近日,田淵棟等人在 arXiv 上發表了一篇題爲《When is a Convolutional Filter Easy To Learn?》的論文,分析了用於學習帶有 ReLU 激活函數的卷積濾波器的(隨機)梯度下降算法的收斂,整個過程沒有依賴輸出分佈的任何特定形式,論證也只用到了 ReLU 定義,這與先前受限於標準高斯分佈的工作相反。同時這一理論也證明了深度神經網絡中兩階段的學習率策略。
深度卷積神經網絡(CNN)已經在很多應用中展現出了人工智能的最佳水平,如計算機視覺、自然語言處理和圍棋等複雜遊戲。儘管目標函數具有非常高的非凸性,簡單的一階算法(如隨機梯度下降及其變體)通常可以成功地訓練這樣的網絡。另一方面,卷積神經網絡的成功從優化角度來考慮仍然是難以捉摸的。
當輸入分佈不受約束時,已有的結果大多數爲負,如 3 節點神經網絡學習的硬度(Blum & Rivest,1989)或非重疊卷積濾波器(Brutzkus & Globerson,2017)。最近,Shamir 等人表明學習單層全連接神經網絡對於某些特定的輸入分佈來說是非常困難的。
這些負面結果告訴我們,爲了解釋 SGD 學習神經網絡的成功,還需要對於輸入分佈做出更強假設。最近的一系列研究(Tian,2017;Brutzkus & Globerson,2017;Li & Yuan,2017;Soltanolkotabi,2017;Zhong 等人,2017)假設輸入分佈爲標準高斯 N(0,I),並展示了(隨機)梯度下降能夠在多項式時間內得到具有 ReLU 激活的神經網絡。
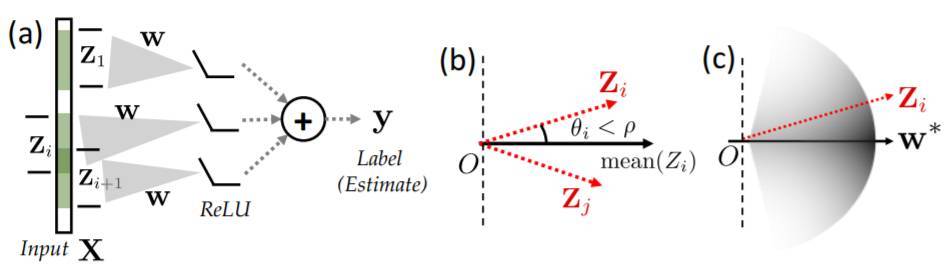
圖 1.(a)研究人員正在考慮的網絡架構。給定輸入 X,我們提取它的補丁 {Zi} 並將其傳遞至共享權重向量 w。隨後輸出會被髮送到 ReLU 並加和產生最終的標籤(以及評估)。(b)-(c)上,我們提出了兩個收斂條件。我們希望數據與(b)高度相關,(c)更加集中於真值向量 w*。
這些分析的一個主要問題在於它們依賴於高斯分佈的專門分析,因此不能推廣到非高斯情況下(真實世界的分佈情況)。對於一般輸入的分佈而言,我們需要新的技術。
在卡耐基梅隆大學、南加州大學和 Facebook 共同發表的這篇論文中,研究人員考慮了一種相對簡單的架構:一個卷積層,隨後跟着一個 ReLU 激活參數,然後是平均池化。形式上,以 x ∈ Rd 作爲輸入示例。例如,一張圖片,我們從 x 中生成 k 個補丁,每個大小均爲 p: Z ∈ R p×k,其中第 i 列是已知函數 Zi = Zi(x) 生成的第 i 個補丁。對於尺寸爲 2,步幅 1 的濾波器,Zi(x) 是第 i 個和第 (i + 1) 個像素。因爲對於卷積濾波器,我們只需要關注補丁而不是輸入,在下面的定義和定理中,我們將 Z 作爲輸入,並將 Z 作爲 Z 的分佈:(σ(x) = max(x, 0) 是 ReLU 激活函數)。
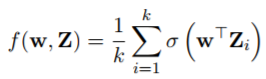
如圖 1(a)所示,很多計算機視覺研究都使用這樣的結構作爲網絡的第一層 [Lin et al., 2013, Milletari et al., 2016]。研究員僅關注可實現的案例,其中訓練數據由式(1)以及一些 Z 輸入分佈的未知參量 w∗生成,比如 `2 loss ` (w, Z) = 1/2 (f(w, Z) − f(w∗, Z))2,通過(隨機)梯度下降方法學習,即:
其中ηt 是訓練步長,在訓練過程中可能發生變化,g(wt) 是一個隨機函數,它的期望值等於 population gradient E [g(w)] = EZ∼Z [∇` (w, Z)]。研究員的訓練目標是瞭解假如 w 經過(隨機)梯度下降優化然後 w → w∗的情況下,發生了什麼。
通過這樣的設定,主要成果如下:
濾波器的可學習性:研究員展示瞭如果輸入補丁之間高度相關(Section 3),即θ (Zi , Zj ) ≤ ρ(一些很小的ρ值,且ρ>0),那麼隨機初始化的梯度下降和隨機梯度下降將在多項式時間內恢復濾波器。此外,強相互作用表明了更快的收斂速度。研究員在 [Tian, 2017] 公開聲稱,這是對非高斯分佈輸入的卷積濾波器(甚至是最簡單的單層單神經元網絡)的基於梯度的算法的第一恢復保證。
研究員正式提出了輸入分佈的平滑度和濾波器權重恢復的收斂速度之間的聯繫,其中平滑度的定義是活化區域的二次矩的最大和最小的本徵值的比(Section 2)。研究表明,輸入分佈越平滑,收斂速度越快,其中高斯分佈作爲一個特例,收斂到了最緊緻的範圍。這個理論結果同樣證實了由 [He et al., 2016, Szegedy et al., 2017] 提出的步長(隨時間)可變的兩態學習速率策略。
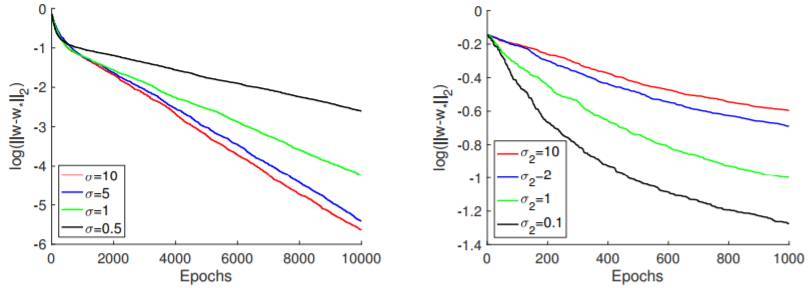
圖 3:關於合成與真實數據的實驗。(a)單層單個神經元模型對不同平滑度的輸入分佈的隨機梯度下降的收斂率。較大的σ更平滑;(b)隨機梯度下降的收斂率用於學習不同補丁親近度的輸入分佈上的卷積濾波器。較大的σ2 更平滑。
論文鏈接:https://arxiv.org/abs/1709.06129
摘要:我們分析了用於學習帶有 ReLU 激活函數的卷積濾波器的(隨機)梯度下降算法的收斂行爲,整個過程沒有依賴輸出分佈的任何特定形式,我們的論證也只用到了 ReLU 的定義,這與先前受限於標準高斯分佈的工作相反。我們表明帶有隨機初始化的(隨機)梯度下降能夠學習多項式時間中的卷積濾波器,收斂速度取決於輸入分佈的平滑度和補丁的接近度。據我們所知,這是對非高斯分佈輸入的卷積濾波器的基於梯度的算法的第一恢復保證。我們的理論也證明了深度神經網絡中兩階段的學習率策略。儘管我們聚焦於理論,但也展現了論證理論發現的實驗。