和我近期的大多數博文一樣,我寫這篇文章的起因是近期一個 Twitter 討論,具體是關於如何將深度卷積 神經網絡(CNN)的組件與大腦聯繫起來。但是,這裏的大多數思考都是我以前考慮並討論過的。當有人使用 CNN 作爲視覺系統的模型時,我通常(在研究討論和其它對話上)必須鼓勵和支持這一選擇。部分原因是它們(在某種程度上)是 神經科學領域相對較新的方法,還有部分原因是人們對它們持懷疑態度。計算模型一般在 神經科學領域發展較慢,很大部分(但並非全部)是來自不使用或構建計算模型的人;它們通常被描述成不切實際或沒有用處。在對技術宅的普遍反感和 深度學習/人工智能(會值多少錢?)的過度炒作氛圍中,不管你得到了什麼模型,某些人都會厭惡它。
所以在這裏我希望使用一個簡單(但很長)的問答形式來相對合理且準確地闡釋使用 CNN 建模生物視覺系統的情況。這個子領域很大程度上仍處於發展階段,所以文中不會有太多確定無疑的事實,但我會盡可能引述。此外,這些顯然是我個人對這些問題的答案(以及我個人提出的問題),所以請相信其中值得相信的。
我重點關注的是作爲視覺系統的模型的 CNN——而不是更寬泛的問題,比如「深度學習能否幫助我們理解大腦?」——因爲我相信這一領域是比較起來最合理、信息最多、最富成效的(而且也是我研究的領域)。但這種通用流程(根據生物學信息指定一個架構然後在相關數據上訓練)也可用於幫助理解和復現其它大腦區域和功能。當然,已經有人做過這種事了,可參閱:https://www.frontiersin.org/articles/10.3389/fncom.2016.00094/full
(我希望機器學習和數據科學領域的讀者都能讀懂這篇文章,但其中確實有些神經科學詞彙沒有給出定義。)
1.CNN 是什麼?
卷積神經網絡(CNN)是一類人工神經網絡。因此,它們是由被稱爲「神經元」的單元構成的,這些單元可根據輸入的加權和輸出一個活動水平。這個活動水平通常是輸入的非線性函數,通常只是一個整流線性單元(ReLU),其中當輸入全爲正時活動等於輸入,當輸入全爲非正時活動等於 0。
CNN 的獨特之處是神經元之間的連接的構建方式。在一個前饋神經網絡中,單元會被組織成層的形式,給定層的單元只會獲得來自其下面一層的輸入(即不會有來自同一層或後續層的其它單元的輸入,大多數情況下也不會有來自之前超過 1 層的輸入)。CNN 是前饋網絡。但不同於標準的單純的前饋網絡,CNN 中的單元具有一種空間排列。在每一層,單元都會被組織成 2D 網格形式,這被稱爲特徵圖(feature map)。每一個特徵圖都是在其下面一層上執行卷積所得的結果(CNN 也因此得名)。這意味着在其下面一層的每個位置都應用了同樣的卷積過濾器(權重集)。因此,在該 2D 網格上特定位置的單元只能收到來自其下面一層相似位置的單元的輸入。此外,輸入上附帶的權重對一個特徵圖中的每個單元都是一樣的(而各個特徵圖各不相同)。
在卷積(和非線性)之後,通常還會完成一些其它計算。一種可能的計算是交叉特徵歸一化(儘管這種方法在現代的高性能 CNN 中已不再流行)。其中,特徵圖中某個特定空間位置的單元的活動會除以其它特徵圖中同一位置的單元活動。一種更常見的操作是池化(pooling)。其中,每個 2D 特徵圖的一小個空間區域中的最大活動會被用於表示該區域。這能縮減特徵圖的大小。這一組操作(卷積+非線性→歸一化→池化)整體被稱爲一層。一個網絡架構就是由層的數量和各種相關參數(比如卷積過濾器的大小)的選擇定義的。
大多數現代 CNN 都有多個(至少 5)這樣的層,其中最後一層會向一個全連接層饋送數據。全連接層就像是標準的前饋網絡,其中沒有空間佈局或受限的連接。通常會有 2-3 個全連接層連在一起使用,並且網絡的最後一層執行分類。舉個例子,如果該網絡執行的是 10 類目標分類,那麼最後一層將會有 10 個單元,會有一個 softmax 操作應用在它們的活動水平上以得到每個類別相關的概率。
這些網絡主要通過監督學習和反向傳播訓練。這時,提供給網絡的輸入是圖像及其相關類別標籤構成的配對集。圖像像素值輸入網絡的第一層,然後網絡最後一層得出一個預測類別。如果這個預測得到的標籤與所提供的標籤不一致,那麼就會計算梯度,確定應該如何修改權重(即卷積過濾器中的值)以使分類正確。如此重複很多很多次(很多網絡都是在 ImageNet 數據庫上訓練的,這個數據庫包含 1000 個目標類別的超過 100 萬張圖像),就能得到在留存測試圖像上有很高準確度的模型。CNN 的某些變體模型現在已能達到 4.94% 乃至更低的錯誤率,優於人類水平。要得到優良的表現,通常需要很多訓練「技巧」,比如智能學習率選擇和權重正則化(主要是通過 dropout,即在每個訓練階段都有隨機一半的權重關閉)。
歷史上曾使用無監督預訓練來初始化權重,然後再使用監督學習來進行改善。但是,這似乎已經不再是優越性能所必需的了。
神經科學家能夠理解的深度 CNN 介紹可參閱《深度神經網絡:一種用於建模生物視覺和大腦信息處理的新框架》:https://www.annualreviews.org/doi/10.1146/annurev-vision-082114-035447
2.CNN 是否曾受視覺系統的啓發?
