如果希望瞭解機器學習,或者已經決定投身機器學習,你會第一時間找到各種教材進行充電,同時在心中默認:書裏講的是牛人大神的畢生智慧,是正確無誤的行動指南,認真學習就能獲得快速提升。但實際情況是,你很可能已經在走彎路。
科技發展很快,數據在指數級增長,環境也在指數級改變,因此很多時候教科書會跟不上時代的發展。有時,即便是寫教科書的人,也不見得都明白結論背後的「所以然」,因此有些結論就會落後於時代。針對這個問題,第四範式創始人、首席執行官戴文淵近日就在公司內部分享上,向大家介紹了機器學習教材中的七個經典問題。戴文淵是ACM世界冠軍(2005年),「遷移學習」全球領軍人物,在遷移學習領域單篇論文引用數至今仍排名世界第三。曾任百度鳳巢策略的技術負責人、華爲諾亞方舟實驗室主任科學家。本文根據演講實錄整理,略有刪減。
有時我們會發現,在實際工作中,應該怎麼做和教科書講的結論相矛盾,這時候要怎麼辦呢?難道教科書中的結論出錯了?事實上,有時確實如此。所
問題一:神經網絡不宜超過3層
這是最有名錯誤判斷,現在的教科書幾乎已經不再有這樣的結論,但如果看15年、20年前的機器學習教科書,會有一個很有趣的結論:神經網絡不能超過三層。這和我們現在說的深度學習是矛盾的,深度學習現在大家比拼的不是神經網絡能不能超過三層,而是能不能做出一百層、一千層或者更多。
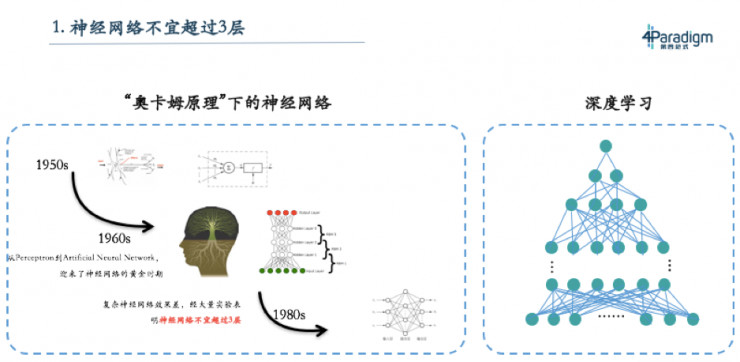
那爲什麼之前的教科書上會寫神經網絡不能超過三層,這就要從神經網絡的歷史說起。五十年代有位科學家叫Marvin Minksy,他是一位生物學家,數學又很好,所以他在研究神經元的時候就在想能不能用數學模型去刻畫生物的神經元,因此就設計了感知機。感知機就像一個神經細胞,它能像神經細胞一樣連起來,形成神經網絡,就像大腦的神經網絡。其實在60年代開始的時候,是有很深的神經網絡,但當時經過大量實驗發現,不超過三層的神經網絡效果不錯,於是大概到80年代時就得出結論:神經網絡不宜超過三層。
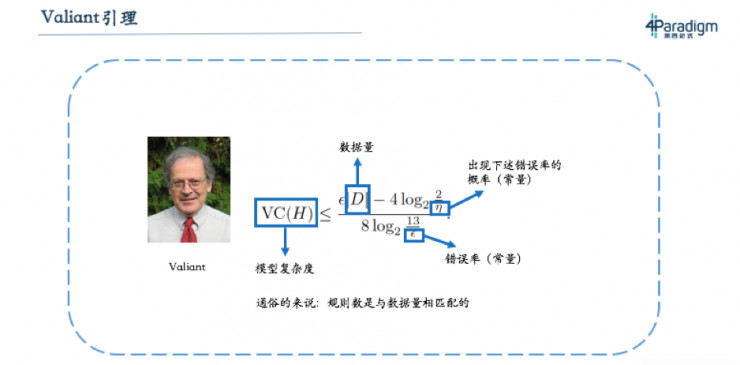
那爲什麼現在這條結論又被推翻了呢?實際上這條結論是有前提條件的,即在數據量不大的情況下,神經網絡不宜超過三層。而從2005年開始,大家發現隨着數據增加,深度神經網絡的表現良好,所以慢慢走向深度學習。其實這裏真正正確的原理是Valiant引理,它可以理解爲「模型複雜度(例如專家系統的規則數量)要和數據量成正比」。數據量越大,模型就越複雜。上個世紀因爲數據量小,所以神經網絡的層數不能太深,現在數據量大,所以神經網絡的層數就要做深。這也解釋了爲什麼當時教科書會有這樣的結論,而現在隨着深度學習的流行,大家已經不再會認爲這句話是對的。
