機器之心原創
作者:邱陸陸
10 月10日,中科視拓對外公佈,獲得安賜資本領投的數千萬元 pre-A 輪融資。這是去年秋天中科視拓宣佈成立,並獲得線性資本領投的千萬級天使輪融資後,首次公開融資消息。
去年初秋,中科院人臉識別專業研究員山世光攜千萬級天使融資創業的消息引發了人工智能領域內一次不小的震動,如今整整一年過去了,人臉識別領域繁盛如烈火烹油,而中科視拓這家靜水深流的公司卻並未給我們太多機會得以一窺其廬山真面目。9 月,機器之心來到中科視拓,與「學者山世光」聊了聊人臉識別學界 20 年裏走過的萬水千山和仍需努力的未竟革命,與「企業家山世光」談了談人臉識別在業界裏能做的、要做的、想做的事,他的新身份帶來的新視角,以及他通過賦能推動 AI 邊界拓展的新計劃。
以下爲採訪實錄:
人臉識別領域的「激盪 20 年」
我從 97 年做本科畢業設計的時候就開始做人臉識別,概括下來,這 20 年裏人臉識別領域經歷了幾次小起伏和一次大起伏。
如果從歷史的角度看,94 年到 97 年其實是一個人臉識別的小高潮。美國的國家標準與技術研究院(NIST)在 1994-1995 年的時候舉辦了一個競賽,叫 FERET(Face Recognition Technology),並且建了一個包含一千一百多人,數千張照片的人臉數據庫。雖然現在看來這個數據庫規模很小,但是在當時已經是很大的數據了。當時有一些美國的知名高校,比如 CMU、UMD、哥大,在 94、95 年參加競賽,取得了一些進步,然後在 97 年的時候發表了一些文章。其中有一篇發表在 PAMI 上面的,叫做 Fisherface [1],可能現在還是自 91 年的 Eigenface [2] 以來,整個人臉識別領域引用最高的文章之一。Fisher 代表的是費舍爾線性判別分析(Fisher Discriminative Analysis)算法,對輸入圖像 X 用 W 做線性變換 Y = WX,將其降維映射到另一個空間得到向量 Y,而問題的核心在於如何找到合適的 W。97 年 Fisherface 這篇文章採用了線性判別分析方法,簡單來說就是找一個空間,在這個空間裏同一個人的照片儘可能聚集在一起,不同人的照片儘可能遠離。這就是就是費舍爾判別準則:把同一個人的照片間距離稱爲類內距離,不同人的稱爲類間距離,判別函數試圖讓類內距離儘可能小,類間距離儘可能大。而 Fisherface 就基於這樣一個準則去尋找 W,做線性變換。這個工作的影響非常深遠,一直到 2010 年前後,很多人臉識別方法都還是在以這個準則爲目標來尋求所謂最優的變換。
90 年代的小高峯過去之後,2002 年到 2004 年還有一些非常重要的工作,在對圖像進行線性變換前先對它做特徵提取。其中影響力最大的是 Gabor 小波變換 [3] 和 LBP(Local Binary Patterns)[4]。其中,Gabor 小波其實是一個加窗的傅里葉變換。我們把原圖用 Gabor 濾波器函數進行處理,處理後維度可能比原圖更高,例如,用了 40 個 Gabor 小波濾波器的話,維度會變成原圖的 40 倍,我們在此基礎上再去求 W,一方面 W 可以把特徵維度降低,另一方面還是通過 W 實現類似 Fisher 的目標。