是的。首先,從名稱上就能看出來,人工神經網絡整體都受到了 20 世紀中期開始發展的神經生物學的啓發。人工神經元被設計用來模擬神經元接收和轉換信息的基本特性。
其次,卷積網絡所執行的主要功能和計算受到了某些關於視覺系統的早期發現的啓發。1962 年,Hubel 和 Wiesel 發現初級視覺皮層中的神經元會響應視覺環境中特定的簡單特徵(尤其是有向的邊)。此外,他們注意到了兩種不同類型的細胞:簡單細胞(它們只在非常特定的空間位置對它們偏好的方向起最強烈的響應)和複雜細胞(它們的響應有更大的空間不變性)。他們得出結論:複雜細胞通過在來自多個簡單細胞(每個都有一個不同的偏好位置)的輸入上進行池化而實現了這種不變性。這兩個特徵(對特定特徵的選擇性以及通過前饋連接增大空間不變性)構成了 CNN 這樣的人工視覺系統的基礎。
神經認知機(neocognitron)
CNN 的發展可以通過被稱爲神經認知機的模型直接追溯到這一發現。神經認知機是福島邦彥(Kunihiko Fukushima)於 1980 年開發的,其融合了當時有關生物視覺的知識,以期構建出一個能夠工作的人工視覺系統。神經認知機由「S 細胞」和「C 細胞」構成,可通過無監督學習來學習識別簡單的圖像。最早開發出 CNN 的 AI 研究者 Yann LeCun 明確表明他們的開發根基於神經認知機,參閱:https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
3.CNN 什麼時候開始流行起來的?
縱觀整個計算機視覺史,很多研究工作都集中在人工設計要在圖像中檢測的特徵上,這些設計都基於人們對圖像中最有信息的部分的看法。經過這些人工設計的特徵的過濾之後,學習只會在最後的階段進行,以將特徵映射到目標類別。通過監督學習端到端訓練的 CNN 提供了一種自動生成這些特徵的方法,這是最適合這種任務的方法。
這方面最早的主要示例出現在 1989 年。那時候 LeCun 等人使用反向傳播訓練了一個小型 CNN 來識別手寫數字。隨着 1999 年 MNIST 數據集的引入,CNN 的能力得到了進一步的發展和驗證。儘管取得了這樣的成功,但由於研究界認爲這種訓練很困難,這種方法失勢了,非神經網絡方法(比如支持向量機)迎來了發展勢頭。
下一個大事件直到 2012 年纔出現,那一年完全通過監督方法訓練的一個深度 CNN 贏得了當年的 ImageNet 競賽。那時候,1000 類目標分類的優良錯誤率大約是 25%,但 AlexNet 實現了 16% 的錯誤率,這是一個巨大進步。這一挑戰賽之前的獲勝方法依賴於更古老的技術,比如淺網絡和 SVM。CNN 的這一進展得益於使用了某些全新的技術,比如 ReLU(而不是 sigmoid 或雙曲正切非線性)、將網絡分配在 2 個 GPU 上執行和 dropout 正則化。但這並不是無中生有突如其來的,神經網絡的復興早在 2006 年就初見端倪了。但是,這些網絡大都使用了無監督預訓練。2012 年的這一進展絕對算得上是現代深度學習大爆發的一個重磅時刻。
參閱《用於圖像分類的深度卷積神經網絡:全面回顧》:https://www.mitpressjournals.org/doi/abs/10.1162/neco_a_00990
