計算機視覺盛會 CVPR 2017已經結束了,我們帶來的多篇大會現場演講及收錄論文的報道相信也讓讀者們對今年的 CVPR 有了一些直觀的感受。
論文的故事還在繼續
相對於 CVPR 2017收錄的共783篇論文,即便近期挑選報道的獲獎論文、業界大公司論文等等是具有一定特色和代表性的,也仍然只是滄海一粟,其餘的收錄論文中仍有很大的價值等待我們去挖掘,生物醫學圖像、3D視覺、運動追蹤、場景理解、視頻分析等方面都有許多新穎的研究成果。
所以我們繼續邀請了宜遠智能的劉凱博士對生物醫學圖像方面的多篇論文進行解讀,延續之前最佳論文直播講解活動,此次是第2篇。
劉凱博士是宜遠智能的總裁兼聯合創始人,有着香港浸會大學的博士學位,曾任聯想(香港)主管研究員、騰訊高級工程師。半個月前宜遠智能的團隊剛剛在阿里舉辦的天池 AI 醫療大賽上從全球2887支參賽隊伍中脫穎而出取得了第二名的優異成績。
在 8 月 1 日的直播分享中,劉凱博士爲大家解讀了「Joint Sequence Learning and Cross-Modality Convolution for 3D Biomedical Segmentation」(用於三維生物醫學分割的合併序列學習和多形態卷積)這篇論文,它主要解決了一個三維生物醫學圖像分割中重要問題:如何綜合使用多種形態的 MRI 數據進行區域分割。以下爲當天分享的內容總結。

圖文分享總結
劉凱博士:大家好,我是深圳市宜遠智能科技有限公司的劉凱,我們的官網是 yiyuan.ai。這裏也有我的微博ID,我經常會發一些跟人工智能相關的資料和文章,大家可以關注一下。今天講的也是關於生物醫學圖像的應用,是結合序列學習和交叉模態卷積的3D生物醫學圖像分割。其實在醫學圖像方面,分割,英文是segmentation,是非常重要的工具或者應用。
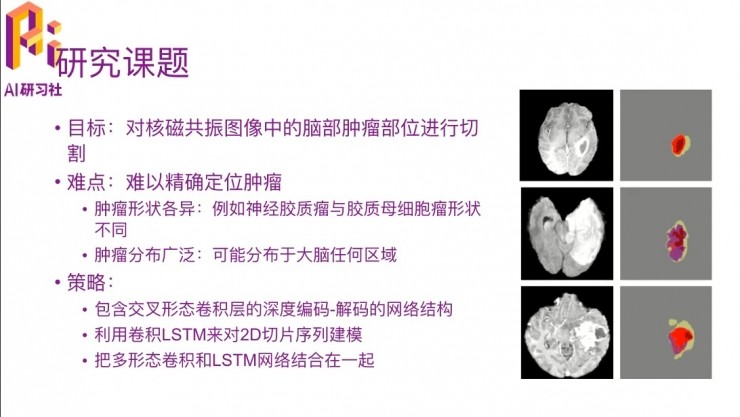
我先講一下這篇文章的主要內容,它講的是對核磁共振圖像中的腦部腫瘤部位進行切割的例子。右邊的圖給出來的就是什麼叫「對腫瘤部位進行切割」。我們通過MRI拍出來圖片,如果有一些跟正常的大腦皮層細胞不太一樣的部位,這些部位就很有可能是有腦部腫瘤,所以要把它切出來,切出來之後再做相應的研究。比如這三個例子可以看到大腦中有一些病變的位置,要達到的就是最右邊一列的樣子,把它們切出來。這個工作其實不算太容易,主要有幾個方面的原因。
首先比較難定位到哪些是腫瘤部位,因爲腫瘤部位的形狀千奇百怪,沒有固定的形狀,不像人臉識別的時候,每個人的五官都差不多,位置區別也不會很大。比如說神經膠質瘤和膠質母細胞瘤的形狀兩種就就很不同,就是不同的腫瘤形狀也不一樣。然後腫瘤的分佈很廣泛,可能分佈在大腦的任何區域,那跟人臉也不一樣了,就跟剛纔我說一樣。
那怎麼去實現、怎麼去解決這些難點呢,這篇文章提出來一個思路就是交叉形態卷積的方法做一個 encoder-decoder 的網絡結構,然後同時用LSTM對2D的切片序列建模。
這裏有個概念,因爲MRI也是跟CT一樣斷層掃描的過程,就是它一層一層,一層掃出來的就是一個2D的圖片,然後多層累計起來就是3D的,但是其實切割是要切割出3D的腦部腫瘤位置,這樣就需要把2D的變成3D的,把2D的切片之間的關係通過LSTM描述出來,最後把多模態卷積和LSTM網絡結合在一起,達到3D切割。

剛纔提到多模態的概念,就是因爲這個是MRI特有的特徵,因爲CT裏面並沒有。這裏有四個模態,就是通過四種方式掃描腦部得到MRI數據,這是這裏列出來的四個的名字,我們先不用管它這四個具體是什麼意思,只是知道它有四種模態就行了,這四種模態對最終切割的結果是有直接的作用的。現在大多數的3D圖像切割方法只是用了一個模態,或者把多個模態分別來做,然後再堆積起來。
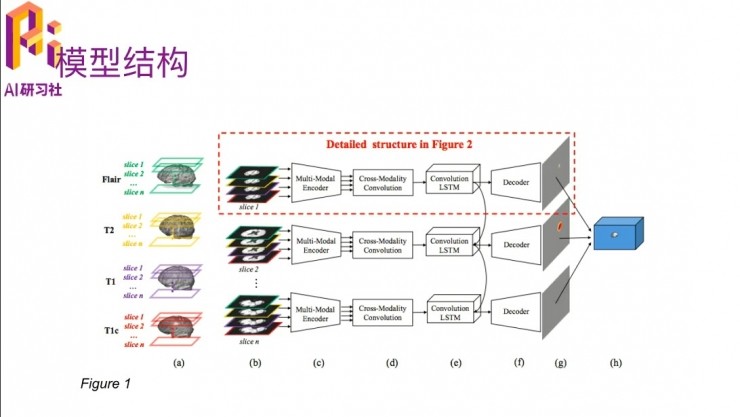
這個方法的framework大概是這樣的,從左到右看。
首先每一個腦部的MRI數據,他都是通過四種模態切出來的,這裏用四種不同的顏色來表示,相當於每一個slice就是我說的那個2D的圖片。
切完之後他會把四個模態,就是到圖b這個階段了,四個模態交叉在一起做一個multi-modal的encoder,這個encoder就是用一個神經網絡來實現的。
四個模態encode到一起之後,在這一步就用神經網絡把四個模態下的腦部切割出來了,這是2D的情況下。
然後再加上convolution LSTM把2D的切割、2D和2D之間的dependency描述出來之後就形成了3D的切割,然後再做一下decoder,展現成最後這種形式。在最中間有一個切割出來的東西,其他沒被切割到的background。
這就是一個大體的流程,然後對具體對每一個細節的過程,我再詳細介紹一下。
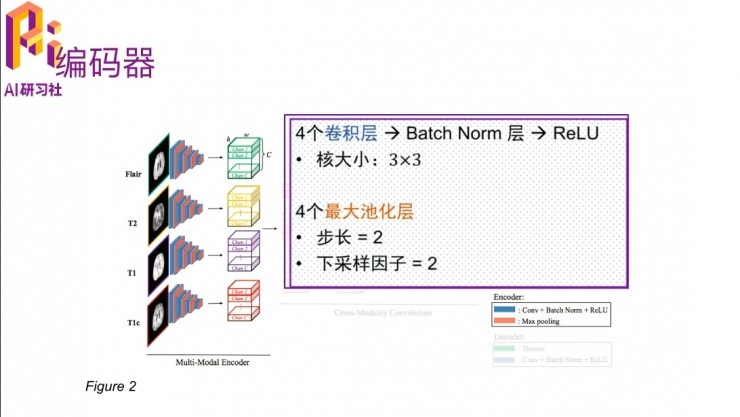
第一個模塊就是multi-modal的encoder,這裏的網絡結構最主要的幾個方面是用四個卷積核,通過batch-normalization,然後加一個非線性變換,在後面有四個最大池化層。這就是先簡單介紹一下,如果要詳細瞭解這個網絡結構是怎麼設計的,可以去讀一下這篇論文。
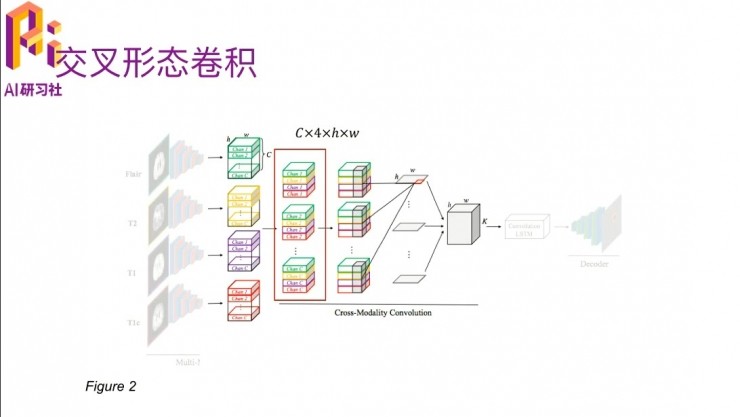
另外一個嗯比較重要的部分就是多模態交叉卷積。四個模態的數據進入到這個卷積網絡之後,他就會把每一個模態下面的cross在一起,然後通過一個三維的卷積,卷積的大小裏有個C×4,就是因爲他每個channel裏面有 c 個slice,就是說它是一個立體結構了,一個長寬是H、W,高是C的這種。四個模態弄到一起就是C×4×H×W,有大小。
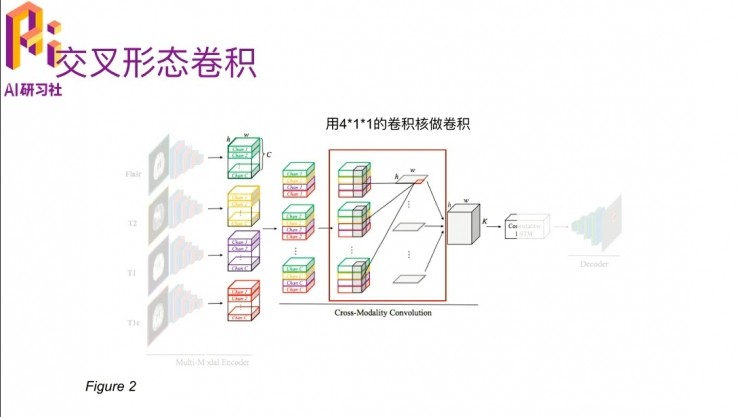
然後在這裏,是用4×1×1的一個卷積核,做卷積之後得到每一層的切割出來的特徵。切割出來之後,然後就進入了後面的convolution LSTM。

這個convolution LSTM跟普通的LSTM有一個區別,就是把原來的矩陣相乘替換爲一個卷積操作,就是普通的乘法變成卷積層,這樣它就能夠在把之前狀態的空間信息保留着。其實它的目的就是,卷積LSTM會描述一個2D切割邊緣的趨勢,比如說這一張中切片它的形態是這樣的,然後到下一張它會有一個輕微的變化,要把這種變化描述出來。
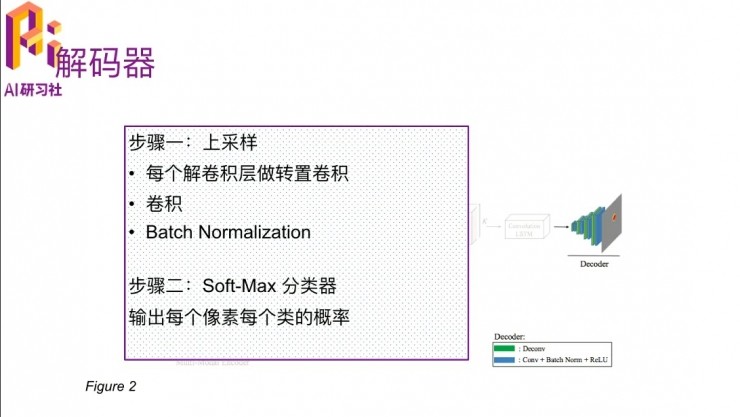
因爲剛開始有一個圖像的encoder,還是要把它解析出來。最後就有一個soft-max的分類,也是一個兩分類的,就是每一個像素是前景還是背景的概率。是前景的話,就是我們要切割出來的部位;如果是背景的話就不是我們感興趣的地方。
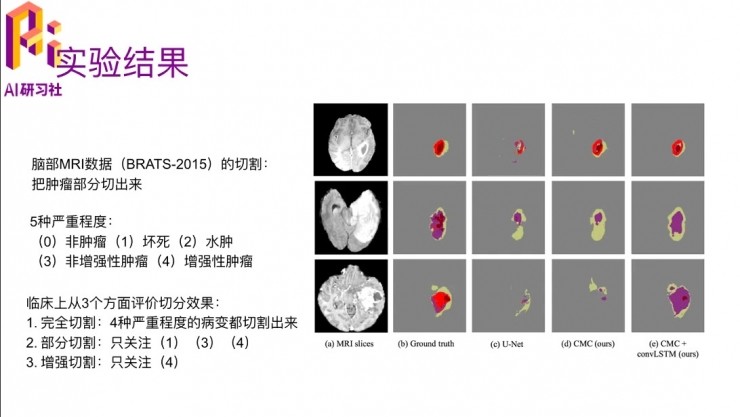
它的實驗部分做了兩個,第一個跟醫學沒有關係,這個通用的場景就不講了。我講一下跟醫學相關的那個,他有一個公開的腦部MRI的數據,就叫BRATS-2015。
他切的是神經膠質瘤這個疾病,它的嚴重程度分爲五種,0 就是非腫留,1 是腦細胞壞死,2 是水腫,3 是非增強性腫瘤,4 是增強性腫瘤,數字從低到高,它嚴重程度會越來越高。臨牀上是從三種不同的方面去評價切分的效果:
第一種,完全把四種嚴重程度的病都切割切割出來,相當於區分腫瘤和非腫瘤;
第二種,部分切割,只關注 1、3、4 這三種。2 的水腫,其實也是比較容易混淆的,就是它不是真正的腫瘤
第三種,只關注增強型的腫瘤,就是最嚴重的那種
最右邊是一個圖例,看這幾種方法哪一個切的好一些。第二列是就是ground truth,第三列是U-Net,是一個提的比較早、比較通用的一個benchmark的方法,來做數據切割;然後第四列的CMC,cross-modality convolution,這個也是這篇文章提出來的;然後CMC+convolution LSTM,就是描述了切片與切片之間的dependency的算法。可以看出來,最後一個跟ground truth是比較接近的。

這裏有從三個方面看的評價結果,三個指標。其實都是算它切割得跟ground truth重合的部分的比例,第一種「Dice」就是它的 overlap 部分,除以他們兩個面積交集和並集的一個平均,這裏的P就是predict出來的區域,然後T是ground truth的區域。PPV是positive predicted value,那是他的交集部分除以預測的區域;sensitivity就是交集的面積除以ground truth區域。這裏也是跟U-Net比較了一下。
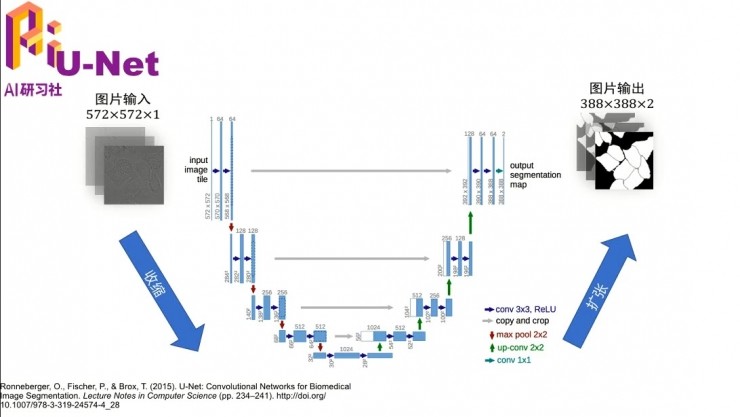
我下面補充一下這個U-Net的概念,如果沒有醫學圖像切割的一些知識背景的話,可能不太理解它。其實U-Net就是一個網絡結構,參考文獻在最下面。這種網絡結構,就是畫出來長得字母U,然後所以叫yU-Net。
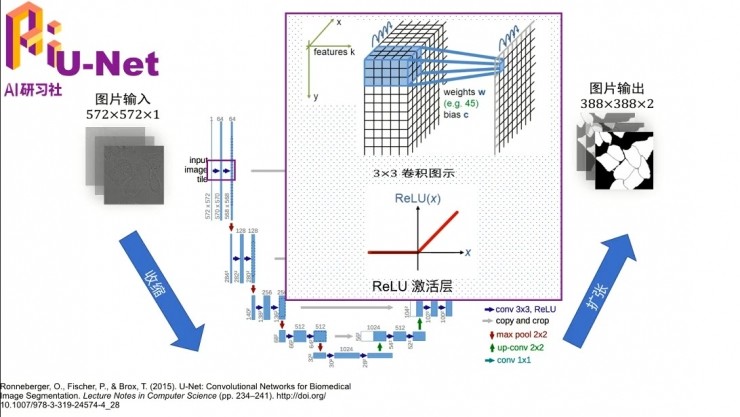
它之所以長成這樣,是因爲這個圖像進來,最左邊可能大家看的不是很清楚,圖像裏其實是一個一個的細胞,它們都連在一起,但是邊緣是有一些線割開的。網絡的目標是把這些細胞一個一個地切開,就像最右邊的這種情況。網絡剛開始的時候用的卷積就先是3×3的卷積,然後加上ReLu這個非線性變換,然後一步一步做下去。其實這個網絡結構還是挺深的,如果有興趣可以去看一下這篇文章。其實這個算法對大物體小物體的切割都是做得還不錯的,就是因爲這種U結構的,先對大物體切割,然後再去對小物體切割。

這裏面還有一些trick,就是在BRATS-2015這個數據上來,因爲這個數據量其實不大,好像正例一共只有60多個,負例兩百多個。這裏也出現了一個數據不均衡的問題,它是用median frequency平衡法,這個很簡單,這個算式裏有一個除法,就是分子式median frequency,就是每一個類的平均frequency,除以這一類總的出現的次數。如果出現次數越多,那它這個權重就會越小,就是賦了一個比較小的權重,就在 loss 函數裏對這一類的數據設定了一個權重,相當於下采樣的過程。
在這個學習過程中使用了two-stage training,第一個階段是隻採用了包含腫瘤的切片,然後用median frequency減少大類的權重。第二階段是降低學習率,然後把median frequency這種限制去掉,它的分佈就是接近你的真實的分佈,因爲如果使用median frequency,它的分佈是會變的,但是真實數據中那個大類的確實會存在,還是要去描述這個問題,先保證了這個模型第一部分不收斂到大類這個問題之後,然後第二個階段去再去慢慢的學習真實的分佈。
在第一階段的時候避免採樣到空的序列,就是先去採樣了有腫瘤問題的,然後再在訓練LSTM的時候也用了正交初始化的方法處理梯度消失的問題。這種方法其實都是可以用的,不一定非得這個問題上去用。

我讀到最後就發現一個不太好的一個地方,就是他在前面後面都提到了這個KU-Net,它說了跟它的方法模型是最相關的,其實這個KU-Net就是用U-Net+RNN,他用RNN也是去描述2D切片之間的dependency。
這篇論文裏方法的不同就是,它用的交叉模態的方法去代替U-Net的那一部分,然後用LSTM去代替RNN那一部分。從直觀上來講應該會比這個KU-Net效果要好,但是他說因爲沒有公開代碼不進行實驗對比,我覺得這個理由不是特別充分。其實寫文章的時候既然他都給了U-Net的比較了,然後這種跟他更相關的、而且思路上也挺像的,應該更要比較一下才對。
問答環節
(先上一次論文講解中的問題開始)
Q:Sequntial learning的時候有沒有用move-and-average,就是有沒有移動平移法
A:這個那篇文章裏面並沒有講,但是我覺得這個移動平均法在sequntial的學習的時候還是可以用的,就是相當於你在不同的步驟的預測值都做一個平均,還是有一定的推廣性的。
Q:關於醫學圖像數據不平衡的問題
A:其實不平衡的問題,解決方法有好多種,最簡單的就是上採樣和下采樣。如果那些大類的數據特別多,做一下下采樣,然後小類的做一下上採樣。這個比較簡單,然後我在實際問題中有一些經驗,其實不是這一類多就一定要下采樣,這一類少就一定要上採樣,其實要看它具體的分佈。
有的時候,比如說我們在做肺結節檢測的這個過程中,通過肺CT或者X光去看那個肺部有一些會癌變的結節,去找這些病變的點。其實在這裏面小結節會比較多,大結節會比較少。在這種例子裏,大家直觀的很可能覺得要下采樣小結節,那實際上並不是的,我們這反而是上採用了上採樣的小結節,就是把它的數據要增多。因爲小結節比較難分,它其實很小,跟background非常像,然後就容易被忽略掉,然後大結節就很明顯,即使只有少量的數據,它也能分出來的。
所以這個跟實際的應用有關係,一般情況下做模型之前一個很大的步驟是要去處理數據,有的時候一些trick是從數據得到靈感,就應該去怎麼去實現。包括數據增強也好,怎麼解決數據偏移也好。這是預處理的部分。
然後在實際訓練中解決數據不平衡的問題可以通過一個叫hard negative mining的方式,就比如剛開始的數據不平衡,有的傾向於分到大類那一部分。而且你這個模型在分的時候,前期會有一些分錯的,分錯了就說明這個模型分的效果還不太好。比如說把小類的分到大類裏面去了,明顯是分錯了,然後就把這些分錯的小類的找出來,做一下增強,比如說做兩倍的增強,然後再放到模型裏面、再去學,這樣持續下去,就會有針對性的把小的數據去增強,慢慢把數據變平衡了。這個思路其實是跟剛纔的數據預處理是一樣的,但是更靈活一些,因爲在訓練之前,直接把小的類做增強,這種是比較主觀的,實際上不一定小類的就難分,最好先去模型試一下,看哪些比較難分,然後就專注於這種數據去做數據增強。其實上一篇論文講解直播的時候,論文裏面也提到這個思路。
然後數據增強的時候其實也挺有意思的,上一篇論文裏面提到要根據泛化能力比較強的做增強,而不是統一形式的增強。我們在實際在做的時候,也還是以肺結節爲例子,我們在做hard negative mining的時候,因爲在肺結節檢測裏面少,就是發現肺結節在跟常規思路的機器學習方式有一些相反的現象。其實正例跟負例相比,本身是偏少的,因爲他那個肺裏面有很多部位結節是很少的。但是實際模型去訓練,然後訓練的時候就會發現好多並不是結節的預測成結節了。這個需要hard negative mining,就是要把negative的sample要增強一些。原來我們心想的通常情況下是應該把少的那一部分增強,那肺結節檢測是實際上是相反的。在腦部切割的時候也會有這個問題。
然後最近關於一個segmentation的一個新的方法,目前還沒有用到在segmentation裏面,我只是有一個想法,提出目標檢測Fast-RCNN這一系列的何愷明發了一篇文章,是Fast-RCNN的延續,叫做Mask-RCNN,就不光是把那個目標能檢測出來了,還能把目標的輪廓給畫出來。這樣的話就非常像這裏,比如說把病變的位置detect出來,其實是在這個地方畫了一個rectangle,這是找出它的位置了。如果我們要把病變區域切出來的,就要沿着它的輪廓,把它做一個mask。我覺得這個方法是可以試一下的,就相當於把目標檢測和segmentation結合在一起了,所以還是一個挺好的思路。
(等待問題過程中順便插播一則公司介紹)
我們宜遠智能位於深圳,也是一個初創公司,主要是做人工智能在醫學圖像處理上的應用,然後做一些基於醫學圖像的輔助診斷,大家有興趣的話可以去我們官網看一下。我們現在也在招人,如果有興趣的話可以在微博裏面艾特我或者發郵件給我,郵箱地址是 kennethkliu@foxmail.com。加我的微信也可以,但是微信的話我也不會發太多東西。微信號是 kenneth_liukai。
Q:這個問題有人問,我重複一下。也是數據不平衡的問題,當positive和negative不平衡的時候可以做hard negative mining。那麼假如第一次分類有部分數據分錯了,那麼增強的權重是重採樣權重還是梯度的權重?
