性能分析
首先,我們需要對一種深度學習模型很熟悉,這樣我們就可以找到其性能瓶頸,並查看在我們進行了優化之後有多大的提升。我們可以使用內置的 PyTorch 分析器,也可以使用通用的 python 分析器。我們將同時考察這兩種方法。
torch.autograd.profiler
PyTorch 提供了一個名爲「torch.autograd.profiler」的 API。我們可以通過如下方式使用該 API:
with torch.autograd.profiler.profile(use_cuda=True) as prof: # Execute ops hereprint(prof)接着,PyTorch 會自動找到每個操作符並衡量他們的性能。性能分析結果如下:
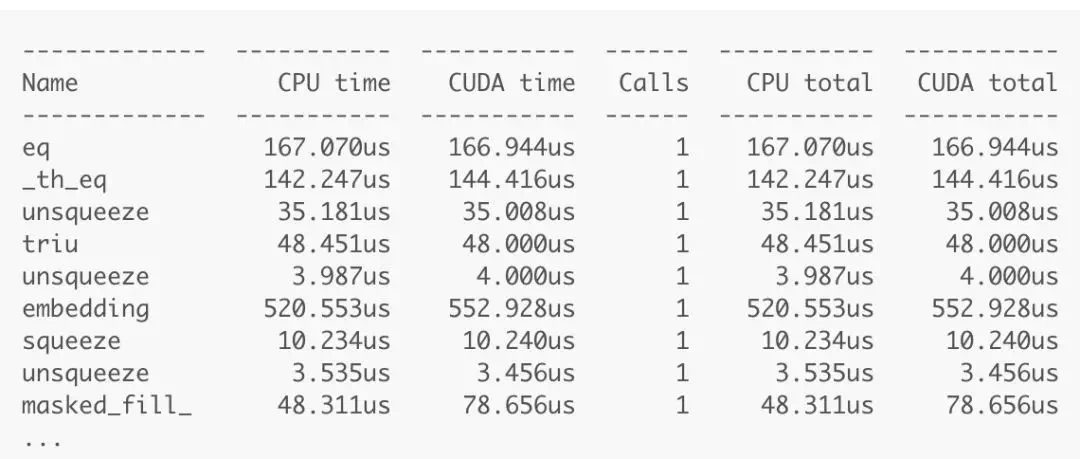
分析器顯示出了每個操作符在 CPU 和 GPU 上花費的時間。分析結果很直觀,並且看起來似乎很精確,但是我們很難分辨出每個操作符並將它們與我的源代碼匹配起來。例如,上面的輸出結果顯示出了三個不同的「unsqueeze」操作符,但是我們並不知道它們是在哪裏被調用的。因此,我轉而使用其它的分析器來尋找性能的瓶頸點
逐行分析器
因爲 PyTorch 是基於 python 編寫的,所以我們也可以使用通用的 python 分析器。我找來了一個逐行分析器(https://github.com/rkern/line_profiler),它可以逐行分析一個 python 應用程序。在要分析的函數的頂部添加「@profiler」裝飾器之後,我們可以在命令行中用「kernprof」替換「python」來運行分析器。此外,在 CUDA 的環境下,我們必須設置一個環境變量「CUDA_LAUNCH_BLOCKING」來同步對 CUDA 調用。

運行一個 epoch 的後分析多頭注意力機制前饋函數的結果如上圖所示。結果顯示了測量每一行所花費的時間,因此我們可以很容易地找到需要優化的目標代碼。我們將重點關注第 85、87 和 88 行中的掩碼操作。它組合了多個操作符來模擬「掩碼處理後的 softmax」操作:爲 softmax 的掩碼輸入填充負無窮數,從而使 softmax 忽略它們。在本文中,我將嘗試優化這些操作。請注意,它當前花費了函數執行時間的 19.1%(7.2 + 5.9 + 6.0),而第 86 行花費了 15.2% 的執行時間。讓我們使用這個值作爲對比基線。
還有另一個適合優化的地方:第 86 行和第 90 行中的矩陣乘法,因爲它們的輸入或輸出都填滿了許多 0。本文不會對此進行深入探討。
掩碼處理後的 Softmax
首先,我認爲我們可以通過將運算過程封裝進一個操作符中來優化掩碼處理後的 softmax,因爲執行多個操作符本身就會產生開銷。每次調用每個獨立的操作符時,對 CUDA 核函數的調用會產生開銷,而主機和 GPU 之間的數據傳輸也需要時間。
我們將使用一個名爲「MaskedSoftmax」的自定義 CUDA 操作符。我們將其直接簡略地定義如下:
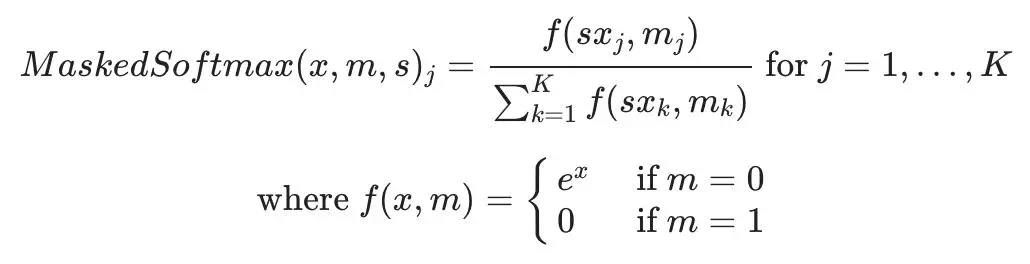
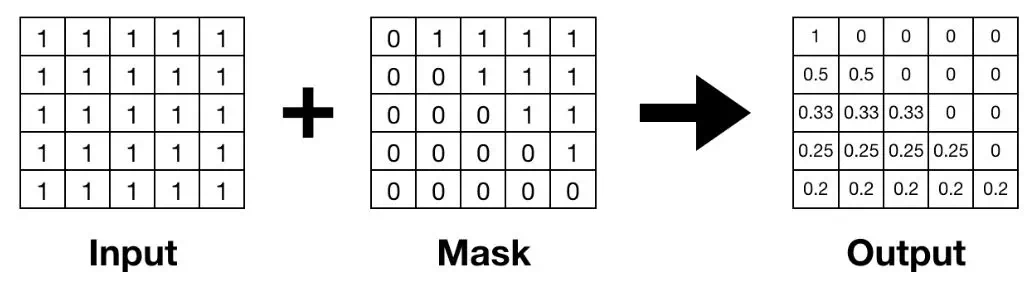
x 是一個softmax 函數數的輸入張量,m 代表一個掩膜張量,s 是一個用於歸一化的標量值。該方程與 softmax 類似,只是掩碼處理後值被規定爲零,並乘以歸一化係數。下圖顯示了掩碼處理後的 Softmax 的一個示例。掩碼處理後的位置變爲零,並且使用 softmax 計算出其餘位置上的值。
第一版