4. CNN 與視覺系統的當前聯繫是何時出現的?
當今神經科學領域對 CNN 的熱情喧囂很多都源自 2014 年左右發表的少數研究。這些研究明確比較了在不同的系統看到同樣的圖像時,從人類和獼猴身上記錄到的神經活動與 CNN 中的人工活動。
首先是 Yamins et al. (2014)。這一研究探索了很多不同的 CNN 架構,以確定是什麼導致了預測猴子 IT 細胞的響應的優良能力。對於一個給定的網絡,數據的一個子集被用於訓練能將人工網絡中的活動映射到單個 IT 細胞活動的線性迴歸模型。在留存數據上的預測能力被用於評估該模型。另外還有使用另外一種方法:表徵相似度分析(representational similarity analysis)。這一方法不涉及對神經活動的直接預測,而是會問兩個系統是否能以相同的方式表徵信息。這是通過爲每個系統構建一個矩陣實現的,其中的值代表對兩個不同輸入的響應的相似度。如果這些矩陣在不同的系統上看起來一樣,那麼它們表徵信息的方式也是類似的。
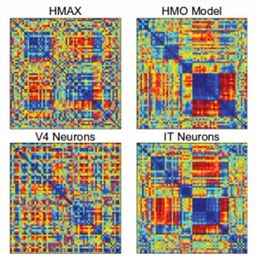
不同系統的表徵相異度矩陣(Representational Dissimilarity Matrix)
通過這兩種措施,爲目標識別優化過的 CNN 的表現超越了其它方法。此外,該網絡的第 3 層能更好地預測 V4 細胞的活動,而第 4 層(最後一層)能更好地預測 IT 細胞的活動。這表明模型層與腦區之間存在對應關係。
另一個發現是在目標識別上表現更好的網絡在獲取 IT 活動上也表現更好,而無需直接在 IT 數據上進行優化。這一趨勢在更大更好的網絡上也能大致保持,直到遇到某些限制(見第 11 問)。
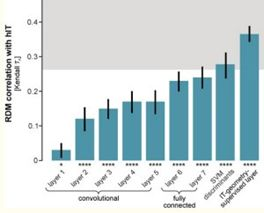
CNN 的後面幾層有與人類 IT 更相似的表徵
另一篇論文 Khaligh-Razavi and Kriegeskorte (2014) 也使用了表徵相似度分析,其將 37 種不同的模型與人類和猴子 IT 進行了比較。他們也發現更擅長目標識別的模型也能更好地匹配 IT 表徵。此外,通過監督學習訓練的深度 CNN(AlexNet)是表現最好的,也是最匹配的,其中該網絡的後面基層的表現比前面幾層更好。
5. 神經科學家過去是否使用過類似 CNN 的方法?
是的!第 2 問中提到的神經認知機受到了 Hubel 和 Wiesel 的發現的啓發,並且又轉而啓發了現代 CNN,但它也還催生了一些視覺神經科學領域的研究分支,其中最顯眼的是 Tomaso Poggio、Thomas Serre、Maximilian Riesenhuber 和 Jim DiCarlo 的實驗室的研究。基於卷積的堆疊和最大池化的模型被用於解釋視覺系統的各種性質。這些模型通常使用了不同於當前 CNN 的非線性和特徵的無監督訓練(在當時的機器學習領域也很流行),而且它們沒有達到現代 CNN 的規模。
視覺神經科學家和計算機視覺研究者所選擇的道路有各種不同的重合和分岔,因爲他們所追求的目標不同但又相關。但總體而言,CNN 可以很好地被視爲視覺神經科學家的建模道路的延續。來自深度學習領域的貢獻涉及到計算能力和訓練方法(以及數據),讓這些模型最終發揮了作用。
6. 我們有什麼證據說 CNN 的工作方式「類似大腦」?