Gabor 小波變換是很早就有的方法,但是這個工作的意義體現在和後來的深度學習有密切的關係。Gabor 小波濾波器的參數,或者說權重,是通過 Gabor 小波人爲定義出來的。深度學習的底層其實也是一些濾波器,它和傳統方法的不同就是參數不是人爲定出來而是通過數據學習出來的。而二者的聯繫在於,通過學習得來的底層濾波器非常像 Gabor 小波濾波器或者高斯導數濾波器。尤其是在一個不是特別深的卷積神經網絡裏,前面幾層,尤其是第一層的濾波器會非常像人爲定義出來的濾波器。這並不是一個偶然現象,其中是存在必然聯繫的,我們可以認爲二者都是在試圖提取一些特定朝向的邊緣特徵。除了與深度學習的聯繫之外,這個工作在性能上也較 Fisherface 有了大幅度的提高。
後來大家普遍覺得,尋求一個把不同人分得很開的低維空間這樣一個非常複雜的目標可能不是一個簡單的線性變換能夠解決的。畢竟我們要把圖像從非常高維的空間映射到非常低維的空間,同時又希望獲得好的判別能力。所以大家想方設法地去找一些非線性的變換。我們實驗室在 2007 年發過一篇 ICCV 的工作 [5],是在 Gabor 小波濾波器的基礎上做分段線性來逼近一個可能非常複雜的非線性函數。這個工作後來也申請了專利,並授權給合作伙伴銀晨做了大量的應用。這些應用包括國家出入境管理局的基於數億護照照片的人臉識別系統,以及全國十餘個省的省廳級大庫人員比對系統。這也是人臉識別的在國內第一波成功應用,解決的是一個人有多個戶口或護照的「多重身份問題」,這些系統最多在一個省內就識別出數以萬計的有多重身份的人,其中不乏洗白了身份的在逃人員。
除了分段線性外,另一種常見方法是用 Kernel 技巧做非線性的特徵提取。此外,2000 年《科學》雜誌上的兩篇文章,Isomap [6] 和 LLE [7],引領了流形學習這個領域的進展。因此 2000 年前後,特別是 03、04 年的時候,國內和國際上很多人開始做流形學習。流形學習試圖找一個非線性的變換,得到一個好的空間,能夠把類內聚集,類間分開這個目標實現得更好,本質上也是想解決非線性問題。
2009 年有一個稍顯曇花一現的方法是稀疏表示。它本質上還是一個線性模型,只不過沒有添加 L2 正則項,而是添加了 L1 或者 L0 的。我們傾向於認爲它在信號處理等底層視覺處理上是有用的,但在人臉這樣高層任務的處理上,不解決特徵提取這個最根本問題。
2012 年左右,ImageNet 的巨大成功直接把深度學習帶到了人臉識別領域。從 2013 年開始,人臉識別的所有技術非常迅速地切換到了深度學習上。深度學習的核心就是特徵學習,換句話說,就是不再人爲定義 Y = WX 形式的特徵,而是交給數據去學習一個通過神經網絡實現的 Y=f(X) 形式的變換。
深度學習有幾個非常重要的特徵:第一是非線性,並且和 Kernel 方法相比,是一個顯式的非線性。Kernel 方法是通過在原始空間中進行 Kernel 函數計算逼近目標空間中的兩個輸入的點積,但由於 Kernel 函數的種類非常有限,所以不一定能找到適合特定問題的 Kernel 函數。第二是逐層抽象,這非常符合過去研究者一直期望找到的特徵提取方式:從底層的邊緣、角、點這樣的基礎特徵,到圓、橢圓這樣的稍微複雜的模式,再到眼睛、鼻子、嘴這樣的部件,到臉型、是否帶眼鏡等屬性,最後是性別、身份、表情等高級屬性。這樣的特徵提取方式非常符合人在認知方面的需求。第三是技術上解決了多層特徵提取問題,原來人爲設計濾波器的時候做不了很多層。比如在一層 Gabor 小波濾波器的基礎上再做一層 Gabor 小波濾波器的話,我們已經不知道是什麼意思了。LBP、SIFT [8]、HOG 等方法嘗試在濾波器的基礎上做直方圖的表達,然而再往上抽象,就又遇到瓶頸了。
