按:本文作者張俊,文章將會詳細解密1)聊天機器人所要解決的三個問題;2)以及它們所使用的模式。
引言:
chatbot是最近一段時間非常火的一個詞或者一個應用,不僅僅各大新聞媒體在熱炒bot的概念,各大巨頭也投入巨大的資源進行研發,arxiv上刷出bot相關的paper也更是家常便飯。炒作歸炒作,PR歸PR,不得不說一個尷尬的事實是市面上確實難以找到一個真正好用的bot。bot按照涉及的領域,分爲開放域(open-domain)和麪向具體任務(task-oriented)的bot。開放域要做的事情很大,更像是一個什麼都能搞的平臺,不管你提什麼樣的需求,它都能夠解決,有點true AI的意思,而面向任務的bot則專注做好一件事情,訂機票,訂餐,辦護照等等。
說到開放域bot,大家接觸最多的也就是一些回答非常無厘頭的娛樂用bot,比如很多年前活躍在各大社交網站上的小黃雞,現在市面上活躍着很多號稱掌握了bot技術,在用深度學習解決bot技術的bot公司,都是這種,解決不了什麼實際問題,就是能和大家聊上兩句,而且很多時候回答都是牛頭不對馬嘴的,十分可笑。
再說task-oriented bot,市面上最多的就是客服機器人,銀行也好,電商也罷,不想重複性地回答用戶的問題,就用一個客服機器人來應對,且不說效果如何,開發一個具體task的bot需要費不少工夫,而且後期還要大量的維護,因爲太多的hand crafted features被用到,整個bot的框架橫向擴展性相對來說較差,換一個場景基本上就需要重新開發一套,人力成本太高了。
bot的理想非常豐滿,大公司描繪的場景也確實很美,但現實的bot卻狠狠地澆了一盆冷水下來。期望越高,失望越大。如果媒體一味地吹捧bot,彷彿整個世界明天就會是bot的了,對bot的發展並無益處,捧殺只會帶來氣泡,破裂之後,一切如初。
功能強大的、開放域的bot在短期內是比較難實現的,但是如果降低期望,將bot不應當做是一種技術層面的革命,而應當做交互層面的革新纔是理性的態度,bot作爲一種入口,可能大家都不再需要一個隨身攜帶的終端,只需要找到一個可以識別身份,可以聯網的硬件,比如一面鏡子,就可以執行很多的task,訂機票、買東西等等等等。bot這個時候起到的是一個操作的入口和背後執行各種不同task的黑箱,我們不需要看到整個執行過程,也不需要知道原理是什麼,通過一些簡單的語言交互,就能完成一些複雜的task,終端要做的事情就是反饋結果和接收輸入,執行的過程都在雲端,各種bot雲。
而這一切的關鍵是解決好task-oriented bot,用更多data driven的解決方案來代替傳統的人工features和templates。
|問題描述
bot是一個綜合性的問題,涉及到下面三個主要問題:
1、response generation(selection)
對話生成是最後一個步驟,是輸出的部分。簡單總結下,有四種solutions:
solution 1 直接根據context來生成對話,這方面最近的paper非常地多,尤其是seq2seq+attention框架席捲了NLP的很多任務之後,對話生成的benchmark也一次又一次地被各種model刷新着。對話生成的問題,被定義爲基於某個條件下的生成模型,典型的根據context來predict words,涉及到句子生成的問題,評價問題就會是一個比較難的問題。
solution 2 當然有的paper並不是將對話生成定義爲語言模型問題,而是一個next utterance selection的問題,一個多選一的問題,給定一個context,給定一個utterance candidate list,從list中選擇一個作爲response,當然這類問題的難度會小很多,評價起來也非常容易,但是數據集準備起來要多花一些功夫,而且在實際應用中不好被借鑑。
solution 3 rule-based或者說template-based,response的最終形式其實是填充了一個模板而成的,大多數的東西是給定的,只有一些具體的value需要來填充。這一類解決方案很適合做task-oriented bot,但過多的人工features和templates導致了其難以移植到其他task上。
