前言:眨眼間我們就從人工特徵、專家系統來到了自動特徵、深度學習的人工智能新時代,衆多開源測試數據集也大大降低了理論研究的門檻,直接加載數據集就可以開始模型訓練或者測試。然而面對實際問題時,收集到的數據往往不是像數據集中那樣整理好的,直接用來跑模型會帶來各種各樣的問題。這時候我們就開始回憶起「特徵工程」這一組容易被忽略但解決問題時不可或缺的硬功夫。

數據科學家 Dipanjan Sarkar 近日就發佈了兩篇長博客介紹了一些基本的特徵工程知識和技巧。這篇爲上篇,主要介紹連續型數值數據的特徵工程處理方法。我們全文編譯如下。
背景
「推動世界運轉的是錢」,不論你是否同意這句話,都不能忽視這個事實。以今天的數字化革命時代而言,更恰當的說法已經成了「推動世界運轉的是數據」。確實,無論數據的大小和規模,其已經成爲企業、公司和組織的頭等資產。任何智能系統不管其複雜度如何都需要由數據來驅動。在任何智能系統的核心模塊,我們都有一個或多個基於機器學習、深度學習或統計方法的算法,這些算法在一段時間內以數據爲原料收集知識,並提供智能見解。但算法本身非常樸素且不能在原始數據上直接得出結果。因此一個重要的任務就是需要從數據中設計出工程上有意義的特徵,即能被這些算法理解和使用的特徵。
平緩的機器學習進階路線
任何智能系統基本上是由一個端到端的流程組成,從數據原始數據開始,利用數據處理技術來加工、處理並從這些數據中設計出有意義的特徵和屬性。然後我們通常利用統計模型或機器學習模型在這些特徵上建模,如果未來要使用的話,就基於眼前要解決的問題部署模型。一個典型的標準的基於 CRISP-DM(注:跨行業數據挖掘標準流程)工業標準處理模型的機器學習流程描述如下。
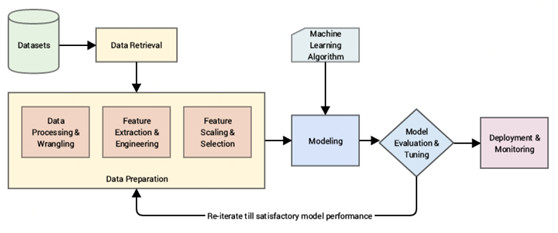
一個標準的機器學習系統流程圖(來源:Pratical Machine Learning with Python,Apress/Springer)
直接輸入原始數據並在這些數據基礎上直接建模很可能是魯莽的,因爲我們很可能不會得到期望的結果或性能,且算法不夠智能,不能自動地從原始數據中抽取有意義的特徵(雖然有一些某種程度上自動抽取特徵的技術,比如深度學習技術,後文我們會再談到)。
我們的主要關注領域放在數據準備方面,正如上圖中所指出的,我們先對數據做一些必要數據加工和處理,然後採用各種方法從原始數據中抽取有意義的屬性或特徵。
動機
特徵工程是構建任何智能系統的必要部分。即使你有了很多新的方法如深度學習和元啓發式方法來幫助你自動進行機器學習,但每個問題都是針對特定領域的,且更好的特徵(適合問題的)通常是系統性能的決定性因素。特徵工程是一門藝術也是一門科學,這就是爲什麼數據科學家在建模前通常花 70% 的時間用於準備數據。讓我們看看數據科學界領域裏一些名人關於特徵工程的言論。
「特徵處理是困難的、耗時的且需要專家知識。『實用化的機器學習』基本上就是特徵工程。」
—— 吳恩達
這些基本加強了我們先前提到的觀點:數據科學家將近 80% 的時間是用在困難且處理耗時的特徵工程上,其過程既需要領域知識又需要數學計算。
「特徵工程是將原始數據轉化特徵的過程,特徵要能更好地表示潛在問題並提高預測模型在未知數據上的準確率。」
—— Dr. Jason Brownlee
這讓我們瞭解到特徵工程是將數據轉換爲特徵的過程,特徵是機器學習模型的輸入,從而更高質量的特徵有助於提高整體模型的性能。特徵的好壞非常地取決於潛在的問題。因此,即使機器學習任務在不同場景中是相同的,比如將郵件分爲垃圾郵件或非垃圾郵件,或對手寫數字字符進行分類,這兩個場景中提取的特徵千差萬別。
來自華盛頓大學的 Pedro Domingos 教授,在這篇名爲《A Few Useful Things to Know about Machine Learning》中告訴我們。
「歸根到底,有的機器學習項目成功了, 有的失敗了。爲何如此不同呢?我們很容易想到,最重要的因素就是使用的特徵。」
—— Prof. Pedro Domingos
有可能啓發你的最後一句關於特徵工程的名言來自有名的 Kaggle 比賽選手 Xavier Conort。你們大部分人都知道 Kaggle 上通常會定期地放一些來自真實世界中的棘手的機器學習問題,一般對所有人開放。
「我們使用的算法對 Kaggle 賽手來說都是非常標準的。…我們花費大部分精力在特徵工程上。... 我們也非常小心地丟棄可能使模型過擬合的特徵。」
—— Xarvier Conort
理解特徵
一個特徵通常是來自原始數據的一種特定表示,它是一個單獨的、可度量的屬性,通常由數據集中的一列來描述。考慮到一個通用的二維數據集,每個樣本的觀測值用一行來表示,每種特徵用一列來表示,從而每個樣本的觀測值中的各種特徵都有一個具體的值。
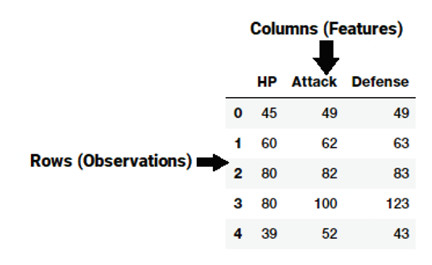
一個通用的數據集示意
這樣以來,正如上圖中例子所示,每行通常代表一個特徵向量,整個特徵集包括了所有的觀察值形成了二維的特徵矩陣,稱爲特徵集。這與代表二維數據的數據框或電子表格相似。機器學習算法通常都是處理這些數值型矩陣或張量,因此大部分特徵工程技術都將原始數據轉換爲一些數值型數來表示,使得它們能更好地被算法理解。
從數據集的角度出發,特徵可以分爲兩種主要的類型。一般地,原始特徵是直接從數據集中得到,沒有額外的操作或處理。導出特徵通常來自於特徵工程,即我們從現有數據屬性中提取的特徵。一個簡單的例子是從一個包含出生日期的僱員數據集中創建一個新的「年齡」特徵,只需要將當前日期減去出生日期即可。
數據的類型和格式各不相同,包括結構化的和非結構化的數據。在這篇文章中,我們將討論各種用來處理結構化的連續型數值數據的特徵工程策略。所有的這些例子都是我最近一本書中的一部分《Pratical Mahine Learning with Python》,你可以訪問這篇文章中使用的相關的數據集和代碼,它們放在 GitHub 上。在此着重感謝 Gabriel Moreira ,他在特徵工程技術上提供了一些優雅的指針,給了我很大幫助。
數值型數據上的特徵工程
數值型數據通常以標量的形式表示數據,描述觀測值、記錄或者測量值。本文的數值型數據是指連續型數據而不是離散型數據,表示不同類目的數據就是後者。數值型數據也可以用向量來表示,向量的每個值或分量代表一個特徵。整數和浮點數是連續型數值數據中最常見也是最常使用的數值型數據類型。即使數值型數據可以直接輸入到機器學習模型中,你仍需要在建模前設計與場景、問題和領域相關的特徵。因此仍需要特徵工程。讓我們利用 python 來看看在數值型數據上做特徵工程的一些策略。我們首先加載下面一些必要的依賴(通常在 Jupyter botebook 上)。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as spstats
%matplotlib inline
原始度量
正如我們先前提到的,根據上下文和數據的格式,原始數值型數據通常可直接輸入到機器學習模型中。原始的度量方法通常用數值型變量來直接表示爲特徵,而不需要任何形式的變換或特徵工程。通常這些特徵可以表示一些值或總數。讓我們加載四個數據集之一的 Pokemon 數據集,該數據集也在 Kaggle 上公佈了。
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8')
poke_df.head()
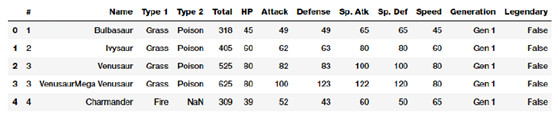
我們的Pokemon數據集截圖
Pokemon 是一個大型多媒體遊戲,包含了各種口袋妖怪(Pokemon)角色。簡而言之,你可以認爲他們是帶有超能力的動物!這些數據集由這些口袋妖怪角色構成,每個角色帶有各種統計信息。
數值
如果你仔細地觀察上圖中這些數據,你會看到幾個代表數值型原始值的屬性,它可以被直接使用。下面的這行代碼挑出了其中一些重點特徵。
poke_df[['HP', 'Attack', 'Defense']].head()
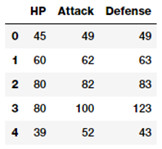
帶(連續型)數值數據的特徵
這樣,你可以直接將這些屬性作爲特徵,如上圖所示。這些特徵包括 Pokemon 的 HP(血量),Attack (攻擊)和 Defense(防禦)狀態。事實上,我們也可以基於這些字段計算出一些基本的統計量。
poke_df[['HP', 'Attack', 'Defense']].describe()
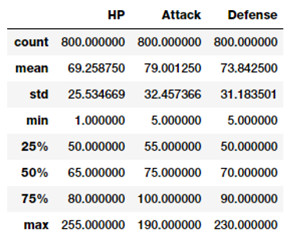
數值特徵形式的基本描述性統計量
這樣你就對特徵中的統計量如總數、平均值、標準差和四分位數有了一個很好的印象。
記數
原始度量的另一種形式包括代表頻率、總數或特徵屬性發生次數的特徵。讓我們看看 millionsong 數據集中的一個例子,其描述了某一歌曲被各種用戶收聽的總數或頻數。
popsong_df = pd.read_csv('datasets/song_views.csv',encoding='utf-8')
popsong_df.head(10)
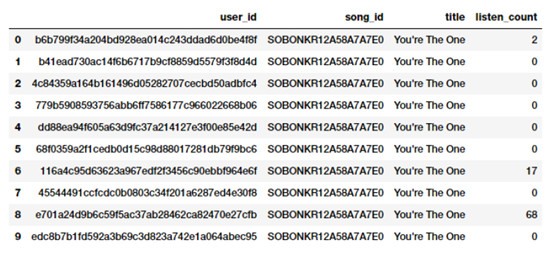
數值特徵形式的歌曲收聽總數
根據這張截圖,顯而易見 listen_count 字段可以直接作爲基於數值型特徵的頻數或總數。
二值化
基於要解決的問題構建模型時,通常原始頻數或總數可能與此不相關。比如如果我要建立一個推薦系統用來推薦歌曲,我只希望知道一個人是否感興趣或是否聽過某歌曲。我不需要知道一首歌被聽過的次數,因爲我更關心的是一個人所聽過的各種各樣的歌曲。在這個例子中,二值化的特徵比基於計數的特徵更合適。我們二值化 listen_count 字段如下。
watched = np.array(popsong_df['listen_count'])
watched[watched >= 1] = 1
popsong_df['watched'] = watched
你也可以使用 scikit-learn 中 preprocessing 模塊的 Binarizer 類來執行同樣的任務,而不一定使用 numpy 數組。
from sklearn.preprocessing import Binarizer
bn = Binarizer(threshold=0.9)
pd_watched =bn.transform([popsong_df['listen_count']])[0]
popsong_df['pd_watched'] = pd_watched
popsong_df.head(11)
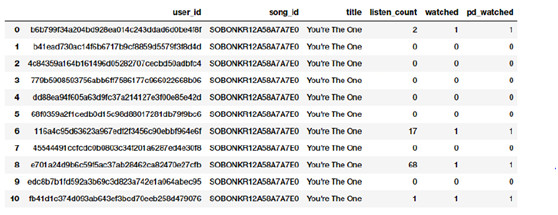
歌曲收聽總數的二值化結構
你可以從上面的截圖中清楚地看到,兩個方法得到了相同的結果。因此我們得到了一個二值化的特徵來表示一首歌是否被每個用戶聽過,並且可以在相關的模型中使用它。
數據舍入
處理連續型數值屬性如比例或百分比時,我們通常不需要高精度的原始數值。因此通常有必要將這些高精度的百分比舍入爲整數型數值。這些整數可以直接作爲原始數值甚至分類型特徵(基於離散類的)使用。讓我們試着將這個觀念應用到一個虛擬數據集上,該數據集描述了庫存項和他們的流行度百分比。
items_popularity =pd.read_csv('datasets/item_popularity.csv',encoding='utf-8')
items_popularity['popularity_scale_10'] = np.array(np.round((items_popularity['pop_percent'] * 10)),dtype='int')
items_popularity['popularity_scale_100'] = np.array(np.round((items_popularity['pop_percent'] * 100)),dtype='int')
items_popularity
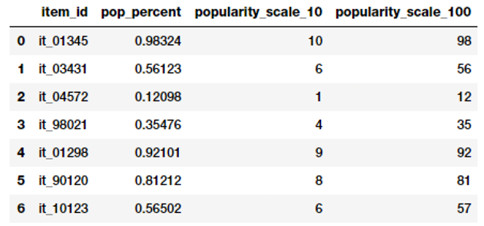
不同尺度下流行度舍入結果
基於上面的輸出,你可能猜到我們試了兩種不同的舍入方式。這些特徵表明項目流行度的特徵現在既有 1-10 的尺度也有 1-100 的尺度。基於這個場景或問題你可以使用這些值同時作爲數值型或分類型特徵。
相關性
高級機器學習模型通常會對作爲輸入特徵變量函數的輸出響應建模(離散類別或連續數值)。例如,一個簡單的線性迴歸方程可以表示爲
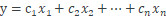
其中輸入特徵用變量表示爲
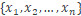
權重或係數可以分別表示爲
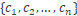
目標是預測響應 y.
在這個例子中,僅僅根據單個的、分離的輸入特徵,這個簡單的線性模型描述了輸出與輸入之間的關係。
然而,在一些真實場景中,有必要試着捕獲這些輸入特徵集一部分的特徵變量之間的相關性。上述帶有相關特徵的線性迴歸方程的展開式可以簡單表示爲
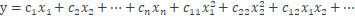
此處特徵可表示爲
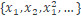
表示了相關特徵。現在讓我們試着在 Pokemon 數據集上設計一些相關特徵。
atk_def = poke_df[['Attack', 'Defense']]
atk_def.head()
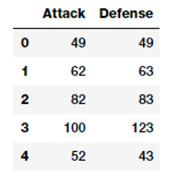
從輸出數據框中,我們可以看到我們有兩個數值型(連續的)特徵,Attack 和 Defence。現在我們可以利用 scikit-learn 建立二度特徵。
pf = PolynomialFeatures(degree=2,
interaction_only=False,include_bias=False)
res = pf.fit_transform(atk_def)
res
Output
------
array([[ 49., 49., 2401., 2401., 2401.],
[ 62., 63., 3844., 3906., 3969.],
[ 82., 83., 6724., 6806., 6889.],
...,
[ 110., 60., 12100., 6600., 3600.],
[ 160., 60., 25600., 9600., 3600.],
[ 110., 120., 12100., 13200., 14400.]])
上面的特徵矩陣一共描述了 5 個特徵,其中包括新的相關特徵。我們可以看到上述矩陣中每個特徵的度,如下所示。
pd.DataFrame(pf.powers_, columns=['Attack_degree','Defense_degree'])
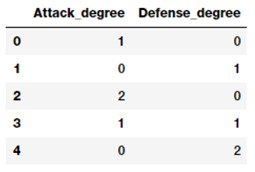
基於這個輸出,現在我們可以通過每個特徵的度知道它實際上代表什麼。在此基礎上,現在我們可以對每個特徵進行命名如下。這僅僅是爲了便於理解,你可以給這些特徵取更好的、容易使用和簡單的名字。
intr_features = pd.DataFrame(res, columns=['Attack','Defense','Attack^2','Attack x Defense','Defense^2'])
intr_features.head(5)
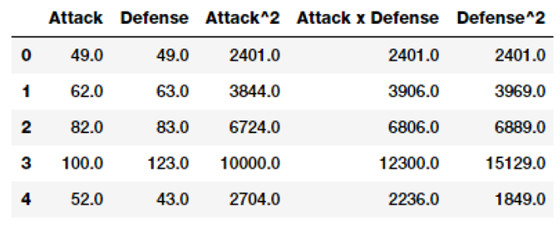
數值型特徵及其相關特徵
因此上述數據代表了我們原始的特徵以及它們的相關特徵。
分區間處理數據
處理原始、連續的數值型特徵問題通常會導致這些特徵值的分佈被破壞。這表明有些值經常出現而另一些值出現非常少。除此之外,另一個問題是這些特徵的值的變化範圍。比如某個音樂視頻的觀看總數會非常大(Despacito,說你呢)而一些值會非常小。直接使用這些特徵會產生很多問題,反而會影響模型表現。因此出現了處理這些問題的技巧,包括分區間法和變換。
分區間(Bining),也叫做量化,用於將連續型數值特徵轉換爲離散型特徵(類別)。可以認爲這些離散值或數字是類別或原始的連續型數值被分區間或分組之後的數目。每個不同的區間大小代表某種密度,因此一個特定範圍的連續型數值會落在裏面。對數據做分區間的具體技巧包括等寬分區間以及自適應分區間。我們使用從 2016 年 FreeCodeCamp 開發者和編碼員調查報告中抽取出來的一個子集中的數據,來討論各種針對編碼員和軟件開發者的屬性。
fcc_survey_df =pd.read_csv('datasets/fcc_2016_coder_survey_subset.csv',encoding='utf-8')
fcc_survey_df[['ID.x', 'EmploymentField', 'Age','Income']].head()
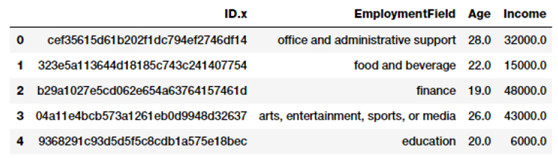
來自FCC編碼員調查數據集的樣本屬性
對於每個參加調查的編碼員或開發者,ID.x 變量基本上是一個唯一的標識符而其他字段是可自我解釋的。
等寬分區間
就像名字表明的那樣,在等寬分區間方法中,每個區間都是固定寬度的,通常可以預先分析數據進行定義。基於一些領域知識、規則或約束,每個區間有個預先固定的值的範圍,只有處於範圍內的數值才被分配到該區間。基於數據舍入操作的分區間是一種方式,你可以使用數據舍入操作來對原始值進行分區間,我們前面已經講過。
現在我們分析編碼員調查報告數據集的 Age 特徵並看看它的分佈。
fig, ax = plt.subplots()
fcc_survey_df['Age'].hist(color='#A9C5D3',edgecolor='black',grid=False)
ax.set_title('Developer Age Histogram', fontsize=12)
ax.set_xlabel('Age', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
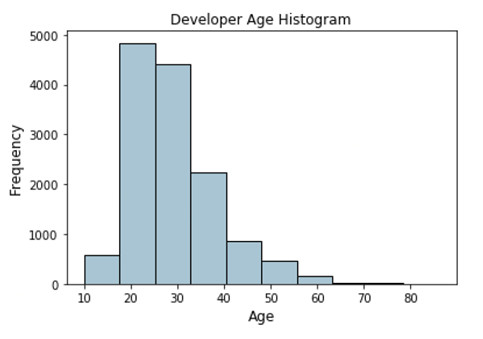
描述開發者年齡分佈的直方圖
上面的直方圖表明,如預期那樣,開發者年齡分佈彷彿往左側傾斜(上年紀的開發者偏少)。現在我們根據下面的模式,將這些原始年齡值分配到特定的區間。
Age Range: Bin
---------------
0 - 9 : 0
10 - 19 : 1
20 - 29 : 2
30 - 39 : 3
40 - 49 : 4
50 - 59 : 5
60 - 69 : 6
... and so on
我們可以簡單地使用我們先前學習到的數據舍入部分知識,先將這些原始年齡值除以 10,然後通過 floor 函數對原始年齡數值進行截斷。
fcc_survey_df['Age_bin_round'] = np.array(np.floor(np.array(fcc_survey_df['Age']) / 10.))
fcc_survey_df[['ID.x', 'Age','Age_bin_round']].iloc[1071:1076]
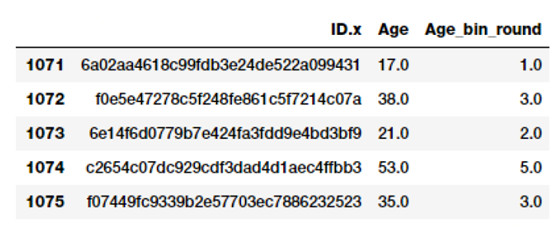
通過舍入法分區間
你可以看到基於數據舍入操作的每個年齡對應的區間。但是如果我們需要更靈活的操作怎麼辦?如果我們想基於我們的規則或邏輯,確定或修改區間的寬度怎麼辦?基於常用範圍的分區間方法將幫助我們完成這個。讓我們來定義一些通用年齡段位,使用下面的方式來對開發者年齡分區間。
Age Range : Bin
---------------
0 - 15 : 1
16 - 30 : 2
31 - 45 : 3
46 - 60 : 4
61 - 75 : 5
75 - 100 : 6
基於這些常用的分區間方式,我們現在可以對每個開發者年齡值的區間打標籤,我們將存儲區間的範圍和相應的標籤。
bin_ranges = [0, 15, 30, 45, 60, 75, 100]
bin_names = [1, 2, 3, 4, 5, 6]
fcc_survey_df['Age_bin_custom_range'] = pd.cut(np.array(fcc_survey_df['Age']),bins=bin_ranges)
fcc_survey_df['Age_bin_custom_label'] = pd.cut(np.array(fcc_survey_df['Age']),bins=bin_ranges, labels=bin_names)
# view the binned features
fcc_survey_df[['ID.x', 'Age', 'Age_bin_round','Age_bin_custom_range','Age_bin_custom_label']].iloc[10a71:1076]
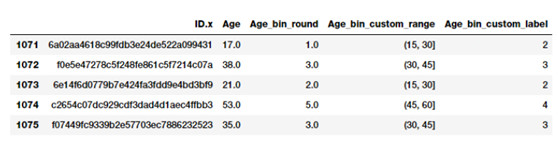
開發者年齡的常用分區間方式
自適應分區間
使用等寬分區間的不足之處在於,我們手動決定了區間的值範圍,而由於落在某個區間中的數據點或值的數目是不均勻的,因此可能會得到不規則的區間。一些區間中的數據可能會非常的密集,一些區間會非常稀疏甚至是空的!自適應分區間方法是一個更安全的策略,在這些場景中,我們讓數據自己說話!這樣,我們使用數據分佈來決定區間的範圍。
基於分位數的分區間方法是自適應分箱方法中一個很好的技巧。量化對於特定值或切點有助於將特定數值域的連續值分佈劃分爲離散的互相挨着的區間。因此 q 分位數有助於將數值屬性劃分爲 q 個相等的部分。關於量化比較流行的例子包括 2 分位數,也叫中值,將數據分佈劃分爲2個相等的區間;4 分位數,也簡稱分位數,它將數據劃分爲 4 個相等的區間;以及 10 分位數,也叫十分位數,創建 10 個相等寬度的區間,現在讓我們看看開發者數據集的 Income 字段的數據分佈。
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',edgecolor='black',grid=False)
ax.set_title('Developer Income Histogram',fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
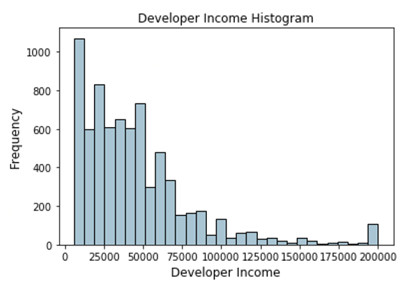
描述開發者收入分佈的直方圖
上述的分佈描述了一個在收入上右歪斜的分佈,少數人賺更多的錢,多數人賺更少的錢。讓我們基於自適應分箱方式做一個 4-分位數或分位數。我們可以很容易地得到如下的分位數。
quantile_list = [0, .25, .5, .75, 1.]
quantiles =
fcc_survey_df['Income'].quantile(quantile_list)
quantiles
Output
------
0.00 6000.0
0.25 20000.0
0.50 37000.0
0.75 60000.0
1.00 200000.0
Name: Income, dtype: float64
現在讓我們在原始的分佈直方圖中可視化下這些分位數。
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',edgecolor='black',grid=False)
for quantile in quantiles:
qvl = plt.axvline(quantile, color='r')
ax.legend([qvl], ['Quantiles'], fontsize=10)
ax.set_title('Developer Income Histogram with Quantiles',fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
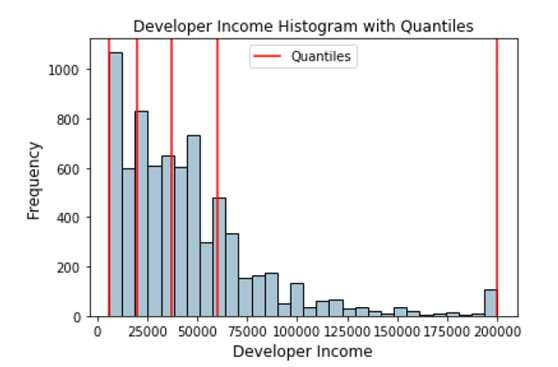
帶分位數形式描述開發者收入分佈的直方圖
上面描述的分佈中紅色線代表了分位數值和我們潛在的區間。讓我們利用這些知識來構建我們基於分區間策略的分位數。
quantile_labels = ['0-25Q', '25-50Q', '50-75Q', '75-100Q']
fcc_survey_df['Income_quantile_range'] = pd.qcut(
fcc_survey_df['Income'],q=quantile_list)
fcc_survey_df['Income_quantile_label'] = pd.qcut(
fcc_survey_df['Income'],q=quantile_list,labels=quantile_labels)
fcc_survey_df[['ID.x', 'Age', 'Income','Income_quantile_range',
'Income_quantile_label']].iloc[4:9]
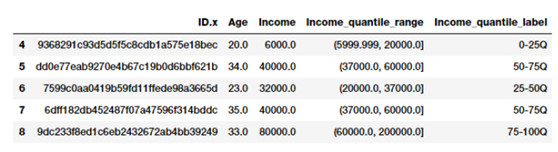
基於分位數的開發者收入的區間範圍和標籤
通過這個例子,你應該對如何做基於分位數的自適應分區間法有了一個很好的認識。一個需要重點記住的是,分區間的結果是離散值類型的分類特徵,當你在模型中使用分類數據之前,可能需要額外的特徵工程相關步驟。我們將在接下來的部分簡要地講述分類數據的特徵工程技巧。
統計變換
我們討論下先前簡單提到過的數據分佈傾斜的負面影響。現在我們可以考慮另一個特徵工程技巧,即利用統計或數學變換。我們試試看 Log 變換和 Box-Cox 變換。這兩種變換函數都屬於冪變換函數簇,通常用來創建單調的數據變換。它們的主要作用在於它能幫助穩定方差,始終保持分佈接近於正態分佈並使得數據與分佈的平均值無關。
Log變換
log 變換屬於冪變換函數簇。該函數用數學表達式表示爲
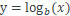
讀爲以 b 爲底 x 的對數等於 y。這可以變換爲
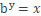
表示以b爲底指數必須達到多少纔等於x。自然對數使用 b=e,e=2.71828,通常叫作歐拉常數。你可以使用通常在十進制系統中使用的 b=10 作爲底數。
當應用於傾斜分佈時 Log 變換是很有用的,因爲他們傾向於拉伸那些落在較低的幅度範圍內自變量值的範圍,傾向於壓縮或減少更高幅度範圍內的自變量值的範圍。從而使得傾斜分佈儘可能的接近正態分佈。讓我們對先前使用的開發者數據集的 Income 特徵上使用log變換。
fcc_survey_df['Income_log'] = np.log((1+fcc_survey_df['Income']))
fcc_survey_df[['ID.x', 'Age', 'Income','Income_log']].iloc[4:9]
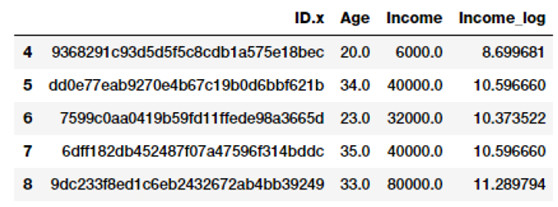
開發者收入log變換後結構
Income_log 字段描述了經過 log 變換後的特徵。現在讓我們來看看字段變換後數據的分佈。
基於上面的圖,我們可以清楚地看到與先前傾斜分佈相比,該分佈更加像正態分佈或高斯分佈。
income_log_mean =np.round(np.mean(fcc_survey_df['Income_log']), 2)
fig, ax = plt.subplots()
fcc_survey_df['Income_log'].hist(bins=30,color='#A9C5D3',edgecolor='black',grid=False)
plt.axvline(income_log_mean, color='r')
ax.set_title('Developer Income Histogram after Log Transform',fontsize=12)
ax.set_xlabel('Developer Income (log scale)',fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(11.5, 450, r'$\mu$='+str(income_log_mean),fontsize=10)
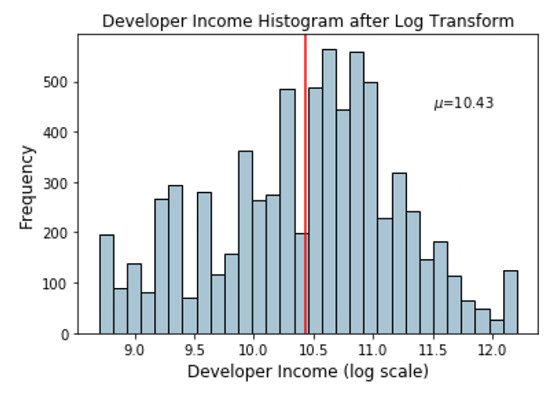
經過log變換後描述開發者收入分佈的直方圖
Box-Cox變換
Box-Cox 變換是另一個流行的冪變換函數簇中的一個函數。該函數有一個前提條件,即數值型值必須先變換爲正數(與 log 變換所要求的一樣)。萬一出現數值是負的,使用一個常數對數值進行偏移是有幫助的。數學上,Box-Cox 變換函數可以表示如下。
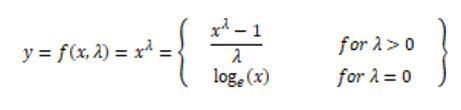
生成的變換後的輸出y是輸入 x 和變換參數的函數;當 λ=0 時,該變換就是自然對數 log 變換,前面我們已經提到過了。λ 的最佳取值通常由最大似然或最大對數似然確定。現在讓我們在開發者數據集的收入特徵上應用 Box-Cox 變換。首先我們從數據分佈中移除非零值得到最佳的值,結果如下。
income = np.array(fcc_survey_df['Income'])
income_clean = income[~np.isnan(income)]
l, opt_lambda = spstats.boxcox(income_clean)
print('Optimal lambda value:', opt_lambda)
Output
------
Optimal lambda value: 0.117991239456
現在我們得到了最佳的值,讓我們在取值爲 0 和 λ(最佳取值 λ )時使用 Box-Cox 變換對開發者收入特徵進行變換。
fcc_survey_df['Income_boxcox_lambda_0'] = spstats.boxcox((1+fcc_survey_df['Income']),lmbda=0)
fcc_survey_df['Income_boxcox_lambda_opt'] = spstats.boxcox(fcc_survey_df['Income'],lmbda=opt_lambda)
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_log','Income_boxcox_lambda_0','Income_boxcox_lambda_opt']].iloc[4:9]
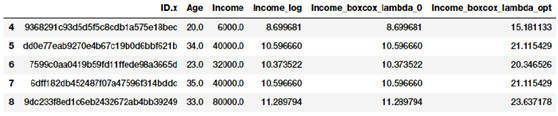
經過 Box-Cox 變換後開發者的收入分佈
變換後的特徵在上述數據框中描述了。就像我們期望的那樣,Income_log 和 Income_boxcox_lamba_0 具有相同的取值。讓我們看看經過最佳λ變換後 Income 特徵的分佈。
income_boxcox_mean = np.round(np.mean(fcc_survey_df['Income_boxcox_lambda_opt']),2)
fig, ax = plt.subplots()
fcc_survey_df['Income_boxcox_lambda_opt'].hist(bins=30,
color='#A9C5D3',edgecolor='black', grid=False)
plt.axvline(income_boxcox_mean, color='r')
ax.set_title('Developer Income Histogram after Box–Cox Transform',fontsize=12)
ax.set_xlabel('Developer Income (Box–Cox transform)',fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(24, 450, r'$\mu$='+str(income_boxcox_mean),fontsize=10)
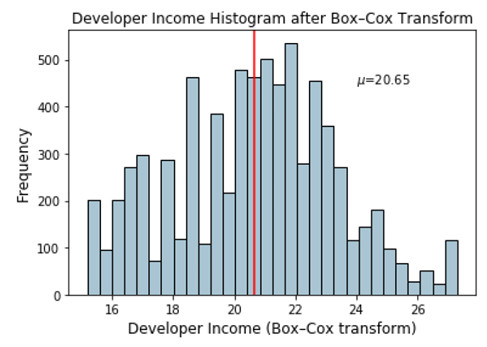
經過Box-Cox變換後描述開發者收入分佈的直方圖
分佈看起來更像是正態分佈,與我們經過 log 變換後的分佈相似。
結論
特徵工程是機器學習和數據科學中的一個重要方面,永遠都不應該被忽視。雖然我們也有自動的機器學習框架,如 AutoML(但該框架也強調了它需要好的特徵才能跑出好的效果!)。特徵工程永不過時,即使對於自動化方法,其中也有一部分經常需要根據數據類型、領域和要解決的問題而設計特殊的特徵。
這篇文章中我們討論了在連續型數值數據上特徵工程的常用策略。在接下來的部分,我們將討論處理離散、分類數據的常用策略,在後續章節中會提到非結構化類型數據的處理策略。敬請關注!
這篇文章中使用的所有的代碼和數據集都可以從 GitHub 上訪問。
代碼也以 Jupyter notebook 的形式提供了。
via:Understanding Feature Engineering (Part-1)
相關文章:
Kaggle16000份問卷揭示數據科學家平均畫像:30歲,碩士學位,年薪36萬