作爲 Facebook 人工智能團隊(FAIR)提供支持的深度學習框架,PyTorch 自 2017 年 1 月推出以來立即成爲了一種流行開發工具。其在調試、編譯等方面的優勢使其受到了學界研究者們的普遍歡迎。本文中,來自蒙特利爾綜合理工學院的研究員 Christian S. Perone 將爲我們介紹這種神經網絡框架的內部架構,揭開 PyTorch 方便好用的真正原因。
前言
本文主要介紹了 PyTorch 代碼庫,旨在爲 PyTorch 及其內部架構設計提供指導,核心目標是爲那些想了解 API 知識之外的人提供有益的幫助,並給出之前教程所沒有的新內容。注意:PyTorch 構建系統需要大量使用代碼設置,因此其他人的描述我將不再重複。如果你感興趣,請參考原文提供的擴展資料。
C/C++中 Python 擴展對象的簡介
你可能知道可以藉助 C/C++擴展 Python,並開發所謂的「擴展」。PyTorch 的所有繁重工作由 C/C++實現,而不是純 Python。爲了定義 C/C++中一個新的 Python 對象類型,你需要定義如下實例的一個類似結構:
// Python object that backs torch.autograd.Variablestruct THPVariable { PyObject_HEAD torch::autograd::Variable cdata; PyObject* backward_hooks;};如上,在定義的開始有一個稱之爲 PyObject_HEAD 的宏,其目標是標準化 Python 對象,並擴展至另一個結構,該結構包含一個指向類型對象的指針,以及一個帶有引用計數的字段。

Python API 中有兩個額外的宏,分別稱爲 Py_INCREF() 和 Py_DECREF(),可用於增加和減少 Python 對象的引用計數。多實體可以借用或擁有其他對象的引用(因此引用計數被增加),而只有當引用計數達到零,Python 纔會自動刪除那個對象的內存。想了解更多有關 Python C/++擴展的知識,請參見:https://docs.python.org/3/extending/newtypes.html。
有趣的事實:使用小的整數作爲索引、計數等在很多應用中非常見。爲了提高效率,官方 CPython 解釋器緩存從-5 到 256 的整數。正由於此,聲明 a = 200; b = 200; a is b 爲真,而聲明 a = 300; b = 300; a is b 爲假。
Zero-copy PyTorch 張量到 Numpy,反之亦然
PyTorch 有專屬的張量表徵,分離 PyTorch 的內部表徵和外部表徵。但是,由於 Numpy 數組的使用非常普遍,尤其是當數據加載源不同時,我們確實需要在 Numpy 和 PyTorch 張量之間做轉換。正由於此,PyTorch 給出了兩個方法(from_numpy() 和 numpy()),從而把 Numpy 數組轉化爲 PyTorch 數組,反之亦然。如果我們查看把 Numpy 數組轉化爲 PyTorch 張量的調用代碼,就可以獲得有關 PyTorch 內部表徵的更多洞見:
at::Tensor tensor_from_numpy(PyObject* obj) { if (!PyArray_Check(obj)) { throw TypeError("expected np.ndarray (got %s)", Py_TYPE(obj)->tp_name); } auto array = (PyArrayObject*)obj; int ndim = PyArray_NDIM(array); auto sizes = to_aten_shape(ndim, PyArray_DIMS(array)); auto strides = to_aten_shape(ndim, PyArray_STRIDES(array)); // NumPy strides use bytes. Torch strides use element counts. auto element_size_in_bytes = PyArray_ITEMSIZE(array); for (auto& stride : strides) { stride /= element_size_in_bytes; } // (...) - omitted for brevity void* data_ptr = PyArray_DATA(array); auto& type = CPU(dtype_to_aten(PyArray_TYPE(array))); Py_INCREF(obj); return type.tensorFromBlob(data_ptr, sizes, strides, [obj](void* data) { AutoGIL gil; Py_DECREF(obj); });}代碼摘自(tensor_numpy.cpp:https://github.com/pytorch/pytorch/blob/master/torch/csrc/utils/tensor_numpy.cpp#L88)
正如你在這段代碼中看到的,PyTorch 從 Numpy 表徵中獲取所有信息(數組元數據),並創建自己的張量。但是,正如你從被標註的第 18 行所看到的,PyTorch 保留一個指向內部 Numpy 數組原始數據的指針,而不是複製它。這意味着 PyTorch 將擁有這一數據,並與 Numpy 數組對象共享同一內存區域。
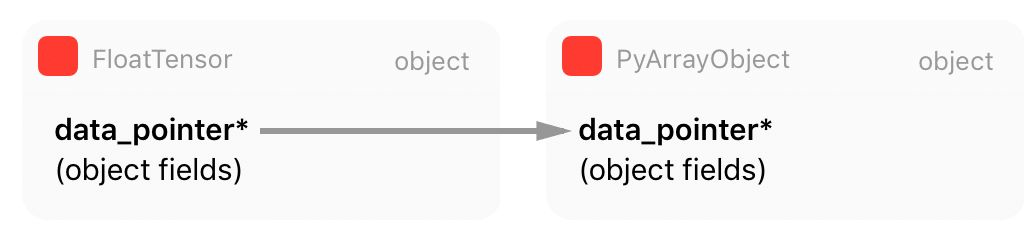
還有一點很重要:當 Numpy 數組對象越出範圍並獲得零引用(zero reference)計數,它將被當作垃圾回收並銷燬,這就是爲什麼 Numpy 數組對象的引用計數在第 20 行有增加。該行之後,PyTorch 將從這一 Numpy 數據 blob 中創建一個新的張量對象,並且在創建這一新張量的過程中,PyTorch 將會傳遞內存數據指針,連同內存大小、步幅以及稍後張量存儲將會使用的函數(我們將會在下節討論),從而通過減少 Numpy 數組對象的引用計數並使 Python 關心這一對象內存管理而釋放數據。
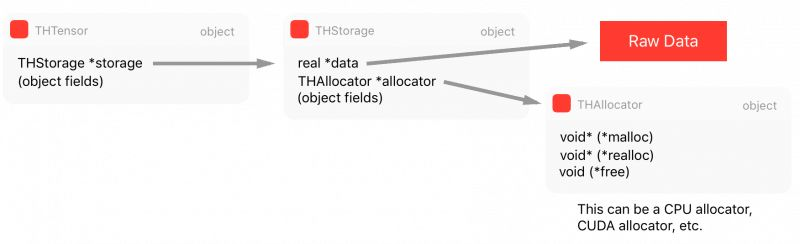
tensorFromBlob() 方法將創建一個新張量,但只有在爲這一張量創建一個新「存儲」之後。存儲是指存儲數據指針的地方,它並不在張量結構內部。張量存儲正是我們下一節要討論的內容。
張量存儲
張量的實際原始數據並不是立即保存在張量結構中,而是保存在我們稱之爲「存儲(Storage)」的地方,它是張量結構的一部分。
正如我們前面在 tensor_from_numpy() 中看到的代碼,它調用了 tensorFromBlob() 函數以從原始數據 Blob 中創建一個張量。tensorFromBlob() 函數在內部會調用另一個名爲 storageFromBlob() 函數,該函數主要根據類型爲數據創建一個存儲。例如在 CPU 浮點型的情況下,它會返回一個新的 CPUFloatStorage 實例。
CPUFloatStorage 基本上是包含 utility 函數的包裝類(wrapper),且實際存儲結構如下所示稱爲 THFloatStorage:
typedef struct THStorage{ real *data; ptrdiff_t size; int refcount; char flag; THAllocator *allocator; void *allocatorContext; struct THStorage *view;} THStorage;如上所示,THStorage 有一個指向原始數據、原始數據大小、flags 和 allocator 的指針,我們會在後面詳細地討論它們。值得注意的是,THStorage 不包含如何解釋內部數據的元數據,這是因爲存儲對保存的內容「無處理信息的能力」,只有張量才知道如何「查看」數據
因此,你可能已經意識到多個張量可以指向相同的存儲,而僅僅對數據採用不同的解析。這也就是爲什麼我們以不同的形狀或維度,查看相同元素數量的張量會有很高的效率。下面的 Python 代碼表明,在改變張量的形狀後,存儲中的數據指針將得到共享。
>>> tensor_a = torch.ones((3, 3))>>> tensor_b = tensor_a.view(9)>>> tensor_a.storage().data_ptr() == tensor_b.storage().data_ptr()True如 THFloatStorage 結構中的第七行代碼所示,它有一個指向 THAllocator 結構的指針。它因爲給分配器(allocator)帶來靈活性而顯得十分重要,其中 allocator 可以用來分配存儲數據。
typedef struct THAllocator{ void* (*malloc)(void*, ptrdiff_t); void* (*realloc)(void*, void*, ptrdiff_t); void (*free)(void*, void*);} THAllocator;代碼摘自(THAllocator.h:https://github.com/pytorch/pytorch/blob/master/aten/src/TH/THAllocator.h#L16)
如上所述,該結構有三個函數指針字段來定義分配器的意義:malloc、realloc 和 free。對於分配給 CPU 的內存,這些函數當然與傳統的 malloc/realloc/free POSIX 函數相關。然而當我們希望分配存儲給 GPU,我們最終會使用如 cudaMallocHost() 那樣的 CUDA 分配器,我們可以在下面的 THCudaHostAllocator malloc 函數中看到這一點。
static void *THCudaHostAllocator_malloc(void* ctx, ptrdiff_t size) { void* ptr; if (size < 0) THError("Invalid memory size: %ld", size); if (size == 0) return NULL; THCudaCheck(cudaMallocHost(&ptr, size)); return ptr;}代碼摘自(THCAllocator.c:https://github.com/pytorch/pytorch/blob/master/aten/src/THC/THCAllocator.c#L3)
如上所示,分配器調用了一個 cudaMallocHost() 函數。你可能已經注意到版本庫組織中有縮寫的表示模式,在瀏覽版本庫時記住這些約定非常重要,它們在 PyTorch README 文件中有所總結:
TH = TorcH
THC = TorcH Cuda
THCS = TorcH Cuda Sparse
THCUNN = TorcH CUda Neural Network
THD = TorcH Distributed
THNN = TorcH Neural Network
THS = TorcH Sparse
該約定同樣存在於函數/類別名和其它對象中,因此瞭解它們十分重要。你可以在 TH 代碼中找到 CPU 分配器,在 THC 代碼中找到 CUDA 分配器。最後,我們可以看到主張量 THTensor 結構的組成:
typedef struct THTensor{ int64_t *size; int64_t *stride; int nDimension; THStorage *storage; ptrdiff_t storageOffset; int refcount; char flag;} THTensor;如上,THTensor 的主要結構爲張量數據保留了 size/strides/dimensions/offsets/等,同時還有存儲 THStorage。我們可以將所有這些結構總結爲以下圖表:
現在,如果我們有多重處理的需求,且希望在多個不同的進程中共享張量數據,那麼我們需要一個共享內存的方法。否則每次另一個進程需要張量或我們希望實現 Hogwild 訓練過程以將所有不同的進程寫入相同的內存區域時,我們就需要在進程間創建副本,這是非常低效的。因此,我們將在下一節討論共享內存的特定存儲方法。
共享內存
共享內存可以用很多種不同的方法實現(依賴於支持的平臺)。PyTorch 支持部分方法,但爲了簡單起見,我將討論在 MacOS 上使用 CPU(而不是 GPU)的情況。由於 PyTorch 支持多種共享內存的方法,由於代碼中包含很多級的間接性,這部分會有點困難。
PyTorch 爲 Python multiprocessing 模塊提供了一個封裝器,可以從 torch.multiprocessing 導入。他們對該封裝器中的實現做出了一些變動,以確保每當一個 Tensor 被放在隊列上或和其它進程共享時,PyTorch 可以確保僅有一個句柄的共享內存會被共享,而不會共享 Tensor 的完整新副本。現在,很多人都不知道 PyTorch 中的 Tensor 方法是 share_memory_(),然而,該函數正好可以觸發那個特定 Tensor 的保存內存的完整重建。該方法的執行過程是創建共享內存的一個區域,其可以在不同的進程中使用。最終,該函數可以調用以下的函數:
static THStorage* THPStorage_(newFilenameStorage)(ptrdiff_t size){ int flags = TH_ALLOCATOR_MAPPED_SHAREDMEM | TH_ALLOCATOR_MAPPED_EXCLUSIVE; std::string handle = THPStorage_(__newHandle)(); auto ctx = libshm_context_new(NULL, handle.c_str(), flags); return THStorage_(newWithAllocator)(size, &THManagedSharedAllocator, (void*)ctx);}如上所示,該函數使用了一個特殊的分類器 THManagedSharedAllocator 來創建另一個存儲。它首先定義了一些 flags,然後創建了一個格式爲 /torch_ [process id] _ [random number] 的字符串句柄,最後在使用特殊的 THManagedSharedAllocator 創建新的存儲。該分配器有一個指向 PyTorch 內部庫 libshm 的函數指針,它將實現名爲 Unix Domain Socket 的通信以共享特定 quyu 的內存句柄。這種分配器實際上是「smart allocator」的特例,因爲它包含通信控制邏輯單元,並使用了另一個稱之爲 THRefcountedMapAllocator 的分配器,它將創建市級共享內存區域並調用 mmp() 以將該區域映射到進程虛擬地址空間。
現在我們可以通過手動交換共享內存句柄而將分配給另一個進程的張量分配給一個進程,如下爲 Python 示例:
>>> import torch>>> tensor_a = torch.ones((5, 5))>>> tensor_a 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1[torch.FloatTensor of size 5x5]>>> tensor_a.is_shared()False>>> tensor_a = tensor_a.share_memory_()>>> tensor_a.is_shared()True>>> tensor_a_storage = tensor_a.storage()>>> tensor_a_storage._share_filename_()(b'/var/tmp/tmp.0.yowqlr', b'/torch_31258_1218748506', 25)在這段代碼中,執行進程 A,我們就創建了一個 5×5,被 1 所填充的張量。在此之後,我們將其共享,並打印 Unix Domain Socket 地址和句柄的元組。現在我們可以從另一個進程 B 中接入這一內存區域了:
進程 B 執行代碼:
>>> import torch>>> tensor_a = torch.Tensor()>>> tuple_info = (b'/var/tmp/tmp.0.yowqlr', b'/torch_31258_1218748506', 25)>>> storage = torch.Storage._new_shared_filename(*tuple_info)>>> tensor_a = torch.Tensor(storage).view((5, 5)) 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1[torch.FloatTensor of size 5x5]如你所見,使用 Unix Domain Socket 地址和句柄的元組信息,我們可以接入另一個進程的張量存儲內容。如果你在進程 B 改變張量,你會看到改動也會反映在進程 A 中,因爲張量之間共享着同樣的存儲區域。
