雷鋒網(公衆號:雷鋒網)按:本文由Zouxy責編,全面介紹了深度學習的發展歷史及其在各個領域的應用,並解釋了深度學習的基本思想,深度與淺度學習的區別和深度學習與神經網絡之間的關係。
深度學習,即Deep Learning,是一種學習算法(Learning algorithm),亦是人工智能領域的一個重要分支。從快速發展到實際應用,短短几年時間裏,深度學習顛覆了語音識別、圖像分類、文本理解等衆多領域的算法設計思路,漸漸形成了一種從訓練數據出發,經過一個端到端(end-to-end)的模型,然後直接輸出得到最終結果的一種新模式。那麼,深度學習有多深?學了究竟有幾分?本文將帶你領略深度學習高端範兒背後的方法與過程。
一、概述
二、背景
三、人腦視覺機理
四、關於特徵
4.1、特徵表示的粒度
4.2、初級(淺層)特徵表示
4.3、結構性特徵表示
4.4、需要有多少個特徵?
五、Deep Learning的基本思想
六、淺層學習(Shallow Learning)和深度學習(Deep Learning)
七、Deep learning與Neural Network
八、Deep learning訓練過程
8.1、傳統神經網絡的訓練方法
8.2、deep learning訓練過程
九、Deep Learning的常用模型或者方法
9.1、AutoEncoder自動編碼器
9.2、Sparse Coding稀疏編碼
9.3、Restricted Boltzmann Machine(RBM)限制波爾茲曼機
9.4、Deep BeliefNetworks深信度網絡
9.5、Convolutional Neural Networks卷積神經網絡
十、總結與展望
|一、概述
Artificial Intelligence,也就是人 工智能,就像長生不老和星際漫遊一樣,是人類最美好的夢想之一。雖然計算機技術已經取得了長足的進步,但是到目前爲止,還沒有一臺電腦能產生「自我」的意識。是的,在人類和大量現成數據的幫助下,電腦可以表現的十分強大,但是離開了這兩者,它甚至都不能分辨一個喵星人和一個汪星人。
圖靈(圖靈,大家都知道吧。計算機和人工智能的鼻祖,分別對應於其著名的「圖靈機」和「圖靈測試」)在 1950 年的論文裏,提出圖靈試驗的設想,即,隔牆對話,你將不知道與你談話的,是人還是電腦。這無疑給計算機,尤其是人工智能,預設了一個很高的期望值。但是半個世紀過去了,人工智能的進展,遠遠沒有達到圖靈試驗的標準。這不僅讓多年翹首以待的人們,心灰意冷,認爲人工智能是忽悠,相關領域是「僞科學」。
但是自 2006 年以來,機器學習領域,取得了突破性的進展。圖靈試驗,至少不是那麼可望而不可及了。至於技術手段,不僅僅依賴於雲計算對大數據的並行處理能力,而且依賴於算法。這個算法就是,Deep Learning。藉助於 Deep Learning 算法,人類終於找到了如何處理「抽象概念」這個亙古難題的方法。
2012年6月,《紐約時報》披露了Google Brain項目,吸引了公衆的廣泛關注。這個項目是由著名的斯坦福大學的機器學習教授Andrew Ng和在大規模計算機系統方面的世界頂尖專家JeffDean共同主導,用16000個CPU Core的並行計算平臺訓練一種稱爲「深度神經網絡」(DNN,Deep Neural Networks)的機器學習模型(內部共有10億個節點。這一網絡自然是不能跟人類的神經網絡相提並論的。要知道,人腦中可是有150多億個神經元,互相連接的節點也就是突觸數更是如銀河沙數。曾經有人估算過,如果將一個人的大腦中所有神經細胞的軸突和樹突依次連接起來,並拉成一根直線,可從地球連到月亮,再從月亮返回地球),在語音識別和圖像識別等領域獲得了巨大的成功。
