作者:圖鴨科技
現如今城市生活節奏越來越快,我們每天接收的信息越來越多。在龐大視頻信息中,作爲用戶的我們在看完整視頻之前,更想知道視頻主題是什麼、視頻精華信息是哪些,也是基於這種需求,谷阿莫等影視評論者纔得到如此多的關注。此時,視頻摘要就體現出其價值所在了。
什麼是視頻摘要?
視頻摘要,就是以自動或半自動的方式,通過分析視頻的結構和內容存在的時空冗餘,從原始視頻中提取有意義的片段/幀。從摘要的技術處理過程來講,視頻摘要一般可以分成兩種,靜態視頻摘要和動態視頻摘要。現階段,我們公司主要致力於靜態視頻摘要的研究。接下來就和大家主要說一下靜態視頻摘要。
什麼是靜態視頻摘要?
靜態視頻摘要,又稱爲視頻概要,即用一系列從原始視頻流中抽取出來的靜態語義單元來表示視頻內容的技術。簡單來說,就是在一段視頻中提取出一些關鍵幀,通過將多個關鍵幀組合成視頻摘要,使用戶可以通過少量的關鍵幀快速瀏覽原始視頻內容。進一步發展的話可以爲用戶提供快速的內容檢索服務。
例如,公開課的視頻中,提取出含有完整 PPT 的幀。我們將含有關鍵信息的所有幀提供給瀏覽者,可以使其在較短的時間內瞭解到較長視頻的主要內容。又例如,將一個 2 小時的電影提取出其關鍵部分,組合成一個 2 分鐘的預告片,也屬於靜態視頻摘要。其提取流程大致如下:

靜態視頻摘要技術簡介
靜態視頻摘要通過描述原始視頻中的每幀圖像的特徵,通過對幀間的特徵差異值比較,抽取出原始視頻的關鍵幀。故,靜態視頻摘要的第一步,需要獲取幀信息特徵。
關於圖片的特徵提取,從 2012 年的 AlexNet,到 2014 年的 VGGNet 和 GoogleNet,幾年的 ILSVRC(ImageNet 大規模視覺識別挑戰賽)已經使得圖片分類和特徵提取達到了近乎完美的境界。靜態視頻摘要中的圖片摘要工作基本無需耗費時間,利用已有的圖片分類網絡,提取出視頻每一幀的圖片特徵信息,即可解決。

圖片來源:http://www.jianshu.com/p/58168fec534d
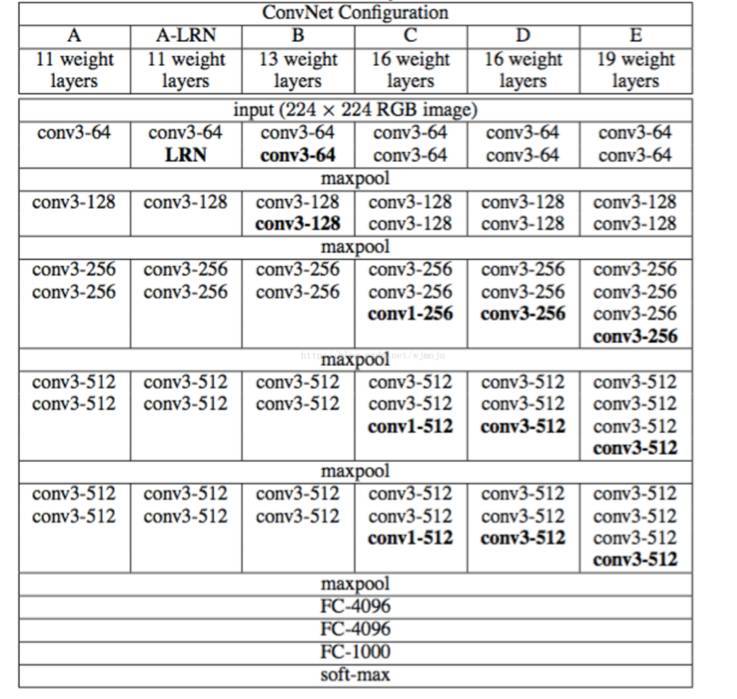
VGG 網絡結構圖,圖片來源:http://x-algo.cn/index.php/2017/01/08/1471/
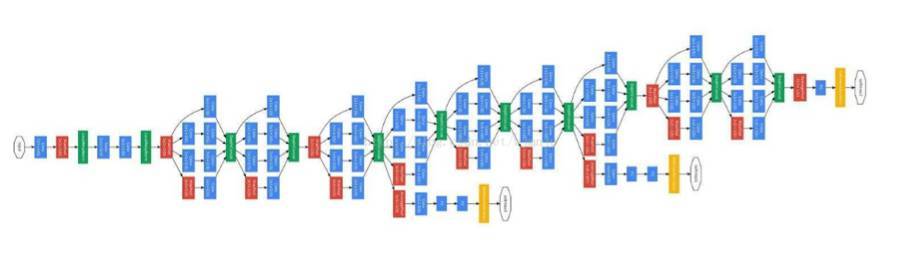
Googlenet 模型,Google 官方論文配圖
但是人們在閱讀一篇文章或觀看一段視頻的時候,往往不是根據單一的幀或單詞進行理解,而是需要與前後所看過內容相結合,完成對整體內容的理解。傳統的神經網絡不能做到這點,因此,在視頻文本摘要中,往往需要一種特殊的神經網絡——Recurrent Neural Networks(循環神經網絡)。RNN 是一種具有循環結構的網絡,它可以持續保存前面的信息,其大致網絡結構如下圖:
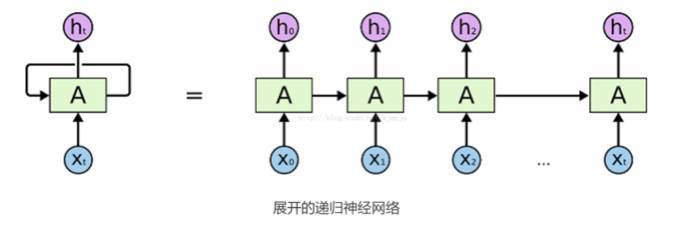
這樣的一個神經網絡,可以在做視頻文本摘要中,保留一部分前文的信息,達到銜接上下文關係的目的。因此,它被廣泛運用在文本類、摘要類的實驗中。
但傳統的 RNN 網絡依舊存在弊端,它無法連接到較遠的前文信息。例如,當我們需要預測「I grew up in France... I speak fluent French」中的最後一個詞「French」,我們需要與距離當前文較遠的「France」取得聯繫,但是,當兩個詞間隔十分大的時候,RNN 就會喪失遠距離的學習能力。這個問題被稱爲「長期依賴問題」。
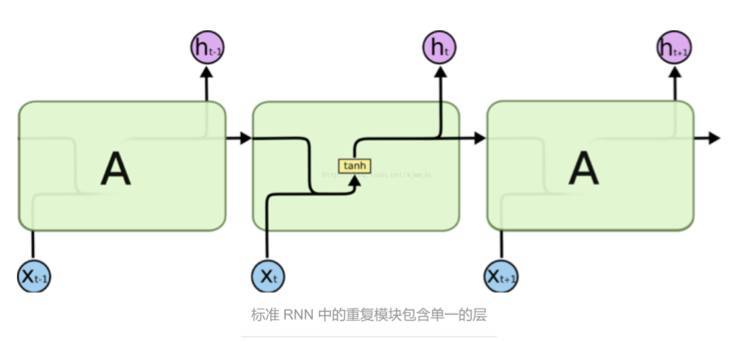
爲了解決這個問題,一種新的網絡被提出:Long Short Term 網絡,簡稱 LSTM,是一種特殊的循環神經網絡,它由 Hochreiter & Schmidhuber 提出,被認爲可以解決 RNN 所不能解決的長期依賴問題。與 RNN 不同,它利用一個叫做「輸入門限層」的 sigmoid 層來決定需要丟棄或更新的值,保證在每一步狀態中各個信息實時存在且爲最新的狀態。這樣的網絡被廣泛應用於需要上下文相關的實驗模型中。
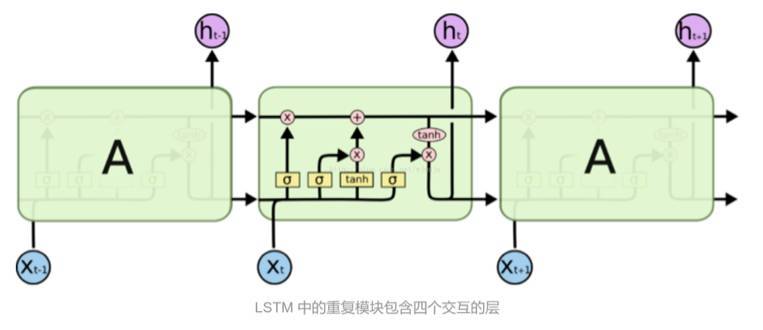
靜態視頻摘要的過程
下面我們用一個例子來簡述靜態視頻摘要的過程。2016 年 CVPR 的文章《Video Summarization with LongShort-term Memory》就利用了 LSTM 來完成視頻摘要。其主要模型如下:
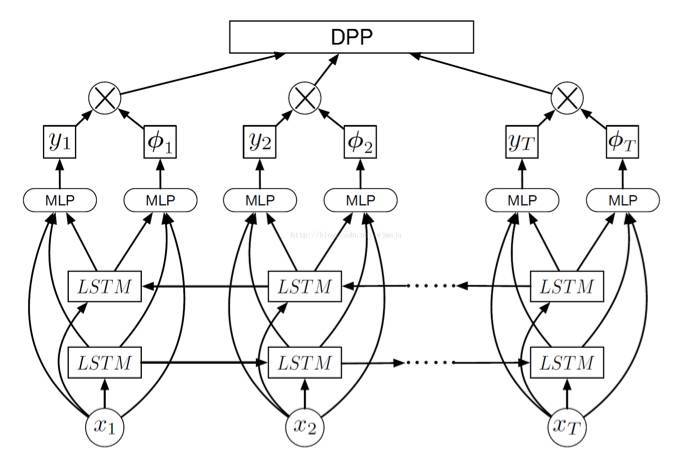
首先,利用 GoogleNet 網絡獲取視頻每幀的關鍵信息,即爲上圖的 x1_xT。將特徵信息輸入網絡中,經過雙層 LSTM 之後,獲得 y1_yT 即幀的分值,和ф1…фT 爲幀間的相似性。通過上圖模型,我們利用獲得的幀間相似性對整體視頻進行時間分割,以避免關鍵幀重複。得到每一幀的關鍵性分值之後,根據分值大小以及所需要的關鍵幀數目,獲得關鍵幀。
最後,根據客戶需求或視頻不同內容,可以將獲得的關鍵幀處理爲關鍵圖集或對其進行聚類後重新組合,獲得概括內容的短視頻。
總結
視頻摘要的運用場合非常廣泛,其技術也是近兩年計算機視覺界發展的熱門點。圖鴨科技目前主要致力於會議場景相關的視頻摘要,將視頻摘要與文本摘要相結合,用更精準簡單的結果向用戶展示一個完整的會議場景,在縮減用戶觀看視頻時間的同時,也使視頻的內容變得更加簡單。
圖鴨科技是一個專注於視頻通信、壓縮和分析的技術團隊,致力於讓視頻的每一幀變得更小更智能,有興趣的小夥伴可以直接郵件聯繫dumengping@tucodec.com