機器之心原創
作者:邱陸陸
10 月下旬,華爲的 NPU AI 專用處理單元和 HiAI 移動計算平臺亮相華爲上海發佈會,引起了諸多關注。在發佈會上,餘承東通過微軟爲華爲開發的 Microsoft Translator 的 AI 離線翻譯功能介紹了人工智能專用芯片 NPU 與 HiAI 移動計算平臺。隨後,我們與微軟全球技術院士黃學東進行了對話,仔細聊了聊這款包含了世界上第一個能夠在智能設備上進行離線推理的自然語言處理神經網絡的應用的誕生始末。

Microsoft Translator 是一款部署在 iOS 和 Android 平臺上的應用,支持包括英文、中文等在內的超過 60 種語言的互譯。
其翻譯模式按照輸入類別可以分爲三種,分別是文本翻譯(text)、圖像翻譯(photo)和語音翻譯(voice)。其中圖像翻譯是藉助 OCR 技術,讀取出圖片內的文本然後進行翻譯,語音翻譯則藉助了語音識別技術。
按照翻譯所用的模型類別,則可以分爲在線的 NMT 模式和離線的 SMT 模式。
NMT 指神經機器翻譯,是以神經網絡爲基礎,以句子爲單位進行整體翻譯的方法,是當下的最佳模型(state-of-the-art model),然而神經網絡模型通常規模龐大,需要大量計算資源,因此只能部署在雲端。
SMT 以詞和短語爲單位進行翻譯,是 NMT 出現前的上一代最佳模型,主要依賴於對大量語料進行統計找出規律,SMT 模型相比於 NMT 模型規模較小,能夠保存在本地,以 Microsoft Translator 的 iOS 版本爲例,一個簡體中文離線包的大小是 205MB。
而爲華爲特別開發的這一款 Microsoft Translator 的特別之處就在於,其文本翻譯和圖像翻譯模式均採用了離線的神經機器翻譯模型。
這一原先僅僅能通過微軟 Cognitive Services API 調用的,部署在微軟雲上的神經機器翻譯系統,採用了慣用的多層 LSTM 編碼器、注意力(attention)算法和解碼器組成的系統。

圖:LSTM 編碼器 + 注意力模型 + 解碼器系統演示
這類複雜的神經網絡通常帶有數以百萬計的參數,每次解碼過程需要進行大量的運算,通常都會以雲端的 CPU 或 GPU 進行。例如,谷歌翻譯利用 GPU 進行推理,有道翻譯利用 CPU 進行。而開發一款神經機器翻譯系統最大的障礙之一就是推理速度。谷歌和有道的工程師都曾表示,開發的初期階段,模型雖然準確率很高,但翻譯一句話需要 10 秒鐘甚至更多。這使得系統完全達不到「可用」的標準。工程師們投入了大量的精力對模型做不影響效果前提下的修改和簡化,才讓部署在雲端處理器上的系統變得可用。而這一次,微軟的工程師直接將這個原本難倒了大型 CPU 和 GPU 的模型放在了移動端芯片裏。