solution 4 query-based或者說example-based,response是來自於一個叫做知識庫的數據庫,裏面包含了大量的、豐富的example,根據用戶的query,找到最接近的example,將對應的response返回出來作爲輸出。這一類解決方案非常適合做娛樂、搞笑用的bot,核心技術在於找更多的數據來豐富知識庫,來清洗知識庫。但畢竟respnose是從別人那裏拿出來的,可能會很搞笑,但大多數會牛頭不對馬嘴。
2、dialog state tracking(DST)
有的paper稱DST爲belief trackers,這個部件其實是bot的核心,它的作用在於理解或者捕捉user intention或者goal,只有當你真的知道用戶需要什麼,你才能做出正確的action或者response。關於這個部分,會有Dialog State Tracking Challenge比賽。一般來說都會給定一個state的範圍,通過context來predict用戶屬於哪個state,有什麼樣的需求,是需要查詢天氣還是要查詢火車票。
3、user modeling
bot面向具體的業務,都是和真實的user來打交道的,如果只是簡單的FAQ bot,回答幾個常見的問題可能不需要這塊,但如果是其他更加複雜、細緻的業務,都需要給用戶建模,相同的問題,bot給每個人的response一定是不同的,這個道理非常簡單。user modeling,需要涉及的不僅僅是簡單的用戶基本信息和用戶的一些顯式反饋信息,而更重要的是用戶的history conversations,這些隱式的反饋信息。就像是推薦系統火起來之前,大家都是中規中矩地賣東西,但是有一些聰明人開始分析用戶的行爲,不僅是那些點贊行爲,更多的是那些用戶不經意間留下的「蛛絲馬跡」,從而知道了用戶對哪些東西潛在地感興趣,也就是後來推薦系統在做的事情。對user進行建模,就是做一個個性化的bot,生成的每一個response都有這個user鮮明的特點。
|語料
大型的語料都是用來訓練開放域bot對話生成模型的,數據源一般都是來自社交網站。而對於task-oriented bot來說,客戶的數據一般規模都非常地小,這也正是難以將data driven的方案直接套用到task-oriented bot上的一個主要原因。
[1]中給出了bot訓練語料的survey,感興趣的同學可以讀一下這篇survey。
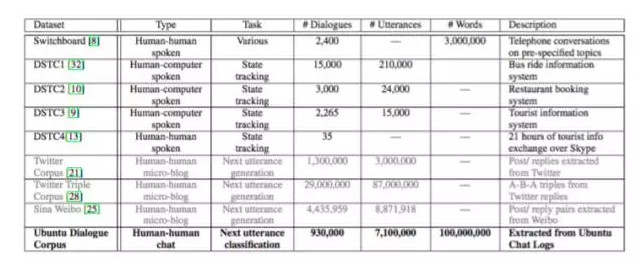
圖來自文章[13],英文的語料確實比較多,Sina Weibo那個語料是華爲諾亞方舟實驗室release的[12]。從twitter或者微博上產生bot數據的話,「conversational in nature」效果不如從ubuntu chat logs這種聊天室產生的數據更加適合訓練response生成模型,因爲更加天然無公害。文章[5]也用了一個大型中文語料,數據來自百度貼吧。
|模型
研究bot的paper是在太多了,這是一個非常活躍的研究領域,細分的方向也非常的多,接下來按照所針對的研究問題來分別介紹一些模型。
seq2seq生成模型
現在最流行的解決方案是seq2seq+attention,encoder將user query feed進來,輸出一個vector representation來表示整個query,然後作爲decoder的condition,而decoder本質上就是一個語言模型,一步一步地生成response,[2]採用就是這種方案,google用了海量的參數訓練出這麼一個模型,得到了一個不錯的bot。
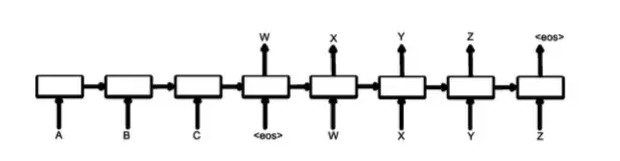