項目負責人之一Andrew稱:「我們沒有像通常做的那樣自己框定邊界,而是直接把海量數據投放到算法中,讓數據自己說話,系統會自動從數據中學習。」另外一名負責人Jeff則說:「我們在訓練的時候從來不會告訴機器說:‘這是一隻貓。’系統其實是自己發明或者領悟了「貓」的概念。」

2012年11月,微軟在中國天津的一次活動上公開演示了一個全自動的同聲傳譯系統,講演者用英文演講,後臺的計算機一氣呵成自動完成語音識別、英中機器翻譯和中文語音合成,效果非常流暢。據報道,後面支撐的關鍵技術也是DNN,或者深度學習(DL,DeepLearning)。
2013年1月,在百度年會上,創始人兼CEO李彥宏高調宣佈要成立百度研究院,其中第一個成立的就是「深度學習研究所」(IDL,Institue of Deep Learning)。

爲什麼擁有大數據的互聯網公司爭相投入大量資源研發深度學習技術。聽起來感覺deeplearning很牛那樣。那什麼是deep learning?爲什麼有deep learning?它是怎麼來的?又能幹什麼呢?目前存在哪些困難呢?這些問題的簡答都需要慢慢來。咱們先來了解下機器學習(人工智能的核心)的背景。
|二、背景
機器學習(Machine Learning)是一門專門研究計算機怎樣模擬或實現人類的學習行爲,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能的學科。機器能否像人類一樣能具有學習能力呢?1959年美國的塞繆爾(Samuel)設計了一個下棋程序,這個程序具有學習能力,它可以在不斷的對弈中改善自己的棋藝。4年後,這個程序戰勝了設計者本人。又過了3年,這個程序戰勝了美國一個保持8年之久的常勝不敗的冠軍。這個程序向人們展示了機器學習的能力,提出了許多令人深思的社會問題與哲學問題(呵呵,人工智能正常的軌道沒有很大的發展,這些什麼哲學倫理啊倒發展的挺快。什麼未來機器越來越像人,人越來越像機器啊。什麼機器會反人類啊,ATM是開第一槍的啊等等。人類的思維無窮啊)。
機器學習雖然發展了幾十年,但還是存在很多沒有良好解決的問題:

例如圖像識別、語音識別、自然語言理解、天氣預測、基因表達、內容推薦等等。目前我們通過機器學習去解決這些問題的思路都是這樣的(以視覺感知爲例子):

從開始的通過傳感器(例如CMOS)來獲得數據。然後經過預處理、特徵提取、特徵選擇,再到推理、預測或者識別。最後一個部分,也就是機器學習的部分,絕大部分的工作是在這方面做的,也存在很多的paper和研究。
而中間的三部分,概括起來就是特徵表達。良好的特徵表達,對最終算法的準確性起了非常關鍵的作用,而且系統主要的計算和測試工作都耗在這一大部分。但,這塊實際中一般都是人工完成的。靠人工提取特徵。
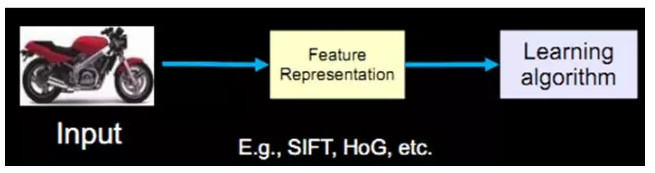
截止現在,也出現了不少NB的特徵(好的特徵應具有不變性(大小、尺度和旋轉等)和可區分性):例如Sift的出現,是局部圖像特徵描述子研究領域一項里程碑式的工作。由於SIFT對尺度、旋轉以及一定視角和光照變化等圖像變化都具有不變性,並且SIFT具有很強的可區分性,的確讓很多問題的解決變爲可能。但它也不是萬能的。
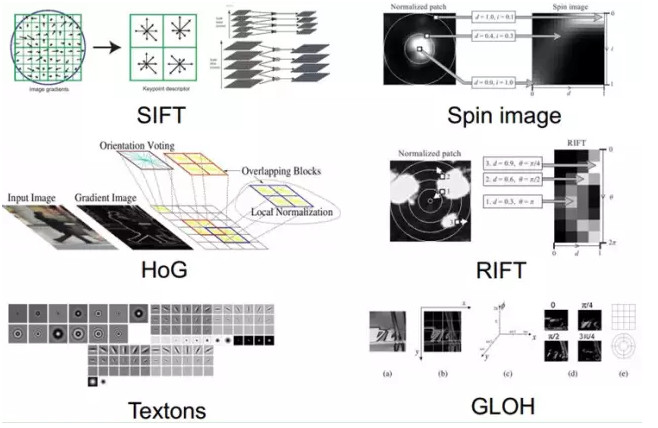
然而,手工地選取特徵是一件非常費力、啓發式(需要專業知識)的方法,能不能選取好很大程度上靠經驗和運氣,而且它的調節需要大量的時間。既然手工選取特徵不太好,那麼能不能自動地學習一些特徵呢?答案是能!Deep Learning就是用來幹這個事情的,看它的一個別名UnsupervisedFeature Learning,就可以顧名思義了,Unsupervised的意思就是不要人蔘與特徵的選取過程。