卷積神經網絡有三個主要特點能支持將它們用作生物視覺的模型:(1)它們可以以接近人類的水平執行視覺任務,(2)它們的工作架構複製了有關視覺系統的已知基本功能,(3)它們產生的活動能與視覺系統中不同區域的活動直接關聯。
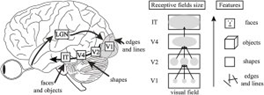
視覺層次結構的特徵
首先,究其根本和架構,它們有視覺層次結構的兩個重要組件。首先,單個單元感受野的大小會隨網絡中層的遞進而增大,就像 V1 到 IT 中感受野的增大一樣。第二,隨着層的遞進,神經元所響應的圖像特徵也越來越複雜,就像調諧過程從 V1 中的簡單線條到 IT 中的目標部分一樣。這種特徵複雜度的增長可直接通過可用於 CNN 的可視化技術看到。

網絡在不同層所學習的特徵的可視化
再更深入地看一下第(3)點,在原來的 2014 年的研究(Q4)之後的很多研究都在進一步確定 CNN 中的活動與視覺系統之間的關係。這些都表明了同樣的一般性發現:在觀看同樣的圖像時,人工網絡中的活動可與視覺系統的活動關聯起來。此外,人工網絡中後面的層能對應於腹視流(ventral visual stream)中更後的區域(或使用 MEG 等方法時所得響應中更後的時間點)。
很多不同的方法和數據集都可被用於製作這些點,比如下列研究:Seibert et al. (2016)、Cadena et al. (2017)、Cichy et al. (2016)、Wen et al. (2018)、Eickenberg et al. (2017)、Güçlü and van Gerven (2015) 和 Seeliger et al. (2017)。
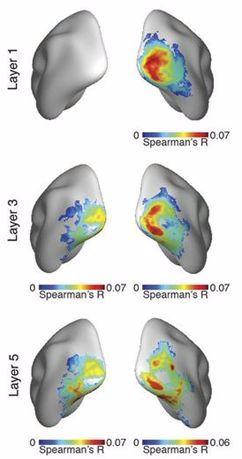
不同 CNN 層與腦區的表徵的對應(來自 Cichy et al.)
這些研究關注的重點一般是在簡單呈現不同目標類別的自然圖像時所得到的初始神經響應。因此,這些 CNN 實現的是所謂的「核心目標識別」或「快速鑑別給定視覺目標與其它所有目標的能力,即使出現了身份保持不變的變換(位置、尺寸、視角和視覺背景改變)」。一般而言,標準的前饋 CNN 能最好地得到視覺響應的早期組件,這說明它們復現了從視網膜到更高的皮層區的初始前饋信息掃視。
視覺系統創建的一系列神經表徵可以被 CNN 復現,這一事實說明它們執行了一樣的「解開(untangling)過程。也就是說,這兩種系統都會取圖像/視網膜層面上不可分的不同目標類別的表徵,並且創建允許線性可分的表徵。
除了比較活動,我們還可以更深入(1),即網絡的表現。這些網絡與人類和動物的行爲之間的詳細比較可以進一步被用於驗證它們作爲模型的使用情況以及確定仍然需要進展的領域。來自這類研究的發現已經表明這些網絡可以比之前來自多個領域的模型更好地取得人類分類行爲的模式(甚至能預測/操作它),但在某些特定領域這些網絡表現很差,比如圖像中出現噪聲或圖像差別很小但準確度下降很多的情況。
這種行爲效應的研究包括:Rajalingham et al. (2018)、Kheradpishesh et al. (2015)、Elsayed et al. (2018)、Jozwik et al. (2017)、Kubilius et al. (2016)、Dodge and Karam (2017)、Berardino et al. (2017) 和 Geirhos et al. (2017)。
所有這些是否滿足優秀大腦模型的標準?我們最好看看視覺領域的人說他們希望從視覺系統模型中得到什麼:
「理解大腦的目標識別解決方案的進展需要構建人工識別系統(通常會用到生物學啓發,比如 [2-6]),其最終目的是模擬我們自己的視覺能力。這樣的計算方法是至關重要的,因爲它們能提供可通過實驗檢驗的假設,也因爲有效識別系統的實例化是理解目標識別上一種特別有效的成功度量。」——Pinto et al., 2007
從這個角度看,很顯然 CNN 並不是視覺科學領域目標的轉移,而是實現其目標的一種方法。
7. 有其它能更好預測視覺區域的行爲的模型嗎?
總體而言,沒有。已經有一些研究直接比較了 CNN 與之前的視覺系統模型(比如 HMAX)的獲取神經活動的能力。CNN 出類拔萃。這樣的研究包括:Yamins et al. (2014)、Cichy et al. (2017) 和 Cadieu et al. (2014)。
8. CNN 是視覺系統的機制模型還是描述模型?
機制模型的合理定義是該模型的內部部分可以映射到系統中相關的內部部分。而描述模型則是僅匹配他們的整體輸入-輸出關係。所以視覺系統的描述模型可能是一個輸入圖像並且能輸出與人類給出的標籤一致的目標標籤的模型,但可能其工作方式與大腦並沒有明顯的聯繫。但是,如上所述,CNN 的層可以映射到大腦的區域。因此,在 CNN 執行目標識別時,它是腹側系統所執行的表徵變換的機制模型。
整體而言,如果要讓 CNN 是機制模型,我們不需要讓所有組件都有對應機制。舉個例子,傳統的大腦回路模型中基於放電率(rate-based)的神經元的使用。基於放電率的神經模型只是一個將輸入強度映射到輸出放電率的簡單函數。因此,它們只是神經元的描述性模型:模型中沒有內部組件與導致放電率的神經過程有關(Hodgkin-Huxley 神經元等更細化的生物物理模型是機制的)。然而,我們仍然可以使用基於放電率的神經元來構建迴路的機制模型(我喜歡的一個案例:https://www.ncbi.nlm.nih.gov/pubmed/25611511)。所有機制模型都依賴描述模型作爲它們的基本單元(否則我們都需要深入到量子機制來構建模型了)。
所以 CNN 的組件(即層——由卷積、非線性、可能的歸一化和池化構成)是腦區的機制模型還是描述模型?這個問題更難以回答。儘管這些層是由人工神經元構成的,其可以合理地映射到真實的神經元(或神經元羣),但很多計算的實現都不是生物式的。比如,歸一化(在使用它的網絡中)是使用高度參數化的除法方程實現的。我們相信這些計算可以使用擬真的神經機制實現(見上面引用的研究),但目前的模型並沒有這樣使用(不過我和其他一些人正在研究這個問題……見第 12 問)。
9. 我們應該如何解讀 CNN 的不同部分與大腦的關係?
對於習慣了處理細胞層面的事物的神經科學家而言,可能會覺得 CNN 這樣的模型的抽象價值大過實用價值(儘管研究抽象多區域建模的認知科學家可能會更熟悉它們)。
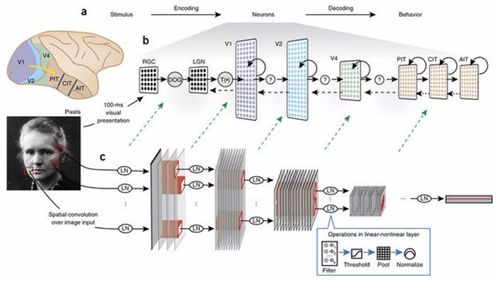
將 CNN 與大腦的區域和處理關聯起來
但就算沒有確切的生物學細節,我們還是可以將 CNN 的組件映射到視覺系統的組件。首先,CNN 的輸入通常是三維(RGB)的像素值,它們已經過了一些歸一化或變白處理,大致可以對應視網膜和背外側膝狀體核所執行的計算。卷積所創造的特徵圖有一個空間佈局,類似於在視覺區域中找到的視網膜拓撲映射(retinotopy),這意味着每個人工神經元都有一個空間受限的感受野。與每個特徵圖相關的卷積過濾器確定了該特徵圖中的神經元的特徵調製。單個人工神經元並不是要直接映射到單個真實神經元;將單個單元想成是皮質柱(cortical column)可能會更合理一點。
CNN 的哪些層對應於哪些腦區?早期使用僅包含少量層的模型的研究爲一層映射一個腦區提供了支持。比如,在 Yamins et al. (2014) 中,最後的卷積層能最好地預測 IT 活動,而倒數第二層能最好地預測 V4。但是,其確切的關係將取決於所使用的模型(更深度的模型允許每個腦區有更多層)。
在卷積網絡末尾的全連接層有更復雜的解讀方式。它們與分類器的最終決策的緊密關係以及它們不再有視網膜拓撲的事實說明它們更像是前額皮質。但它們在預測 IT 活動上也可能表現很好。
10. 視覺系統有哪些 CNN 不具備的東西?