微軟將模型中最耗費計算資源的 LSTM 編碼器用深層前饋神經網絡(deep feed-forward neural network)替代,轉換爲大量低運算難度的可並行計算,充分利用華爲 NPU 能夠進行大規模並行計算的特點,讓 NPU 在神經網絡的每一層中同時計算神經元的原始輸出和經過 ReLU 激活函數的非線性輸出,由於 NPU 有充足的高速存儲空間,這些計算可以免受 CPU 與 NPU 間數據交換的延遲,直接並行得到結果。
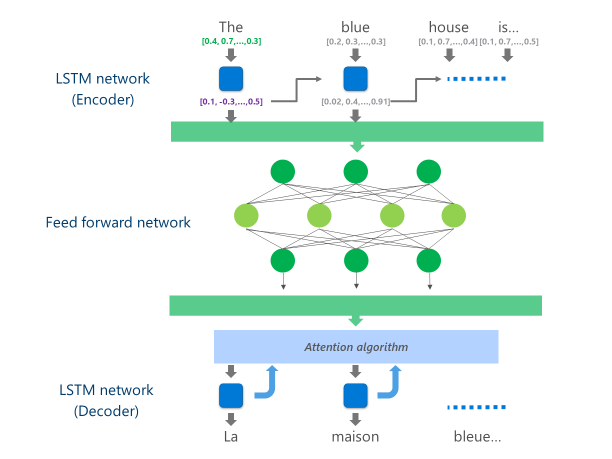
圖:替代後的翻譯模型
搭載於最新的 Mate 10 系列上的麒麟 970 芯片及其內置的 AI 專用處理單元 NPU,是華爲第一次在移動設備的層面上把機器學習硬件計算加速能力疊加進芯片中去,也讓 Mate 10 成爲全世界的消費者拿到的第一款有專用於進行人工智能方面計算的處理單元的手機。
黃學東表示,從手機 CPU 到 NPU 有接近 300% 的計算加速,正是這個加速讓神經網絡在終端設備上的離線推理越過了閾值,從不可能變成可能。
以前在 CPU 時代,離線操作就要承受巨大的性能損失,而在線服務就無法脫離開對網絡的依賴。尤其是翻譯這樣一項服務,很多應用場景都並沒有穩定的網絡支持,是需要有強大的離線功能存在的。而華爲手機的用戶大多爲商務人士,很多應用場景都在國外,網絡條件並不能得到保障,離線功能可以說是必不可少。
因此微軟的工程師聯合華爲的工程師,對現有的神經翻譯模型進行了層數、模型結構、工程實現方法等多方面優化,能夠在大幅減小所需運算量的情況下讓離線模型效果可以媲美在線模型,「大家應該感覺不出來二者的差距」,黃學東說。同時也研究瞭如何更好地同時使用 NPU 與 CPU :利用 NPU 完成推理工作,利用 CPU 輔助程序所需的其他操作。
而選擇了神經機器翻譯作「第一個吃螃蟹的 AI」,則主要是出於兩個考量,一是翻譯是一個痛點十分明確的需求,二是神經機器翻譯模型的簡化和提速相比於語音模型更容易。
黃學東十分看好神經網絡處理單元在移動端的前景:「未來會有更多手機有神經網絡處理單元,例如蘋果 iPhone X 需要做面部識別解鎖,就一定需要手機具有離線運行深度神經網絡的能力。另外 iPhone X 的照相功能中的三維打光,也需要進行大量的計算。未來這樣的需求會越來越多,因此專門的處理單元是很必要的。」
