近日 GitHub 用戶 wu.zheng 開源了一個使用雙向 LSTM 構建的中文處理工具包,該工具不僅可以實現分詞、詞性標註和命名實體識別,同時還能使用用戶自定義字典加強分詞的效果。我們簡要介紹了這種雙向 LSTM,並給出了我們在 Windows 上測試該工具的結果。
中文處理工具包 GitHub 地址:https://github.com/rockyzhengwu/FoolNLTK
根據該項目所述,這個中文工具包的特點有如下幾點:
可能不是最快的開源中文分詞,但很可能是最準的開源中文分詞
基於 BiLSTM 模型訓練而成
包含分詞,詞性標註,實體識別, 都有比較高的準確率
用戶自定義詞典
在中文信息處理中,分詞(word segmentation)是一項基本技術,因爲中文的詞彙是彼此相連的,不像英文有一個天然的空格符可以分隔不同的單詞。雖然把一串漢字劃分成一個個詞對於漢語使用者來說是很簡單的事情,但對機器來說卻很有挑戰性,所以一直以來分詞都是中文信息處理領域的重要的研究問題。
如該項目所述,作者使用了雙向 LSTM 來構建整個模型,這也許是作者對分詞性能非常有信心的原因。在中文分詞上,基於神經網絡的方法,往往使用「字向量 + 雙向 LSTM + CRF」模型,利用神經網絡來學習特徵,將傳統 CRF 中的人工特徵工程量將到最低。
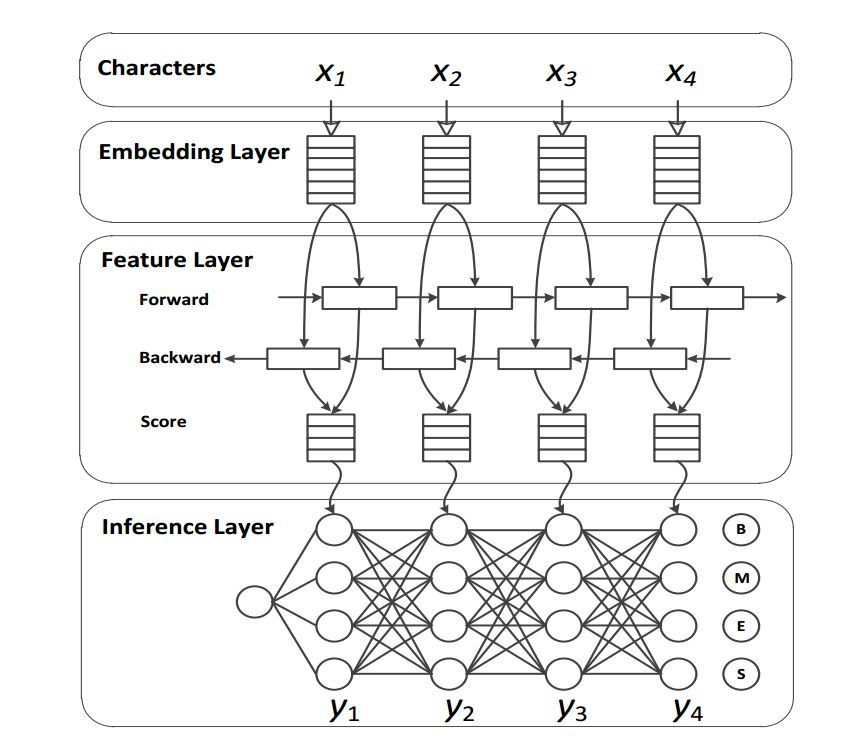
中文分詞系統的一般神經網絡架構,其中特徵層就是使用的 LSTM,來源 Xinchi Chen et al.(2017)。
除了該工具包所使用的深度方法,其實今年 ACL 的傑出論文就有一篇專門描述了分詞方法。復旦大學的陳新馳、施展、邱錫鵬和黃萱菁在 Adversarial Multi-Criteria Learning for Chinese Word Segmentation 論文中提出了一個新框架,可以利用多標準的中文分詞語料進行訓練。
因爲該工具包主要使用的是雙向 LSTM,所以我們先簡要解釋一下這種網絡再討論我們測試的分詞效果。首先顧名思義,雙向 LSTM 結合了從序列起點開始移動的 LSTM 和另一個從序列末端開始移動的 LSTM。其中正向和逆向的循環網絡都由一個個 LSTM 單元組成。以下是 LSTM 單元的詳細結構,其中 Z 爲輸入部分,Z_i、Z_o 和 Z_f 分別爲控制三個門的值,即它們會通過激活函數 f 對輸入信息進行篩選。一般激活函數可以選擇爲 Sigmoid 函數,因爲它的輸出值爲 0 到 1,即表示這三個門被打開的程度。
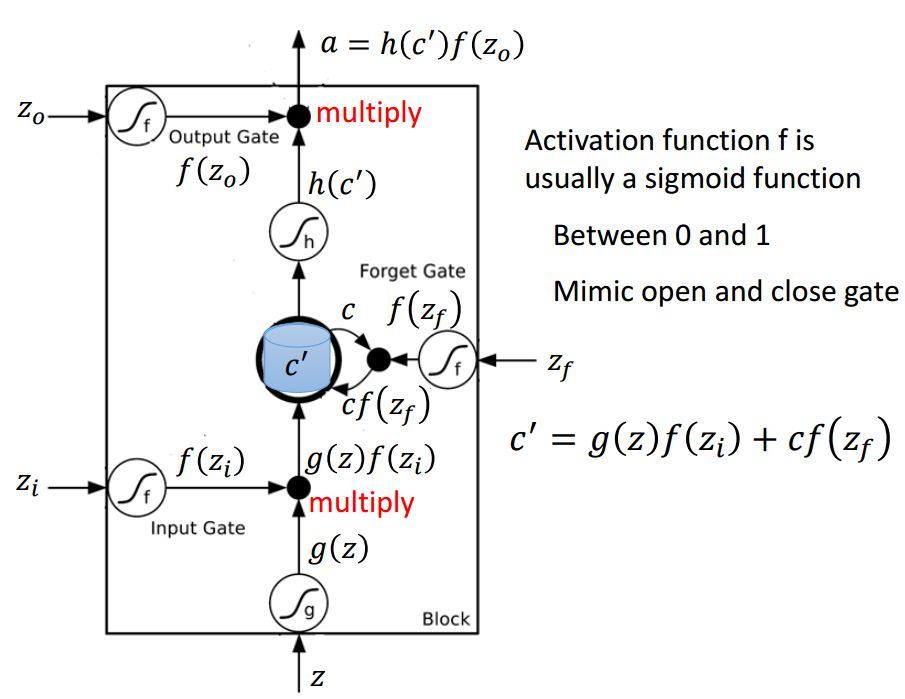
圖片來源於李弘毅機器學習講義
