聯合編譯: 高斐 章敏
摘要
我們將在文中介紹一種用於視頻中動作檢測的端對端方法,該方法用於學習直接預測動作的瞬時改變。我們認爲,動作檢測是一個對運動目標進行觀察並細化假設的過程:觀察視頻中每一個動作變化瞬間,細化關於一個動作將何時發生的所有假設。基於該觀點,我們將提出的模型視爲一個基於遞歸神經網絡結構的代理人程序,該代理人程序與視頻進行交流互動。代理人程序觀察視頻幀序列,決定下一步觀察哪裏,何時對運動目標進行動作預測。由於反向傳播算法在這種不可微的環境下不能得到充分利用,我們使用REINFORCE算法學習智能體的決策策略。我們的模型運用THUMOS’14和ActivityNet數據集,僅僅觀測一小部分(2%或更少)視頻幀序列就獲得了state-of-the-art結果。
1 引言
在計算機視覺研究領域,要對現實世界中歷時長的視頻進行動作檢測是一個頗具挑戰性的科研難題。衆多算法必須不僅能夠推理得出一個動作是否會在視頻中發生,也要能夠預測該動作何時會發生。現有的文獻[22,39,13,46]均採用構建幀級別分類器,在多個時間標尺下,詳盡地在一個視頻中運行這些分類器,並且運用後期處理方式,如時間先驗和極大值抑制。然而,在精確度與計算效率方面,該間接動作定位模型不甚令人滿意。
我們在本文中介紹一種端對端的動作檢測方法,該方法能夠直接推理得出動作的瞬時變化。我們的主要觀點爲,動作檢測是一個具有連續性和慣性的觀察細化過程。通過觀察單個或多個幀序列,能夠人爲地對動作何時發生做出假設。然後,我們可以重複觀察一些幀序列證實作出的假設,快速確定動作將要發生的位置(例如,圖1所示揮動棒球棒這一動作)。我們能夠有順序地決定將目光投向哪個方向,如何採用與已有算法相比較爲簡化的搜索方法,來細化動作預測假設,獲得精確的動作位置信息。
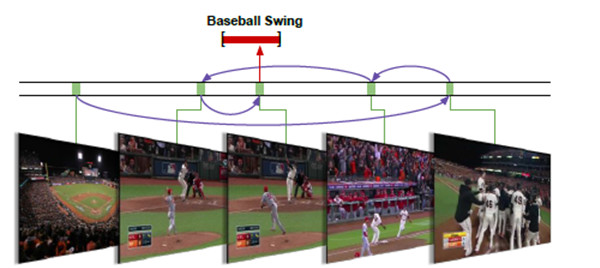
圖1:動作檢測是一個觀察與細化的過程。有效地選取幀觀察序列有助於我們快速確定何時揮動棒球棒。
基於上述觀點,我們提出一個單一連續性模型,該模型需要一個歷時較長的視頻作爲輸入信息,輸出檢測所得的動作實例的瞬時變化。我們將提出的模型制定爲一個代理人程序,該代理人程序可以學習策略,關於動作實例形成有序的假設,並對作出的假設進行細化。在一個遞歸神經網絡結構中運用這一觀點,我們採用反向傳播算法與REINFORCE算法[42]相結合的方法全面端對端訓練所提出的模型。
我們的模型是從一些研究文獻中汲取靈感的,這些文獻運用REINFORCE算法來學習對圖像分類與加字幕的空間觀測策略[19,1,30,43 ]。然而,動作檢測仍面臨另一個挑戰,即如何處理一個結構化檢測輸出結果的變量集合。爲了解決這一難題,我們提出一個既能夠決定運用哪一個幀觀測下一個潛在動作,也能夠決定何時對動作變化作出預測。此外,我們介紹了一種獎勵機制,使得計算機能夠學習這一策略。就我們所知,這是首個學習視頻動作檢測的端對端方法。