我認爲深度學習給人臉識別領域帶來了一次跨越式的發展。舉個例子,在 12 年甚至 13 年的時候,研究者還普遍認爲,基於二代身份證的人證比對是一個不可能完成的任務。它的難度太大了:身份證的照片可能是多年以前差別很大的舊照,大小又只有 102×126,而且被從 30k 左右強制壓縮到了 1k,損失了非常多信息。但是現在我們已經可以做到,在人配合地去看鏡頭的時候,做到 0.01% 的誤識率(false accept rate)的情況下,有 98% 以上的識別率(Recognition rate)。也就是說一萬個人冒充你,只有一個人能成功的條件下,自己本人被正確識別的概率在 98% 以上。在 13 年之前,萬分之一精度可能只有 20% 不到的召回率。
圖像識別「問題解決」目標尚遠
如今,雖然 ImageNet 競賽已經結束了,但是圖像識別問題還遠遠沒有解決。如果我們寄希望於用深度學習解決圖像識別問題,就意味着我們要收集所有待識別物體的大量有標註數據。這件事情需要多少人力、物力、時間是不可知的,我們甚至無法定義這個世界上有多少需要識別的物體種類。ImageNet 中有一千類,然而日常生活中需要識別的物體至少在萬類規模,大千世界裏出現過的物體可能有百萬類甚至更多。另外,實際應用中的大量需求是難以想象的,例如對車輛安檢需求,可能需要拍車底部的照片。這樣的問題是否只能通過採集大量數據來解決,還要打一個大大的問號,而且對於做科學技術的人來說,這個過程非常痛苦,不是一個「優雅」的解決辦法。
我們期望有一個像人一樣解決問題的辦法。以讓小區裏的巡邏機器人學會檢測狗屎爲例:

在前深度學習時代,這個過程大概分三步:第一步,花幾個月時間收集和標註幾百或上千張圖;第二步,觀察並人爲設計形狀、顏色、紋理等特徵;第三步,嘗試各種分類器做測試,如果測試結果不好,返回第二步不斷地迭代。人臉檢測就是這樣進行的,從上世紀八十年代開始做,大量研究者花了大概二十年時間,纔得到了一個基本可用的模型,能較好地解決人臉檢測的問題。而後在監控場景下做行人和車輛的檢測,前後也花了大概十年的時間。就算基於這些經驗,做出好用的狗屎檢測器,至少還是需要一年左右的時間。

在深度學習時代,開發一個狗屎檢測器的流程被大大縮短了。儘管深度學習需要收集大量的數據並進行標註(用矩形把圖中的狗屎位置框出來),但由於衆包平臺的繁榮,收集一萬張左右的數據可能只需要兩星期。接下來,我們只需要挑幾個已經被證明有效的深度學習模型進行優化訓練就可以了,訓練優化大概需要一個星期,就算換幾個模型再試試看。這樣完成整個過程只需要一兩個月而已。而在後深度學習時代,我們期待先花幾分鐘時間,在網上隨便收集幾張狗屎照片,交給機器去完成餘下所有的模型選擇與優化工作,或許最終只需要一、兩星期解決這個問題。

總之,我們認爲,圖像識別,或是說計算機視覺問題,應該有不依靠大數據的、更優雅的解決方案。我們的團隊現在也作了一些這方面的嘗試。例如以大量數據學習出來的人臉識別的模型爲基礎,使用少量數據精調,來完成表情識別、年齡估計等任務,這樣得到的技術甚至贏得了國際競賽的冠軍或亞軍。此外,在數據有限的情況下,我們還嘗試了在深度學習過程中融入人類專家知識,以減少對數據量的需求。我們的一種策略是把神經網絡中需要大量數據進行優化的低層連接權重,替換成人爲定義的特徵,例如傳統的 Gabor 特徵,從而減少對大數據的需求,也獲得了不錯的結果。
深度學習的端到端思想對人臉識別的影響
前深度學習時代的人臉識別的標準流程裏,第一步是人臉檢測,其結果就是在圖片中的臉部區域打一個矩形框。第二步是尋找眼睛、鼻子、嘴等特徵點,目的是把臉對齊,也就是把眼鼻嘴放在近乎相同的位置,好像所有的臉都能「串成一串」一樣,且只保留臉的中心區域,甚至連頭髮不要。第三步是光照的預處理,通過高斯平滑、直方圖均衡化等來進行亮度調節、偏光糾正等。第四步是做 Y= f(X) 的變換。第五步,是計算兩張照片得到的 Y 的相似程度,如果超過特定的閾值,就認定是同一個人。