若我們輸入 Z,那麼該輸入向量通過激活函數得到的 g(Z) 和輸入門 f(Z_i ) 的乘積 g(Z) f(Z_i ) 就表示輸入數據經篩選後所保留的信息。Z_f 控制的遺忘門將控制以前記憶的信息到底需要保留多少,保留的記憶可以用方程 c*f(z_f)表示。以前保留的信息加上當前輸入有意義的信息將會保留至下一個 LSTM 單元,即我們可以用 c' = g(Z)f(Z_i) + cf(z_f) 表示更新的記憶,更新的記憶 c' 也表示前面與當前所保留的全部有用信息。我們再取這一更新記憶的激活值 h(c') 作爲可能的輸出,一般可以選擇 tanh 激活函數。最後剩下的就是由 Z_o 所控制的輸出門,它決定當前記憶所激活的輸出到底哪些是有用的。因此最終 LSTM 的輸出就可以表示爲 a = h(c')f(Z_o)。
若我們將這一系列 LSTM 單元組織爲如下形式,那麼它們就構成了一個 BiLSTM 網絡:
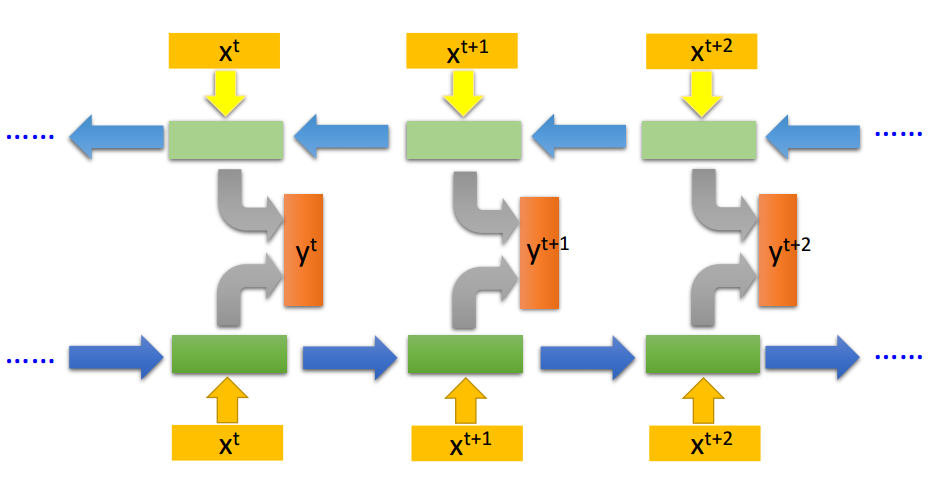
圖片來源於李弘毅機器學習講義
如上所示,我們將兩個反向讀取的 LSTM 網絡連接就成了 BiLSTM。如果我們同時訓練正向 LSTM 與逆向 LSTM,並把這兩個循環網絡的隱藏層拿出來都接入一個輸出層,那麼我們就能得到最後的輸出結果 y。使用這種 BiLSTM 的好處是模型的觀察範圍比較廣,因爲當我們只採用單向循環網絡時,在時間步 t+1 只能觀察到 x_t 以及之前的輸入數據,而不能觀察到 x_t+2 及之後的情況。而當我們使用雙向循環網絡,模型在每一個時間步都會觀察全部的輸入序列,從而決定最後的輸出。
以上是簡要的 BiLSTM 概念,我們在 Windows 10 系統、TensorFlow 1.4、Numpy 1.13.3 成功地運行了該模型。我們簡單地測試了三段文字的分詞效果,即一般的文本、專業文本和定義字典後的專業文本。我們使用 Python 自帶函數讀取 TXT 文檔並執行分詞任務,分詞後返回的數據結構是非常常見的 Python 列表,因此我們可以輕易地進行後續的處理。
對於較爲常見的文本,該工具的分詞效果確實挺好:
['本', '報告', '所', '討論', '的', '「', '人工智能', '」', '主要', '是', '指', '可以', '通過', '機器', '體現', '的', '智能', ',', '也', '叫做', '機器', '智能', '。', '在', '學術', '研究', '領域', ',', '指', '能夠', '感知', '周圍', '環境', '並', '採取', '行動', '以', '實現', '最', '優', '可能', '結果', '的', '智能體', '。', '一般而言', ',', '人工智能', '的', '長期', '目標', '是', '實現', '通用', '人工智能', ',', '這', '被', '看作', '是', '「', '強', '人工智能', '」', '。', '在', '處理', '交叉', '領域', '問題', '時', ',', 