按:近日,Facebook 人工智能研究院 ( FAIR ) 宣佈開源首個全卷積語音識別工具包 wav2letter++。系統基於全卷積方法進行語音識別,訓練語音識別端到端神經網絡的速度是其他框架的 2 倍多。他們在博客中對此次開源進行了詳細介紹。
由於端到端語音識別技術能夠輕易擴展至多種語言,同時能在多變的環境下保證識別質量,因此被普遍認爲是一種高效且穩定的語音識別技術。雖說遞歸卷積神經網絡在處理具有遠程依賴性的建模任務上很佔優勢,如語言建模、機器翻譯和語音合成等,然而在端到端語音識別任務上,循環架構纔是業內的主流。
有鑑於此,Facebook 人工智能研究院 (FAIR) 的語音小組上週推出首個全卷積語音識別系統,該系統完全由卷積層組成,取消了特徵提取步驟,僅憑端到端訓練對音頻波形中的轉錄文字進行預測,再通過外部卷積語言模型對文字進行解碼。隨後 Facebook 宣佈開源 wav2letter ++——這種高性能框架的出現,讓端到端語音識別技術得以實現快速迭代,爲技術將來的優化工作和模型調優打下夯實的基礎。
與 wav2letter++ 一同宣佈開源的,還有機器學習庫 Flashlight。Flashlight 是建立在 C++基礎之上的機器學習庫,使用了 ArrayFire 張量庫,並以 C++進行實時編譯,目標是最大化 CPU 與 GPU 後端的效率和規模,而 wave2letter ++工具包建立在 Flashlight 基礎上,同樣使用 C++進行編寫,以 ArrayFire 作爲張量庫。
這裏着重介紹一下 ArrayFire,它可以在 CUDA GPU 和 CPU 支持的多種後端上被執行,支持多種音頻文件格式(如 wav、flac 等),此外還支持多種功能類型,其中包括原始音頻、線性縮放功率譜、log 梅爾譜 (MFSC) 和 MFCCs 等。
Github 開源地址:
https://github.com/facebookresearch/wav2letter/
在 Facebook 對外發布論文中,wav2letter++被拿來與其他主流開源語音識別系統進行對比,發現 wav2letter++訓練語音識別端到端神經網絡速度是其他框架的 2 倍還多。其使用了 1 億個參數的模型測試,使用從 1~64 個 GPU,且訓練時間是線性變化的。
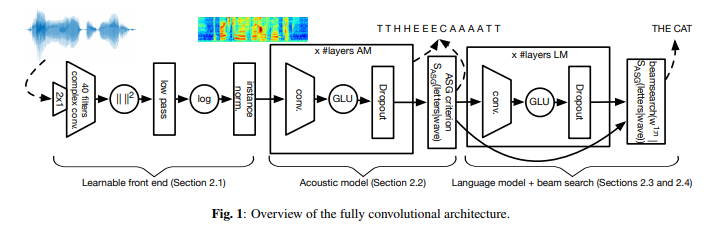
圖片來源:Facebook
上面爲系統的網絡結構圖,主要由 4 個部分組成:
可學習前端(Learnable front end):這部分包含寬度爲 2 的卷積(用於模擬預加重流程)和寬度爲 25 ms 的復卷積。在計算完平方模數後,由低通濾波器和步長執行抽取任務。最後應用於 log-compression 和 per-channel mean-variance normalization 上。
聲學模型:這是一款帶有門線性單元(GLU)的卷積神經網絡,負責處理可學習前端的輸出內容。基於自動分割準則,該模型在字母預測任務上進行訓練。
語言模型:該卷積語言模型一共包含 14 個卷積殘差塊,並將門線性單元作爲激活函數,主要用來對集束搜索解碼器中語言模型的預備轉錄內容進行評分。
集束搜索解碼器(Beam-search decoder):根據聲學模型的輸出內容生成詞序列。
想深入瞭解系統背後運作原理感的同學,可以自行查閱完整內容:
https://arxiv.org/abs/1812.07625
wav2letter++: The Fastest Open-source Speech Recognition System
via https://opensource.fb.com/