我們認爲,我們的模型具備有效推理動作瞬時變化的能力,並且能夠運用THUMOS’14和ActivityNe數據集獲得state-of-the-art性能。此外,我們的模型能夠學習決定使用哪一個幀進行觀測或實時觀測,它也具備僅觀測一部分(2%或更少)幀序列,便可學習決策策略的能力。
2 相關研究文獻
視頻分析與活動識別領域具有悠久的研究歷史[20,449,2,31,17,8,10,112,50]。我們參考Poppe[24]與Weinland等人[40]的研究對該領域進行研究。這裏我們將回顧近來有關瞬時動作檢測的文獻。瞬時動作檢測 該研究方向的典型研究成果當屬Ke等人[14]。Rohrbach等人[27]與Ni等人[21]在一個固定攝像機廚房環境下,以手和物體爲特徵分別檢測嫺熟的烹飪動作。與我們當前研究更爲相關的是無約束無修改設置的THUMOS’14動作數據集。Oneata等[22],王等[39],Karaman等[13],及Yuan等[46]在滑動窗口框架中使用密集軌跡,幀級別CNN特徵,和/或聲音特徵檢測瞬時動作。Sun等[34]基於網絡圖像提高檢測性能。Pirsiacash與Ramanan[23]對複雜的動作建立語法結構,並及時檢測子成分。
空間-時間動作檢測方法也得到了發展。在「無約束」的網絡視頻環境下,發展這些方法需要有大量關於空間-時間動作假說的文獻[44,16,36,9,7,45,41]。動作檢測更爲寬泛的檢測場景分析也是一個活躍的研究領域。Shu等[32]在人羣中進行推理,Loy等[18]運用多臺攝像機場景進行推理,Kwak等[15]遵循基於二次編程的實例化原則進行推理。這些研究存在一個共同點,即在時間維度內典型地運用基於滑動窗口的方法,在空間-時間動作假說或人類軌跡的基礎上進行推理。此外,這些研究是運用經過修剪或約束的視頻剪輯開展來的。與之形成鮮明對比,我們運用無修剪,無約束的視頻剪輯完成空間動作檢測任務,提供了一種有效的方法來確定使用那些幀序列進行觀測。
端對端檢測 我們直接推理動作的瞬時變化的研究目的與關於從整幅圖像到物體變化的物體檢測的研究工作具有相同的哲學意義[29,35,5,6,26,25]。相反,現有的動作檢測方法主要運用詳盡的滑動窗口方法和後期處理程序得出動作實例[22,39,13,46]。就我們所知,我們的研究工作是首個採用端對端框架學習瞬時動作檢測的。
學習特定任務策略 我們從近期使用REINFORCE算法來學習特定任務策略的途徑中獲得研究靈感。Mnih等[19]學習圖像分類的空間注意策略,Xu等[43]學習圖像字幕生成。在非視覺化任務中,Zaremba等[47]學習REINFORCE算法神經圖靈機策略。我們採用的方法是建立在這些研究方向之上,運用強化法學習處理動作檢測任務的策略。
3 研究方法