那它是怎麼學習的呢?怎麼知道哪些特徵好哪些不好呢?我們說機器學習是一門專門研究計算機怎樣模擬或實現人類的學習行爲的學科。好,那我們人的視覺系統是怎麼工作的呢?爲什麼在茫茫人海,芸芸衆生,滾滾紅塵中我們都可以找到另一個她(因爲,你存在我深深的腦海裏,我的夢裏 我的心裏 我的歌聲裏……)。人腦那麼NB,我們能不能參考人腦,模擬人腦呢?(好像和人腦扯上點關係的特徵啊,算法啊,都不錯,但不知道是不是人爲強加的,爲了使自己的作品變得神聖和高雅。) 近幾十年以來,認知神經科學、生物學等等學科的發展,讓我們對自己這個神祕的而又神奇的大腦不再那麼的陌生。也給人工智能的發展推波助瀾。
|三、人腦視覺機理
1981 年的諾貝爾醫學獎,頒發給了 David Hubel(出生於加拿大的美國神經生物學家) 和TorstenWiesel,以及 Roger Sperry。前兩位的主要貢獻,是「發現了視覺系統的信息處理」:可視皮層是分級的:
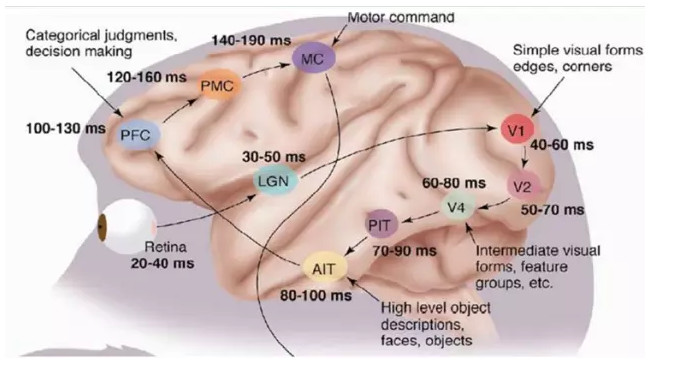
我們看看他們做了什麼。1958 年,DavidHubel 和Torsten Wiesel 在 JohnHopkins University,研究瞳孔區域與大腦皮層神經元的對應關係。他們在貓的後腦頭骨上,開了一個3 毫米的小洞,向洞裏插入電極,測量神經元的活躍程度。
然後,他們在小貓的眼前,展現各種形狀、各種亮度的物體。並且,在展現每一件物體時,還改變物體放置的位置和角度。他們期望通過這個辦法,讓小貓瞳孔感受不同類型、不同強弱的刺激。
之所以做這個試驗,目的是去證明一個猜測。位於後腦皮層的不同視覺神經元,與瞳孔所受刺激之間,存在某種對應關係。一旦瞳孔受到某一種刺激,後腦皮層的某一部分神經元就會活躍。經歷了很多天反覆的枯燥的試驗,同時犧牲了若干只可憐的小貓,David Hubel 和Torsten Wiesel 發現了一種被稱爲「方向選擇性細胞(Orientation Selective Cell)」的神經元細胞。當瞳孔發現了眼前的物體的邊緣,而且這個邊緣指向某個方向時,這種神經元細胞就會活躍。
這個發現激發了人們對於神經系統的進一步思考。神經-中樞-大腦的工作過程,或許是一個不斷迭代、不斷抽象的過程。這裏的關鍵詞有兩個,一個是抽象,一個是迭代。從原始信號,做低級抽象,逐漸向高級抽象迭代。人類的邏輯思維,經常使用高度抽象的概念。
例如,從原始信號攝入開始(瞳孔攝入像素 Pixels),接着做初步處理(大腦皮層某些細胞發現邊緣和方向),然後抽象(大腦判定,眼前的物體的形狀,是圓形的),然後進一步抽象(大腦進一步判定該物體是隻氣球)。
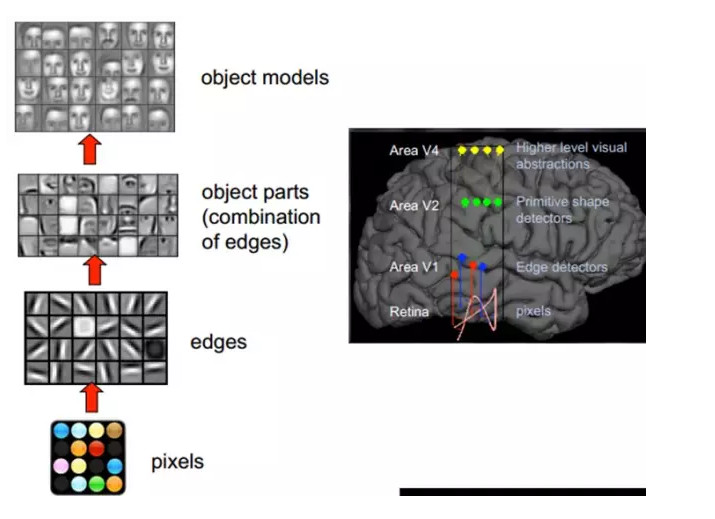
這個生理學的發現,促成了計算機人工智能,在四十年後的突破性發展。
總的來說,人的視覺系統的信息處理是分級的。從低級的V1區提取邊緣特徵,再到V2區的形狀或者目標的部分等,再到更高層,整個目標、目標的行爲等。也就是說高層的特徵是低層特徵的組合,從低層到高層的特徵表示越來越抽象,越來越能表現語義或者意圖。而抽象層面越高,存在的可能猜測就越少,就越利於分類。例如,單詞集合和句子的對應是多對一的,句子和語義的對應又是多對一的,語義和意圖的對應還是多對一的,這是個層級體系。
敏感的人注意到關鍵詞了:分層。而Deep learning的deep是不是就表示我存在多少層,也就是多深呢?沒錯。那Deep learning是如何借鑑這個過程的呢?畢竟是歸於計算機來處理,面對的一個問題就是怎麼對這個過程建模?