深度學習的到來對整個流程有一個巨大的衝擊。
一開始,研究者用深度學習完成人臉檢測、特徵點定位、預處理、特徵提取和識別等每個獨立的步驟。而後首先被砍掉的是預處理,我們發現這個步驟是完全不必要的。理論上來解釋,深度學習學出來的底層濾波器本身就可以完成光照的預處理,而且這個預處理是以「識別更準確」爲目標進行的,而不是像原來的預處理一樣,以「讓人看得更清楚」爲目標。人的知識和機器的知識其實是有衝突的,人類覺得好的知識不一定對機器識別有利。
而最近的一些工作,包括我們在今年 ICCV 上的一個工作 [9],就是把第二步特徵點定位砍掉。因爲神經網絡也可以進行對齊變換,所以我們的工作通過空間變換(spatial transform),將圖片自動按需進行矯正。並且我有一個猜測:傳統的刻意把非正面照片轉成正面照片的做法,也未必是有利於識別的。因爲一個觀察結果是,同一個人的兩張正面照相似度可能小於一張正面、一張稍微轉向的照片的相似度。最終,我們希望進行以識別爲目標的對齊(recognition oriented alignment)。
在未來,或許檢測和識別也可能合二爲一。現在的檢測是對一個通用的人臉的檢測,未來或許可以實現檢測和識別全部端到端完成:只有特定的某個人臉出現,纔會觸發檢測框出現。
第五步的相似度(或距離測度)的計算方法存在一定的爭議。我認爲特徵提取的過程已經通過損失函數暗含了距離測度的計算,所以深度特徵提取與深度測度學習有一定的等價性。但也有不少學者在研究特徵之間距離測度的學習,乃至於省略掉特徵提取,直接學習輸入兩張人臉圖片時的距離測度。
總體來說,深度學習的引入體現了端到端、數據驅動的思想:儘可能少地對流程進行干預、儘可能少地做人爲假設。
當然,這一切的前提是大數據,否則還是需要人的知識嵌入。從進化的角度,人腦在出生時就是一個歷代祖先大數據學習的結果。而人的個體的後天發育是通過觀察得到的小數據和教育給予的知識對大腦進行適應性修改的過程。將現在的人工智能與人類進行對比,就能發現人工智能是專科智能而非全科智能,而且專科智能還太依賴大數據。我們可以認爲深度學習其實只是歸納法的勝利,而人的學習還有很大一部分是基於演繹推理。因此,我認爲在未來,會出現知識與數據聯合驅動的方法,但這面臨着一個非常大的挑戰,即機器知識和人類知識在表示上的鴻溝的彌合。人的知識表達在書本上,機器的知識蘊含在神經網絡裏,現在二者沒有辦法對應,更不能互相轉化。這是未來非常值得去研究的一件事情。
從服務到賦能,從技術到應用場景,不同視角下的 Seeta 業務版圖
中科視拓的業務類型可以按照與客戶合作的形式和應用的場景兩種方式進行分類。
按照與客戶合作的形式上,主要有四種:
一種是以提供 SDK 做技術服務的方式。客戶購買 SDK,我們協助他們嵌入到產品裏面去,這類客戶大約有十餘家。
另一種是深度授權與深度定製,與華爲、平安、中國移動的合作都屬於這一類。我們面向一些標杆客戶提供非常開放的源碼級的合作,甚至在這個過程中,我們也非常願意幫助客戶去提升自身團隊的深度學習研發能力。
第三種,我們自己也在做 C 端產品和集成系統的開發。我們委託第三方開發硬件,搭載視拓的算法,開發出 1:1 人證驗證一體機用於實名驗證需求,開發出 1:N 人臉識別閘機等,可以給數千人規模的樓宇或單位做無卡的刷臉門禁或閘機,預期可以全面取代傳統的刷卡門禁或閘機系統。