而對於微軟來說,下一步可能會研發在線與離線相結合的混合系統,能夠在網絡條件好的時候自動調用性能更好的在線模型,在網絡條件不足以支持的時候進行離線推理。這對於微軟以 Cognitive Service 爲代表的雲服務是一個很自然的拓展,增加了終端的適用性。
同時微軟的 PowerPoint 實時翻譯功能也能夠在華爲手機上使用,能在演講中、課堂上提供實時的幫助。演講者在臺上進行演講的同時,PowerPoint 的自動翻譯插件會識別語音、轉換爲文本,並可以進行超過 60 種語言的同傳。臺下的每個人都可以在自己的手機上獲得自己需要的語言的翻譯。」
「我們最終的目標是去掉語言障礙。」黃學東說,「We want to bring people together. 當年我帶着美式英文的底子去愛丁堡大學留學,很是爲教授的蘇格蘭口音英語吃了一些苦頭。如果現在的愛丁堡大學的教授下載了 Presentation Translator,而每一位留學生的手裏有一部華爲 Mate 10 手機,他們就不必經受我當年的痛苦了。希望通過這次與華爲合作,能夠幫助更多用戶打破語言障礙。」
最後,讓我們通過一組截圖感受一下 NPU 與神經網絡的強大之處。以下全部截圖來自華爲 Mate 10 Pro。
主屏界面:
可以看到有文本、圖像、語音和對話四種翻譯模式,用圖標代替文字說明也體現了「消除語言障礙」的目標。
文本翻譯模式英翻中:
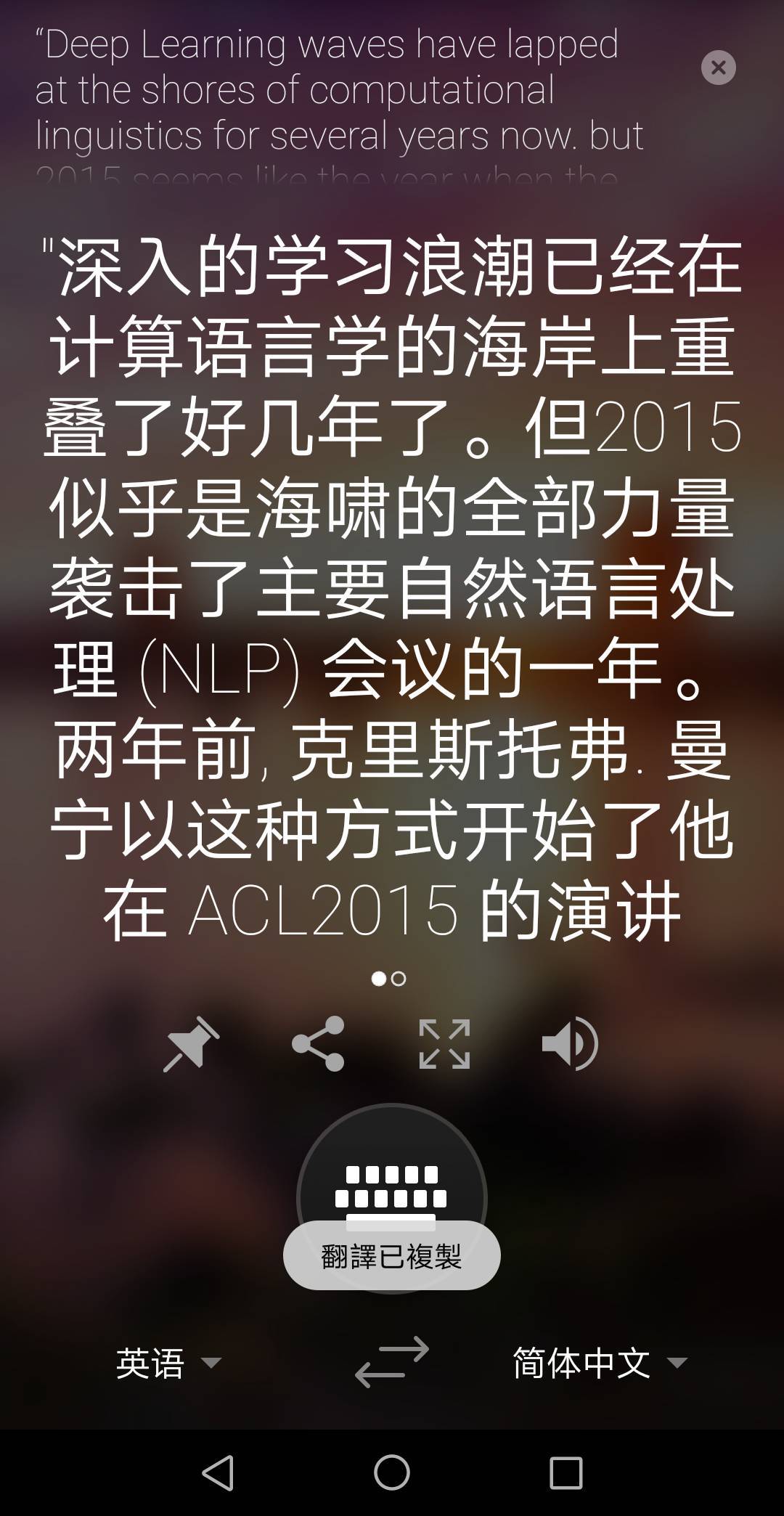
我們選擇了一段機器之心對 Christopher Manning 的專訪文章的開篇:
「Deep Learning waves have lapped at the shores of computational linguistics for several years now. but 2015 seems like the year when the full force of the tsunami hit the major Natural Language Processing(NLP) conferences.」Two years ago, Christopher Manning began his speech on ACL2015 this way.
