論文:Multimodal Unsupervised Image-to-Image Translation

論文地址:https://arxiv.org/pdf/1804.04732.pdf
摘要:無監督 Image-to-Image 變換是計算機視覺領域一個重要而富有挑戰的問題:給定源域(source domain)中的一張圖像,需要在沒有任何配對圖像數據的情況下,學習出目標域(target domain)中其對應圖像的條件分佈。雖然條件分佈是多模態的,但現有方法都引入了過於簡化的假設,而將其作爲一個確定性的一對一映射。因此,這些模型都無法在特定的源域圖像中生成富有多樣性的輸出結果。爲突破這一限制,我們提出了多模態無監督 Image-to-Image 變換(Multimodal Unsupervised Image-to-image Translation,MUNT)框架。我們假設,圖像表徵可以分解爲一個具有域不變性(domain-invariant)的內容碼(content code)和一個能刻畫域特有性質的風格碼(style code)。爲了將圖像轉化到另一個域中,我們將:1. 原圖像的內容碼,2. 從目標域中隨機抽取的某個風格碼 進行重組。(在下文中)我們分析了 MUNT 框架,並建立了相應的理論結果。我們進行了大量實驗,將 MUNT 與其他目前最先進方的法進行了比較,結果進一步展現出了 MUNT 的優越性。最後,通過引入一個風格圖像(style image)樣例,使用者可以利用 MUNT 來控制轉化的輸出風格。
預訓練模型及相關代碼可在這裏查看:https://github.com/nvlabs/MUNIT
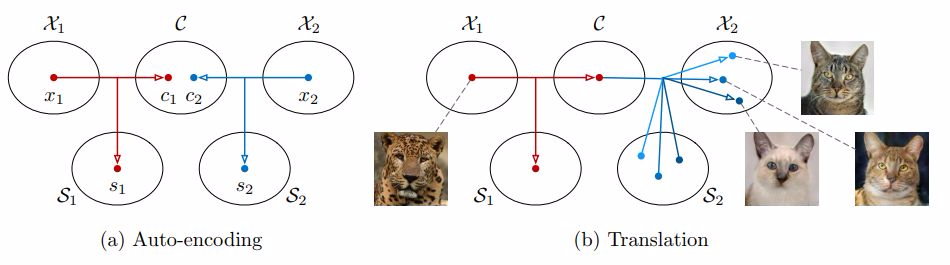
圖 1. 方法演示。(a)各個域 Xi 中圖像的編碼形式爲:共享目標空間 C 和域特有的風格空間 Si。每個編碼器都有對應的反編碼器(未在圖中展示)。(b)爲了將某個 X1 中的圖像(如獵豹)變換到 X2 中(如家貓),我們將輸入圖像的內容碼和目標風格空間中的某個隨機風格碼進行重組。不同的風格碼會得到不同的輸出。
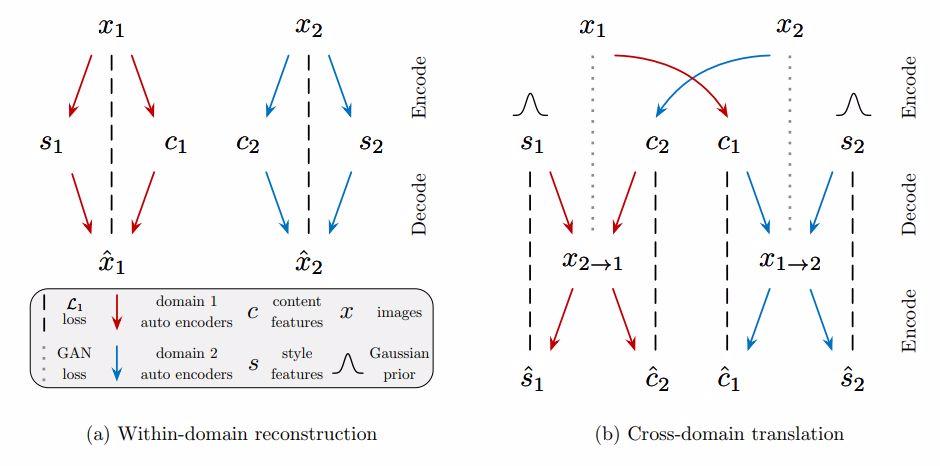
圖 2. 模型概述。我們的 Image-to-Image 轉化模型(MUNT)由分別各屬於一個域的兩個自編碼器組成(在圖中分別用紅色和藍色箭頭表示),每個自編碼器的隱編碼由一個內容碼 c 和一個風格碼 s 構成。我們利用對抗目標(adversarial objectives)(圖中點線)和雙向重建目標(bidirectional reconstruction objectives)(圖中短線)訓練模型,其中對抗目標能保證轉化的圖像和目標域中真實圖像難以區分,雙向重建目標則用於同時重建圖像和隱編碼。
實驗
實現細節
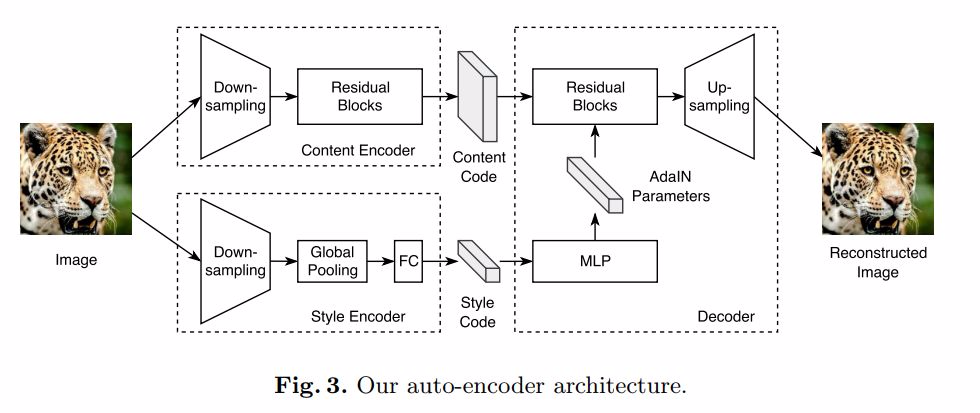
圖 3. 自編碼器架構展示:由一個內容編碼器、一個風格編碼器和一個聯合解碼器組成。更詳細的信息和相關超參數在附錄中。我們提供了 PyTorch 下的開源實現
內容編碼器:由多個用於對輸入降低採樣的 Strided Convulsion 層和多個進一步處理輸入的 Residual Block 組成,其中所有的 Convulsion 層都進行了 Instance Normalization 處理。
風格編碼器:由多個 Strided Convulsion 層、一個全局的 Average Pooling 層和一個全連接(Fully Connected)層組成。在這裏我們沒有使用 IN 層,因爲 IN 會去除原始特徵的均值和方差,而很多重要的風格信息都包含在其中。
解碼器:我們的解碼器根據輸入圖像的內容碼和風格碼對其實現了重建。解碼器通過一組 Residual Blocks 處理內容碼,並最終利用多個上採樣和 Convulsion 層來生成重建圖像。另外,最近有研究通過在 normalization 層中使用仿射變換(Affine Transformation)來表徵風格。受其啓發,我們在 Residual Block 中引入了自適應實例標準化(Adaptive Instance Normalization,AdaIN)層,AdaIN 層中的參數可以利用多層感知器(MLP)在風格碼上動態生成:
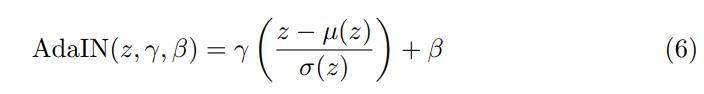
其中 z 是前一個卷積層產生的激活(Activation),µ 和 σ分別表示各個通道的均值和標準差,γ 和 β是 MLP 從風格碼中生成的參數。注意:這裏的仿射參數是通過訓練出的神經網絡生成的,而不是像 Huang et al. [53] 研究中一樣,根據預訓練的神經網絡的統計量計算得到的。
判別器:我們使用了 Mao et al. [38] 所提出的 LSGAN 目標,並利用 Wang et al. [20] 提出的多尺度判別器,來確保生成器同時生成了真實細節和正確的全局結構。
具有域不變性的感知損失(perceptual loss):通常,以輸出圖像和參考圖像在 VGG [74] 特徵空間中的距離作爲感知損失,在有配對圖像的監督數據中,這種方法已被證明可以有效地幫助 Image-to-Image 變換;但在無監督場景下,我們並沒有目標域中的參考圖像。爲此,我們提出了一個具有更強的域不變性的修正感知損失,進而可以將輸入圖像作爲參考圖像。具體而言,在計算距離前,我們利用 Instance Normalization 處理了 VGG 特徵 [70](沒有使用仿射變換),去除了原始特徵中包含大量域特定信息的均值和方差 [53,57]。我們發現,修正後的感知損失能夠加速高分辨率(≥ 512 × 512)數據集上的訓練過程,因此在這些數據集上,我們使用的是這一修正感知損失。

圖 4. 線圖→鞋子變換的定性比較。第一列展示了輸入和對應輸出的真實圖像。第二列開始每一列展示從某種方法中得到的 3 個隨機的輸出結果。
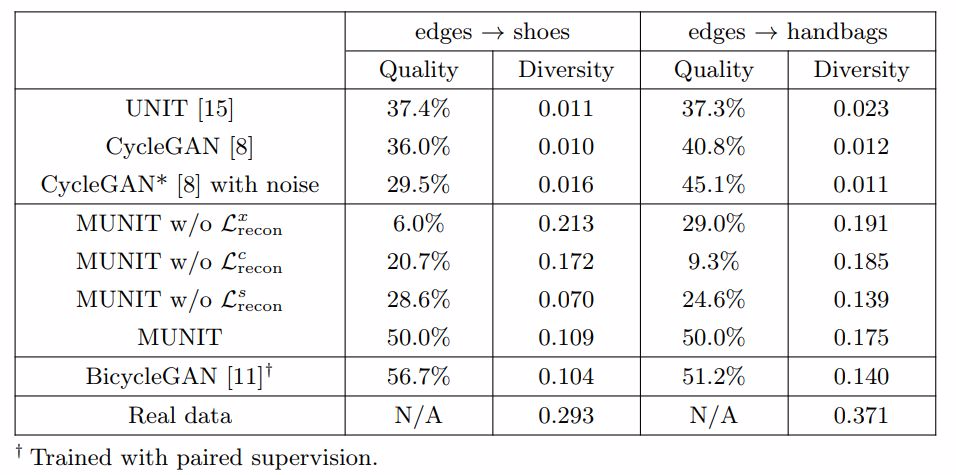
表 1. 線圖→鞋子/手提包變換的定量分析。多樣性得分使用的是 LPIPS 距離均值,質量評分使用的是「人類偏好得分」:人們相較於 MUNIT 更偏好該方法的百分比。兩個指標中,都是數值越高表現越好。

圖 5. 例:(a)線圖↔鞋子(b)線圖↔手提包

圖 6. 例:動物圖像變換結果
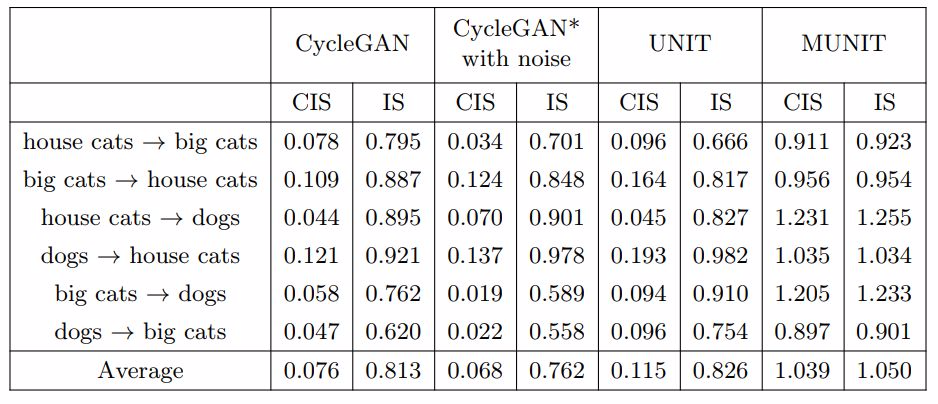
表 2. 動物圖像變換的定量分析。這個數據集中共包含 3 個域,我們在任意兩個域對之間完成雙向變換,共 6 個變換目標。在每個目標上使用 CIS 和 IS 來度量表現效果。

圖 7. 示例:街景變換結果

圖 8. 示例:約塞米蒂國家公園的夏天↔冬天(HD 分辨率)

圖 9. 示例:有引導圖像變換。其中每一行內容相同,每一列風格相同

圖 10. 現有風格變換方法的比較
結論
我們展示了一個多模態無監督 Image-to-Image 變換框架,我們的模型在(輸出圖像的)質量和多樣性上都超過了現有的無監督方法,達到了和如今最先進的監督方法相當的結果。我們下一階段的研究方向會是將這一框架推廣到其他域,如影像、文本中。