我們的研究目的是運用一個長的視頻序列,輸出任意一個指定動作的實例。圖2所示爲我們的模型結構。我們將這個模型制定爲一個REINFORCE算法代理人程序,該代理人程序與視頻在特定時間段內進行交流溝通。代理人程序接收一系列視頻幀序列V={v1,…,vT}作爲輸入信息,能夠觀測固定比例的幀序列。該模型必須能夠有效地利用這些觀測結果,或幀觀測結果,來推理動作的瞬時變化。
3.1結構
我們提出的模型由兩個主要成分構成:一個觀測網絡(見3.1.1),一個遞歸網絡(見3.1.2)。觀測網絡爲視頻幀的視覺表徵編碼。遞歸網絡有序地加工這些觀測結果,並決定運用哪一個幀序列觀測下一個動作,何時對動作變化作出預測。我們現在將更爲詳細地描述這兩個組成成分。之後在3.2,我們將闡釋如何運用端對端的方法,結合反向傳播算法與強化手段訓練我們提出的模型。
3.1.1 觀測網絡
如圖2所示,觀測網絡f0,用參數θ0表示,在每一個時間步長中觀察單一的視頻幀。在該觀測網絡中,用特徵向量On爲幀編碼,將該特徵向量作爲遞歸網絡的輸入信息。
重要的是,On表示在視頻中何處進行觀測及觀測什麼的編碼信息。因而,觀測網絡的輸入信息由觀測的正常時間位置與相對應的視頻幀構成。
觀測網絡結構受到文獻[19]中涉及到的空間觀測網絡啓發。Ln和vln被映射到一個隱蔽的空間內,然後,與一個全面的連接層相結合。在我們的實驗中,我們從一個經過優化的VGG-16網絡中提取得到fc7特徵。
3.1.2 遞歸網絡
遞歸網絡fh,用參數oh表示,是學習代理人程序的核心網絡結構。正如可以在圖2中觀測到的,在每一個時間步長n中,該網絡的輸入信息爲一個觀測特徵向量on。該網絡的隱蔽空間hn,on與先前隱蔽空間hn-1,爲動作實例構建時間假說。
在代理人程序推理的過程中,每一個時間步長內輸出三種信息:候選檢測結果dn,標誌是否產出預測結果dn的二進制指示參數pn,及確定觀測下一個動作的幀的時間位置ln+1。
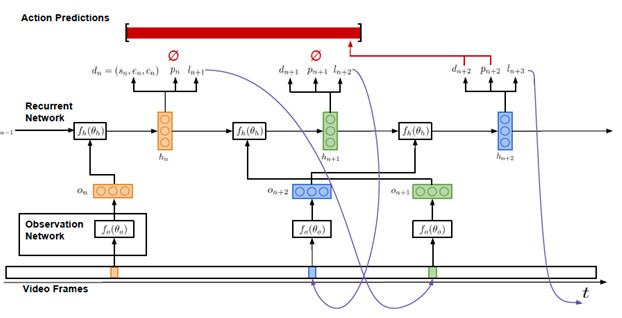
圖2:該模型的輸入信息爲一系列視頻幀序列,輸出信息爲一系列動作預測結果。
3.2 訓練
我們的最終研究目的是學習輸出一系列動作檢測結果。爲了實現這一目標,我們需要在代理人程序的遞歸網絡中的每一步訓練這三種輸出信息:候選檢測結果dn,預測指示值pn,及下一個觀測位置ln+1。鑑於對長視頻中瞬時動作註釋的檢測,訓練這些輸出結果面臨着設計合適的損失與獎勵函數,處理不可微模型組成成分。我們運用標準的反向傳播算法來訓練dn,運用強化手段來訓練pn和ln+1。
3.2.1 候選檢測結果
運用反向傳播算法訓練候選檢測結果,以確保每一個候選檢測結果的正確性。由於每一個候選結果都代表代理人程序關於動作作出的假設,不論每一個候選結果最終是否得到輸出,我們都希望確保該結果最爲正確。這便要求在訓練過程中將每一個候選結果與一個ground truth實例相匹配。代理人程序應當在視頻中最接近當前位置的地方對動作實例作出假設。這有助於我們設計出一個簡單卻有效的匹配函數。