而典型的seq2seq存在一個問題,就是說容易生成一些「呵呵」的response,即一些非常safe,grammatical但沒有實際意義的response,比如」I don’t know!」之類的。原因在於傳統的seq2seq在decoding過程中都是以MLE(Maximum Likelihood Estimate)爲目標函數,即生成最grammatical的話,而不是最有用的話,這些safe句子大量地出現在訓練語料中,模型學習了之後,無可避免地總是生成這樣的response,而文章[3]借鑑了語音識別的一些經驗,在decoding的時候用MMI(Maximum Mutual Information)作爲目標函數,提高了response的diversity。
文章[4]認爲類似於RNNLM這樣的語言模型在生成人話質量不高的根本原因在於,沒有處理好隱藏在utterance中的隨機feature或者說noise,從而在生成next token(short term goal)和future tokens(long term goal)效果一般。
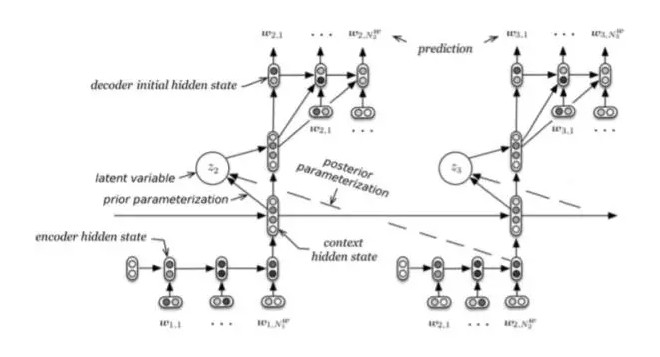
在生成每一個utterance時,需要用到四個部分,encoder RNN、context RNN、latent variable、decoder RNN,按順序依次輸入和輸出。這裏的latent variable和IR中的LSI有一點異曲同工,latent表明我們說不清他們到底具體是什麼,但可能是代表一種topic或者sentiment,是一種降維的表示。
文章[5]提出了一種叫做content introducing的方法來生成短文本response。
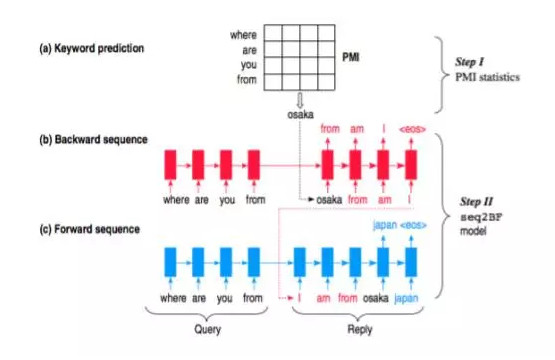
step 1 給定query之後,預測一個keyword作爲response的topic,這個topic詞性是名詞,這裏的keyword並不能捕捉複雜的語義和語法,而只是根據query的每個詞來預估出一個PMI(Pointwise Mutual Information)最高的名詞作爲keyword.
step 2 [5]的模型叫做Sequence To Backward and Forward Sequences,首先進行backward step,給定一個query,用encoder表示出來得到一個context,decoder的部分首先給定keyword作爲第一個詞,然後進行decoding,生成的這部分相當於keyword詞前面的部分;接下來進行的是forward step,也是一個典型的seq2seq,用encoder將query表示成context,然後給定backward生成的話和keyword作爲decoder的前半部分,繼續decoding生成後半部分。整個的流程這樣簡單描述下:
step 1 query + keyword => backward sequence
step 2 query + keyword + backward sequence(reverse) => forward sequence
step 3 response = backward (reverse) sequence + keyword + forward sequence
user modeling模型
文章[6]針對的問題是多輪對話中response不一致的問題,將user identity(比如背景信息、用戶畫像,年齡等信息)考慮到model中,構建出一個個性化的seq2seq模型,爲不同的user,以及同一個user對不同的請將中生成不同風格的response。
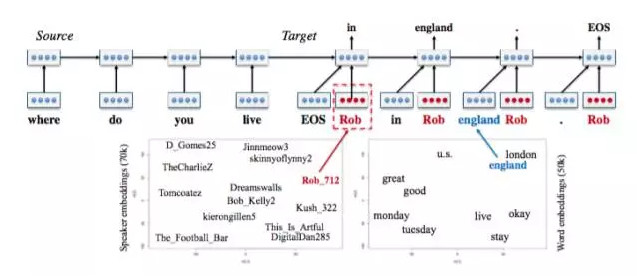
[6]的模型叫Speaker Model,是一個典型的seq2seq模型,不同的地方在於在decoding部分增加了一個speaker embedding,類似於word embedding,只是說這裏對用戶進行建模。因爲無法對用戶的信息顯式地進行建模,所以用了一種embedding的方法,通過訓練來得到speaker向量,下面左邊的圖是speaker向量在二維平面上的表示,具有相似背景信息的user就會很接近,與word向量一個道理。