因爲我們要學習的是特徵的表達,那麼關於特徵,或者說關於這個層級特徵,我們需要了解地更深入點。所以在說Deep Learning之前,我們有必要再囉嗦下特徵(呵呵,實際上是看到那麼好的對特徵的解釋,不放在這裏有點可惜,所以就塞到這了)。
|四、關於特徵
特徵是機器學習系統的原材料,對最終模型的影響是毋庸置疑的。如果數據被很好的表達成了特徵,通常線性模型就能達到滿意的精度。那對於特徵,我們需要考慮什麼呢?
4.1、特徵表示的粒度
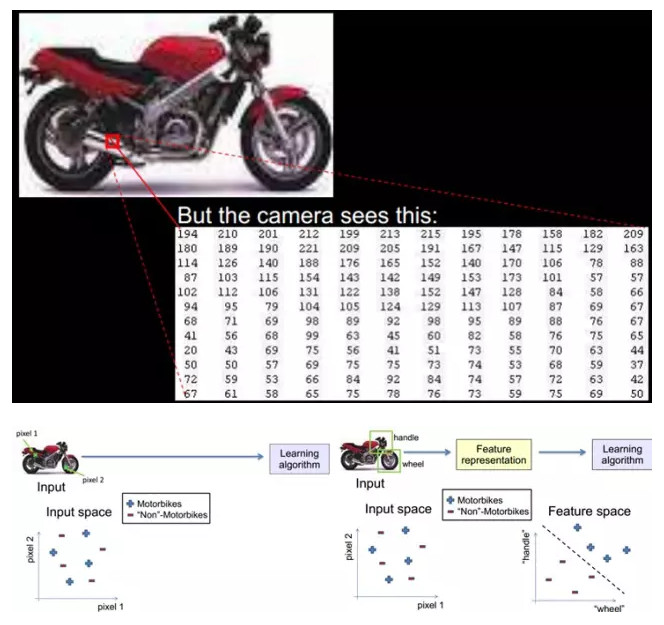
學習算法在一個什麼粒度上的特徵表示,纔有能發揮作用-?就一個圖片來說,像素級的特徵根本沒有價值。例如下面的摩托車,從像素級別,根本得不到任何信息,其無法進行摩托車和非摩托車的區分。而如果特徵是一個具有結構性(或者說有含義)的時候,比如是否具有車把手(handle),是否具有車輪(wheel),就很容易把摩托車和非摩托車區分,學習算法才能發揮作用。
4.2、初級(淺層)特徵表示
既然像素級的特徵表示方法沒有作用,那怎樣的表示纔有用呢?
1995 年前後,Bruno Olshausen和 David Field 兩位學者任職 Cornell University,他們試圖同時用生理學和計算機的手段,雙管齊下,研究視覺問題。 他們收集了很多黑白風景照片,從這些照片中,提取出400個小碎片,每個照片碎片的尺寸均爲 16x16 像素,不妨把這400個碎片標記爲 S[i], i = 0,.. 399。接下來,再從這些黑白風景照片中,隨機提取另一個碎片,尺寸也是 16x16 像素,不妨把這個碎片標記爲 T。
他們提出的問題是,如何從這400個碎片中,選取一組碎片,S[k], 通過疊加的辦法,合成出一個新的碎片,而這個新的碎片,應當與隨機選擇的目標碎片 T,儘可能相似,同時,S[k] 的數量儘可能少。用數學的語言來描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在疊加碎片 S[k] 時的權重係數。
爲解決這個問題,Bruno Olshausen和 David Field 發明了一個算法,稀疏編碼(Sparse Coding)。
稀疏編碼是一個重複迭代的過程,每次迭代分兩步:
1)選擇一組 S[k],然後調整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 個碎片中,選擇其它更合適的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
經過幾次迭代後,最佳的 S[k] 組合,被遴選出來了。令人驚奇的是,被選中的 S[k],基本上都是照片上不同物體的邊緣線,這些線段形狀相似,區別在於方向。
Bruno Olshausen和 David Field 的算法結果,與 David Hubel 和Torsten Wiesel 的生理髮現,不謀而合!