A:這個是兩種都可以,我們實際中一般是數據重採樣。如果增加梯度的權重,其實不知道是針對哪一種。只是說這個權重的話,就把數據重新放進去。增加權重也可以,但是你增加這個權重的時候,學的時候就不只針對分錯的那些了,會對所有的數據都增加了權重。那麼還是重採樣來得更直接一些,就是分錯的那個數據再重新放進去,或者是加倍重新放進去,再去訓練,這個都是可以的。
其實在圖像上面做數據增強,不光是重採樣,還有一些時候爲了增加它的泛化性,會做一些偏移、切割、平移這種操作,也是很有效果的。
Q:除了重採樣,還有其他辦法解決數據不平衡的問題嗎?
A:重採樣跟數據不平衡,其實是同一個思路。因爲數據不平衡,你爲了能達到平衡,那就是要打亂原來的數據分佈了。除非這個模型對數據不平衡的狀況不敏感,就是說即使數據不平衡,也能學出來,大類就大類的學,小類就小類的學。這種就是要考驗模型的能力的,有些模型即使類別比較小的也是能夠學出來的,要看這個模型的區分能力了。
Q:如果數據圖像label有時標錯的比較厲害,標錯的比例甚至達到1/3,有沒有什麼數據清洗的辦法?
A:對這個這個問題非常好,因爲在醫學圖像裏面這個問題特別嚴重。
其實醫學標註數據是有很強的背景知識要求,一般都是要比較高水平的醫生標的纔會比較準確。
對普通的醫生來說,比如說有一些結節,或者一些腦部的MRI上病變的位置,其實在那裏,但他就看不到,因爲他知識水平有限,他就沒見過這種東西。我們也曾經試過要用好幾個醫生然後去標,水平不一樣,指標的差異還挺大的,跟ground truth差距就更大了。
當然了這個ground truth也不是標準的ground truth,只是三個專家級的醫生標的共同的結果。這種方法可以這麼來,就是說你的模型也可以去標一下。如果這個模型是完全基於現在這種「髒」數據學出來的,那麼它真的是沒辦法能夠學得好,那它就是去擬和這個「髒」數據了。如果有另外一個好的模型,就可以transfer過來,它去把這個數據標一遍,跟達到1/3標錯的那個數據一起,相當於兩個專家會診一樣。它會有一個統計分佈,這種情況下能夠一定程度上把那些「髒」數據給剔除掉。這是一種思路。
另外的話,有一些如果他標錯了,就會出現同樣的圖像、非常相近的圖像,得到了不同的label。這種就是標註相沖突的,這也是一個問題。我們就可以拿一個ImageNet pre-train的model去看兩個圖像的差異。假如說真的差異很小,然後label標註的截然相反,就可以做一定形式的過濾。
這個問題我不知道回答的好不好,我就是以我的經驗來說。這其實是一個開放性的問題,可能有很多的方法去實現。其實做機器學習,ground truth就相當於一個先知,告訴你哪些是真的標註數據,那纔是真正的標註數據。那實際上很多都是人標的,人的知識水平就限制了標註質量的好與差。
感謝劉凱老師帶來的分享。
相關文章:
CVPR 2017精彩論文解讀:顯著降低模型訓練成本的主動增量學習 | 分享總結
ICML 2017最佳論文:爲什麼你改了一個參數,模型預測率突然提高了|分享總結