與ground truth 相匹配 如果存在一個由遞歸網絡中N個時間步長得出的候選檢測結果集合D={dn|n=1,…,N}和ground truth 動作實例g1,…,M,那麼每一個候選檢測結果都將於一個ground truth實例相匹配;如果M=0,那麼沒有匹配結果。
我們定義匹配函數爲
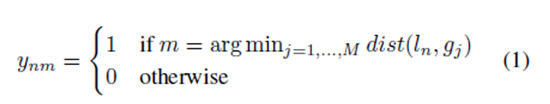
換句話講,如果在時間步長n內,代理人程序的時間位置ln比任何一個ground truth實例都接近gm,候選結果dn與ground truth gm匹配。
損失函數 一旦候選檢測結果與ground truth實例得以匹配,我們運用集合D來優化一個多重任務分類與定位損失函數:
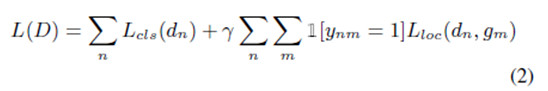
公式中的分類術語 是一個關於檢測信度cn的標準交叉熵損失值,如果檢測結果dn與一個ground truth實例相匹配,那麼信度接近1;否則,信度爲0。
我們運用反向傳播算法優化該損失函數。
3.2.2 序列的觀測與輸出
觀測定位與預測指數輸出結果是我們的模型中不可微的組成成分,無法用反向傳播算法訓練這些輸出結果。然而,強化手段是一種強有力的方法,能夠實現在不可微的環境下進行學習。下文我們將簡略描述這種強化手段。之後,我們介紹一種與強化手段相結合的獎勵函數,學習觀測與預測輸出序列的有效策略。
強化手段 存在Α,一個動作序列空間,和一個Pθ(a),強化目標可以表示爲
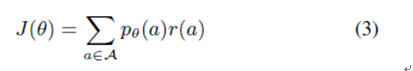
在該公式中r(a)爲分配給每一個可能動作序列的獎勵,J(θ)爲每一個可能動作序列分佈結果的預期獎勵。我們希望學習網絡參數θ,該參數使每一個位置序列和預期指示輸出結果的預期獎勵實現最大值。
目標梯度爲
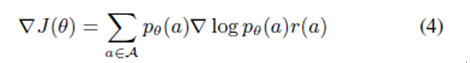
由於可能動作序列具有高維度空間,這將導致一個特殊的優化問題。強化手段通過使用蒙特卡洛樣本和近似梯度方程學習網絡參數,以解決這一問題。
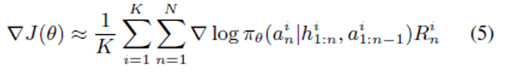
由於一個代理人程序與周圍環境進行交流溝通,在我們的視頻中,πθ爲代理人程序的策略。在每一個時間步長n內,an是該策略的當前動作,h1:n爲包括當前狀態在內的過去狀態的歷史記錄,a1:n-1爲過去動作的歷史記錄。通過在其所處環境中,經營一個代理人程序的當前策略,以獲得K互動序列,最終計算得出近似梯度。
根據該近似梯度,強化手段學習模型參數。導致高未來獎勵的動作的概率在不斷增長,那些導致低獎勵的概率將下降。可以運用反向傳播算法對模型參數實施實時更新。
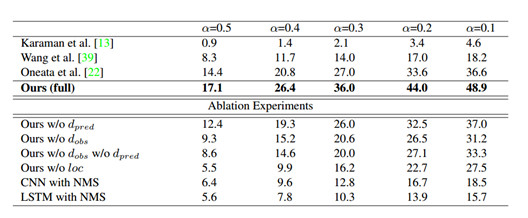
圖1:THYMOS`14上的行動檢測結果。與THUMOS`14挑戰榜排行前3的性能進行比較,並且展示了消融模型。mAP報道了不同的交叉聯合(intersection-over-union/IOU)閾值α