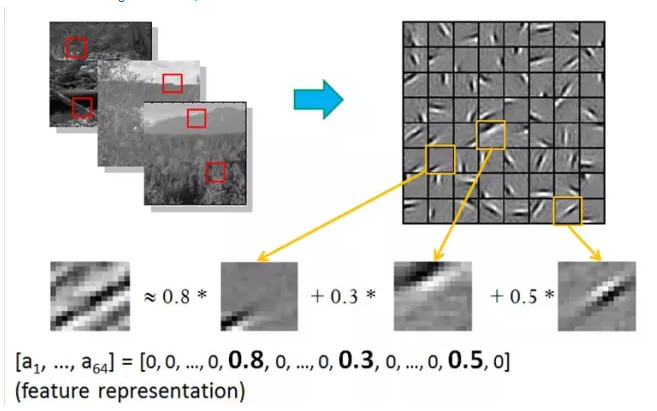
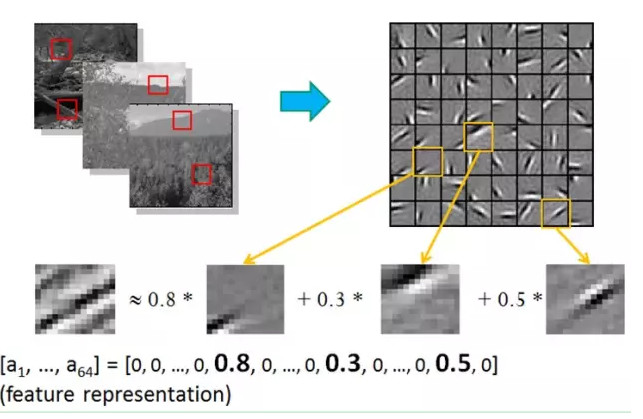
也就是說,複雜圖形,往往由一些基本結構組成。比如下圖:一個圖可以通過用64種正交的edges(可以理解成正交的基本結構)來線性表示。比如樣例的x可以用1-64個edges中的三個按照0.8,0.3,0.5的權重調和而成。而其他基本edge沒有貢獻,因此均爲0 。
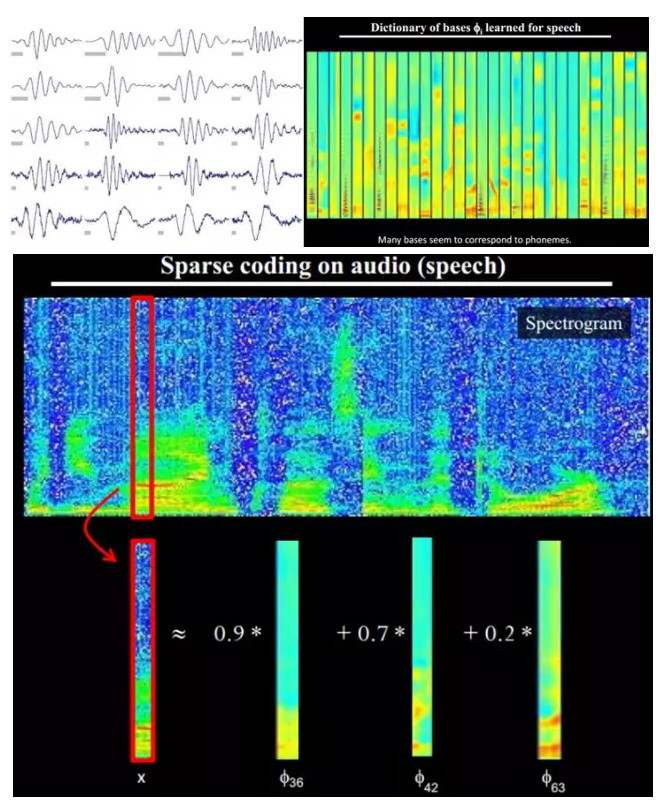
另外,大牛們還發現,不僅圖像存在這個規律,聲音也存在。他們從未標註的聲音中發現了20種基本的聲音結構,其餘的聲音可以由這20種基本結構合成。
4.3、結構性特徵表示
小塊的圖形可以由基本edge構成,更結構化,更復雜的,具有概念性的圖形如何表示呢?這就需要更高層次的特徵表示,比如V2,V4。因此V1看像素級是像素級。V2看V1是像素級,這個是層次遞進的,高層表達由底層表達的組合而成。專業點說就是基basis。V1取提出的basis是邊緣,然後V2層是V1層這些basis的組合,這時候V2區得到的又是高一層的basis。即上一層的basis組合的結果,上上層又是上一層的組合basis……(所以有大牛說Deep learning就是「搞基」,因爲難聽,所以美其名曰Deep learning或者Unsupervised Feature Learning)
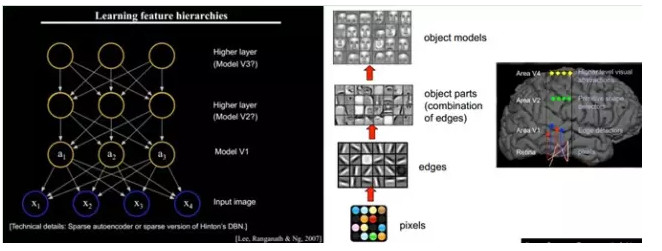
直觀上說,就是找到make sense的小patch再將其進行combine,就得到了上一層的feature,遞歸地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就會completely different了(那咱們分辨car或者face是不是容易多了):

從文本來說,一個doc表示什麼意思?我們描述一件事情,用什麼來表示比較合適?用一個一個字嘛,我看不是,字就是像素級別了,起碼應該是term,換句話說每個doc都由term構成,但這樣表示概念的能力就夠了嘛,可能也不夠,需要再上一步,達到topic級,有了topic,再到doc就合理。但每個層次的數量差距很大,比如doc表示的概念->topic(千-萬量級)->term(10萬量級)->word(百萬量級)。
一個人在看一個doc的時候,眼睛看到的是word,由這些word在大腦裏自動切詞形成term,在按照概念組織的方式,先驗的學習,得到topic,然後再進行高層次的learning。
4.4、需要有多少個特徵?