最後一種,也是我們正在推進的賦能型產品服務,Seeta Training As a Service,簡稱 SeeTaaS。我們的終極目標是做一個平臺,底層有私有云或公有云形式的雲端計算能力,上層有一套 SeeTaaS 軟件,軟硬件結合成一個黑盒子。用戶將自己的數據給黑盒子做自動優化,包括模型自動選擇、模型超參數和參數的自動優化,一段時間後得到完成的結果。我們已經做了初步的工作,通過這種方式對一些有嚴格保密要求的用戶,例如航天和軍工用戶進行賦能。最終,我們希望達到的目標是,對不具備 AI 開發能力的公司進行賦能,希望在五年之後,我們的系統是一個不懂深度學習的中學生都可以通過簡單的設置來使用的系統。而這個系統在處理過足夠多數據的時候,可以像研究者一樣積累經驗,能夠針對一批特定數據去進行分析,對可能的最優模型、超參數和參數、可能的優化方法與優化路徑等進行推測和優化。
這個系統旨在填補 AI 人才與社會對 AI 技術需求之間的缺口。儘管 AI 人才的數量在增加,但這個速度和各行各業對特定領域的 AI 技術需求的增速還是不可相比的。很多傳統行業企業都具有數據蒐集的能力,因此我們的理想是,通過這個系統快速地開發出越來越多的 AI 引擎,由此使得整個社會裏各行各業的智能化的水平得到很快的提升。我堅信,5 到 10 年後,AI 的開發肯定是可以走進高中課程去的。
從應用角度來看,人臉識別大概有十幾種不同的應用場景,中科視拓的重點有以下幾類:
第一個是人證一致性場景,解決實名制驗證需求,識別的根基是公民身份證照片。我們和中國移動、中國電信等有實名制需求的企業合作,把客戶現場照片和身份證表面/內部的照片,或者是通過姓名和身份證號在國家的身份證號碼查驗中心獲得的照片進行比對。這是車站、碼頭、酒店、運營商、券商以及越來越多的互聯網企業都有的實名制驗證需求。這個場景下,我們實現了非常高的精度。在一萬人來冒充你只有一個人成功的情況下,基本可以做到接近百分之九十九的準確率了。這其中的技術難點是對含有水紋噪聲的身份證照片的處理。
第二個是「驗明正身」需求,更多是民用的無感門禁、考勤加上訪客系統,或者手機等私人物品的訪問系統。這是一個巨大潛在市場的場景。和第一種場景不同,這一類場景的根照片的質量比較高,可以拿到近照、清晰照片,甚至可以讓識別對象協助拍攝多角度照片乃至視頻。因此這種場景下的精度更高,可以做到萬人規模的單位,98% 的人次可以一次通過。
而且系統會進行適應性調整,就從一個生人系統變成一個熟人系統,會越用越好。這個系統的侷限性是閘機系統還是以室內應用爲主,在室外情況下受到陽光干擾會出現難以識別的情景。
第三個是泛安防領域的會議簽到系統或者訪客系統等,這是一類 1:N 問題,特殊性在於提交的照片通常不是證件照而是生活照。
上述幾類都是配合用戶,難度增加一層的應用場景是用戶不會刻意配合的常客或白名單系統,例如在智慧商業領域,人臉識別技術也在快速切入。我們中科視拓正在和某無人零售商店合作開發面向無人商店的人臉識別系統。當然,最難的應用場景還是警用安全防範領域,這類應用因爲識別對象可能進行刻意僞裝而難度大增,但得益於數據獲取機會的增多,人臉識別技術也在非常快速地進入這個市場,公安部門已經取得了不少戰果。我們也和公安部門合作,開發了針對萬人級別的黑名單庫的人臉識別系統,這個場景的特殊性是需要控制虛警率儘可能的低,同時還要保證足夠高的召回率。
其他外圍的應用還包括情感計算,換言之,就是「察言觀色」,通過眨眼次數、心跳次數、眼神集中度、七種基本表情和十幾個面部肌肉運動單元的動作捕捉,做情緒指標估計。例如,用心跳次數估計做緊張指標。這類應用可以用於輔助金融機構的風控工作,代替業務員來對客戶的風險性進行判斷,解決業務員能力參差不齊的問題。也可以用於面試、教學效果評估、疲勞駕駛預防等場景。
