雷鋒網按:深度學習(神經處理)給自然語言處理帶來了革命性的進步,基於深度學習的機器翻譯等任務的性能優良大幅度的提升。面向未來,自然語言處理技術將如何發展和演進?在哪些方面會有新突破?7 月 23 日,第二屆語言與智能高峯論壇在北京舉行,華爲諾亞方舟實驗室主任李航以《神經符號處理開啓自然語言處理新篇章》爲題作了報告,就自然語言領域的發展、神經符號處理對自然語言處理的影響等方面闡述了他的看法。

李航博士,華爲諾亞方舟實驗室主任,北京大學、南京大學客座教授,IEEE Fellow、ACM 傑出科學家,研究方向包括信息檢索、自然語言處理、統計機器學習以及數據挖掘。
以下爲李航博士演講內容實錄,雷鋒網(公衆號:雷鋒網)做了不改變原意的編輯。
今天想跟大家一起看一下,我們現在一個主要研究方向,也希望跟大家一起推動這個研究方向,它是神經符號處理。
神經符號處理是未來自然語言處理非常重要的一個方向,這個報告大概分以下幾個部分:
一,對自然語言領域做一個概述。從我的角度把最近幾個報告的主要觀點,再重新梳理一下。
二,爲什麼我們覺得神經符號處理是未來重要的一個研究方向,它的主要應用就是更廣義的問答(我們叫智能信息知識管理系統)。同時,介紹一些業界相關工作和我們自己做的一些研究。
三,拋磚引玉,大家一起探討一些相關問題。
自然語言處理的終極目標是做自然語言理解,就是讓計算機能夠理解人類的語言。具體來說有兩個方面:像人一樣能夠去說話;像人一樣能去閱讀。理解大概有兩層定義:基於表示的;基於行爲的。
如果計算機系統聽到一句話,它能夠對應它內部的表示,我們就認爲這個計算機理解了這個語言。或者是基於行爲的,機器人聽到一句話,能夠按照話的內容去做一些行爲,就認爲這個機器人理解了這個自然語言。我們這個領域終極目標就是,期望我們能夠開發出這個技術,使計算機能達到這樣的智能識別。
但我們也知道,語言其實是一個非常複雜的現象,不做自然語言處理、人工智能,可能人類自己都不知道,我們自己的語言是這麼複雜的一個現象。讓我來總結的話,語言有五個特性,使得我們把語言放在計算機上,變得非常具有挑戰性。
既有規律又有很多例外;
組合性;
遞歸性,造成了語言非常複雜;
比喻性;
語言的本質就是產生新的語言進行表示,其實都是在做比喻。所以,比喻性是語言非常重要的特性。語言的理解跟世界知識是密切相關的,如果你撇開了知識這些東西談語言,其實都是無從談起的。
交互性。
我們人類的語言其實是人跟外界做互動的一種手段,離開了對外環境的交互,談論語言其實也是沒有意義的。所以,因爲語言有這麼複雜的特性,使得我們在計算機上去實現自然語言理解,非常具有挑戰性的。這就相當於這些特性使得我們要用現在的技術做計算的話,基本上都是做全局搜索,全局的這種計算還不知道該怎麼做。這是非常複雜,具有挑戰性的。
主要原因有以下幾點:
原因一,最近寫的一篇文章,在計算機學會通訊上,叫做迎接自然語言處理新時代,有這樣一些觀點,做了比較詳細的介紹和總結。而在去年在中文信息處理大會上報告的內容,也是這個觀點。
原因二,我們現在總結看的話,爲什麼自然語言處理這麼難,因爲本質的原因就是,我們還不知道,是不是能夠用數學的模型刻畫語言現象,這個是自然語言處理的本質。這件事情可能不可能做我們不知道,我們只能是部分地實現這個目標。
所以,這是爲什麼自然語言處理(甚至是廣義的人工智能)都非常具有挑戰性的原因。
現實當中大家採用的辦法,我們不叫自然語言理解,而是叫自然語言處理。我們的策略是,把人類做語言理解的這個複雜過程進行簡化。
第一個,我們現在能去做的事情。人類要是理解語言的話,比如人做這種問答,問我姚明身高是多少,我想一想可能是 2 米 29。我回答的這個過程,可能包含了多個步驟。比如語言的分析、理解、推理、知識的檢索,最後做判斷,最後產生我的回答,是一個非常複雜的過程。
但是,我們現在要用計算機來做這種智能問答或者知識問答的時候,其實我們大幅度地簡化了這個過程。就是隻做分析、檢索和生成。今天大會裏面有很多老師做報告,介紹自然語言處理相關的技術,基本上做問答的時候,都是把這個問答的過程簡化。 
第二個,現在自然語言處理,非常主流的做法就是數據驅動。我們主要的核心技術是機器學習,現在是用深度學習來做。同時,我們把人的知識放進去。深度學習的重要的特點是,整個技術其實是一種機器學習,但是它的模型是從人的大腦處理機制中得到啓發,然後我們定義這個模型。
所以,現在人工智能、自然語言處理,我們採用的基本工具是機器學習,儘量能夠把人的知識導入進來,同時讓這個模型儘量去參考跟人一樣的處理機制,實現自然語言處理。
現實當中,我們看到深度學習、大數據,確實給自然語言處理帶來了很多新契機。這條路到目前爲止看,是最有希望能夠再往前推進的一條路。
這個觀點前年在一次大會上我作報告介紹的觀點,也是在計算機學會通訊上有寫過一篇文章,簡論 AI,就是這裏面介紹的觀點。 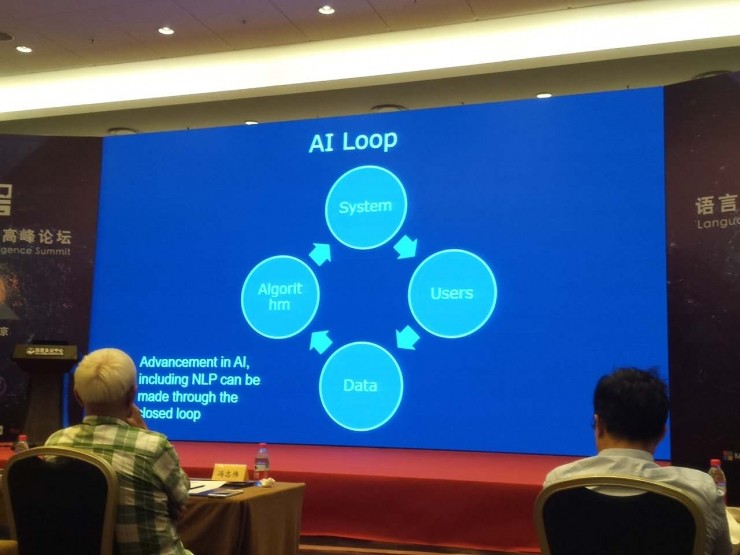
大家也看到,我們現在的自然語言處理包括人工智能都是這樣一個過程。基於數據,我們的系統有了用戶,之後我們根據數據改進算法、改進系統,使系統的性能不斷提高。在人工智能閉環的時候,我們就可以不斷地去給用戶提供更好的服務,使得我們這個系統變得更加智能化。
我們看一些自然語言處理技術,就是說數據驅動,自然語言處理大概有五類技術,我們用數學建模,用統計機器學習辦法建模,基本上就是這五類模型。主要的應用、方法基本上都屬於這五類技術。
分類。文字的序列,我們要打印標籤,這是我們常做的最基本的自然語言處理。
匹配。兩個文字序列都匹配,看它們匹配的程度,最後輸出一個非負的實數值,判斷這兩個文字序列它們的匹配程度。
翻譯。把一個文字序列,轉換成另外一個文字序列。
結構預測。你給我一個文字序列,讓它形成內部結構的一個信息。
序列決策過程。在一個複雜的動態變化環境裏面,我們怎麼樣不斷去決策。比如描述序列決策過程的馬爾可夫隨機過程,這是一個有效的、非常常用的數學工具。
我們看自然語言處理的大部分問題,基本上做得比較成功、實用的都是基於這樣的技術做出來的。比如:分類,有文本分類、情感分析;匹配,有搜索、問答、單輪對話、基於檢索的單輪對話;翻譯,有機器翻譯、語音識別、手寫體識別、基於生成方法的單輪對話;結構預測,有專名識別、詞性標註、語意分析;序列決策過程,有多輪對話。
我們看到所有的這些重要的自然語言應用,其實是這五種最基本的技術,基本上都能夠做得還不錯。不過,自然語言處理我們現在做得並不完美,離理想中的情況還差得非常遠。
這是從另一個角度看這個問題,我們把它叫做技術的上界和需求的下界。這個綠線表示技術能夠達到的性能上界,比如機器翻譯、專名識別,不可能達到一個上界。這個藍線表示,用戶對需求要求的下界。用戶肯定是有一個最基本的要求,你這個機器翻譯如果達不到,或者太低的話,我們是不能夠給用戶提供滿意服務的,用戶是不會去用這個自然語言處理系統的。所以,一定有一個用戶要求的最低下界,對任何一個實際的應用,都可能有這樣的一個下界。 
我們這個技術的上界就是,如果能夠碰到需求要求的下界的話,實際上這個系統就有可能被用戶用起來。大家覺得這個已經能夠滿足實際的需求了,否則的話,你這個做得再好,用戶要求的下界更高,實際的技術也不可能實用。自然語言處理,大家現在在做的事情就是剛纔看的這個綠線部分,怎麼樣不斷往上提高,使技術的上界——紅色的這部分,能夠再往上提高,使得我們有更多的技術能夠去滿足用戶需求,使得用戶能夠使用起來。
我們可以看到,現實當中自然語言處理很熱,上午還有人問,自然語言處理裏面哪些技術已經比較實用了,可以看到機器翻譯和語音識別已經越來越實用化。但是我們可以清楚地看到,這個機制和人做的機器翻譯、或者人去做語言識別完全不是一回事。我們還是用數學模型、數據驅動的方法。這個模型是參考了人類大腦的機制,用大數據做出這樣的東西。
這塊的話,我們還會看到有很多新的技術,比如說,Sequence Learning(序列學習)這樣的技術,不斷有新技術出來改進。至少現在看,主流的研究方向、發展方向是這個,但是我們已經越來越能夠碰到用戶需求要求的下界,所以我們這些技術能夠變得越來越實用化。單獨對話包括單獨的這種問答,也是越來越實用化。
我們看到各種各樣的工業產品、服務出來,能夠單輪對話。或者相對來說已經比較成熟,未來能做得越來越好。但是,多輪對話還是相對比較有挑戰。最主要的原因是,多人對話的數據還非常缺少。其實數據驅動這個模型做好的話,沒有足夠的數據,就是一個很大的挑戰。現在做研究也是非常困難。
所以,我們可以看到,未來自然語言的發展,可能會有大的改變。我們剛纔說這五種最基本技術,大家不斷往前推進,能夠使得技術上界不斷往上提高,整個業界趨勢是這樣的。
下面看一下神經符號處理。
自然語言的本質特點就是符號,符號表示的一個最重要的優點就是它可解釋性和可操作性好。我們在計算機上進行符號處理的話,就會用符號來表示我們所有的東西。但是,我們同時也看到,自然語言的特性,它本身是具有歧義性,有不確定性。我們如果把語言搬到計算機,多半都還擁有噪音。
另一方面,我們看到深度學習,更廣義的統計學習能夠比較成功的原因就是,這些機器學習方法它能夠很好地應對不確定性、處理好語言裏面的歧義和噪音。另一方面,我們叫神經表示(向量表示),用向量來表示語義,它有很強大的優勢。

我們現在可以明顯看到,符號表示和神經表示其實是互補的。大家自然會想到這樣一個問題,我們能不能把這兩個結合起來,這就是我們說的神經符號處理。我們希望通過這樣的手段,能夠把自然語言處理能做得更好,把這個技術往前推動。
不過我說的話,大家可能不太相信。正好今年年初的時候去了一個大學訪問,拜訪了深度學習大師 Yoshua Bengio 教授,我還專門跟他探討了他對神經符號處理的看法,這是他基本的 Comments,不是原話,總結一下就是有三點:
第一,如果把符號放到神經網絡裏面,他覺得這很難,可能不 Work。神經網絡本身就是一個向量矩陣表示的東西,在這個模型裏,把符號塞進去其實是挺難塞的。
第二,如果把符號處理和神經處理在外圍有效地、不斷地結合起來,這是很有道理的,是可以考慮的。
第三,他說這種問答對話,其實應該是一個重要的應用。
至少我們也得到他的認可,最基本的觀點跟 Bengio 教授的想法也是一致的。
我們下面看一下,智能信息知識管理系統。大家可以認爲這是一個知識問答系統,但是我這樣叫的原因是它跟我們一般的問答系統還略微有點不同,我們希望一定程度上,參考人類大腦的機制。

這個系統有幾個模塊,有語言處理單元、中央處理單元、短期記憶、長期記憶。比如說我們來了一個問句,語言處理單元對它進行分析,把這個結果放到短期記憶力,然後在長期記憶力找到相關的知識或者信息,接着把檢索到的內容放到短期記憶力,最後再通過語言處理單元產生出回答。這個是我們在使用過程當中的系統。
還有學習,這塊我們希望用深度學習技術,進行端到端的系統構建。這個系統本身同樣有語言處理單位、中央處理單元、短期記憶、長期記憶。我們在學習的過程中進行假設,這個輸入是大量的信息知識和問答數據,就是有非結構化數據、結構化數據,也有大量問答,就是一問一答,形成這樣的訓練數據。我們最理想的狀況,只使用完全數據驅動的方法,端到端地自動構建整個問答系統。我們構建整個長期記憶裏面的信息和知識,這是我們所構想的,或者建議大家考慮這樣的智能信息知識處理系統。
它有幾個特點。首先,能夠不斷去積累信息和知識。這點跟我們人是相似的。能夠去不斷地看到新知識加到自己長期記憶裏。同時,如果有人用自然語言來問問題的時候,它能夠準確地回答。當自己不知道的時候,就說我不知道。我們人也是這樣,不是什麼都知道,就是我們不知道的時候,能夠準確地告訴用戶我不知道。
其次,希望這個系統儘量完全沒有人干預,而是自動地去能夠把它建立起來。這樣的系統將來會非常有用,而且非常強大。大家可以想象,我們如果身邊有一個智能助手,有什麼問題你不知道,過去問它,它可能會告訴你,這個會有多麼方便。當然這個願景不光是我在這兒說的,我們也可以看到業界很多人描述出了類似願景。
我覺得這非常重要,如果人類能夠做到這一點的話,就是一個質的飛躍。人類發明了語言,是第一個質的飛躍,有了語言,大家可以交流、傳遞信息,互相傳授知識。第二個質的飛躍就是,我們如果有一個智能系統放在自己身邊,我想要問什麼知識都能準確告訴我。
然後,換另外一個角度看,計算機有兩個地方是非常強大的:計算能力和存儲能力。計算能力已經發揮得淋漓盡致了,但是存儲能力發揮到一半,概念上講,它能存儲無窮多的信息,計算機現在可以把人類所有的知識信息全部存儲下來。但是我們現在遇到的瓶頸是我們不能有效地去訪問這些信息。這塊如果我們在自然語言處理、人工智能研究方面有重大突破的話,我們真的是可以把整個人類的能力又推進一步。
大家可以從另一個角度看,我們這樣的智能系統很理想,現實當中其實已經有這樣的雛形,也不是說幾乎是渺茫的。現在的搜索引擎,一定程度上已經扮演了這樣的角色,搜索引擎有爬蟲、索引、機器學習機制幫助我們去做排序,給我反饋結果。一定程度上已經在做類似的事情了,但只是沒有做得更好,我們相信這是一個演進過程,會不斷地往前推動,技術不斷地會進步。我們相信,未來的話擁有這樣一個智能助手能夠幫助到我們。
我們再看一下,爲什麼神經符號處理和智能信息管理是密切結合的。這個跟 Bengio 教授的想法是相關的。這個技術和這個應用有一些天然的關係,另一方面的話,它倆真正是互補、強烈相關的。
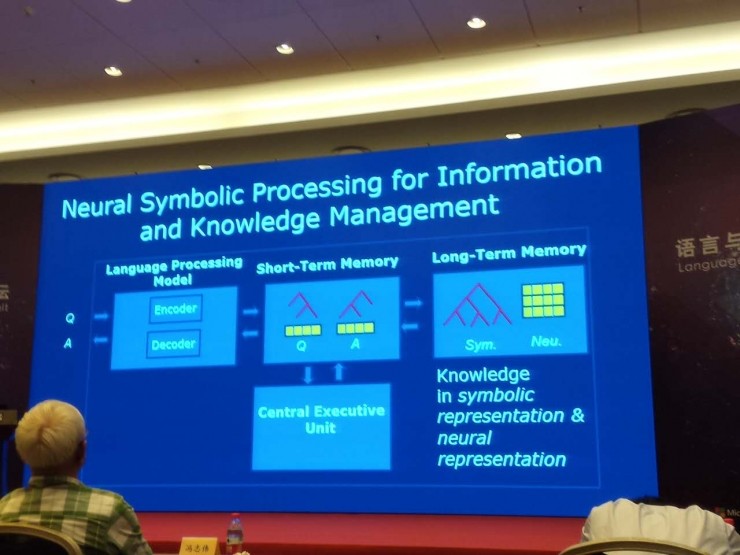
我們可以考慮用這樣的技術,神經符號處理實現智能信息知識管理系統。就是說,你先來了一個問題,通過語言處理模塊,它有編碼器和解碼器,編碼器把這個問題轉換成中間的表示,中間表示放在短期記憶裏,這個問題是有兩部分,既有符號表示又有神經表示。現在自然語言處理內,很多系統類似在做這樣的事情,大家可能沒有明確說這個事。
知識信息都放在長期記憶裏,也是有兩種表示,既有信息表示又有符號表示。但這兩者中間的話也是分開的,其實應該是密切相關的,但是這個怎麼去做,還有很多要去解決的問題。
但是,我們可以想象,長期記憶裏的信息和知識,都是既有符號表示又有神經表示。做問答的時候來了個問題,做了分析有了內部表示以後,可以通過在短期記憶裏的表示,通過表示之間的匹配,在長期記憶裏找到相關的信息和知識,在短期記憶裏也產生對應的符號和神經表示。這時候還有一個解碼器,把這個表示轉換成自然語言、答案,這樣我們就可以構建一個非常智能的自然語言問答系統。
這個想法其實大家已經在各個層面上看到很多了,相關的工作有很多。例如:語義分析,Semantic Parsing,在 Semantic Parsing 裏面要做的事情,就要把自然語言的語句,轉換成結構化內容的表示,這個 Semantic Parsing 到目前爲止,最主要的想法還是通過人寫的規則,定義語法、定義模型,然後做語意的解析。但是,我們假設完全不用人來參與,更要去學習內部的表示該怎麼去做。
還有,CMU 的這個項目大家知道,叫 Never Ending Language Learning(NELL),這些想法就是,互聯網裏抓取的知識,不斷擴大知識,開始的時候,有最基本的 Ontology(本體論)。然後有一些例子,比如北京是中國的首都,這樣的例子,希望從互聯網裏面找到更多的知識,把它加入到 Ontology 裏去,希望這個過程機器能夠不斷抓取,抓取的準確率和效率能夠不斷提升。這是 NELL 這個項目。
還有 Facebook 的 Memory Network,能做一些簡單的問答,比如裏面有一個系統用自然語言的,比如—John is in the playground.—Bob is in the office.—John picked up the football.—Bob went to the kitchen.然後就問這個系統,Where is the football?回答 Playground 就是對的。
Facebook 推出這種模型的話,可以去做這樣簡單的問答。當然現在準確率還不是特別高,它最基本的想法就是,把這些用自然語言表示的信息,能夠把它放到長期記憶裏,這個長期記憶也是神經表示,把內容表示放到裏面,來了一個新問題,把新問題直接轉換成神經表示然後再做匹配,找到相關答案,然後返回回來。現在這個模型還比較簡單,但是這個方向很多人都已經在做了。
還有大家也知道,Differentiable Neural Computers 這樣的模型,它基本的想法也是,覺得現在神經網絡很弱的地方,就是沒有長期記憶,希望能夠更好地利用長期記憶。長期記憶在 DNBD 的模型裏,它實際上就是一個大矩陣,每一行向量其實是比較深的一個語義表示。這個模型本身有三種神經網絡,能夠去控制訪問這個長期記憶機制,因爲有長期記憶的話,一個重要事情是要從長期記憶裏進行讀取。這個讀取的控制,有三個神經網絡能夠去進行。我們大家也在朝這個方向在做。
下面簡短介紹一下,我們在諾亞方舟實驗室做的一些基礎研究。有呂正東博士、尚利峯博士,還有其他合作的老師一起做的工作。
主要有兩個工作,都是研究我們順着這個思路來做的。
第一個是在知識圖譜裏面進行知識問答。假設我們有大量數據,比如說姚明身高是多少,2 米 29,我們能夠有這種觀點,說出答案的話,具體是對應着知識庫裏的哪一個單元,我們有大量數據的話,我們的目標就是有一個學習系統,就是學習神經網絡的,然後構建自動問答系統。來了一個新問句的話,我們能夠從數據庫、知識庫裏面找到答案。然後就這麼產生自然語言回答,這是我們現在做的一個工作。
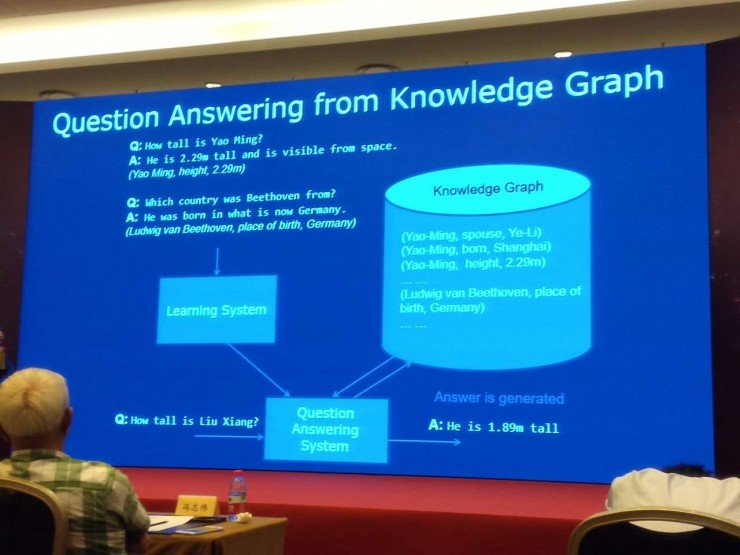
這種 Setting 如果大家能夠做得非常好的話,真正就能夠自動地構建這個問答系統,一個知識庫的例子,能夠自動地構建問答系統。
這個思想的話,基本上也是剛纔我介紹的我們想做的這種神經符號處理的思想。就是來了問句以後,我們有編碼器,轉換成內部的表示,它既有符號,又有神經表示(向量表示),這個三角是一個符號,這個黃色長條表示神經表示(向量),我們這個知識庫裏的單元圖,也是由符號單元圖表示,也有對應向量表示。整個知識,有兩種表示,問答過程中,確實像剛纔描述一樣,我們在知識庫裏找到答案,產生中間表示,解碼器通過答案還有編碼器產生問句的表示,最後產生一個回答。

我們剛開始從知識圖庫裏面找到答案,第二個可能就是關係數據庫。我們的知識不是在網絡表示裏面給的,而是在數據庫的表裏給出,這樣我們其實也可以做類似事情。就是我們提出了一個模型,可以把這個關係數據庫既做符號表示又做神經表示。有這樣一個長期記憶力的整個知識表示。來了問句以後,把它轉換成中間的神經表示,然後去做檢索、匹配找到答案,最後產生答案。這塊的話,我們進一步改進了這個模型,希望能夠更或地結合符號和神經處理。

下面就是對報告的總結,今天跟大家一起看的神經符號處理,我覺得是重要的研究方向。要我來說的話,是自然語言處理未來發展最重要的方向之一。
它最主要的應用,應該是這種廣義的知識問答,這塊智能的信息和知識管理。我們也都看到,業界大家都是往這個方向走,已經取得了一些成果,但是真正把這些技術實用化,還有很多具體的問題要去解決,還有很多實際的工作需要去做。但是,我覺得,我們對這個方向還是充滿信心,還是覺得將來會是非常令人振奮的。
問:您剛纔報告中有一句話我覺得非常好,就是我們現在要懷疑一下,人工智能能不能用數學模擬到人的智能的情況。這裏我想聊一下當今比較熱門的 Chatbot,大家在做對話的時候,都是侷限於單輪對話,或者說不特定領域的,對多輪對話和開放領域的問答,我們都做得非常不好,對於多輪對話開放性的問題,您覺得人工智能目前它能夠實現到一個什麼樣的程度?以及用目前的技術的話,它有個大致的解決時間嗎?
李航:我覺得還是數據是一個瓶頸,現在大家都沒有數據,其實一定程度上,不管大公司小公司,大家數據都不夠,因爲多輪對話的時候,它的複雜度一下子增加很多。它不是一個簡單地從單輪到多輪,大數據增加了一些,它應該是指數級地增加這些大數據。
我個人觀點是,Open Domain 的這種閒聊,做成多輪是很難的。可能都沒有什麼短期看到的可能性。但是如果基於任務驅動的,有一定的數據以後,應該是能夠做的,真的需要有數據才能夠往前推動。
問:您剛纔提到兩種表示方式,一種是傳統符號的表示方式,現在是知識圖譜中間的一種表示,另外一種是向量化的表示。我覺得向量化的表示方式一種好處是,雖然我覺得我們有很多知識,很難用目前這種邏輯符號方式來描述,用向量化的表示方法,不一定很準,但可以從大量語料裏頭學習到一定的東西,我們雖然不知道它是對的。但對於傳統符號很難表示的這種情況下,像您剛纔說的這種,怎麼來互相結合?
李航:應用驅動比較難,你就不知道用向量表示到底是不是合理,那只有通過最後應用的結果進行判斷。其實大家對知識的理解,我們自己日常工作生活當中使用的一些知識都是下意識的,真的是不知道它具體是個什麼樣形式,有什麼樣內容。這些東西,如果我們放在計算機裏就會發現,語言有衆多歧義,知識有更多不確定性。
這些東西就是你說的,我們現在只能在一些頁目能看到,可以怎麼把它表示出來。比如說,我們現在默認 Binding 還是非常簡單粗暴的方法。但在這裏面能看到,它能解決一些問題,就說明應用啓動能夠幫助我們找到這些更好的表示方法,更好地去學習這些表示方法。
反正我覺得對知識的認識有兩個很重要:一個是應用驅動,一個是具體的領域。
一定要把領域跟應用分清楚。當然你也可以說我就是 General Domain,那也是一個,但是一般來說知識要用的話,可能是在金融、醫療甚至更細的領域這樣去做,能更加在現實當中能夠用起來,也更容易去對這種應用的評價,看這個表示方法到底好不好。
雷鋒網後續還將發佈芝加哥伊利諾伊大學劉兵教授的演講內容實錄,敬請期待。