我們知道需要層次的特徵構建,由淺入深,但每一層該有多少個特徵呢?
任何一種方法,特徵越多,給出的參考信息就越多,準確性會得到提升。但特徵多意味着計算複雜,探索的空間大,可以用來訓練的數據在每個特徵上就會稀疏,都會帶來各種問題,並不一定特徵越多越好。
好了,到了這一步,終於可以聊到Deep learning了。上面我們聊到爲什麼會有Deep learning(讓機器自動學習良好的特徵,而免去人工選取過程。還有參考人的分層視覺處理系統),我們得到一個結論就是Deep learning需要多層來獲得更抽象的特徵表達。那麼多少層才合適呢?用什麼架構來建模呢?怎麼進行非監督訓練呢?
|五、Deep Learning的基本思想
假設我們有一個系統S,它有n層(S1,…Sn),它的輸入是I,輸出是O,形象地表示爲: I =>S1=>S2=>…..=>Sn => O,如果輸出O等於輸入I,即輸入I經過這個系統變化之後沒有任何的信息損失(呵呵,大牛說,這是不可能的。信息論中有個「信息逐層丟失」的說法(信息處理不等式),設處理a信息得到b,再對b處理得到c,那麼可以證明:a和c的互信息不會超過a和b的互信息。這表明信息處理不會增加信息,大部分處理會丟失信息。當然了,如果丟掉的是沒用的信息那多好啊),保持了不變,這意味着輸入I經過每一層Si都沒有任何的信息損失,即在任何一層Si,它都是原有信息(即輸入I)的另外一種表示。現在回到我們的主題Deep Learning,我們需要自動地學習特徵,假設我們有一堆輸入I(如一堆圖像或者文本),假設我們設計了一個系統S(有n層),我們通過調整系統中參數,使得它的輸出仍然是輸入I,那麼我們就可以自動地獲取得到輸入I的一系列層次特徵,即S1,…, Sn。
對於深度學習來說,其思想就是對堆疊多個層,也就是說這一層的輸出作爲下一層的輸入。通過這種方式,就可以實現對輸入信息進行分級表達了。
另外,前面是假設輸出嚴格地等於輸入,這個限制太嚴格,我們可以略微地放鬆這個限制,例如我們只要使得輸入與輸出的差別儘可能地小即可,這個放鬆會導致另外一類不同的Deep Learning方法。上述就是Deep Learning的基本思想。
|六、淺層學習(Shallow Learning)和深度學習(Deep Learning)
淺層學習是機器學習的第一次浪潮。
20世紀80年代末期,用於人工神經網絡的反向傳播算法(也叫Back Propagation算法或者BP算法)的發明,給機器學習帶來了希望,掀起了基於統計模型的機器學習熱潮。這個熱潮一直持續到今天。人們發現,利用BP算法可以讓一個人工神經網絡模型從大量訓練樣本中學習統計規律,從而對未知事件做預測。這種基於統計的機器學習方法比起過去基於人工規則的系統,在很多方面顯出優越性。這個時候的人工神經網絡,雖也被稱作多層感知機(Multi-layer Perceptron),但實際是種只含有一層隱層節點的淺層模型。
20世紀90年代,各種各樣的淺層機器學習模型相繼被提出,例如支撐向量機(SVM,Support Vector Machines)、 Boosting、最大熵方法(如LR,Logistic Regression)等。這些模型的結構基本上可以看成帶有一層隱層節點(如SVM、Boosting),或沒有隱層節點(如LR)。這些模型無論是在理論分析還是應用中都獲得了巨大的成功。相比之下,由於理論分析的難度大,訓練方法又需要很多經驗和技巧,這個時期淺層人工神經網絡反而相對沉寂。
深度學習是機器學習的第二次浪潮。
2006年,加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton和他的學生RuslanSalakhutdinov在《科學》上發表了一篇文章,開啓了深度學習在學術界和工業界的浪潮。這篇文章有兩個主要觀點:1)多隱層的人工神經網絡具有優異的特徵學習能力,學習得到的特徵對數據有更本質的刻畫,從而有利於可視化或分類;2)深度神經網絡在訓練上的難度,可以通過「逐層初始化」(layer-wise pre-training)來有效克服,在這篇文章中,逐層初始化是通過無監督學習實現的。
當前多數分類、迴歸等學習方法爲淺層結構算法,其侷限性在於有限樣本和計算單元情況下對複雜函數的表示能力有限,針對複雜分類問題其泛化能力受到一定製約。深度學習可通過學習一種深層非線性網絡結構,實現複雜函數逼近,表徵輸入數據分佈式表示,並展現了強大的從少數樣本集中學習數據集本質特徵的能力。(多層的好處是可以用較少的參數表示複雜的函數)