從「學者山世光」到「企業家山世光」的這一年
中科視拓成立一年了,對於業界和學界的異同,還是有特別深的體會。相似的地方是,做學術和做企業對於價值的判斷還是很相似的。一個學術工作的價值體現在別人沒有做過或者做得不好,這在企業裏也是非常類似的,物以稀爲貴,而不是能做就有價值。因此我們在選擇市場的過程中,除了在做較多人能做的事之外,也一直在探索有自己特色的東西,這種思路來源於我們從學術界帶來的「求新求異」的思維模式。作爲一家科技公司,比起商業方面的突出,我們有更大意願在技術上做到和別人不一樣。
而不同的地方在於,商業價值的體現不是一個純粹的技術問題,而是如何讓市場上的用戶接受你的技術以及產品。所以從這個角度來說,企業就要反過來從用戶的需求出發。例如我們做人臉閘機這個看起來別人也能做的項目,就是因爲通過做這些項目才能夠真正地理解用戶的需求,反饋到技術上做更好的改進。雖然人臉識別看起來在快速落地,但其實還是有很多和核心技術沒有直接關係的、需要根據用戶需求設定策略的問題需要解決,而在學術界的時候,我們努力解決的問題有時候是我們想象出來的,實際應用中可能不會存在這樣的問題。
我們和中科院計算所的實驗室依然有非常緊密的聯繫,實驗室定位爲「視拓研究院」,而公司則把實驗室的算法工程化、產品化。我經常說現在的 AI 技術等於 A (Algorithm) + B (Big Data) + C (Computation Power),實驗室強調的是 A,是算法,公司會把數據和算力加進來,也會反過來爲實驗室提供數據和算力支持。
這一年,我們發現學術界和業界對數據的理解也很不一樣。工業界的勢頭很猛、對學術界的衝擊非常大。很多實驗室對數據的重視程度不夠,他們現在覺得很重要的問題其實業界已經通過數據解決了。所以學術界其實需要調整思路,把問題定義清楚,不要在算力和數據量跟不上的情況下試圖在大數據問題上挑戰工業界。現在在世界範圍內,人工智能的最強驅動力量還是 Google、Facebook 這些企業,這也是很正常的一個現象,當一個領域開始走向成熟的時候,工業界有巨大的利益驅動,學術界反而因爲需要發散的求異思考,所以看起來好像沒有相對明確的目標。但是我相信學術界在幾年之後會走出一條和工業界不一樣的路。
工業界和學術界從方法論上來講,應該有本質不同。工業界一定是數據驅動的方法論,而學術界一定要把知識加進來,把深度學習的作用「弱化」,找到可以利用小數據、髒數據、亂數據、半監督、弱監督、無監督數據的機器學習方法。我把這些數據條件稱之爲 X 數據,而支持 X 數據驅動的方法,一定要充分利用人類數千年來總結的各類知識。
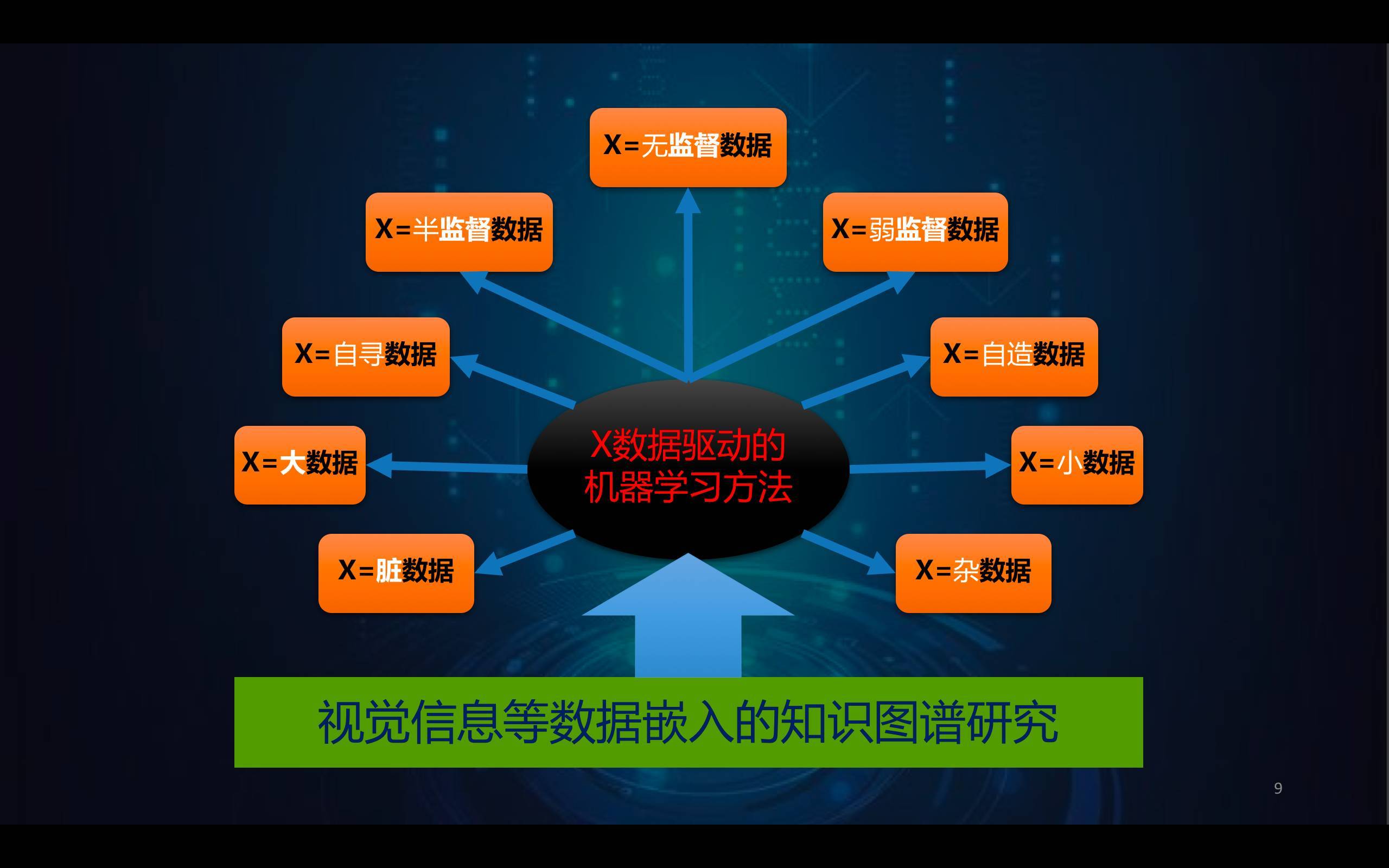
過去講「知識圖譜」是僅僅從人的角度出發,現在我認爲還應該把數據嵌入到知識圖譜裏面,通過這種方式去促進機器知識和人的知識的對應與相互利用,獲得更高效的方法。例如圖像識別領域最終的解決方案,可能是工業界和學術界一起配合,由工業界通過大數據給出萬類規模的常見物體準確識別解決方案,而餘下的大量不常見的物體識別問題,就需要學術界給出小樣本解決方案了。
總而言之,現在學術界最大的任務應該是要把深度學習「搞掉」,而工業界要做的就是不斷地收集數據,然後把深度學習用好,盡力向外推廣,拓展它的邊界。
公司大事記
2016 年 8 月,公司成立,獲得天使投資
2016 年年底,與平安、電信等大公司達成合作
2017 年 1 月,與軍方簽署無人機視覺技術合作項目
2017 年 3 月,入選中關村前沿儲備企業