獎勵函數 訓練強化手段要求設計出一個合適的獎勵函數。我們的目標是學習位置與預測指示輸出結果的策略,這些輸出結果將產生高回憶和高精確度的動作檢測結果。因而,我們介紹一種能夠使真肯定檢測結果最大化,而使假肯定檢測結果最小化的獎勵函數:
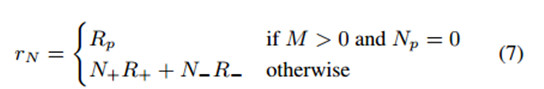
所有的獎勵都是在Nth(最後)時間步長時提供的,且n<N時爲0,因爲我們想找到一個可以共同產生高整體檢測性能的方法。M是正確標註(ground truth)行爲實例的數量,並且Np是代理髮出預測的數量。N+是正的正樣本(positive predictions)預測數量,N-是最小正的負樣本(false positive)預測數量,並且R+和R-分別是每一個預測的正獎勵和負獎勵。如果一個預測與正確標註的重疊比閾值大,且比其他所有的預測還高,那麼該預測就是正確的。爲了鼓勵代理人不過於保守,當視頻包含正確標註實例(M > 0),但該模型沒有發出任何預測(NP = 0)時,我們提供一個負面的獎勵Rp。
我們使用有REINFORACE的函數訓練位置和預測指標輸出,並學習觀測和排放政策(emission policies)以優化行動檢測。
4.實驗
我們在THUMOS`14和ActivityNet兩個數據集評估了我們的模型。結果顯示,我們的端對端的方法確保了模型可以最大幅度的在兩個數據集產生最好的結果。此外,幀的學習策略即有效又高效;當觀測到的視頻幀只有2%或更少的時,模型達到了這些結果。
4.1實施細節
對於每一個行動級別我們都學習了1-vs-all模型。在觀測網絡中,我們使用了VGG-16網絡優調數據集,以便從觀測的視頻幀中提取視覺特徵。FC7-layer特徵被提取並嵌入幀的時間位置到1024維的觀測向量。
對於遞歸網絡,我們使用了一個3層LSTM網絡(在每一個層都有1024個隱藏單元)視頻在THUMOS`14向下採樣到5fps,在ActivityNe向下採樣到1fps,並且在50幀的序列中進行。代理被給予了對於每個序列固定數量的觀測,我們實驗中代表性的數量是6。在視頻序列中,所有的時間位置被歸一化成[0,1]。任何預測重疊或交叉序列的邊界都會被融合到一個簡單的聯盟規則。我們學習256序列中極小的一部分,並且在優化時使用RMSProp模擬預參數學習率(the perparameter learning rate)。其它的超參數通過交叉驗證(cross-validation)來學習。序列的係數包含了每一個極小部分(mini-batch)的正實例,它是阻止模型過渡保守的一個非常重要的超參數。大概三分之一到一半的正實例被代表性的使用。
4.2.THUMOS`14數據集
