TFBT 的架構
Nicolò Valigi測試地址:https://nicolovaligi.com/gradient-boosting-tensorflow-xgboost.html