'AGI', ' ', '的', '表現', '會', '遠遠', '超過', '普通', '機器', ',', '並且', '可以', '同時', '處理', '多', '個', '任務', '。', '而', '弱', '人工智能', '無法', '解決', '之前', '未', '見過', '的', '問題', ',', '而且', '其', '能力', '僅', '侷限', '在', '特定', '領域', '內', '。', '但是', ',', '人工智能', '專家', '和', '科學家', '現在', '對', ' ', 'AGI', ' ', '的', '確切', '定義', '仍然', '含', '混', '不', '清', '。', '區別', '強', '人工智能', '和', '弱', '人工智能', '的', '常見', '方法', '是', '進行', '測試', ',', '比如', '圖靈', '測試', '、', '機器人', '大學生', '測試', '和', '就業', '測試', '。']
而對於較爲專業性的文字,該工具傾向於將其分割爲更離散的詞組:
['在', '論文', '中', ',', ' Hinton', ' ', '介紹', ' ', 'Capsule', ' ', '爲', ':', '「', 'Capsule', ' ', '是', '一', '組', '神經元', ',', '其', '輸入', '輸出', '向', '量', '表示', '特定', '實體', '類型', '的', '實例化', '參數', '(', '即', '特定', '物體', '、', '概念', '實體', '等', '出現', '的', '概率', '與', '某些', '屬性', ')', '。', '我們', '使用', '輸入', '輸出', '向', '量', '的', '長度', '表徵', '實體', '存在', '的', '概率', ',', '向', '量', '的', '方向', '表示', '實例化', '參數', '(', '即', '實體', '的', '某些', '圖形', '屬性', ')', '。', '同一', '層級', '的', ' ', 'capsule', ' ', '通過', '變換', '矩陣', '對', '更', '高', '級別', '的', ' ', 'capsule', ' ', '的', '實例化', '參數', '進行', '預測', '。', '當', '多', '個', '預測', '一致', '時', '(', '本', '論文', '使用', '動態', '路', '由', '使', '預測', '一致', ')', ',', '更', '高', '級別', '的', ' ', 'capsule', ' ', '將', '變', '得', '活躍', '。', '」']
但是我們可以將專業詞彙添加到詞典而加強分詞的效果,如下所示爲添加了字典後的分詞:
['在', '論文', '中', ','Hinton', ' ', '介紹', ' ', 'Capsule', ' ', '爲', ':', '「', 'Capsule', ' ', '是', '一組', '神經元', ',', '其', '輸入輸出向量', '表示', '特定', '實體類型', '的', '實例化參數', '(', '即', '特定', '物體', '、', '概念', '實體', '等', '出現', '的', '概率', '與', '某些', '屬性', ')', '。', '我們', '使用', '輸入輸出向量', '的', '長度', '表徵', '實體', '存在', '的', '概率', ',', '向量', '的', '方向', '表示', '實例化參數', '(', '即', '實體', '的', '某些', '圖形屬性', ')', '。', '同一', '層級', '的', ' ', 'capsule', ' ', '通過', '變換', '矩陣', '對', '更', '高', '級別', '的', ' ', 'capsule', ' ', '的', '實例化參數', '進行', '預測', '。', '當', '多個', '預測', '一致', '時', '(', '本', '論文', '使用', '動態', '路由', '使', '預測', '一致', ')', ',', '更', '高', '級別', '的', ' ', 'capsule', ' ', '將', '變', '得', '活躍', '。', '」']
以下是該開源工具的安裝方法與使用說明:
安裝
pip install foolnltk
使用說明
1. 分詞
importfool
text ="一個傻子在北京"print(fool.cut(text))
# ['一個', '傻子', '在', '北京']
命令行分詞
python -m fool [filename]
2. 用戶自定義詞典
詞典格式格式如下,詞的權重越高,詞的長度越長就越越可能出現, 權重值請大於 1
難受香菇10什麼鬼10分詞工具10北京10北京天安門10
加載詞典
importfool
fool.load_userdict(path)
text ="我在北京天安門看你難受香菇"print(fool.cut(text))#['我','在','北京天安門','看','你','難受香菇']
刪除詞典
fool.delete_userdict();
3. 詞性標註
importfool
text ="一個傻子在北京"print(fool.pos_cut(text))
#[('一個', 'm'), ('傻子', 'n'), ('在', 'p'), ('北京', 'ns')]
4. 實體識別
importfool
text ="一個傻子在北京"words,ners =fool.analysis(text)
print(ners)
#[(5, 8, 'location', '北京')]
作者暫時只在 Python3 Linux 平臺測試過,不過我們發現它在 Windows 系統也能正常運行。