深度學習的實質,是通過構建具有很多隱層的機器學習模型和海量的訓練數據,來學習更有用的特徵,從而最終提升分類或預測的準確性。因此,「深度模型」是手段,「特徵學習」是目的。區別於傳統的淺層學習,深度學習的不同在於:1)強調了模型結構的深度,通常有5層、6層,甚至10多層的隱層節點;2)明確突出了特徵學習的重要性,也就是說,通過逐層特徵變換,將樣本在原空間的特徵表示變換到一個新特徵空間,從而使分類或預測更加容易。與人工規則構造特徵的方法相比,利用大數據來學習特徵,更能夠刻畫數據的豐富內在信息。
|七、Deep learning與Neural Network
深度學習是機器學習研究中的一個新的領域,其動機在於建立、模擬人腦進行分析學習的神經網絡,它模仿人腦的機制來解釋數據,例如圖像,聲音和文本。深度學習是無監督學習的一種。
深度學習的概念源於人工神經網絡的研究。含多隱層的多層感知器就是一種深度學習結構。深度學習通過組合低層特徵形成更加抽象的高層表示屬性類別或特徵,以發現數據的分佈式特徵表示。
Deep learning本身算是machine learning的一個分支,簡單可以理解爲neural network的發展。大約二三十年前,neural network曾經是ML領域特別火熱的一個方向,但是後來確慢慢淡出了,原因包括以下幾個方面:
1)比較容易過擬合,參數比較難tune,而且需要不少trick;
2)訓練速度比較慢,在層次比較少(小於等於3)的情況下效果並不比其它方法更優;
所以中間有大約20多年的時間,神經網絡被關注很少,這段時間基本上是SVM和boosting算法的天下。但是,一個癡心的老先生Hinton,他堅持了下來,並最終(和其它人一起Bengio、Yann.lecun等)提成了一個實際可行的deep learning框架。
Deep learning與傳統的神經網絡之間有相同的地方也有很多不同。
二者的相同在於deep learning採用了神經網絡相似的分層結構,系統由包括輸入層、隱層(多層)、輸出層組成的多層網絡,只有相鄰層節點之間有連接,同一層以及跨層節點之間相互無連接,每一層可以看作是一個logistic regression模型;這種分層結構,是比較接近人類大腦的結構的。
而爲了克服神經網絡訓練中的問題,DL採用了與神經網絡很不同的訓練機制。傳統神經網絡中,採用的是back propagation的方式進行,簡單來講就是採用迭代的算法來訓練整個網絡,隨機設定初值,計算當前網絡的輸出,然後根據當前輸出和label之間的差去改變前面各層的參數,直到收斂(整體是一個梯度下降法)。而deep learning整體上是一個layer-wise的訓練機制。這樣做的原因是因爲,如果採用back propagation的機制,對於一個deep network(7層以上),殘差傳播到最前面的層已經變得太小,出現所謂的gradient diffusion(梯度擴散)。這個問題我們接下來討論。
|八、Deep learning訓練過程
8.1、傳統神經網絡的訓練方法爲什麼不能用在深度神經網絡
BP算法作爲傳統訓練多層網絡的典型算法,實際上對僅含幾層網絡,該訓練方法就已經很不理想。深度結構(涉及多個非線性處理單元層)非凸目標代價函數中普遍存在的局部最小是訓練困難的主要來源。
BP算法存在的問題:
(1)梯度越來越稀疏:從頂層越往下,誤差校正信號越來越小;
(2)收斂到局部最小值:尤其是從遠離最優區域開始的時候(隨機值初始化會導致這種情況的發生);
(3)一般,我們只能用有標籤的數據來訓練:但大部分的數據是沒標籤的,而大腦可以從沒有標籤的的數據中學習;
8.2、deep learning訓練過程
如果對所有層同時訓練,時間複雜度會太高;如果每次訓練一層,偏差就會逐層傳遞。這會面臨跟上面監督學習中相反的問題,會嚴重欠擬合(因爲深度網絡的神經元和參數太多了)。
2006年,hinton提出了在非監督數據上建立多層神經網絡的一個有效方法,簡單的說,分爲兩步,一是每次訓練一層網絡,二是調優,使原始表示x向上生成的高級表示r和該高級表示r向下生成的x'儘可能一致。方法是:
1)首先逐層構建單層神經元,這樣每次都是訓練一個單層網絡。
2)當所有層訓練完後,Hinton使用wake-sleep算法進行調優。