THUMOS`14的行動檢測任務包括20類運動,且表1顯示了在這個數據集上的結果。因爲該任務只包括數據集中101類動作的其中20類,我們第一次粗過濾了這些類測試視頻的整個集,用視頻水平的平均值池化類概率——每300幀計算一次(0.1fps)。我們報道了不同IOU閾值的αmAP,並與THUMOS`14挑戰榜排名前3的性能進行了比較。所有這些方法計算密集的軌跡和/或時間窗口的CNN特徵,並使用一個非最大抑制滑動窗口的方法獲得預測。僅使用密集的軌跡,[使用時間窗口結合密集的軌跡和CNN特徵,以及使用有着視頻水平CNN分類預測的密集軌跡的時間窗口。
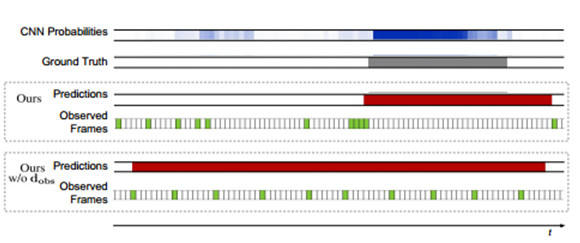
圖片3:將我們的w / odobs描述與所有的模型進行比較。參考圖5中圖形結構的說明
和配色方案。每個模型的觀測幀用綠色顯示,預測程度用紅色顯示。允許模型選擇要觀測的幀,以確保行動邊界上所需的分辨率。
我們的模型優於所有在α值處現存的方法。隨着α的減少,相對利潤率增加了,這表明我們的模型更頻繁地預測接近於正確標註情況的行動,即使不精確定位的情況相。我們的模型使用它的學習觀測策略進行到視頻幀的2%時就實現了該結果。
消融(Ablation)實驗.表1也顯示了消融實驗的結果,分析不同模型組件的貢獻。消融模型如下:
·我們的w/o dpred移除預測指標輸出。在每一個時間步長的候選檢測都被髮出,並與非極大值抑制合併。
·我們的w/o dobs移除了位置輸出指標(下一個要觀測哪一個地方)。觀測不再是由均勻採樣相同總數的觀測決定。
·我們的w/o dobs w/o dpred移除了預測指標和位置預測輸出
·我們的 w/o loc移除位置迴歸。所有發射檢測都是訓練集的中等長度,並集中在目前觀測到的幀。
·有NMS的CNN移除了時間行動邊界的直接預測。我們觀測網絡中VGG-16網絡的預-幀類概率,是在多個時間尺度上密集獲得的,並且聚合了非最大抑制,類似於現有的工作。
由於大量的正的負樣本(false positives),相比於整個模型我們的w/o dpred獲得了更低的性能。我們的w/o dobs同樣更低效,因爲均勻採樣沒有提供足夠的分辨率來定位動作邊界(圖3)。有趣的是,移除dobs相比於比移除dpred對模型的損害更大,這突出了觀測策略的重要性。如想象的一樣,移除我們的w/o dobs和w/o dpred的輸出進一步降低了性能。我們的w/o loc在α=0.5時性能最差,甚至低於CNN的性能,這反映出了時間迴歸的重要性。CNN減少相對差異,以及當我們減少α時的翻轉,暗示出模型仍然檢測出了行動大概的位置,但精確定位的影響。最終,有NMS的CNN相比於所有的消融模型(除了我們的w/o loc模型)達到了最低的性能,量化我們對於端對端框架的貢獻。使用稠密軌跡和的ImageNet 預訓練CNN特徵,它的性能同樣在除了更低的範圍內。這表明,另外結合運動爲基礎的特徵,將進一步提高我們模型的性能。
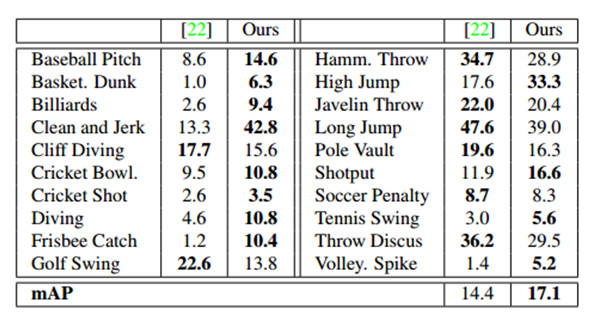