2017 年 4 月,在杭州成立控股子公司「火視科技」,專注於產品與系統集成
2017 年 5 月,與航天部門簽署人臉門禁系統合同
2017 年 6 月,門禁和考勤系統的產品正式問世
2017 年 7 月,第一版 SeeTaaS 系統開始內測
2017 年 8 月,完成 pre-A 輪投資
參考文獻
[1] Belhumeur P N, Hespanha J P, Kriegman D J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection[J]. IEEE Transactions on pattern analysis and machine intelligence, 1997, 19(7): 711-720.
[2] Turk M, Pentland A. Eigenfaces for recognition[J]. Journal of cognitive neuroscience, 1991, 3(1): 71-86.
[3] Liu C, Wechsler H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition[J]. IEEE Transactions on Image processing, 2002, 11(4): 467-476.
[4] Ahonen T, Hadid A, Pietikäinen M. Face recognition with local binary patterns[J]. Computer vision-eccv 2004, 2004: 469-481.
[5] Su Y, Shan S, Chen X, et al. Hierarchical ensemble of global and local classifiers for face recognition[J]. IEEE Transactions on Image Processing, 2009, 18(8): 1885-1896.
[6] Tenenbaum J B, De Silva V, Langford J C. A global geometric framework for nonlinear dimensionality reduction[J]. science, 2000, 290(5500): 2319-2323.
[7] Roweis S T, Saul L K. Nonlinear dimensionality reduction by locally linear embedding[J]. science, 2000, 290(5500): 2323-2326.
[8] Lowe D G. Object recognition from local scale-invariant features[C]//Computer vision, 1999. The proceedings of the seventh IEEE international conference on. Ieee, 1999, 2: 1150-1157.
[9] Wu W, Kan M, Liu X, et al. Recursive Spatial Transformer (ReST) for Alignment-Free Face Recognition[C]. ICCV, 2017.
本文爲機器之心原創,轉載請聯繫本公衆號獲得授權。
責任編輯: