選自GitHub
近日,Artur Suilin 等人發佈了 Kaggle 網站流量時序預測競賽第一名的詳細解決方案。他們不僅公開了所有的實現代碼,同時還詳細解釋了實現的模型與經驗。我們簡要介紹了他們所實現的模型與經驗,更詳細的代碼請查看 GitHub 項目。
GitHub 項目地址:https://github.com/Arturus/kaggle-web-traffic
下面我們將簡要介紹 Artur Suilin 如何修正 GRU 以完成網站流量時序預測競賽。
預測有兩個主要的信息源:
局部特徵。我們看到一個趨勢時,希望它會繼續(自迴歸模型)朝這個趨勢發展;看到流量峯值時,知道它將逐漸衰減(滑動平均模型);看到假期交通流量增加,就知道以後的假期也會出現流量增加(季節模型)。
全局特徵。如果我們查看自相關(autocorrelation)函數圖,就會注意到年與年之間強大的自相關和季節間的自相關。
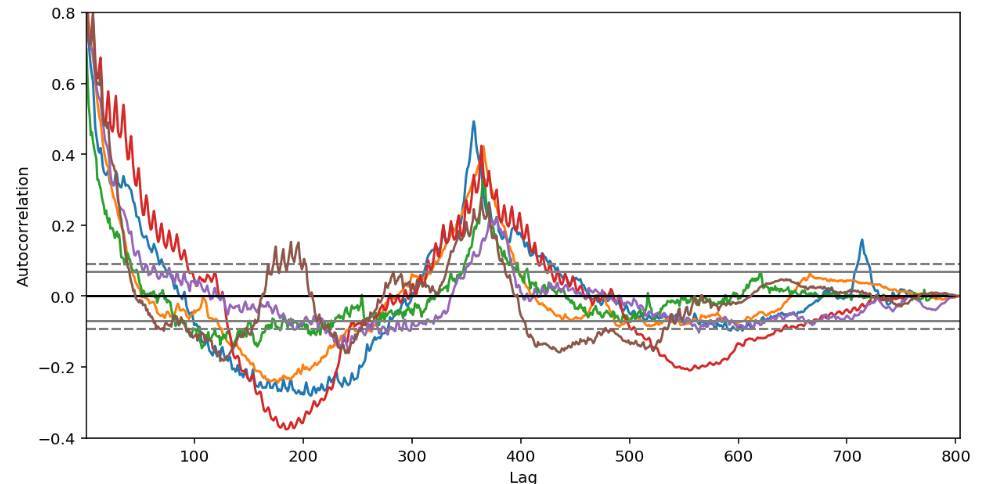
我決定使用 RNN seq2seq 模型進行預測,原因如下:
RNN 可以作爲 ARIMA 模型的自然擴展,但是比 ARIMA 更靈活,更具表達性。
RNN 是非參數的,大大簡化了學習。想象一下對 145K 時序使用不同的 ARIMA 參數。
任何外源性的特徵(數值或類別、時間依賴或序列依賴)都可以輕鬆注入該模型。
seq2seq 天然適合該任務:我們根據先前值(包括先前預測)的聯合概率(joint probability)預測下一個值。使用先前預測可保持模型穩定,因爲誤差會在每一步累積,如果某一步出現極端預測,則有可能毀了所有後續步的預測質量。
現在的深度學習出現了太多的炒作。
特徵工程
RNN 足夠強大來發現和學習自身特徵。模型的特徵列表如下:
pageviews:原始值經過 log1p() 的轉換得到幾乎正態的時序內值分佈,而不是偏態分佈。
agent, country, site:這些特徵從網頁 url 中提取,然後經過 One-Hot 編碼。
day of week:捕捉每週的季節效應。
year-to-year autocorrelation, quarter-to-quarter autocorrelation:捕捉各年、各季度的季節效應。
page popularity:高流量和低流量頁面具有不同的流量變化模式,該特徵(pageviews 的中間值)幫助捕捉流量規模。pageviews 特徵丟失了規模信息,因爲每個 pageviews 序列被獨立歸一化至零均值和單位方差。
lagged pageviews:之後將具體介紹。
特徵預處理
所有特徵(包括 One-Hot 編碼的特徵)被歸一化至零均值和單位方差。每個 pageviews 序列被獨立歸一化。
時間依賴特徵(自相關性、國家等)被「拉伸」至時序長度,即每天重複使用 tf.tile() 命令。
模型在來自初始時序的隨機固定長度樣本上進行訓練。例如,如果初始時序長度是 600 天,我們使用 200 天的樣本進行訓練,那麼我們可以在前 400 天中隨意選擇開始採樣的樣本。
該採樣工作是一種有效的數據增強機制:訓練代碼在每一步隨機選擇每次時序的開始點,生成無限量的幾乎不重複的數據。
模型的核心技術
模型主要由兩部分組成,即編碼器和解碼器。
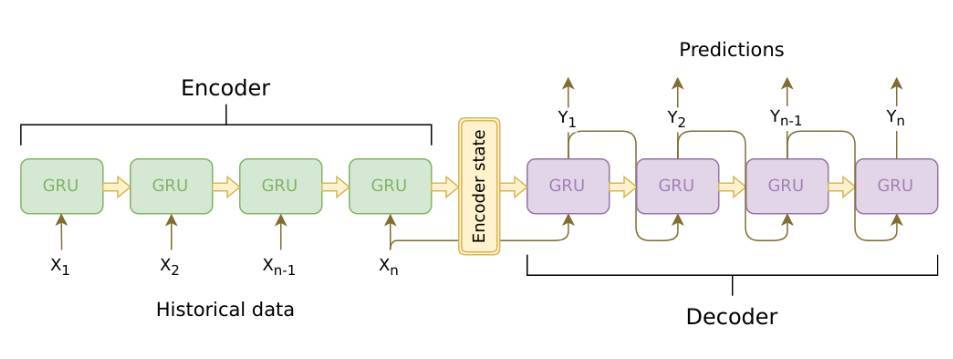
編碼器爲 cuDNN GRU,cuDNN 要比 TensorFlow 的 RNNCells 快大約 5 到 10 倍,但代價就是使用起來不太方便,且文檔也不夠完善。
解碼器爲 TF GRUBlockCell,該 API 封裝在 tf.while_loop() 中。循環體內的代碼從上一步獲得預測,並加入到當前時間步的輸入特徵中。
處理長時間序列
LSTM/GRU 對於相對較短的序列(100-300 項以內)來說是非常好的解決方案。但對於較長的序列來說,LSTM/GRU 仍然有效,只不過會逐漸遺忘較早時間步所包含的信息。Kaggle 競賽的時間序列長達 700 多天,所以我們需要找一些方法來「加強」GRU 的記憶力。
我們第一個方法先是考慮使用一些注意力機制。注意力機制可以將過去較長距離的有用信息保留到當前 RNN 單元中。對於我們的問題,最簡單高效的注意力方法是使用固定權重的滑動窗口注意力機制。它在較長距離的過去時間步上有兩個重要的點(考慮長期的季節性),即 1 年前和 1 個季度前。
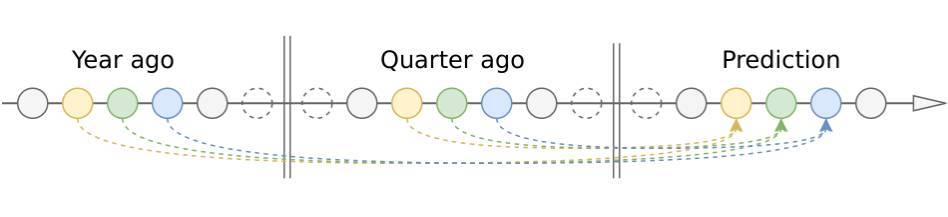
我們可以採用 current_day - 365 和 current_day - 90 這兩個時間點的編碼器輸出,並將它們饋送到全連接層以降低維度,並將結果加入到解碼器的輸入特徵中。這個解決方案雖然簡單卻大大降低了預測誤差。
隨後我們將重要的點與它們的近鄰求均值,並藉此減少噪聲和補償不均勻的間隔(閏年和不同長度的月份):attn_365 = 0.25 * day_364 + 0.5 * day_365 + 0.25 * day_366。
但隨後我們意識到 0.25、0.5、0.25 是一個一維卷積核(length=3),我們可以自動學習更大的卷積核以檢測過去重要的點。
最後,我們構建了一個非常大的注意力機制,它會查看每一個時間序列的「指紋」(指紋由較小的卷積網絡產生),並決定應該注意哪些點和爲較大卷積核生成權重。這個應用於解碼器輸出的較大卷積核會爲每一個預測的日期生成一個注意力特徵。雖然最後沒有使用這種方法,但這個注意力機制仍然保留在代碼中,讀者可以在模型代碼中找到它。
注意,我們並沒有使用經典的注意力方案(Bahdanau 或 Luong 注意力機制),因爲經典的注意力機制應該在每個預測步上使用所有的歷史數據點從頭開始計算,因此這種方法對於較長時間序列(約兩年的天數)來說太耗時間了。所以我們的方案將會對所有數據點進行一次卷積,對所有預測時間步使用相同的注意力權重(這也是缺點),這樣的方案計算起來要快很多。
因爲我們對注意力機制的複雜度感到不太滿意,因此我們試圖完全移除注意力機制,並將一年前、半年前、一季度前重要的數據點作爲編碼器和解碼器的附加特徵。這樣的結果是非常令人驚訝的,甚至在預測質量方面都要比帶注意力機制的模型略勝一籌。因此我們最好的公開分數都是僅使用滯後(lagged)數據點實現的,它們都沒有使用注意力機制。
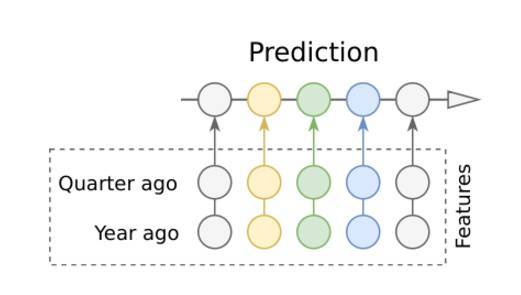
滯後數據點另一個重要的優勢是,模型可以使用更短的編碼器而不需要擔心損失過去的信息,因爲這些信息現在明確地包含在特徵中。在採用這種方法後,即使我們編碼器的長度是 60 到 90 天,結果也是完全可以接受的,而以前需要 300-400 天的長度才能獲得相同的性能。此外,更短的編碼器就等於更快速的訓練和更少的信息損失。
損失和正則化
SMAPE(競賽用的目標損失函數)因其在零值周圍不穩定的行爲而無法直接使用(當真值爲零的時候,損失函數是階躍函數;預測值也爲零的時候,則損失函數不確定)。
我使用經平滑處理的可微 SMAPE 變體,它在所有實數上都表現良好:
epsilon =0.1
summ =tf.maximum(tf.abs(true)+tf.abs(predicted)+epsilon,0.5+epsilon)
smape =tf.abs(predicted -true)/summ *2.0
另一個選擇是在 log1p(data) 上的 MAE 損失函數,它很平滑,且訓練目標與 SMAPE 非常接近。
最終預測取最接近的整數,負面預測取零。
我嘗試使用論文《Regularizing RNNs by Stabilizing Activations》中經正則化的 RNN 激活值,因爲 cuDNN GRU 的內部權重無法直接正則化(也可能是我沒有找到正確的方法)。穩性損失(Stability loss)不起作用,激活損失可以爲較小損失權重(1e-06..1e-05)帶來少許改進。
訓練和驗證
我使用 COCOB 優化器(詳見論文《Training Deep Networks without Learning Rates Through Coin Betting》)結合梯度截斷進行訓練。COCOB 嘗試預測每個訓練步的最優學習率,因此我完全不必調整學習率。它的收斂速度也比傳統的基於動量的優化器快得多,尤其是在第一個 epoch 上,可以讓我及早停止不成功的實驗。
有兩種方式可以將時序分割爲訓練和驗證數據集:
Walk-forward 分割。這實際上不是分割:我們在完整數據集上訓練和驗證,但使用不同的時間跨度。驗證用的時間跨度比訓練用時間跨度前移一個預測間隔。
Side-by-side 分割。這是主流機器學習傳統的分割模型。數據集被分割成兩個獨立的部分,一個用於訓練,另一個用於驗證。
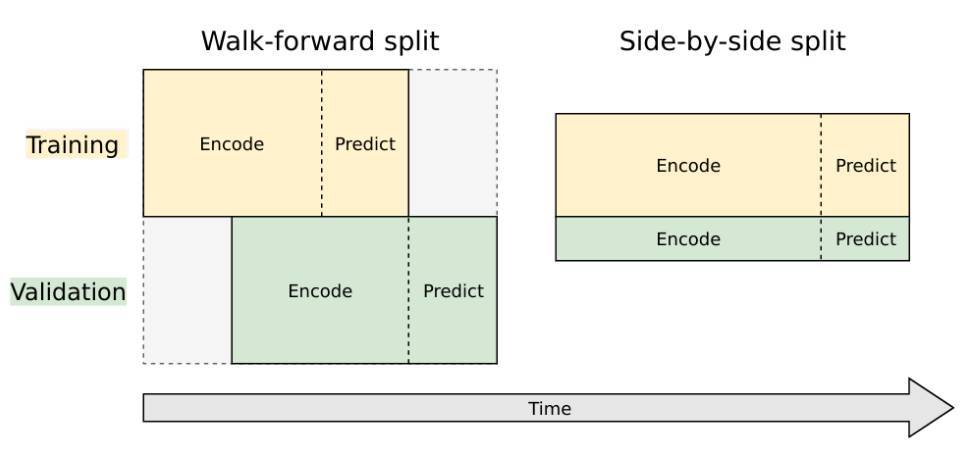
兩種方式我都試了,但對於這個任務來說 Walk-forward 更好,因爲它與競賽目標直接相關:使用歷史值預測未來值。但是該分割破壞了時序結尾的數據點,使得訓練準確預測未來的模型變得困難。
具體來說:比如,我們有 300 天的歷史數據,想預測接下來 100 天的數據。如果我們選擇 walk-forward 分割,我們必須使用前 100 天的數據用於真實訓練,後面 100 天的數據用於訓練模式的預測(運行解碼器、計算損失),再後面 100 天的數據用於驗證,最後 100 天用於對未來值真正進行預測。因此,我們實際上可以使用 1/3 的數據點來訓練,最後一個訓練數據點和第一個預測數據點之間隔了 200 天。間隔太大了,因爲一旦我們離開某個訓練數據,預測質量將出現指數級下降(不確定性增加)。使用 100 天差距訓練的模型預測質量相對較好。
Side-by-side 分割所需要的計算力更少,因爲它在端點時並不會消耗數據點。但是對於我們的數據,模型在驗證集上的性能與在訓練集上的性能是強相關的,並且與將來的實際模型性能幾乎不具有相關性。換而言之,並行分割對於我們的問題基本上是沒有什麼作用的,它只是複製了在訓練數據集上觀察到的模型損失。
我僅使用驗證集(帶有前向分步分割)進行模型調優,預測未來數值的最終模型只是在盲目的模式中進行訓練,沒有使用任何驗證集。
降低模型方差
優於強噪音數據的輸入,模型不可避免地具有高方差。坦白講,我很驚訝 RNN 居然從噪音數據中學習到了東西。
在不同 seed 上訓練的相同模型具有不同的表現,有時模型甚至在「不幸」的 seed 上變得發散。訓練期間,表現也會逐步地發生很大波動。依靠純粹的運氣很難贏得比賽,因此我決定採取行動降低方差。
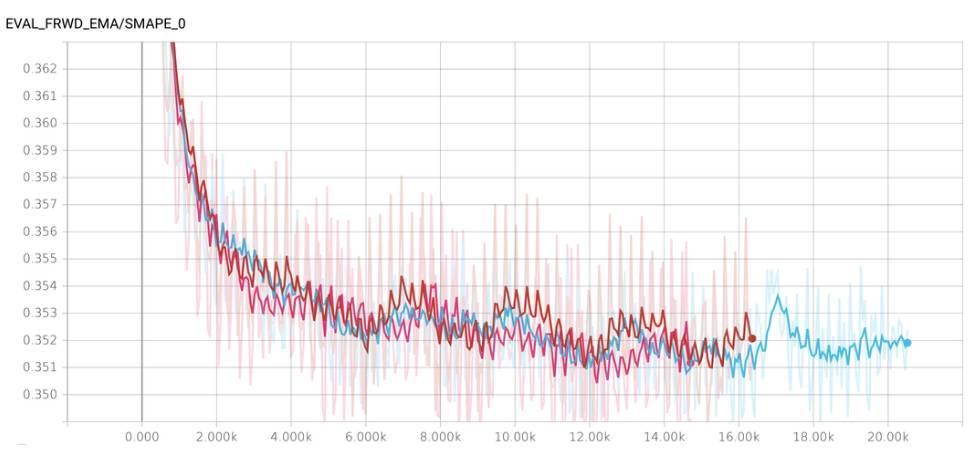
我不知道哪個訓練步驟最適合預測未來(但前數據的驗證結果與未來數據的結果只有弱相關關係),所以我不能使用提前停止。但是我知道近似區域,其中模型(可能)進行了充分訓練,但(可能)沒有開始過擬合。我決定把這個最佳區域設置爲 10500 到 11500 次迭代區間內,並且從這個區域的每第 10000 個步驟保存 10 個檢查點。
相似地,我決定在不同的 seed 上訓練 3 個模型,並從每個模型中保存檢查點。因此我一共有 30 個檢查點。
降低方差、提升模型性能的一個衆所周知的方法是 ASGD(SGD 平均)。它很簡單,並在 TensorFlow 中得到很好的支持。我們必須在訓練期間保持網絡權重的移動平均值,並在推斷中使用這些平均權重,而不是原來的權重。
三個模型的結合表現不錯(在每個檢查點上使用平均模型權重的 30 個檢查點的平均預測)。我在排行榜上(針對未來數據)獲得了相較於歷史數據上的驗證大致相同的 SMAPE 誤差。
理論上講,你也可以把前兩種方法用作集成學習,但我主要用其降低方差。
超參數調節
很多模型參數(層的數量、深度,激活函數,dropout 係數等)能夠(並且應該)被調節從而獲得更優的模型表現。手動調節乏味且費時,所以我決定自動化該過程,並使用 SMAC3 搜索超參數。下面是 SMAC3 的一些優勢:
支持條件參數(例如,爲每層聯合調節層數和 dropout;如果 n_layers > 1,第二層上的 dropout 將被調節)
明確處理模型方差。SMAC 在不同種子上訓練每個模型的若干個實例,如果實例在相同種子上訓練還要對比模型。如果它在所有相同種子上優於另一個模型,則該模型獲勝。
與我的期望相反,超參數搜索並沒有建立定義明確的全局最小。所有的最佳模型大致具有相同的性能,但參數不同。可能 RNN 模型對於這個任務來說太具有表現力了,並且最好的模型得分更多依賴於模型架構上的數據信噪比。不管怎樣,最好的參數設置依然可以在 hparams.py 文件中找到。
原文鏈接:https://github.com/Arturus/kaggle-web-traffic/blob/master/how_it_works.md