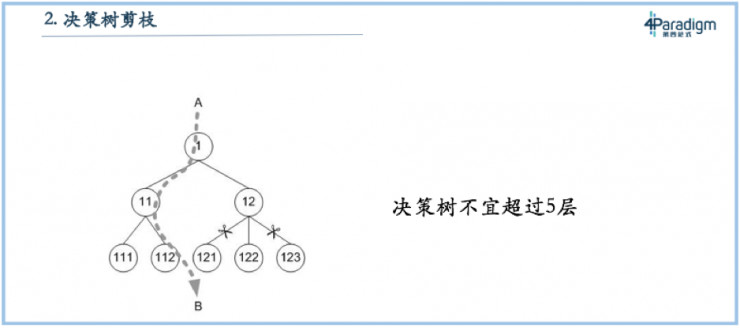
問題二:決策樹不能超過五層
如果有同學看教科書上介紹決策樹,會有一個說法就是決策樹要減枝,決策樹如果不減枝效果不好。還有教科書會告訴決策樹不能超過五層,超過五層的決策樹效果不好。這個結論和神經網絡結論一樣,神經網絡不能超過三層也是因爲當時數據量不大,決策樹不能超過五層也是因爲上個世紀數據量不夠大,二叉樹決策樹如果深度是N的話,複雜度大概是2的N次方,所以不超過五層複雜度也就是三十多。如果數據量達到一百萬的時候,決策樹能達到十幾二十層的規模,如果數據量到了一百億的時候決策樹可能要到三十幾層。
現在,我們強調更深的決策樹,這可能和教科書講的相矛盾。矛盾的原因是現在整個場景下數據量變大,所以要做更深的決策樹。當然,我們也不一定在所有的場景裏都有很大數據量,如果遇到了數據量小的場景,我們也要知道決策樹是要做淺的。最根本來說,就是看有多少數據,能寫出多複雜的模型。
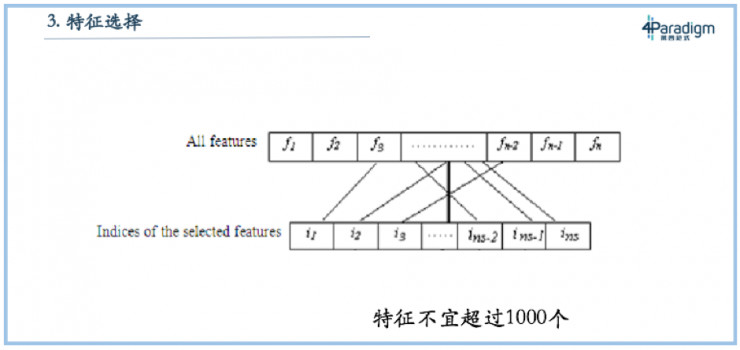
問題三:特徵選擇不能超過一千個
有些教科書會單獨開個章節來講特徵選擇,告訴我們在拿到數據後,要先刪除一些不重要的特徵,甚至有的教科書註明,特徵數不能超過一千,否則模型效果不好。但其實這個結論也是有前提條件的,如果數據量少,是不能夠充分支撐很多特徵,但如果數據量大,結論就會不一樣。這也就是爲什麼我們做LogisticRegression會有幾十億個特徵,而不是限制在幾百個特徵。
過去傳統數據分析軟件,如SAS,之所以只有幾百個特徵,是因爲它誕生於上世紀七十年代,它面臨的問題是在具體場景下沒有太多可用數據,可能只有幾百上千個樣本。因此,在設計系統時,就只需要針對幾百個特徵設計,不需要幾十億個特徵,因爲上千個樣本無法支撐幾十億特徵。但現在,隨着數據量增加,特徵量也需要增加。所以我認爲,在大數據環境下,整個機器學習教科書裏關於特徵選擇的章節已經落後於時代,需要根據新的形式重新撰寫;當然在小數據場景下,它仍然具有價值。
問題四:集成學習獲得最好學習效果
第四個叫做集成學習,這個技術在各種數據挖掘比賽中特別有用,比如近些年KDD CUP的冠軍幾乎都是採用集成學習。什麼是集成學習?它不是做一個模型,而是做很多(例如一千個)不一樣的模型,讓每個模型投票,投票的結果就是最終的結果。如果不考慮資源限制情況,這種模式是效果最好的。這也是爲什麼KDDCUP選手們都選擇集成學習的方式,爲了追求最後效果,不在乎投入多少,在這種條件下,集成學習就是最好的方式。
