雷鋒網(公衆號:雷鋒網)AI科技評論按:Michael Jordan教授是機器學習領域神經網絡的大牛,發表過很多神經網絡方面的學術論文。雷鋒網AI科技評論整理了公開發表在伯克利博客上的一篇機器學習領域的學術性文章,作者Chi Jin、Michael Jordan。
原文地址鏈接:http://bair.berkeley.edu/blog/2017/08/31/saddle-efficiency/
在機器學習領域中,非凸優化中的一個核心問題是鞍點的逃逸問題。最近關於這個方面的研究表明,梯度下降法(GD, Gradient Descent)一般可以漸近地逃離鞍點(詳見Rong Ge和Ben Recht的相關論文),但是還有一個未解決的問題——效率,即梯度下降法是否可以加速逃離鞍點,還是反而速度明顯地降低了?逃逸率和環境維度的關係是怎樣的?那麼,這篇文章將會就涵蓋這些問題,描述Chi Jin與Michael Jordan在與Rong Ge,Praneeth Netrapalli以及Sham Kakade合作的相關成果。效率方面,他們首次公開了梯度下降法在效率問題上的正面表現;令人驚訝的是,使用合理的擾動參數增強的梯度下降法可有效地逃離鞍點;實際上,rate和dimension上的結果幾乎看不出任何鞍點存在的痕跡。
擾動梯度下降
在經典的梯度下降(GD)領域——假設函數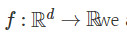 ,我們要在負梯度方向最小化函數f:
,我們要在負梯度方向最小化函數f:
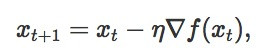
這裏 xt 是需優化變量在第t步的值,η 是步長。梯度下降法的理論研究在凸優化上已經很充分了,但是在非凸優化情況下就少了很多。我們知道,在非凸情況下,GD會快速收斂到駐點(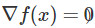 附近的點),但是這些穩定的點可能是局部極小點或者是沒用的局部最大點或者甚至是鞍點。
附近的點),但是這些穩定的點可能是局部極小點或者是沒用的局部最大點或者甚至是鞍點。
顯然,如果駐點是起點,GD是不可能逃離這個起始點的(就算起始點是局部最大點也一樣);因此,爲了實現GD的作用,我們需要稍稍調整一下GD,增加一些隨機變量。目前已經有了兩種方法:
1. 間歇性擾動:Ge/Huang/Jin/Yuan在2015年提出了《Escaping From Saddle Points --- Online Stochastic Gradient for Tensor Decomposition》,增加偶爾的隨機擾動,並提供了逃離鞍點的多項式時間保證。(亦見Rong Ge的博客);
2. 隨機初始化:Lee等人在2016年提出《Gradient Descent Converges to Minimizers》,進使用隨機初始化的方法,GD也可漸近地逃離鞍點(但是實現步驟趨向無窮大)(見Ben Recht的博客)。
漸進——甚至多項式時的結果對一般的理論研究來說是重要的,但這兩點不能解釋基於梯度算法在實際非凸問題中的成功。它們既不能證明GD的運行是可靠的——我們發現自己無法處於一種狀態中,即學習曲線趨於平緩一段時間(無法定義時間的長度),但是用戶無法知道漸近是否已經開始了。它們也不能證明GD具有在高維度中的良好性質,這一點在凸優化中是已知的。
解決這個問題的一個合理的辦法是考慮二階算法(Hessian-based)。儘管這些算法一般在一次迭代中的成本遠比GD高,也比GD執行起來更加複雜,但是它們確實提供了可有效地逃離鞍點所需的鞍點的幾何信息。因此,文獻中出現了對Hessian-based的算法合理解釋,並且使用這種算法已經取得了切實有效的結果。
GD是否是高效的呢?或者說,Hessian對快速逃離鞍點是必不可少的?
如果考慮隨機初始化策略,基於第一個問題則出現了一個反面的結果。總的來說,GD是低效的,尤其在最壞情況下花費冪指數的時間來逃離鞍點(詳見後文「增加擾動的必要性」部分)。
但是如果我們考慮擾動策略,神奇的是,結果竟大不相同。爲了清楚的陳述這個結果,我們使用如下的算法進行分析:

這裏,擾動參數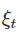 從一個適當的半徑範圍內,以一箇中心爲零的球均勻採樣,並當梯度適當時,擾動會被加入到迭代中。這些特殊的選擇是爲了便於分析;我們不認爲均勻的噪聲是必要的;也不認爲噪聲必須要在梯度值很小時才能加。
從一個適當的半徑範圍內,以一箇中心爲零的球均勻採樣,並當梯度適當時,擾動會被加入到迭代中。這些特殊的選擇是爲了便於分析;我們不認爲均勻的噪聲是必要的;也不認爲噪聲必須要在梯度值很小時才能加。
嚴格鞍點和二階駐點
在這篇文章中,我們定義鞍點,既包括經典鞍點,也包括局部極大值。它們是沿着至少一個方向在局部最大化的駐點。鞍點和局部極小值可以根據Hessian的最小特徵值來分類:
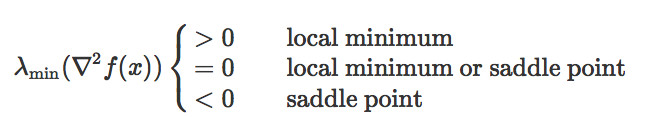
我們將上述情況中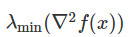 <0的鞍點稱爲嚴格鞍點(strict paddle points)。
<0的鞍點稱爲嚴格鞍點(strict paddle points)。
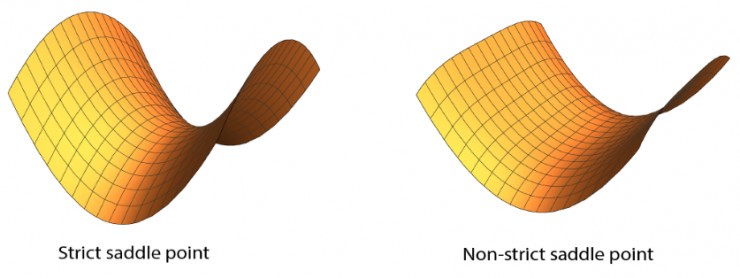
儘管非嚴格鞍點在谷底可以是平坦的,但是嚴格鞍點需要在至少一個方向上的曲率嚴格爲負。這樣的方向的存在則給基於梯度的算法逃離鞍點的可能性。一般來說,區分局部極小和非嚴格鞍點是NP-hard的;因此,我們,也包括之前這方面的學者們,都會把注意力放在逃離嚴格鞍點上。
形式上,我們就光滑度提出以下兩個標準假設:

傳統理論是通過限定迭代次數找到一階駐點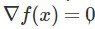 的速度,研究收斂至ϵ-一階駐點(
的速度,研究收斂至ϵ-一階駐點(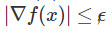 )的所需步數,我們的理論與之類似,即按照如下設定,規劃嚴格鞍點的逃離速度並隨後收斂到二階駐點
)的所需步數,我們的理論與之類似,即按照如下設定,規劃嚴格鞍點的逃離速度並隨後收斂到二階駐點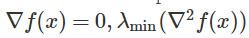 >=0,並找到ϵ-弱化版本所需步數。
>=0,並找到ϵ-弱化版本所需步數。
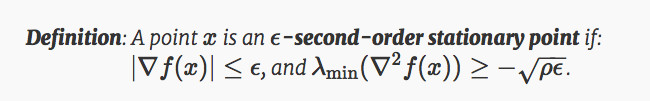
在這個定義中,ρ 是Hessian Lipschitz常數。這個定標是根據Nesterov and Polyak 2016公約設定的。
應用
在大多數的非凸問題中,已經證實所有的鞍點都是嚴格鞍點——這些非凸問題包括,但不僅限於principal components analysis, canonical correlation analysis, orthogonal tensor decomposition, phase retrieval, dictionary learning, matrix sensing, matrix completion等其他非凸低秩問題。
此外,在所有這些非凸問題中,所有的局部極小值事實上也是全局極小值。因此,在這種情況下,所有尋找-二階駐點的問題立即成爲解決這些非凸問題的全局保證。
使用微不足道的開銷避開鞍點
在經典的一階駐點情況下,GD具有很好的理論性質: 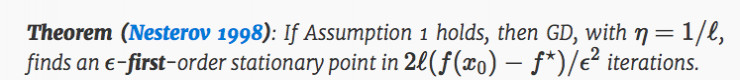
在這個定理中,x0是初始點,f⋆ 是全局極小值的函數。定理規定任何gradient-Lipschitz函數,任何駐點都可以通過GD在第O(1/ϵ2) 次獲得,不受d 的影響,這就是所謂的「自由尺寸優化」。對一個GD的成本計算爲 O(d),因此整體的運行時間爲 O(d)的階。 O(d)這樣線性scaling對現代高維非凸問題(比如深度學習)來說是非常重要的。
那麼,我們將同樣的方法應用到二階駐點的問題上。我們可以得到什麼樣的結論呢?我們是否也可以像之前一樣實現:
1. 一個無維數的迭代次數;
2. O(1/ϵ2)的收斂速度;
3. 對 ℓ 和 (f(x0)−f⋆)的依賴與Nesterov 1998中的結果相同;
結果是出人意料的,對這三個問題的答案都是Yes。 
主要定理中,O~(⋅) 只隱藏了對數因子;這邊對維度的依賴只有log4(d).。定理證明,在一個額外增加的Hessian-Lipschitz條件下,增加擾動的GD收斂到二階駐點的時間和GD收斂到一階駐點的時間幾乎是一樣的。因此,我們可以得出結論,PGD可以無消耗的逃離鞍點。
下面我們討論一下得出這個結論所必須的幾個關鍵點。
爲什麼polylog(d) 的迭代次數是足夠的?
我們關於嚴格鞍點的假設是,在最壞的情況下,逃離鞍點在d維度上只能沿着一個方向實現。一般的鞍點逃逸在梯度下降的方向上至少需要 poly(d)次迭代,那麼 polylog(d)次真的就足夠了嗎?
舉個簡單的例子,假設一個函數在鞍點附近是二次的。那麼目標函數假定爲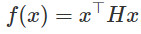 ,鞍點在0,且Hessian
,鞍點在0,且Hessian 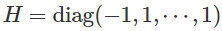 在這種情況下,只有第一個方向是逃離鞍點的方向(負特徵值-1)。
在這種情況下,只有第一個方向是逃離鞍點的方向(負特徵值-1)。
迭代次數的推導是很直接的:
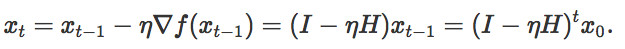
假設我們的起始點是0,那麼增加擾動後,從一個以0爲圓心半徑爲1的球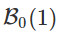 均勻的採樣。函數遞減可以表現爲:
均勻的採樣。函數遞減可以表現爲:
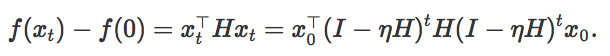
將迭代次數設置爲1/2,λi 將作爲Hessian H的第 i 個本徵值,並將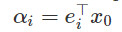 設置爲起始點x0在第i個方向上的參數。同時
設置爲起始點x0在第i個方向上的參數。同時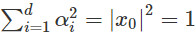 ,於是:
,於是:
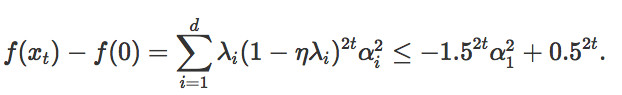
可以得出結論,如果要讓函數值減少一定常量,最多進行O(log d)次迭代。
一般Hessian的餅狀限制區域
我們可以得出這樣的結論:一個恆定的Hessian矩陣的情況下,只有當擾動處x0在集合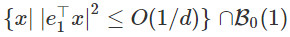 的情況下,我們纔會需要花費很長的時間避開鞍點。我們稱這個區域爲限制區域;在這種情況下,可以看見,這個區域是一個圓盤狀的。一般來說,當Hessian不再是一個恆定值時,限制區域也就不是一個圓盤狀的了,會像下方左圖中的一樣。這個區域很難用公式來表達。
的情況下,我們纔會需要花費很長的時間避開鞍點。我們稱這個區域爲限制區域;在這種情況下,可以看見,這個區域是一個圓盤狀的。一般來說,當Hessian不再是一個恆定值時,限制區域也就不是一個圓盤狀的了,會像下方左圖中的一樣。這個區域很難用公式來表達。
以前的學術分析試圖用一個平面集來逼近鞍點附近的動態範圍的限制區域。這需要非常小的步長和相應的非常大的運行時間和複雜度。我們的速度則非常快,這取決於一個關鍵的因素——雖然我們不知道限制區域的形狀,但是我們知道,這個限制區域很薄。 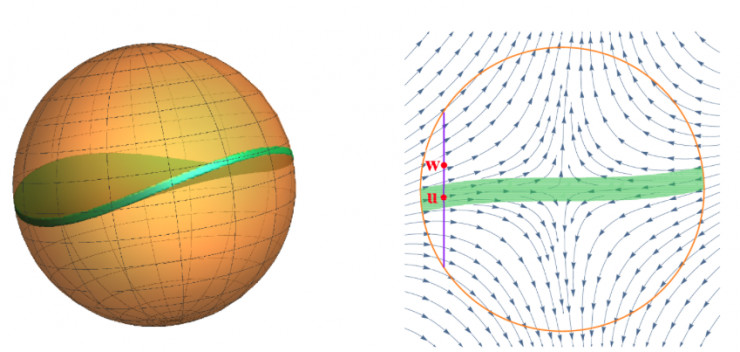
爲了量化這個「薄」的概念,我們假設兩個擾動參數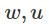 ,由
,由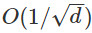 分離並且沿着逃離的方向。如果我們從
分離並且沿着逃離的方向。如果我們從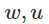 開始運行GD,至少有一個軌跡可以很快的脫離鞍點。這意味着限制區域的厚度最大爲
開始運行GD,至少有一個軌跡可以很快的脫離鞍點。這意味着限制區域的厚度最大爲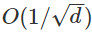 ,因此,隨機擾動落在限制區域內的機率是非常小的。
,因此,隨機擾動落在限制區域內的機率是非常小的。
增加擾動的必要性
以上我們已經討論了兩種方法來修改標準的梯度下降算法了,第一種是增加間歇性的擾動,第二種是依靠隨機初始化。雖然後者具備漸近收斂性,但是它需要耗費大量的時間和資源,犧牲了有效性;在近期與Simon Du,Jason Lee, Barnabas Poczos和Aarti Singh的合作中,我們已經展現出,儘管使用非常自然的隨機初始化方法和非病理函數,僅僅使用隨機初始化的GD會因爲鞍點大大降低效率,需要非常長的時間才能實現鞍點逃離。而PGD的表現卻非常不同,它一般可以在多項式的時間內逃離鞍點。
爲了更好的解釋這個結果,我們使用包括高斯(Gaussians)和均勻分佈的超立方體來進行隨機初始化,同時我們構建一個光滑的目標函數,滿足假設1和2。這個函數被設計成即使隨機初始化,在很大概率上GD和PGD在達到局部極小值之前都需要依次經過d範圍內的嚴格鞍點。所有的嚴格鞍點都只有一個逃逸方向(見下方左圖,d=2)
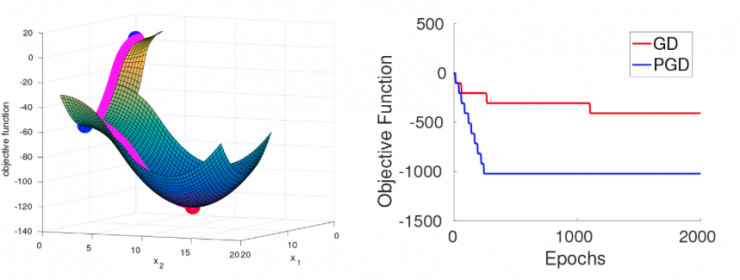
當GD在一系列鞍點附近移動時,它會越來越接近後面一個鞍點,因此需要越來越長的時間實現逃逸。逃逸的時間抽象爲:逃離第i個鞍點的時間爲。另一方面,PGD始終可以在很少的迭代時間內實現逃逸,不管之前的逃逸過程是怎麼樣的。這個過程在我們的實驗中得到了驗證,見上方右圖,d=10。
結論
在這篇文章中,我們證明了一個擾動形式的梯度下降可以收斂到二階駐點,其使用的時間與標準的梯度下降收斂到一階駐點的時間幾乎相同。這意味着,在有效地逃離鞍點的問題上,Hessian信息是不必要的。同時,這還解釋了在非凸問題上基本的GD和SGD表現的出奇的好的原因。這一新的收斂結果可以直接應用於非凸問題,如matrix sensing/completion來進行有效地全局收斂。
當然,在非凸優化領域,還存在着許多懸而未決的問題。舉幾個例子:加入動量會使收斂到一個二階駐點的速度提高?什麼類型的局部極小值可用,並且是否存在一些有用的結構性假設可以讓我們有效地應用在局部極小值上,從而避免局部極小值?在非凸優化問題上我們正在緩慢而穩步地取得這進展,在不久的將來,我們可以真正實現「科學」的跨越。
雷鋒網AI科技評論編譯