reinforcement learning模型
用增強學習來解決人機對話問題具有很悠久的歷史,只不過隨着AlphaGo的炒作,deepmind公司將增強學習重新帶回了舞臺上面,結合着深度學習來解決一些更難的問題。
增強學習用long term reward作爲目標函數,會使得模型通過訓練之後可以predict出質量更高的response,文章[7]提出了一個模型框架,具有下面的能力:
1. 整合開發者自定義的reward函數,來達到目標。
2. 生成一個response之後,可以定量地描述這個response對後續階段的影響。
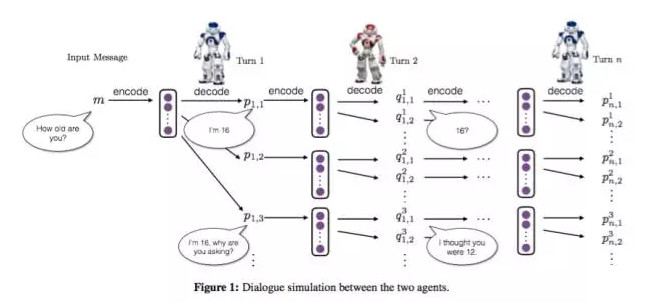
兩個bot在對話,初始的時候給定一個input message,然後bot1根據input生成5個候選response,依次往下進行,因爲每一個input都會產生5個response,隨着turn的增加,response會指數增長,這裏在每輪對話中,通過sample來選擇出5個作爲本輪的response。
在一個大型數據集上訓練一個效果不錯的seq2seq作爲初始值,用增強學習來提升模型實現自定義reward函數的能力,以達到期待的效果。
文章[7]的模型可以生成更多輪數的對話,而不至於過早地陷入死循環中,而且生成的對話diversity非常好。
task-oriented seq2seq模型
現有的task-oriented bot多是採用rule-based、template-based或者example-based或者是綜合起來用,用data driven的解決方案十分稀有。文章[8]和[9]就是嘗試在bot的個別部件上採用深度學習的技術來做,並且給出了切實可行的方案。
文章[8]先是從一個大家熟知的場景開始介紹,一個經驗豐富的客服是如何帶一個新入職的客服,分爲四個階段:
1. 告訴新客服哪些」controls」是可用的,比如:如何查找客戶的信息,如何確定客戶身份等等。
2. 新客服從老客服做出的good examples中模仿學習。
3. 新客服開始試着服務客戶,老客服及時糾正他的錯誤。
4. 老客服放手不管,新客服獨自服務客戶,不斷學習,不斷積累經驗。
[8]的模型框架就是依照上面的過程進行設計的:
開發者提供一系列備選的actions,包括response模板和一些API函數,用來被bot調用。
由專家提供一系列example dialogues,用RNN來學習。
用一個模擬user隨機產生query,bot進行response,專家進行糾正。
bot上線服務,與真實客戶進行對話,通過反饋來提高bot服務質量。
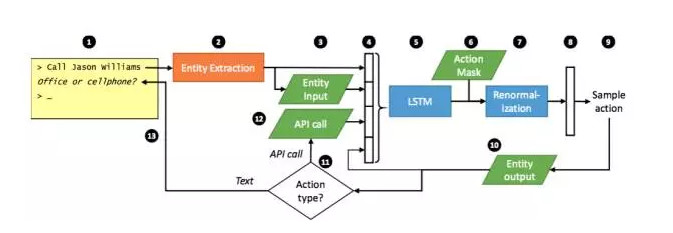
一個完整的工作流程由上圖描述,具體步驟看下圖:

訓練的時候是用一部分高質量的數據進行監督學習SL,用增強學習RL來優化模型,得到質量更高的結果。
文章[9]平衡了兩種流行方案的優缺點,提出了一套有參考價值的、具有實際意義的seq2seq解決方案。
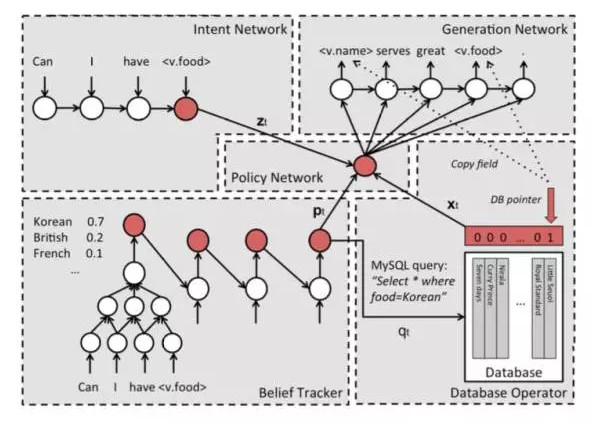
一共五個組件:
1、 Intent Network
這個部分可以理解爲seq2seq的encoder部分,將用戶的輸入encode成一個vector。
2、 Belief Trackers
又被稱爲Dialogue State Tracking(DST),是task-oriented bot的核心部件。本文的Belief Trackers具有以下的作用:
支持各種形式的自然語言被映射成一個有限slot-value對集合中的元素,用於在數據庫中進行query。
追蹤bot的state,避免去學習那些沒有信息量的數據。
使用了一種weight tying strategy,可以極大地減少訓練數據的需求。