複製完文檔內容後,打開 Microsoft Translator,可以看到屏幕右側有黏貼快捷方式。
粘貼後不到一秒翻譯完成,效果如下:
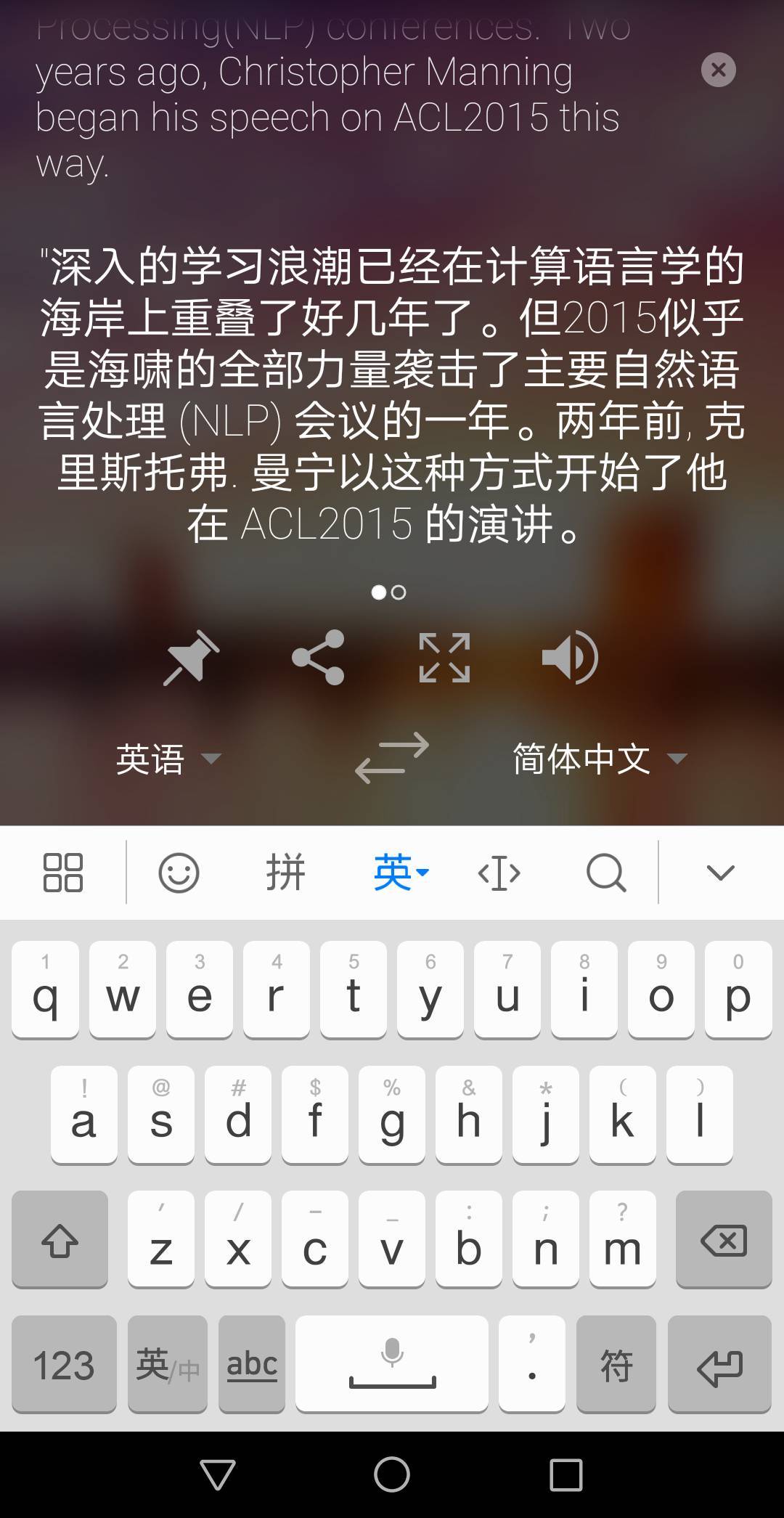
你可以用全屏模式展示給他人:

或雙擊複製內容:
或用其他方式分享:
圖像翻譯模式中翻英:
這裏主要測試 OCR 模型的識別能力、準確度,以及翻譯速度與精度。
我們截取了一段本文中的內容:


應用在不到一秒的時間裏完成了 OCR 文本識別和翻譯兩項工作。
可以看出,該系統準確翻譯了自然語言處理(natural language processing),神經網絡(neural network)等專有名詞,並能夠主動調整句式,將「包括英文、中文在內的超過 60 種語言的互譯」翻譯爲「translation of more than 60 languages, including English, Chinese, etc.」。
圖像識別英翻中:
我們採用了兩張 Christopher Manning 的演講幻燈片作爲樣本:


可以看到幻燈片右下角,連人眼很難看清的標識版權的蠅頭小字都被 OCR 捕捉到。


它也能自動區分哪些是專有名詞與縮寫,採用原文而不翻譯。
目前看來,華爲 Mate 10 系列上搭載的第一款移動端神經網絡應用的效果很棒,相信隨着開發者的跟進,我們很快就會看到人工智能芯片驅動的更多 AI 新應用。
本文爲機器之心原創,轉載請聯繫本公衆號獲得授權。
責任編輯: