2018 年已到尾聲,今年 AI 領域也取得了很多精彩的突破。人們對 AI 的大肆宣揚和恐慌逐漸冷卻,更多地關注到具體的問題中。和往年不一樣的是,今年深度學習在很多非計算機視覺領域也取得了突破,尤其是在 NLP 領域。同時,今年在框架上的競爭大大升溫,Facebook 發佈的 Pytorch 1.0 勢頭強勁,直逼 Google 的 Tensor Flow,微軟也發佈了 TextWorld 。按照慣例,Curai 的聯合創始人兼 CTO Xavier Amatriain 發佈了一篇年度總結,編譯整理如下:
對我來說,在每年的這個時候總結 ML 的進展已經成爲一種傳統(例如,我去年就在 Quora 上回答過這個問題)。一如既往,這個總結必然會偏向於我自己感興趣的領域。
如果要我把 2018 年機器學習進展的主要亮點總結成幾個標題,那就是:
對 AI 的大肆宣揚和恐慌逐漸冷卻;
更多地關注具體問題,如公平性、可解釋性或因果性;
深度學習將持續下去,並且在實踐中不僅僅可以用來對圖像分類(特別是對 NLP 也非常有用);
AI 框架方面的競爭正在升溫,如果你不想默默無聞,你最好發佈一些自己的框架。
讓我們來看看具體是怎麼樣的。
如果說 2017 年對人工智能的大肆宣揚和恐慌都達到了極點,那麼 2018 年似乎就是我們開始冷靜下來的一年。雖然有些人一直在散佈他們對於人工智能的恐懼情緒,但與此同時,媒體和其他人似乎已經同意這樣的觀點,即雖然自動駕駛和類似的技術正在向我們走來,但它們不會在明天發生。儘管如此,仍然有聲音認爲我們應該規範人工智能,而不是集中於控制其結果。
不過,很高興地看到,今年的人們關注的重點似乎已經轉移到了可以處理的更具體的問題上。例如,關於公平性的討論很多,而且關於這個話題的會議不止 1 次(例如 FATML 和 ACM FAT),甚至還有一些在線課程也在是關於這個話題的,比如 Google 教人們認識機器學習中的公平性的課程。
順着這條思路,今年已經深入討論的其他問題有可解釋性、解釋性和因果性。因果關係似乎回到了聚光燈下,這源於 Judea Pearl 的《The Book of Why》的出版。作者不僅決定寫他的第一本「普通人能夠讀懂」的書,而且他還利用 Twitter 來推廣關於因果關係的討論。事實上,甚至大衆媒體都認爲這是對現有 AI 方法的「挑戰」(例如,你可以看看《機器學習的先驅如何成爲最尖銳的批評者之一》這篇文章。實際上,甚至 ACM Recsys 大會上的最佳論文獎也授予了一篇相關論文,該論文討論瞭如何嵌入因果關係的問題(參見《Causal Embeddings for Recommendations》)。儘管如此,許多作家認爲因果關係在某種程度上只是一種理論,我們應該關注更具體的問題。

Judea Pearl 的書
作爲最通用的 AI 範例,深度學習仍然存在很多問題,很顯然,深度學習不會止步於當前,就它所能提供的東西而言,它還遠遠沒有達到高峯。更具體地說,今年深度學習方法在從語言到醫療保健等不同於計算機視覺的領域取得了前所未有的成功。
事實上,今年深度學習最有趣的進展可能出現在 NLP 領域。如果要我選出今年最令人印象深刻的 AI 應用程序,它們都將是 NLP 應用程序(並且都來自於 Google)。第一個是 Google 發佈的超級有用的 smart compose,第二個是他們的 Duplex 對話系統。
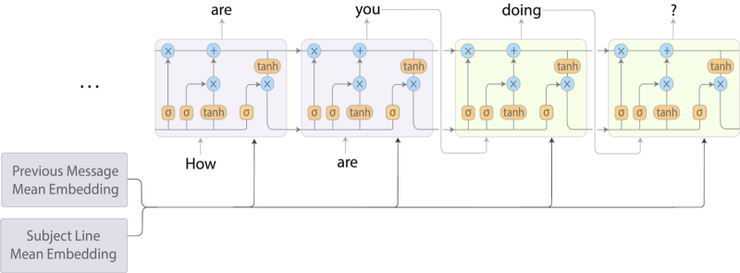
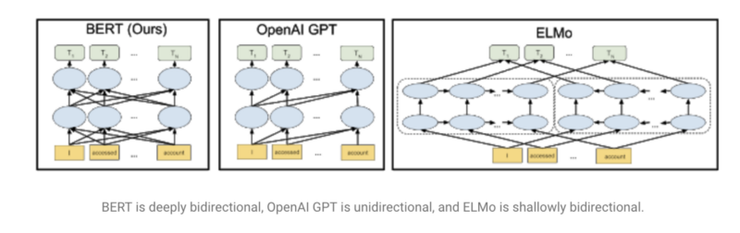
使用語言模型的想法加速了這些進步,這種想法在今年 Fast.ai 的 UMLFit 課程裏面普及。隨後我們看到了其他改進的方法,比如 Allen 的 ELMO,Open AI』s transformers,或最近擊敗了很多 SOTA 的 Google 的 BERT。這些模型被描述爲「Imagenet moment for NLP」,因爲它們提供了隨時可用的預訓練好的通用的模型,這些模型還可以針對特定任務進行微調。除了語言模型之外,還有許多其他有趣的進步,比如 Facebook 的多語言嵌入。值得注意的是,我們還看到這些和其他方法被集成到更通用的 NLP 框架(比如 AllenNLP 或 Zalando) 的 FLAIR 中的速度非常快。
說到框架,今年的「人工智能框架之戰」已經升溫。令人驚訝的是,Pytorch 1.0 發佈之初,它就似乎正在趕上 TensorFlow。雖然在生產中 Pytorch 的使用情況仍然不太理想,但它在可用性、文檔和教育方面的進展速度似乎比 Tensor Flow 要快。有趣的是,選擇 Pytorch 作爲實現 Fast.ai 庫的框架可能起到了很大的作用。也就是說,Google 意識到了這一切,並且在框架中把 Keras 作爲高級模塊。最終,我們都能夠接觸到這些偉大的資源,並從中受益。
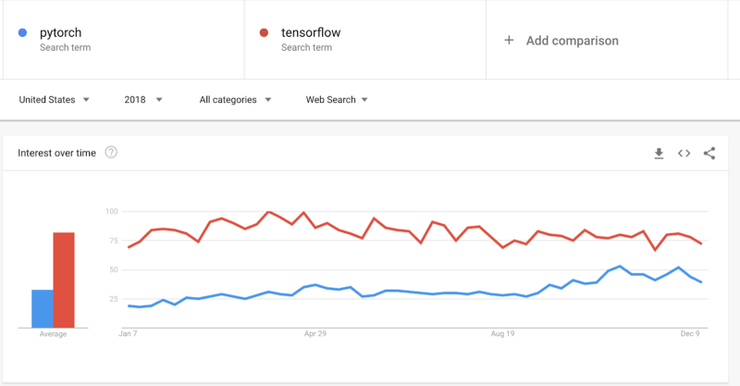
pytorch 與 tensorflow 搜索趨勢
有趣的是,另一個在框架方面看到許多有趣的進展的領域是增強學習。雖然我不認爲 RL 的研究進展與前幾年一樣令人印象深刻(只有最近 DeepMind 的 Impala 浮現在腦海中),但是令人驚訝的是,在一年之內,我們看到了所有主要的 AI 玩家都發布了 RL 框架。Google 發佈了用於研究的 Dopamine 框架,而 Deepmind(隸屬於 Google)發佈了有一定競爭力的 TRFL 框架。Facebook 不甘落後,發佈了 Horizon,微軟也發佈了 TextWorld,而 TextWorld 在基於文本的訓練上更加專業。希望所有這些開源框架在能夠讓我們在 2019 年看到 RL 的進步。
我很高興看到最近 Google 在 Tensor Flow 上發佈了 TFRank。Ranking 是一個非常重要的 ML 應用程序,它可能應該得到更多的重視。
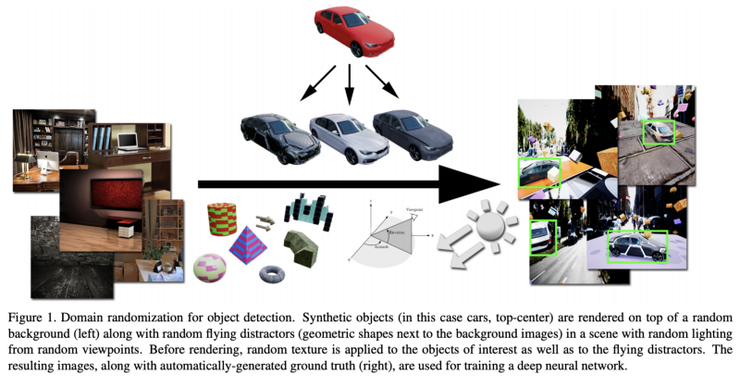
在數據改善領域,也有非常有趣的進展。例如,今年 Google 發佈了 auto-augment,這是一種深度增強學習方法,用於自動增強訓練數據。一個更極端的想法是用合成數據訓練 DL 模型。這種想法已經被在實踐中嘗試了一段時間,並且被許多人視爲 AI 未來的關鍵所在。NVidia 在他們的論文《Training Deep Learning with Synthetic Data》中提出了新穎的想法。在我們「Learning from the Experts」這篇文章中,我們還展示瞭如何使用專家系統生成合成數據,這些合成數據即使在與真實數據結合之後也能用於訓練 DL 系統。
至於人工智能領域的更多基本突破,可能由於我個人偏好的原因,並沒有看到太多。我不完全同意 Hinton 的說法,他認爲這個領域缺乏創新性是由於這個領域有「幾個老傢伙和一大堆年輕人」,儘管科學界有一種趨勢,那就是在研究者會在晚年取得突破性進展。在我看來,當前缺乏突破的主要原因是,現有方法和它們的變體仍然有許多有趣的實際應用,因此很難冒險採用可能並不實用的方法。更重要的是,這個領域的大部分研究都是由大公司贊助的。有一篇有趣的論文《An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling》,雖然它高度依賴過去的經驗,並且使用了已知的方法,但是它打開了發現新方法的大門,因爲它證明了通常被認爲是最優的方法實際上並不是最優的。顯然,我不同意 Bored Yann LeCun 的觀點,他認爲卷積網絡是最終的「主算法」,而 RNN 不是。即便是在序列建模領域,研究空間也很大!另一篇值得研究的論文是最近 NeurIPS 最佳論文「Neural Ordinary Differential Equations」,它挑戰了 DL 中的一些基本問題,包括層本身的概念。