易擴展新的組件。
3、 Database Operator
數據庫查詢的輸入來自於Belief Trackers的輸出,即各種slot的概率分佈,取最大的那個作爲DB的輸入,進行查詢,獲取到相應的值。
4、 Policy Network
這個組件是像一個膠水,起到粘合其他上面三個組件的作用。輸入是上面三個組件的輸出,輸出是一個向量。
5、 Generation Network
最後一個組件是生成模型,本質上是一個語言模型,輸入是Policy Network的輸出,輸出是生成的response,再經過一些處理之後可以返回給用戶了。這裏的處理主要是將response中的slot,比如s.food還原成真實的值。這一步和文章[8]的step 10一樣,將具體的值還原到entity上。
完全用end-to-end來解決task-oriented是不可能的事情,一定是在一個框架或者體系內用這種seq2seq的解決方案來做這件事情,文章[8]和[9]給出了很大的啓發。
Knowledge Sources based模型
純粹的seq2seq可以解決很多問題,但如果針對具體的任務,在seq2seq的基礎上增加一個相關的knowledge sources會讓效果好很多。這裏的knowledge可以是非結構化的文本源,比如文章[10]中的ubuntu manpages,也可以是結構化的業務數據,比如文章[9]中的database,也可以是一個從源數據和業務數據中提取出的knowledge graph。
文章[10]作者將bot任務定義爲next utterance classification,有一點像question answering任務,給定一個context和一個response candidate list作爲備選答案,通過context來從candidate list中選擇正確的response。本文的貢獻在於在context的基礎上,引入了task相關的外部專業知識庫,並且這個知識庫是非結構化的。
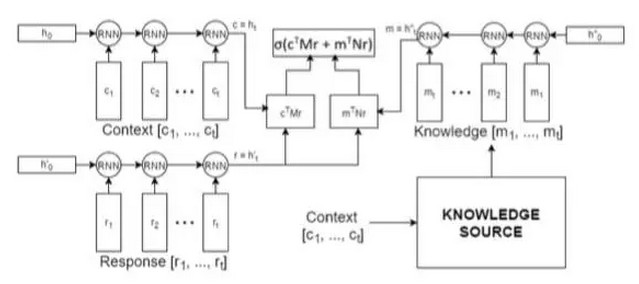
模型是三個rnn encoder組成,一個rnn來encode context,一個rnn來encode response,還有一個rnn來encode knowledge,然後綜合起來做預測,選出最合適的response。模型被稱作knowledge encoder。因爲數據集採用的是ubuntu technical support相關的數據集,外部資源就選用了ubuntu manpages。
context sensitive模型
文章[11]的模型比較簡單,但考慮的問題意義很大,history information的建模對於bot在解決實際工程應用的幫助很大,也直接決定了你的bot是否能夠work。作者將history context用詞袋模型表示,而不是我們經常採用的rnn,然後將context和用戶query經過一個簡單的FNN,得到一個輸出。
|評價
bot response評價很難,雖然說可以借鑑機器翻譯的自動評價方法BLEU來做,但效果不會太好。幾乎每篇paper都是會花錢僱人來做人工評價,設計一套評價機制來打分,人工的評價更具有說服力。對於實際工程應用更是如此,用戶說好纔是真的好。而不是簡單地拿着自己提的、有偏的指標,和幾個方法或者其他公司的bot進行對比,來說明自己好。
|思考
讀了一些paper,也和一線在做bot應用的工程師交流之後,有了一點思考,總結如下:
1、要不要做bot?流行一種說法是市面上沒有好用的bot,要解決bot的問題需要很多技術同時進步,可能還需要非常長的一段時間,現在用這個東西來做business,簡直荒謬。我個人的看法是,解決具體task的bot,結合當前先進的技術,做一些框架性的工具,並不是那麼遙遠的事情,雖然不容易,但卻非常有意義,解決了垂直領域的bot問題,纔有可能解決open domain的bot問題。也正是因爲不容易,提高了門檻,纔會出現真正的機會,誕生一些很牛的技術公司。