表2:在IOU α=0.5時,THUMOS`14的Per-class breakdown(AP)。
作爲額外的基線,我們在LSTM的頂部執行了NMS,一個標準的時間網絡,會產生幀級別的流暢性和一致性。儘管增加了更大的時間一致性,有NMS的LSTM相比於有NMS的CNN有着更低的性能。主要的原因可能是增加幀級別類概率的時間流暢性(精準定位時間邊界所需要的),對於行動情況檢測任務來說實際上是有害的,而不是有益的。

圖4:THYMOS`14上的預測動作情況實例。每一行顯示在檢測動作的時間範圍內,或只是在外面的採樣幀。褪色的幀顯示檢測外的位置並說明了定位能力。
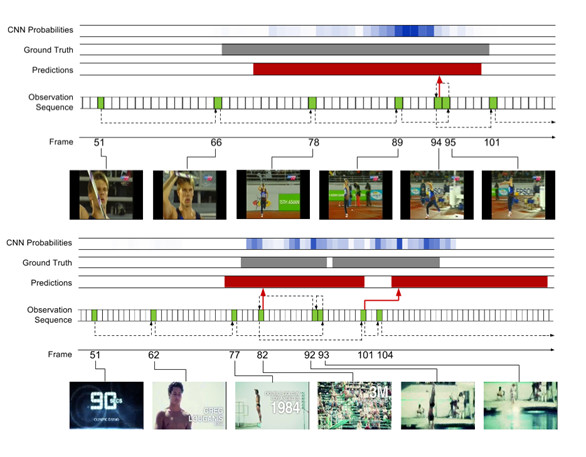
圖5:THUMOS`14的學習觀測策略實例。上面顯示了擲標槍的例子和底部顯示了潛水的例子。觀測到的幀的顏色爲綠色並用幀索引標記。紅色表示預測範圍,灰色表示正確的標示。爲了參考,我們還展示了使用在我們觀測網絡中來自於VGGNet的幀水平的CNN概率;高強度表示更高的概率,並提供對類的幀級信號的洞察。虛線箭頭表示觀測序列,紅色箭頭指示發出預測的幀。
最終,我們實驗了不同數量的觀測前視頻序列,如4,8和10.在該範圍中,檢測的性能沒有實質性的不同。這是與其他使用在CNNs最大池化進行動作識別的工作一致,突出學習有效幀觀測政策的重要性。
預-類分解(per-class breakdown).表2顯示了我們模型的預-類AP分解,並且與THUMOS`14排行榜最好的性能進行比較。我們的模型產生20個類中的12個類。值得注意的是,它顯示了一些數據集中最具挑戰性的類表現出了很大的改善,如籃球,跳水,和接住飛盤。圖4顯示我們模型預檢測的實例,包括這個來自挑戰性類的檢測。模型在行動程度整體合理化的能力,確保了它可以推測時間邊界(甚至在幀是具挑戰性的時候):例如,類似姿勢和環境,或在第二個潛水的例子中場景突然變化。
觀測策略分析.圖5顯示了我們模型學習的觀測實例,以及伴隨的預測。爲了參考,我們還展示用於我們觀測網絡中VGGNet的幀水平的CNN概率,以提供行動幀水平信號的認知。上面是一個 擲標槍的例子,一旦人開始奔跑,該模型就開始進行更頻繁的觀測。接近行動的端邊界,它退一步以完善其假設,然後在移動之前發出一個預測。下面潛水的例子是一個具有挑戰性的情況下,其中兩個動作實例發生的非常快速連續。而幀水平CNN的概率的強度超過序列,使得用標準滑動窗口的方法來處理變得非常困難,我們的模型能夠分辨兩個單獨的實例。該模型再次採取步驟向後完善其預測,包括一次(幀93)運動非常模糊,使得它很難從其它的幀中辨別出來。然而,預測在某些方面比正確標註要長,並且向上觀測第二個情況的第一個幀(幀101),該模型立即發出的預測可媲美長於第一個幀,但持續時間稍。這表明,該模型可能學習時間的先驗,同時極大受益,在這種情況下它過於強大。
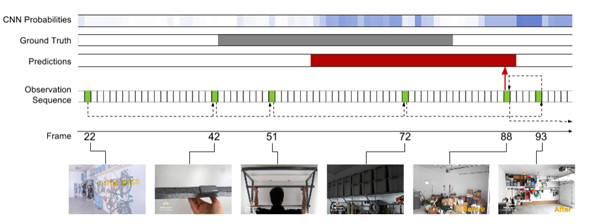
