雷鋒網(公衆號:雷鋒網)AI科技評論按:本文作者Danny Lange,圖普科技編譯自O'REALLY。
「遊戲開發」是一項非常複雜的任務,並且需要耗費大量的人力資源。圖形藝術家、故事敘述者和軟件工程師需要共同努力,才能打造出比較好的遊戲環境、遊戲情節和人物角色行爲。通常,遊戲是以傳統代碼的形式出現的「硬線行爲」的微妙組合,也是以大量規則的形式出現的更具響應性的行爲集合。在過去的幾年間,數據導向型的「機器學習」已經逐漸取代了一些企業(比如亞馬遜、Netflix和優步)中的規則導向型系統。在Unity,我們探究了「機器學習」技術的使用,包括「深度學習」在文本創作中的應用,以及「深度加強學習」在遊戲開發中的應用。在機器學習和人工智能的浪潮中,我們看到了巨大的希望和發展空間。
對於那些數據導向型的大企業來說,機器學習已經不算是新興技術了。2007年,Netflix發起了一個「過濾算法」的公開賽,爲能夠預測電影用戶評分的最佳過濾算法專門設立了「Netflix獎」,這正是我們現在所經歷的人工智能媒體報道浪潮的開端。不過早在2000年年初,一些大企業爲了謀求更好的發展,已經對「數據導向型決策」和「機器學習」有所涉獵了。爲了充分了解顧客們的偏好,進而將顧客偏好轉化爲更高的銷售額,亞馬遜一直在潛心研究他們的「推薦算法」。除了亞馬遜的「推薦算法」之外,廣告技術是另一個較早利用「機器學習」來提高網站點入率的領域。近年來,機器學習已經擴展至更多的行業,並且不斷趨於成熟。
舉例來說,我們在前面提到過的「推薦算法」最初只是作簡單的推薦方案,如今已經發展到能夠通過「探索」和「開發」尋求更多的信息。而亞馬遜和Netflix在使用他們的推薦系統進行數據收集時所面臨的挑戰是,如果只向客戶展示推薦頻率高的產品,而不展示其他的產品,那麼他們獲得的客戶偏好信息就不全面。而解決這一問題的方法是:將純開發行爲轉變爲加入了探索元素的開發行爲。最近,由於同時具備了「開發」和「探索」能力,像「上下文老虎機」(contextual bandits)這樣的算法能夠更好地瞭解客戶的未知信息,也因此越來越受歡迎。相信我,「上下文老虎機」 (contextual bandits)算法肯定會在你瀏覽亞馬遜商城的時候隱藏了一些網頁。我們在「Unity博客」上發表了一篇文章,文章講述了「上下文老虎機」 (contextual bandits)算法的強大功能,從中你可以看到該算法的互動演示。
在2015年,DeepMind進一步發展了「上下文老虎機」 (contextual bandits)算法,並且將其從一個深度神經網絡與加強學習大規模結合的系統上發佈出來。該系統僅靠一些作爲輸入的原始像素和分數就能以超人類的水平掌握各種範圍的Atari 2600遊戲。Deepmind的研究人員將「開發」和「探索」的概念完全對立,「上下文老虎機」 (contextual bandits)算法不太擅長行爲學習,但是「深度加強學習」卻能夠學習用於最大化「未來累積紅利」的行爲順序,換句話來說,深度加強學習會學習那些能夠實現「長期價值」(LTV)最優的行爲。在一些Atari遊戲中,「長期價值」表現在那些通常爲人類玩家保留的策略發展上。
在Unity,我們給自己提出了這樣一個問題:如何讓一隻雞學會穿過繁忙的道路而不被迎面而來的汽車撞上,同時還要收集道路上的禮包?我們採用了一種與DeepMind實驗非常類似的通用「加強學習」算法,並且規定如果小雞撿到禮包獲得正分,被車撞到則獲得負分。除此之外,我們還給小雞設定了四個動作:左移、右移、前進和後退。依靠這些原始像素和分數輸入,以及幾個非常簡單的指令,小雞在不足六個小時的訓練後就達到了超人類水平的性能。
那麼我們究竟是如何從實際應用的角度做到這一點的呢?其實很簡單。我們使用了一組Python APIs,將Unity遊戲與運行於「亞馬遜網絡服務器」(AWS)的TensorFlow服務相聯繫,TensorFlow是谷歌在2005年首次發佈的深度學習框架。仔細觀看視頻中,你會發現小雞在訓練的初期階段主要是探索如何不被汽車撞上(探索階段),隨着訓練的深入,小雞開始學習收集禮包(開發階段)。值得關注的是,這個學習系統的一個重要能力就是處理從未遇到的狀況。遊戲中汽車的出現和禮包的放置都是完全任意的,而儘管小雞已經經過了幾個小時的訓練,它還是會遇到之前訓練中沒有經歷過的情境。有了我們的Python API,讀取遊戲框架和遊戲內部狀態,使用機器學習對遊戲進行反向操作就變得非常簡單了。
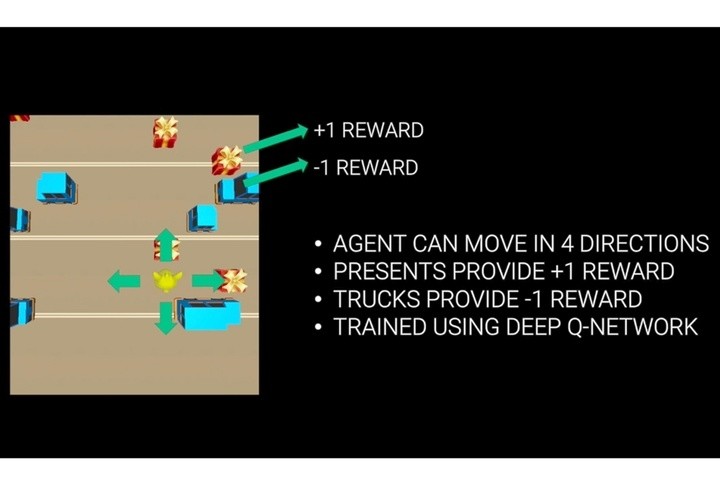
這隻遊戲小雞的訓練給亞馬遜、Netflix和優步的發展提供了一些靈感,他們可以運用相同的技術來優化其客戶服務。
想象一下,假如要訓練一個「非玩家遊戲角色」(NPC),而不是對其行爲進行編碼,那麼遊戲開發者就需要創建一個遊戲場景。在這個場景中,我們將會利用與Python API相聯的「雲加強學習」來訓練NPC。這個遊戲場景可以是完全虛擬合成的,也可以在其中加入一些人類玩家。當訓練到一定程度,這個NPC的性能已經相當不錯的時候,遊戲開發者就能利用另一組Unity API將TensorFlow模型直接嵌入他們的遊戲中,這樣一來,遊戲就不需要連接TensorFlow的雲服務了。
有些遊戲開發者可能會說:「早在10到15年前,我們就已經這麼做過了。」但是時代已經發生了巨大的變遷。儘管我們已經發明瞭「遞歸神經網絡」(RNN),比如用於序列學習的「長短時記憶」(LSTM)和用於空間特徵學習的「卷積神經網絡」(CNN),但是由於計算能力的欠缺,以及大規模、精細軟件框架的缺失,這些神經網絡在實際應用方面,如遊戲開發,仍面臨巨大的阻礙。
「深度加強學習」在遊戲開發中的運用盡管仍處於初期發展階段,但是我們清楚地知道它將很可能成爲一項顛覆性的遊戲技術。像TensorFlow這樣成熟的機器學習框架正在不斷降低遊戲開發者和機器學習研究者的入門門檻。機器學習現在正不斷進入企業的各個角落,那麼我們完全有可能在未來遊戲中的發現機器學習的影子。
想要了解更多關於用深度學習開發數字體驗的訊息,請查看Danny Lange於2017年9月17至20日在美國洛杉磯「人工智能大會」上發表的《利用「深度學習」將遊戲、VR和AR引入現實生活》。雷鋒網也將做持續關注。
via oreilly,雷鋒網AI科技評論