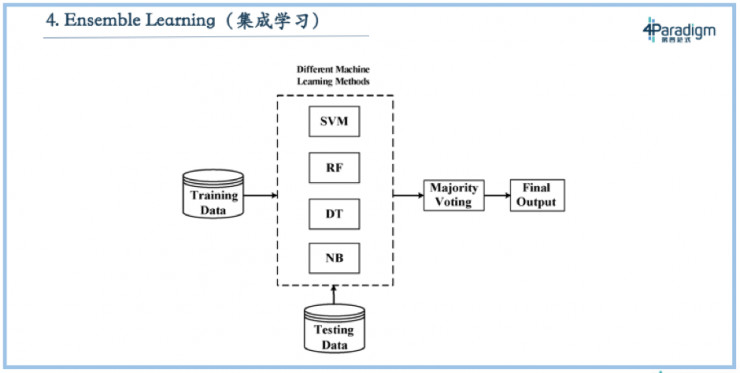
但在現實中,企業做機器學習追求的不是用無限的資源做盡可能好的效果,而是如何充分利用有限資源,獲得最好效果。假設企業只有兩臺機器,如何用這兩臺機器獲得最好的效果呢?如果採用集成學習,用兩臺機器跑五個模型,就要把兩臺機器分成五份,每個模型只能用0.4臺機器去跑,因此跑的數據量就有限。那如果換種方式,不用集成學習,就用一個模型去跑,就能跑5倍的數據。通常5倍的數據量能比集成學習有更好的效果。在工業界比較少會應用集成學習,主要是因爲工業界絕大多數的場景都是資源受限,資源受限時最好的方式是想辦法放進去更多的數據。集成學習因爲跑更多的模型導致只能放更少的數據,通常這種效果都會變差。
問題五:正樣本和負樣本均衡採樣到1:1
第五個叫做均衡採樣,絕大多數的教科書都會講到。它是指如果我們訓練一個模型,正樣本和負樣本很不平均,比如在正樣本和負樣本1:100的情況下,就需要對正、負樣本做均衡採樣,把它變成1:1的比例,這樣纔是最好的。但其實這個結論不一定對,因爲統計學習裏最根本的一條原理就是訓練場景和測試場景的分佈要一樣,所以這個結論只在一個場景下成立,那就是使用模型的場景中正、負樣本是1:1,那這個結論就是對的。
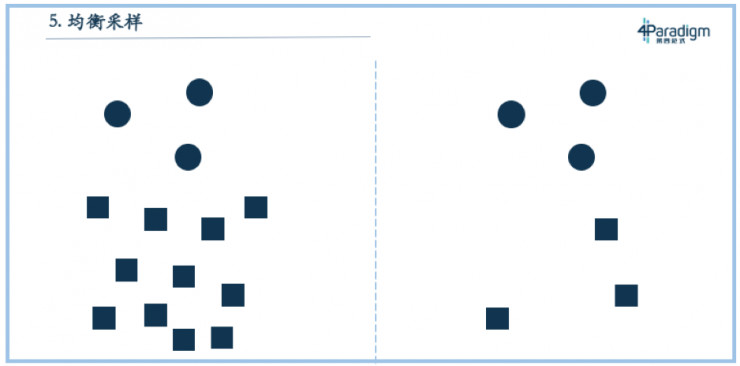
正確的做法是,應用場景是1:100,那訓練集合最好也是1:100。均衡採樣不一定都是對的,多數情況下不採樣反而纔是正確的。因爲大多時候,我們直接把訓練集合和測試集合做隨機拆分,或者按照時間拆分,二者的分佈就是一致的,那個時候不採樣是最好的。當然有時候,我們也會發現做負樣本採樣會有更好的效果,比如範式在爲某股份制銀行卡中心做交易反欺詐時,就做了負樣本採樣,那是因爲當我們把所有樣本都放進去後,發現計算資源不夠,所以只能做採樣。正樣本與負樣本大概是1:1000或者1:10000,如果對正樣本做採樣,損失信息量會比較大,所以我們選擇對負樣本採樣,比如做1:1000的採樣,再把負樣本以1000的加權加回去。在資源受限時這麼做,會盡可能降低信息量的損失。但如果僅僅是爲了把它做均衡而做負樣本採樣,通常是不對的。和前面幾個問題不同,負樣本採樣並不是因環境改變而結論變化,事實上就不應該做負樣本採樣。
問題六:交叉驗證是最好的測試方法