圖6:ActivityNet上工作子集的學習觀測策略實例。行動是組織箱。參考圖5圖形結構和色彩方案的解釋。
4.3.ActivityNet數據集
ActivityNet動作檢測數據集由849小時內未修剪的68.8小時的時間註釋組成,無約束的視頻。每個視頻有1.41個動作實例,且每一個類有193個實例。表3和4分別顯示了每個類和mAP在ActivityNet的子集「運動」和「工作,主要工作」的性能。並且超參數在訓練集上進行交叉驗證。
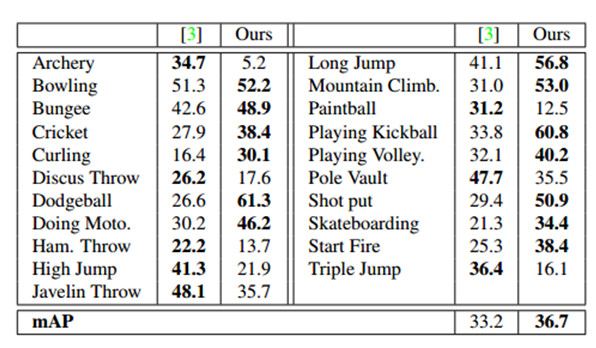
表3:IOU α=0.5時,ActivityNet Sports子集上的Per-class breakdown和mAP。
我們的模型優於現存的工作,它的基礎是是通過大量的差數,結合密集軌跡,SIFT,和ImageNet-預訓練CNN特徵。它優於Sports子集21類中13類,和Work子集15類中10類。在工作子集上的改進是特別大的。這是部分歸因於工作活動通常是不太明確的,並有較少的歧視性運動。圖6 Organizing Boxes行動的訓練實例中,在較弱的地方這是顯而易見的——更擴散的幀水平CNN行動概率。而這給依靠後處理的方法就造成了一個挑戰,我們的模型直接推理作用程度,確保它能夠產生強烈的預測。
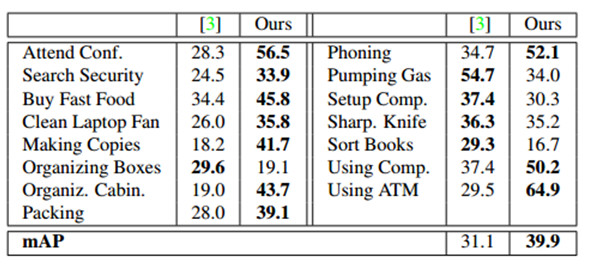
表4:IOU α=0.5時,ActivityNet Work子集上的Per-class breakdown和mAP。
5.結論
總之,我們已經介紹了一個針對視頻中動作檢測的終端到終端的方法,直接學習預測動作的時間界限。我們的模型在THUMOS`14和ActivityNet行動檢測數據集上實現了最佳性能(只看一小部分的幀)。未來的工作方向是擴展我們的框架,學習聯合時空觀測策略。
哈爾濱工業大學李衍傑副教授的點評:在計算機視覺研究領域,對歷時較長的視頻進行動作檢測是一個頗具挑戰性的研究難題。這篇論文介紹了一種端對端的動作檢測方法,該方法能夠推理出每個時刻的動作檢測的範圍。動作檢測是一個連續的反覆的觀察細化過程。我們人類能夠通過觀察單個或多個幀序列,對動作何時發生做出假設,從而略過一些幀迅速地縮小行動檢測的範圍,決定應該看哪些幀以及是否要改進自己的假設來增加動作檢測的定位精度,從而避免了窮舉式搜索。基於這種直觀思想,本文模仿人的這種能力將一些幀序列作爲輸入,在觀測神經網絡和遞歸神經網絡學習訓練的基礎上,得到了每個時刻動作檢測範圍,從而有助於提高動作檢測的效率。在該方法中,將整個網絡分爲觀測神經網絡和遞歸神經網絡,觀測網絡使用了已有的VGG-16網絡,而遞歸網絡則模仿人的假設預測定位過程分別使用了BP反向傳播算法和REINFORCE算法來進行學習訓練,最終通過實驗驗證了算法的有效性。
PS : 本文由雷鋒網(公衆號:雷鋒網)獨家編譯,未經許可拒絕轉載!
如需本文作多瞭解,請訪問原文鏈接細節