我首先寫了一個簡單版的 Masked Softmax。它由三個與 softmax 具有相同計算流程的遍歷組成:(1)找到一個輸入的最大值,(2)計算指數運算的值的和,以及(3)將每個值作爲輸入計算出指數運算的值,用它們分別除以指數運算的值的和。與 softmax 的不同之處在於,它還會加載掩碼值,如果掩碼值爲 1,則將每個對應位置上的輸入值轉換爲零。
template
__global__ void __launch_bounds__(32) masked_softmax_cuda_forward_kernel( const scalar_t* __restrict__ input, const scalar_t* __restrict__ mask, scalar_t* __restrict__ output, unsigned int hidden_size, unsigned int m0, // size of mask dimension 0 unsigned int m1, // size of mask dimension 1 unsigned int m2, // size of mask dimension 2 scalar_t scale) { // This threadIdx.x is a number between 0 and 31 because we only launched 32 threads. const int tid = threadIdx.x; // blockIdx.x, y, z are offsets of 0th, 1st, 2nd dimensions of input tensor. const unsigned int ibase = blockIdx.x * gridDim.y * gridDim.z * hidden_size + blockIdx.y * gridDim.z * hidden_size + blockIdx.z * hidden_size; const unsigned int mbase = blockIdx.x * (m0 > 1 ? m1 * m2 * hidden_size : 0) + blockIdx.y * (m1 > 1 ? m2 * hidden_size : 0) + blockIdx.z * (m2 > 1 ? hidden_size : 0); unsigned shfl_mask = __ballot_sync(0xffffffff, threadIdx.x < hidden_size); // Find a maximum input. scalar_t max_x = -FLT_MAX; for (unsigned int i = tid; i < hidden_size; i+=blockDim.x) { scalar_t m = mask[mbase + i]; max_x = fmaxf(max_x, m == 0 ? input[ibase + i] * scale : -FLT_MAX); } // Reduce values in threads to find a global maximum number. for (unsigned int i = 16; i > 0; i >>= 1) { max_x = max(max_x, __shfl_xor_sync(shfl_mask, max_x, i)); } // Find a sum of exponential inputs. scalar_t exp_sum = 0; for (unsigned int i = tid; i < hidden_size; i+=blockDim.x) { scalar_t m = mask[mbase + i]; exp_sum += m == 0 ? std::exp(input[ibase + i] * scale - max_x) : 0; } // Reduce values in threads to find a global summation of exponential inputs. for (unsigned int i = 16; i > 0; i >>= 1) { exp_sum += __shfl_xor_sync(shfl_mask, exp_sum, i); } // Calculate outputs and save to global memory. for (unsigned int i = tid; i < hidden_size; i+=blockDim.x) { scalar_t m = mask[mbase + i]; output[ibase + i] = m == 0 ? std::exp(input[ibase + i] * scale - max_x) / exp_sum : 0; }}
CUDA 中有「warp」和「block」的概念。Warp 是一組 32 個線程,而一個 block 則包含多個 warp。每個 block 有一個共享的內存,任何線程都可以訪問一個全局內存。每個線程使用不同的線程和 block 的 id 執行相同的核函數代碼,因此每個核函數使用全局內存中的 id 查找和讀取相關輸入,並將每個輸出保存到全局內存中。由於計算是分佈式的,如果有需要,我們可能需要減少不同 block 或線程中的值。
在這個 softmax 的實現中,我們需要一個約簡來獲得值的和或最大值。由於訪問全局/共享內存是 CUDA 核函數中常見的瓶頸,所以我試圖繞開它。爲此,我爲每個 block 創建了一個 warp,並使用了「shuffle」函數。它使用寄存器進行 warp 內的通信,因此線程可以在不訪問共享內存的情況下交換值。
for (unsigned int i = 16; i > 0; i >>= 1) { max_x = max(max_x, __shfl_xor_sync(shfl_mask, max_x, i));}通過這個自定義的操作符,掩碼處理後的 softmax 佔用執行時間的比例降至了 15%。這並不是一個巨大的提升,但無論如何也比之前要快一些了。

現在,內置的 PyTorch 分析器也顯示出了這個自定義操作符的性能提升。因此,由於逐行的分析器需要用太長的時間進行性能分析,我將這個第一版的掩碼處理後的 softmax 用作進行進一步優化的對比基線。

進一步的優化
正如我所提到的,對於全局內存的訪問是一個主要的瓶頸。在一些假設條件下,我們可以最小化內存訪問的次數。前面的第一版現在可以從全局內存中讀取兩種類型的值(掩碼和輸入)。用於歸一化後的點乘注意力機制的掩碼通常有如下所示的形式。
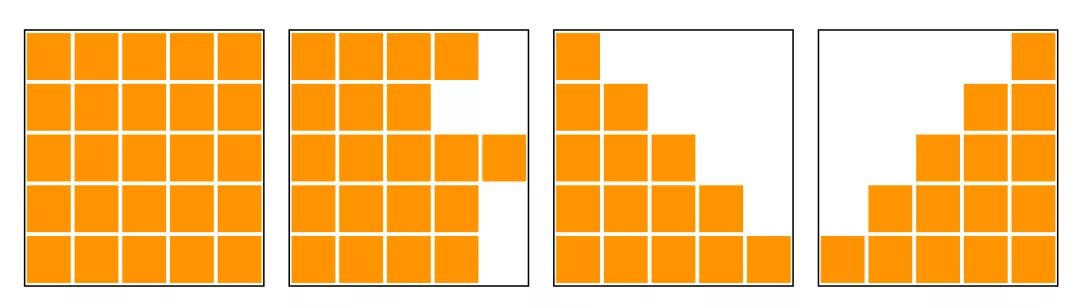
從最左或最右開始,它們是連續的,而基本的 transformer 只有從最左開始的三種形式。因此,我們不需要爲每個輸入加載掩碼值。在讀取每一行之前,加載一個表示掩碼長度的值就足夠了。
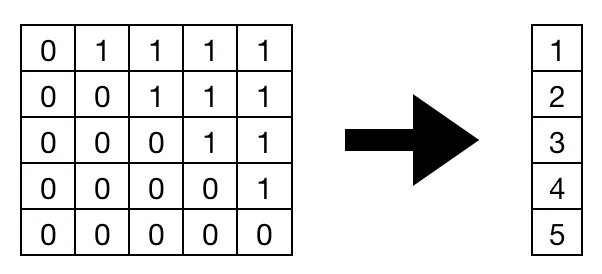
我們可以使用下面的代碼直接將掩碼轉化爲一種新的形式:
mask = mask.size(2) - mask.sum(dim=2, dtype=torch.int32)接着,我們只需要首先加載掩碼長度,將每個循環迭代與掩碼長度相同的次數,並將其餘輸出設置爲零。
// Load a mask length. const unsigned int mask_offset = blockIdx.x * (m0 > 1 ? m1 : 0) + blockIdx.z * (m1 > 1 ? 1 : 0); unsigned int mask_size = min(static_cast
(mask[mask_offset]), hidden_size); unsigned shfl_mask = __ballot_sync(0xffffffff, threadIdx.x < mask_size); scalar_t max_x = -FLT_MAX; // Iterate loop as much as the mask length. for (unsigned int i = tid; i < mask_size; i+=blockDim.x) { max_x = fmaxf(max_x, input[ibase + i] * scale); } for (unsigned int i = 16; i > 0; i >>= 1) { max_x = max(max_x, __shfl_xor_sync(shfl_mask, max_x, i)); } scalar_t exp_sum = 0; for (unsigned int i = tid; i < mask_size; i+=blockDim.x) { exp_sum += std::exp(input[ibase + i] * scale - max_x); } for (unsigned int i = 16; i > 0; i >>= 1) { exp_sum += __shfl_xor_sync(shfl_mask, exp_sum, i); } // We initialized "output" to zero, so remaining outputs will be zero. for (unsigned int i = tid; i < mask_size; i+=blockDim.x) { output[ibase + i] = std::exp(input[ibase + i] * scale - max_x) / exp_sum; }
這樣一來,這個操作就變得快多了。它現在只佔用了執行時間的 9%。

掩碼處理後的 Softmax(MaskedSoftmax)的執行時間現在比第一版快 2.5 倍。

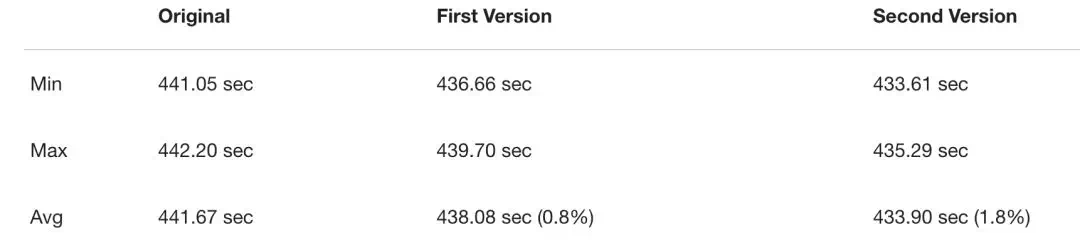
我還檢查了這種優化在多大程度上提高了整個訓練的速度。我在 lm1b 數據集上訓練了語言模型,並且測量了運行每個(碎片)epoch 的平均時間。第一個 CUDA 的版本比單純組合 PyTorch 操作符的方法快了約 0.8%,第二個版本比原始版本快了約 1.8%。
結語
我在 CUDA 中編寫了一個自定義的操作符並使 Transformer 的訓練快了約 2%。我首先希望僅僅在 CUDA 中重寫一個操作符來得到巨大的性能提升,但事與願違。影響性能的因素有很多,但是我不可能找到每一個因素。此外,由於我對 CUDA 並不熟悉,我也遇到了很多 bug。代碼越多,bug 越多。這使得我寫了很多意想不到的測試代碼。這是在提升模型性能和用於寫代碼的時間之間的一種折中。
編寫一個自定義的操作符並沒有我想象的那麼簡單,但是我可以從中學到許多關於 CUDA 如何工作的知識,以及諸如 block、線程、核函數、內存、同步、緩存這樣的概念。我希望本文能夠對那些想要入門 CUDA 性能優化的人有所幫助。
完整代碼:https://github.com/tunz/tcop-pytorch
使用場景:https://github.com/tunz/transformer-pytorch.
原文鏈接:https://tunz.kr/post/5