DLPack:深度學習框架 Babel 的希望
現在讓我們來看看 PyTorch 代碼庫最新的一些內容——DLPack(https://github.com/dmlc/dlpack)。DLPack 是一個內存張量結構的開放標準,允許張量數據在框架之間交換。非常有趣的是,這種內存表示是標準化的——與大多數框架已經在使用的內存表示方法非常類似,這就允許我們可以在框架之間共享,且完全無需複製數據。鑑於目前我們還沒有內部通信的工具,DLPack 是一個非常了不起的創造。
它無疑會幫助我們解決今天存在於 MXNet、PyTorch 等框架上「孤島」一樣的張量表示,並允許開發者在多個深度學習框架之間自由操作,享受標準化爲框架帶來的優勢。
DLPack 的核心結構 DLTensor 非常簡單,如下所示:
/*! * \brief Plain C Tensor object, does not manage memory. */typedef struct { /*! * \brief The opaque data pointer points to the allocated data. * This will be CUDA device pointer or cl_mem handle in OpenCL. * This pointer is always aligns to 256 bytes as in CUDA. */ void* data; /*! \brief The device context of the tensor */ DLContext ctx; /*! \brief Number of dimensions */ int ndim; /*! \brief The data type of the pointer*/ DLDataType dtype; /*! \brief The shape of the tensor */ int64_t* shape; /*! * \brief strides of the tensor, * can be NULL, indicating tensor is compact. */ int64_t* strides; /*! \brief The offset in bytes to the beginning pointer to data */ uint64_t byte_offset;} DLTensor;代碼來自 https://github.com/dmlc/dlpack/blob/master/include/dlpack/dlpack.h
如你所見,這裏有一個未加工數據的數據指針,以及形態/步幅/偏移/GPU 或 CPU,以及其他 DLTensor 指向的元信息。
這裏還有一個被稱爲 DLManagedTensor 的受管理版本,其中框架可以提供一個環境,以及「刪除」函數,後者可以從借用張量來通知其他框架不再需要資源。
在 PyTorch 中,如果你想要轉換到 DLTensor 格式,或從 DLTensor 格式轉換,你可以找到 C/C++的方法,甚至 Python 方法來做這件事:
import torchfrom torch.utils import dlpackt = torch.ones((5, 5))dl = dlpack.to_dlpack(t)這個 Python 函數會從 ATen 調用 toDLPack 函數,如下所示:
DLManagedTensor* toDLPack(const Tensor& src) { ATenDLMTensor * atDLMTensor(new ATenDLMTensor); atDLMTensor->handle = src; atDLMTensor->tensor.manager_ctx = atDLMTensor; atDLMTensor->tensor.deleter = &deleter; atDLMTensor->tensor.dl_tensor.data = src.data_ptr(); int64_t device_id = 0; if (src.type().is_cuda()) { device_id = src.get_device(); } atDLMTensor->tensor.dl_tensor.ctx = getDLContext(src.type(), device_id); atDLMTensor->tensor.dl_tensor.ndim = src.dim(); atDLMTensor->tensor.dl_tensor.dtype = getDLDataType(src.type()); atDLMTensor->tensor.dl_tensor.shape = const_cast
(src.sizes().data()); atDLMTensor->tensor.dl_tensor.strides = const_cast
(src.strides().data()); atDLMTensor->tensor.dl_tensor.byte_offset = 0; return &(atDLMTensor->tensor);}
如上所示,這是一個非常簡單的轉換,它可以將元數據的 PyTorch 格式轉換爲 DLPack 格式,並將指針指向內部張量的數據表示。
我們都希望更多的深度學習框架可以學習這種標準,這會讓整個生態系統受益。希望本文能夠對你有所幫助。
原文鏈接:http://blog.christianperone.com/2018/03/pytorch-internal-architecture-tour/