有很多。尖峯、掃視(saccade)、分開的激勵和抑制細胞、動態、反饋連接、跳過某些層的前饋連接、振盪、樹突、皮質層、神經調質、中央凹、橫向連接、不同細胞類型、雙眼視覺、適應、噪聲以及大腦的其它細節。
當然,還有一些特性是當今用作模型的大多數標準 CNN 默認沒有的。但它們中很多都已經在更新型的模型中得到了研究,比如:skip 連接、反饋連接、掃視、尖峯、橫向連接和中央凹。
所以很顯然,CNN 並不是對靈長類視覺的直接複製。還應該清楚這並不意味着模型不合格。模型不可能是(也不應該)是相關係統的完整復現。我們的目標是讓模型具備能解釋我們想要了解的關於視覺的信息的必要特性,所以某個特性的缺乏對不同的人來說重要性也不一樣。比如說,預測 IT 神經元在前 100 ms 左右對圖像的平均響應需要哪些特性?這是一個需要實證的問題。我們不能事先就說某個生物特性是必要的或沒有這個特性的模型不好。
我們可以說沒有尖峯、E-I 類型和其它實現特性的細節的模型比有這些細節的模型更加抽象。但抽象沒有錯。這只是意味着我們願意把問題分成不同的層次,然後單獨解決它們。我們某天應該能將這些不同層面的解釋組合到一起,得到在大尺度和精細尺度上覆現大腦的複製品。但我們必須記住,不要讓完美成爲成功路上的敵人。
11. CNN 能做到什麼視覺系統無法做到的事?
對我而言,這是一個更加相關的問題。使用某種非生物學的模型來繞過困難問題比使用缺乏某些特定生物特性的模型更有問題。
第一個問題:卷積權重有正有負。這意味着前饋連接有激勵性的,也有抑制性的(而在大腦區域之間的大腦連接大都是激勵性的),單個的人工神經元可以激勵也可以抑制。如果我們只把權重看作是淨效果,那麼這還問題不大,這實際上也許可以通過連接抑制細胞的前饋激勵連接而執行。
接下來:權重是共享的。這意味着特徵圖中某個位置的神經元在其輸入上會使用與同一特徵圖中另一個不同神經元完全一樣的權重。儘管方位調諧(orientation tuning)等功能在 V1 中的視網膜拓撲上是這個情況,但我們不相信在一個視覺空間中更偏愛垂直線的神經元會與另一個位置更偏愛垂直線的神經元有完全一樣的輸入權重。這裏可沒有確保所有權重都相關和共享的「鬼魅般的超距作用」。因此,當前使用的幫助訓練這些網絡的權重共享應該被更接近生物創建空間不變調節的方法替代。
第三:最大池化怎麼樣?用神經科學的術語講,最大池化操作類似於神經元的放電率,其等於其最高放電輸入的放電率。因爲神經元會彙集很多神經元的信號,所以很難設計一個能直接做到這一點的神經元。但池化操作是受複雜細胞的發現啓發的,而且最早是被用作一種平均化操作,這是神經元可以輕鬆實現的。但事實已經證明最大池化在目標識別表現和擬合生物數據方面會更加成功,而且現在已被廣泛使用。
機器學習研究者對 CNN 的進一步發展已經讓它們遠遠超越了視覺系統的範疇(因爲機器學習研究者的目標只有表現水平本身)。某些表現最優的 CNN 現在有很多在生物學角度上看起來很奇怪的特徵。此外,這些更新的模型的極端深度(大約 50 層)已然降低了它們的活動與視覺系統的關聯。
當然,也還存在這些網絡的訓練方式的問題(通過反向傳播)。這會在第 13 問討論。
12.CNN 能做得更像人腦嗎?
我當計算神經科學家的一個主要原因是(沒有實驗設置的限制)我們可以做任何我們想做的事情。所以,是的!我們可以讓標準 CNN 有更多生物啓發式特性。讓我們看看我們已經取得的成果:
正如第 10 問中提及的,很多架構元素已經被添加到了 CNN 的不同變體中,這使得它們更接近腹側流。此外,在增加學習過程的合理性方面也已經有了一些研究成果(見第 13 問)。
除了這些努力之外,在復現生物細節方面的具體研究還包括:
受生物學啓發的 Spoerer et al. (2017) 表明橫向連接和反饋連接可以讓模型更好地識別有遮擋和有噪聲的目標。
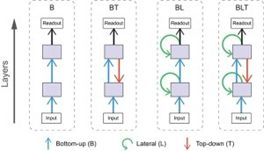
增加生物學啓發的連接,來自 Spoerer et al. (2017)
我本人的一些研究(在 Cosyne 2017 上呈現並在準確提交期刊)涉及到將穩定超線性網絡(stabilized supralinear network)(一種實現歸一化的仿生物迴路模型)納入 CNN 架構中。這會爲 CNN 引入 E 和 I 細胞類型、動態和循環(recurrence)。
Costa et al. (2017) 使用生物學啓發的組件實現了長短期記憶網絡(LSTM)。在爲人工神經網絡添加循環時,LSTM 是很常用的,所以確定可以如何通過生物式的方式實現這種功能會很有用。
13.CNN 使用反向傳播學習權重的方法是否重要?
反向傳播涉及到計算網絡中任意位置的權重應該變化的方式,以便減少分類器產生的誤差。這意味着第一層的一個突觸會有一些關於錯誤的信息並一直傳遞到頂層。但真正的神經元往往依賴於局部的學習規則(比如赫布可塑性(Hebbian plasticity)),其中權重的變化主要是由神經元之前和之後的突觸決定的,而不會受到任何遙遠因素的影響。因此,反向傳播應該不是模擬生物方式。
這無需影響我們對完全訓練的 CNN 作爲視覺系統的模型的影響。計算模型中的參數往往是用與大腦學習方式(比如用於獲取功能連接性的貝葉斯推理)沒有任何相似之處的技術擬合的。但這並不會讓所得到的迴路模型無法解讀。在極端的情況下,我們可以將反向傳播看作是一個和其它技術一樣的單純的參數擬合工具。而且 Yamins et al. (2014) 確實使用了一種不同的參數擬合技術(不是反向傳播)。
但是,採納這一觀點並不意味着模型的特定方面是無法解讀的。比如,我們並不期望學習曲線(誤差隨模型學習的變化方式)與人類或動物學習時犯錯的情況有關聯。
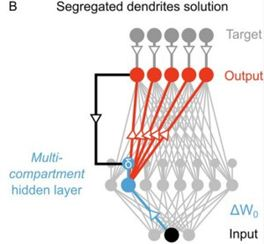
使用分離樹突(segregated dendrite)的局部誤差計算,來自 Guerguiev et al.
儘管當前實現的反向傳播不具有生物合理性,但其可被看作是大腦實際工作方式的一種抽象版本。目前有多個研究正努力使反向傳播具有生物合理性,比如通過局部計算和擬真的細胞類型來實現反向傳播,比如《Towards deep learning with segregated dendrites》和《An Approximation of the Error Backpropagation Algorithm in a Predictive Coding Network with Local Hebbian Synaptic Plasticity》。這會讓這一學習過程獲得更好的生物學解釋。使用更有生物合理性的學習流程是否能得到更匹配數據的神經活動?這還是一個需要實證解答的問題。
另一方面,無監督學習看起來像是一個大腦機制,因爲它不需要關於標籤的明確反饋,而是使用了有關環境的自然統計來發展表徵。到目前爲止,無監督學習還沒有實現監督學習那樣高的目標分類表現。但使無監督學習和方法具有生物合理性的進展可能最終會帶來更好的視覺系統模型。
14. 我們能使用 CNN 瞭解到有關視覺系統的什麼信息?
只靠 CNN,什麼也瞭解不到。所有的見解和發展都需要通過與實驗數據的交互而進行驗證和延展。也就是說,CNN 對我們理解視覺系統的方式可以有三種貢獻。
第一是驗證我們的直觀理解。就像費曼說的「我們不能理解我們不能創造的東西」。有了收集到的所有數據和發展起來的視覺系統理論,神經科學家爲什麼不能創造一個可工作的視覺系統呢?這應該能讓我們警醒,並意識到我們錯過了一些關鍵的東西。現在我們可以說我們對視覺系統的直觀理解基本上是正確的,我們只是缺少計算能力和訓練數據。
第二是允許實現理想的實驗檢驗平臺。這是科學界對機制模型的常用方法。我們可以使用已有數據建立一個模擬我們所感興趣的內容的合理模型。然後我們測試其各個部分,看哪些部分對功能實現是重要的。這能用於產生假設以便未來實驗和/或解釋之前未用於構建該模型的數據。
第三種貢獻方式是通過數學分析。對於計算建模而言,情況總是如此;將我們關於視覺系統工作方式的信念整合成具體的數據術語,從而開啓新型的研究方向。儘管在模型上進行分析時通常需要將它們進一步簡化,但這仍然能爲模型行爲的一般趨勢和侷限性提供有幫助的見解。在這種特定情況下,還會有一些額外的發展動力,因爲某些機器學習也有興趣在數學上剖解這些模型。這樣他們的見解就能在適當的情況成爲我們的見解,比如 http://www.cs.toronto.edu/~wenjie/papers/nips16/top.pdf
15. 使用 CNN 作爲視覺系統模型已讓我們瞭解到了什麼?
首先,我們表明我們的直觀理解實際上可以用來構建可工作的視覺系統,從而驗證了這些直觀理解。此外,這種方法已經幫助我們定義了(用 Marr 的術語)視覺系統的計算層面和算法層面。通過在目標檢測上訓練而獲得如此之多神經數據和行爲數據的能力說明這是腹側流的核心計算作用。而一系列卷積和池化就是做到這一點所需的算法的一部分。
我相信,這些網絡的成功也有助於我們改變對視覺神經科學領域基本研究單元的看法。很多視覺神經科學領域(乃至所有神經科學領域)一直以來都被以單個細胞及其調諧偏好爲中心的方法所主導。沒有嚴格一個神經元對應一個神經元的獲取數據的抽象模型將關注焦點放在了羣編碼(population coding)上。某天有可能對理解單個調製函數的嘗試會得到同樣的結果,但目前羣層面的方法看起來更有效。
此外,將視覺系統看作一整個系統,而不是隔離的區域,能重塑我們對這些區域的理解方式。人們在研究 V4 上投入了大量工作,比如試圖用語言或簡單的數學來描述什麼會導致該區域的細胞產生響應。當 V4 被看作是目標識別路徑上的中間立足點時,似乎就更不可能將其拿出來單獨描述了。就像這篇綜述論文《Deep neural networks: a new framework for modelling
biological vision and brain information processing》說的:「對一個單位的口頭功能解釋(比如作爲眼睛或人臉檢測器)可能有助於我們直接理解某些重要的東西。但是,這樣的口頭解釋可能會誇大分類和定位的程度,並低估這些表徵的統計和分佈本質。」事實上,對訓練後的網絡的分析已經表明對單個單元的強大且可解讀的調製與優良表現無關,這說明歷史上對單個單元的關注的方向有誤。
在探索不同的架構方面還有一些更加具體的進展。通過檢查獲取神經和行爲響應的哪些元素上需要哪些細節,我們可以得到結構和功能之間的直接聯繫。在《Deep Recurrent Neural Network Reveals a Hierarchy of Process Memory during Dynamic Natural Vision》這項研究中,加入網絡的橫向連接在解釋背側流響應的時間過程上比在腹側流上的作用更大。其它研究說明反饋連接對於獲取腹側流動態而言是很重要的。還有研究表明神經響應的特定組分可以通過隨機權重的模型取得,這說明分層架構本身就能解釋它們。而其它組分則需要在自然且有效的圖像類別上訓練得到。
此外,我們還觀察到,特定表現優良的 CNN 並不能準確預測神經行爲(見第 11 問)。這個觀察很重要,因爲這說明並非所有具有視覺能力的模型都是大腦的良模型。這讓我們相信,我們看到的能很好預測神經活動的架構(通過大腦區域和層之間的對應)表現良好的原因是它們確實獲取到了大腦所執行的變換的某些過程。
因爲 CNN 提供了一種生成擬真神經響應的「圖像可計算的」方式,所以它們也可被用於將更少被理解的信號與視覺處理關聯起來,比如這兩項關於 contextualizing oscillation 的研究:《Using DNNs as a yardstick for estimating the representational value of oscillatory brain signals.》和《Activations of Deep Convolutional Neural Network are Aligned with Gamma Band Activity of Human Visual Cortex》。
我自己也有使用 CNN 作爲視覺系統的模型的研究《Understanding Biological Visual Attention Using Convolutional Neural Networks》,我的研究主要是證明特徵相似性增益模型(它描述了注意的神經影響)可以解釋注意機制對錶現效果的有益影響。
最後,某些研究已經記錄到了沒有被 CNN 所實現的神經或行爲元素(見第 6 問)。這些研究有助於確定需要進一步實驗和計算探索的區域。
案例還有很多。總而言之,鑑於這方面的研究從 2014 年左右才真正開始,我會說研究的數量已經相當不錯了。
原文鏈接:https://neurdiness.wordpress.com/2018/05/17/deep-convolutional-neural-networks-as-models-of-the-visual-system-qa/