下一個問題叫做交叉驗證,是指假設要將一份數據拆分成訓練集和測試集,這個時候怎麼評估出它的誤差?交叉驗證是把集合拆成五份,取四份做訓練集、一份做測試集,並且每次選擇不同的那一份做測試級,最後測出五個結果再做平均,這被認爲是最好的測試方法。 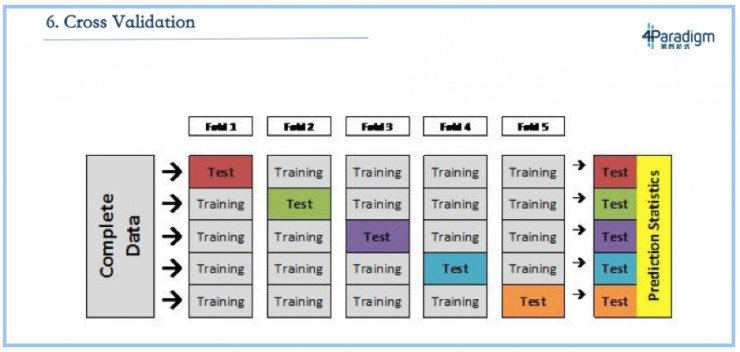
交叉驗證確實是一個還不錯的驗證的方法,但在現實應用場景下,它往往不是最合適的一種方式。因爲通常來說,我們用機器學習做的事情是預測,絕大多數情況下我們是用現在或者過去的數據做一個模型來預測未來。而拿過去的訓練預測未來的最好測試方法不是交叉驗證,因爲交叉驗證是按照交易或者按人拆分的。最合適的是方法其實是按照時間拆分,比如評估的時候選取一個時間點,用在這個時間點之前的數據做訓練,預測在這個時間點之後的,這是最接近真實應用場景的評估結果。
交叉驗證可能只適用於和時間屬性不相關的場景,比如人臉識別,但我們面臨更多的應用場景,無論是風險、營銷或者反欺詐,都是在用過去的數據訓練後預測未來,最合適這樣場景的評估方法不是交叉驗證,而是按照時間去拆分。
問題七:過擬合一定不好
最後一個叫過擬合,這也是一個討論特別多的話題。以前,通常我們會說如果模型做的太複雜了就會過擬合,如PPT右邊所示,而最好的方式應該是圖中中間的狀態——擬合的剛剛好,圖中左邊的模型underfitting,沒有訓練完全。但現在來看,大多數的實際場景都是在拿過去預測未來,過擬合不一定是不好的,還是要看具體場景。如果這個場景是過去見過的情況比較多,新的情況比較少的時候,過擬合反倒是好的。
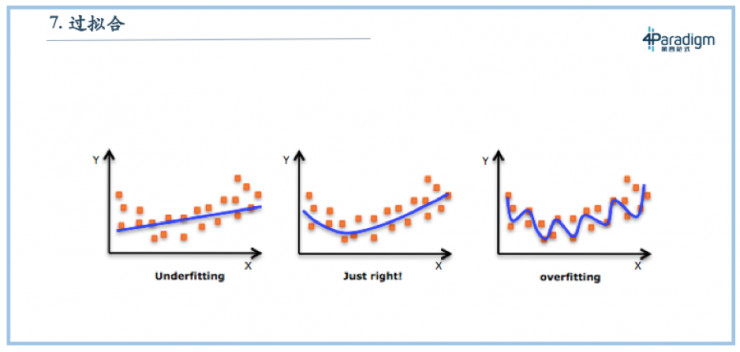
打個比方,如果期末考試題就是平時的作業,那我們把平時的作業都背一遍就是最好的方式,而這就是過擬合。如果期末考試不考平時作業,全是新題,那麼這個時候就不能只背平時的作業,還要充分理解這門課的知識,掌握如何推理解題的技巧。所以過擬合好壞與否,完全取決於場景。如果應用場景依靠死記硬背就能搞定,那過擬合反倒是好的。實際上在我們的設計裏面,很多時候我們會傾向於往過擬合靠一點,可能做新題會差一點,但是對於死記硬背的送分題會做的非常好。在拿過去預測未來的應用場景下,有的時候過擬合不一定不好,要根據實際情況來看。
今天與大家分享了教科書中的幾個經典問題。其實在實際工業應用中,我們不會完全按照教科書中的方式去實踐。我們也會設計很深的模型、很深的決策樹、很多的特徵、會過擬合一點,我們更強調按時間拆分,不強調均衡採樣。面對教科書中的結論,我們需要學會的是根據實際場景做出相應靈活判斷。
雷鋒網(公衆號:雷鋒網)注:題圖來自 channelbiz.es