共面性檢測網絡爲解決這一問題提供了新的思路,並能夠顯著提升三維場景重建的質量。目前這項研究工作已被歐洲計算機視覺大會 (ECCV 2018) 收錄,並被邀請赴會進行口頭報告 (Oral Presentation)。
這項研究工作的完成者包括:國防科技大學-普林斯頓大學聯合培養博士施逸飛,國防科技大學副教授、普林斯頓大學訪問學者徐凱,慕尼黑工業大學教授 Matthias Niessner,普林斯頓大學教授 Szymon Rusinkiewicz,普林斯頓大學教授 Thomas Funkhouser。
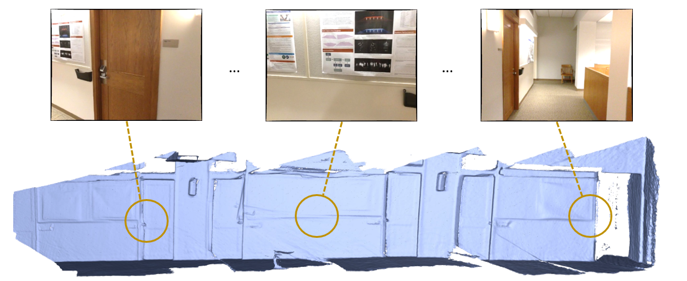 圖 1 三維場景重建
圖 1 三維場景重建
所謂三維場景重建,就是利用輸入的二維圖像數據恢復場景的三維結構。三維重建在多個領域有着廣泛的應用,例如,室內環境設計、增強現實、機器人導航與場景理解。近些年來,隨着消費者級別的深度攝像機日益成熟,使用手持式深度攝像機 (例如 Kinect, structure sensor) 獲取室內場景的深度數據,再使用特定算法對不同角度拍攝到的數據進行融合,成爲了三維場景重建的研究熱點。而這當中最難的問題無疑是確定每一個時刻相機在三維空間中的位置。爲了實現這一目標,算法必須對從不同角度拍攝的圖片進行配準。
在此之前,傳統方法往往通過檢測不同圖片中的共同特徵點來實現圖片配準。但是由於圖片曝光不統一、相機運動太快導致圖像模糊等因素,關鍵點的檢測和特徵計算差強人意,基於特徵點的配准算法有很強的侷限性。
爲了解決這一問題,人們開始嘗試利用較特徵點更大的幾何體來提高三維場景重建的精度。過去的五年裏,這方面的研究工作大多集中於利用平面的共面性對配準結果進行優化矯正。以 CVPR 2017 文章 [1] 中的方法爲例,該方法首先利用 SIFT 特徵點實現初步配準,然後通過將近似共面平面矯正成完全共面平面來優化相機位置。這種遞進式的優化方法雖然能夠在一定程度上提高三維場景重建精度,但是卻嚴重依賴於對相機位姿的初始估計。當初始位姿誤差很大的時候,該方法無法正確檢測幀間的共面平面,從而帶來巨大的重建誤差。那麼,如何才能更好地利用平面提高三維重建精度呢?
 圖 2 平面共面性預測
圖 2 平面共面性預測
「我們注意到,人類在判斷兩個平面是否共面時並不需要估計相機的位姿。爲了解決上述問題,一個很直接的想法是讓機器具有像人類一樣對共面性進行判斷的能力。我們提出使用深度網絡預測不同幀中的兩個平面是否共面,這在三維重建領域尚屬首次。」論文的第一作者施逸飛這樣介紹這項工作。「人類在做這種判斷時,既會觀察兩個平面的紋理顏色是否一致,也會考慮平面的語義信息。例如,假設我知道兩個平面都是地面,那麼它們極有可能是共面的。」
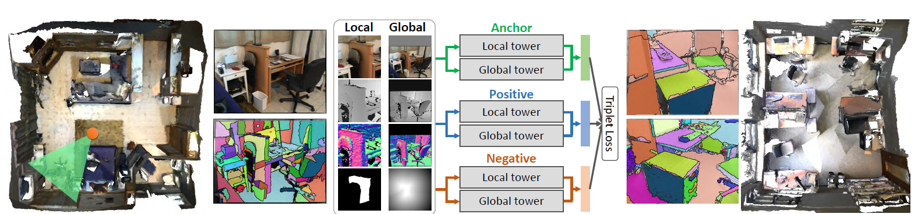 圖 3 PlaneMatch 算法流程圖
圖 3 PlaneMatch 算法流程圖
爲了使算法具有這種判斷能力,網絡首先需要計算平面的共面性特徵描述。爲此,文章作者設計了一種 siamese 網絡並用 triplet loss 進行訓練。網絡的每一個訓練樣本包括一個參考平面 (anchor),一個與 anchor 共面的平面 (positive) 以及一個與 anchor 不共面的平面 (negative)。該網絡的關鍵在於以下三大機制:
1) Multiple channel input: 將 color image、depth map、normal map 和 mask map 同時作爲網絡的輸入。多通道輸入能夠爲網絡提供更多的信息,其中 color image 和 depth map 提供圖片的顏色和深度信息;normal map 由 depth map 計算得到,它顯式地提供了與平面直接相關法向信息;mask map 則告訴網絡當前關注的平面在整個圖像中所處的位置;
2) Multiple resolution input:將兩個 scale 的圖像數據分別輸入網絡提取特徵,然後在網絡的高層進行特徵融合。其中 local tower 主要負責提取平面自身的特徵,而 global tower 更多地關注該平面的上下文 (context);
3) Triplet focal loss: 大多數不共面的平面有着完全不同的顏色,隨機產生的 triplet 樣本往往過於簡單,用這樣的數據對網絡進行訓練效率很低。傳統方法一般使用在 mini-batch 中選擇 hard examples 的策略應對這一問題。本文受 focal loss[3] 的啓發,提出一種新的 triplet loss 計算方法 triplet focal loss 更好地挖掘訓練數據中的有效信息 (hard example),提高網絡訓練的效率。
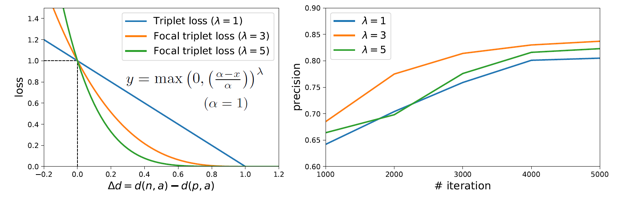 圖 4 Triplet Focal Loss 及其收斂性
圖 4 Triplet Focal Loss 及其收斂性
深度網絡的訓練往往離不開海量的數據。對於平面共面性檢測這一全新的問題,文章作者通過三維場景數據集 ScanNet [2] 全自動地生成訓練數據。每一個 ScanNet 場景都含有高精度的相機位置參數,通過這些相機位置參數能夠準確地計算得到大量的共面訓練數據。一共有一百萬個這樣的樣本被用於訓練共面性檢測網絡。
爲了驗證該網絡的有效性,文章作者提出了一個共面檢測基準 (Coplanarity Benchmark, COP)。其中包括 6000 個共面的平面對和 6000 個不共面的平面對。在該共面基準上的實驗結果表明,該文章提出的共面性檢測網絡的檢測結果遠優於其它方法。
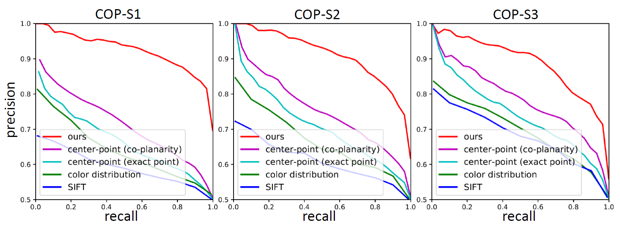 圖 5 共面基準 COP 上的測試結果
圖 5 共面基準 COP 上的測試結果
共面性檢測網絡的直接應用是三維場景重建。文章提出了一種基於共面性的魯棒優化方法,用於實現基於共面的相機配準,並且使用該方法在 TUM、ScanNet 和 SUN3D 等公開數據集上進行了測試。實驗結果表明,該方法的重建精度高,並且能夠彌補基於特徵點配准算法的不足。其原因在於:
1)平面的面積遠大於點,因此平面特徵往往比點特徵更可靠,這大大提高了算法迴環檢測 (loop detection) 的能力;
2)在兩張圖片完全沒有重疊 (overlap) 的情況下,共面性網絡仍然可以檢測到長程的共面平面,給重建提供額外的信息,這對於大規模場景的重建尤爲關鍵。
 圖 6 PlaneMatch 三維場景重建結果
圖 6 PlaneMatch 三維場景重建結果
從對場景結構和語義的分析中獲取信息實現三維場景重建是非常有前景的研究方向,而平面間的共面約束是一個很好的起點。希望該項研究能夠引起業界對該方向的更多關注,推動三維重建由「幾何」邁向「語義」。
項目主頁: http://www.yifeishi.net/planematch.html
源碼發佈:https://github.com/yifeishi/PlaneMatch
[1] Maciej Halber, Thomas Funkhouser. "Fine-to-Coarse Global Registration of RGB-D Scans." CVPR. 2017.
[2] Angela Dai, et al. "ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes." CVPR. 2017.
[3] Tsung-Yi Lin, et al. "Focal Loss for Dense Object Detection." ICCV. 2017.