2、open domain還是task-oriented?如果是我,我會選後者,因爲前者只是一個夢想,一個遙不可及的夢想,需要更多的技術層面上的大突破。task-oriented更加具體,更加實用,針對具體的業務,提供一些解決方案,已經有很多企業在做了,雖然一個通用性或者擴展性強的解決方案還沒有出現,但一定是一個趨勢,也是新一代做bot的公司的機會。
3、task-oriented bot爲什麼難,該朝哪個方向來發力?end-to-end是一種理想化的模型,用深度學習模型從大量訓練數據中來「捕捉」一些features,「擬合」一些函數,雖然可以得到很不錯的效果,而且使用起來確實很方便,但尷尬就尷尬在具體的task中是拿不到海量數據的,數據規模小了之後,純粹的end-to-end就變得非常雞肋了。然而真實的場景中,很多企業又有一定的數據,也有bot的需求,所以現在成熟的解決方案就是針對你的具體業務,來設計一些features,templates和rules,當客戶的業務發生更改時,需要不斷地維護現有的bot系統,十分費時費力。真實的場景中往往涉及到很多結構化的業務數據,純粹地、暴力地直接根據context生成response是不可能做到的,文章[8][9]都給出了非常有啓發性的解決方案,將end-to-end應用在局部,而非整體上,配合上Information Extraction和Knowledge Graph等技術,實現一個高可用的框架體系,這個應該是task-oriented bot的發展方向。
4、response的生成應該與哪些因素有關呢?response質量的好壞,需要聯繫到這幾個features:(1)user query,用戶的提問,用戶在這輪對話中到底在問什麼,準確地理解用戶的意圖,這是至關重要的。(2)user modeling,對用戶進行建模,包括用戶的基本信息,還有更重要的是用戶history conversation logs的mining,這個工作很難,但同時也很見水平,也是一家技術公司證明自己技術牛逼的一種途徑。logs的挖掘現在很常見,不見得大家都做的很好,而這裏的logs不是一般的設定好的、結構化的指標,而是非結構化的文本logs,挖掘起來難度更大。另外一點,也是paper種看到的,user emotion,情感分析是nlp中研究比較多的task,用戶的情緒直接關係到銷售的成敗,如果技術足夠牛,可以考慮的因素就可以足夠多,對user的分析也就足夠清晰。將history生掛在模型中不是一個好辦法,因爲history是不斷增長,會導致模型在捕捉信息時出現問題,更好的辦法可能是build user profile之類的東西,將history沉澱出來,作爲一個vector representation,或者一種knowledge graph來表徵一個user。有了這種能力的bot,說的冠冕堂皇一點就是個性化的bot。(3)knowledge,外部知識源,涉及到具體業務的時候,業務數據也是一種knowledge,如何將knowledge建模到模型中,在生成對話的時候可以更加專業和準確也是一個非常重要的問題。bot是一個綜合性的難題,不僅僅是系統框架上的難,而且是建模上的難。
5、我一直覺得做人和看問題都不可以極端,世界並非非黑即白,而是介於兩者之間的連續值。不可能說要麼做成一個open-domain巨無霸的bot,要麼就是一個什麼具體功能都沒有的bot,不能只看到現有的bot不成熟,以及幻想中的bot遙不可及,就開始黑這個領域,還嘲笑人家能夠居然拿到投資。爭吵這些毫無意義,真正有意義的是深挖這個領域,找到痛點和難點,逐個擊破,不斷地推進這個領域的發展,而不是像一些街邊看熱鬧的人一樣,簡直無趣!在很多領域突破之前,彷彿都看不到曙光,但幾年之後很多當時難以解決的問題不都是紅海一片,滿大街都是了麼?做一個通用的bot可能很長一段時間內都是一件比較困難的事情,但做一個高可用、擴展性不錯的bot解決方案還是有盼頭的,不必過度自信,也不必妄自菲薄,踏踏實實地做就是了。