將除最頂層的其它層間的權重變爲雙向的,這樣最頂層仍然是一個單層神經網絡,而其它層則變爲了圖模型。向上的權重用於「認知」,向下的權重用於「生成」。然後使用Wake-Sleep算法調整所有的權重。讓認知和生成達成一致,也就是保證生成的最頂層表示能夠儘可能正確的復原底層的結點。比如頂層的一個結點表示人臉,那麼所有人臉的圖像應該激活這個結點,並且這個結果向下生成的圖像應該能夠表現爲一個大概的人臉圖像。Wake-Sleep算法分爲醒(wake)和睡(sleep)兩個部分。
1)wake階段:認知過程,通過外界的特徵和向上的權重(認知權重)產生每一層的抽象表示(結點狀態),並且使用梯度下降修改層間的下行權重(生成權重)。也就是「如果現實跟我想象的不一樣,改變我的權重使得我想象的東西就是這樣的」。
2)sleep階段:生成過程,通過頂層表示(醒時學得的概念)和向下權重,生成底層的狀態,同時修改層間向上的權重。也就是「如果夢中的景象不是我腦中的相應概念,改變我的認知權重使得這種景象在我看來就是這個概念」。
deep learning訓練過程具體如下:
1)使用自下上升非監督學習(就是從底層開始,一層一層的往頂層訓練):
採用無標定數據(有標定數據也可)分層訓練各層參數,這一步可以看作是一個無監督訓練過程,是和傳統神經網絡區別最大的部分(這個過程可以看作是feature learning過程)
具體的,先用無標定數據訓練第一層,訓練時先學習第一層的參數(這一層可以看作是得到一個使得輸出和輸入差別最小的三層神經網絡的隱層),由於模型capacity的限制以及稀疏性約束,使得得到的模型能夠學習到數據本身的結構,從而得到比輸入更具有表示能力的特徵;在學習得到第n-1層後,將n-1層的輸出作爲第n層的輸入,訓練第n層,由此分別得到各層的參數;
2)自頂向下的監督學習(就是通過帶標籤的數據去訓練,誤差自頂向下傳輸,對網絡進行微調):
基於第一步得到的各層參數進一步fine-tune整個多層模型的參數,這一步是一個有監督訓練過程;第一步類似神經網絡的隨機初始化初值過程,由於DL的第一步不是隨機初始化,而是通過學習輸入數據的結構得到的,因而這個初值更接近全局最優,從而能夠取得更好的效果;所以deep learning效果好很大程度上歸功於第一步的feature learning過程。
|九、Deep Learning的常用模型或者方法
9.1、AutoEncoder自動編碼器
Deep Learning最簡單的一種方法是利用人工神經網絡的特點,人工神經網絡(ANN)本身就是具有層次結構的系統,如果給定一個神經網絡,我們假設其輸出與輸入是相同的,然後訓練調整其參數,得到每一層中的權重。自然地,我們就得到了輸入I的幾種不同表示(每一層代表一種表示),這些表示就是特徵。自動編碼器就是一種儘可能復現輸入信號的神經網絡。爲了實現這種復現,自動編碼器就必須捕捉可以代表輸入數據的最重要的因素,就像PCA那樣,找到可以代表原信息的主要成分。
具體過程簡單的說明如下:
1)給定無標籤數據,用非監督學習學習特徵:
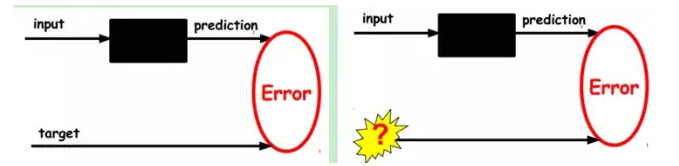
在我們之前的神經網絡中,如第一個圖,我們輸入的樣本是有標籤的,即(input, target),這樣我們根據當前輸出和target(label)之間的差去改變前面各層的參數,直到收斂。但現在我們只有無標籤數據,也就是右邊的圖。那麼這個誤差怎麼得到呢?
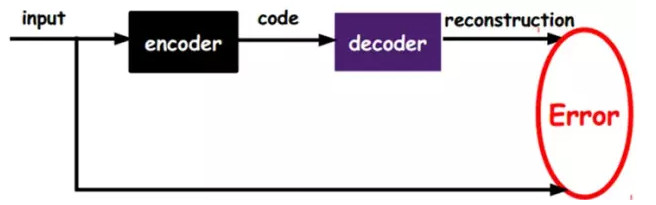
如上圖,我們將input輸入一個encoder編碼器,就會得到一個code,這個code也就是輸入的一個表示,那麼我們怎麼知道這個code表示的就是input呢?我們加一個decoder解碼器,這時候decoder就會輸出一個信息,那麼如果輸出的這個信息和一開始的輸入信號input是很像的(理想情況下就是一樣的),那很明顯,我們就有理由相信這個code是靠譜的。所以,我們就通過調整encoder和decoder的參數,使得重構誤差最小,這時候我們就得到了輸入input信號的第一個表示了,也就是編碼code了。因爲是無標籤數據,所以誤差的來源就是直接重構後與原輸入相比得到。
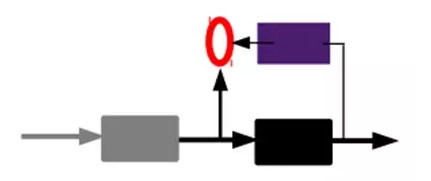
2)通過編碼器產生特徵,然後訓練下一層。這樣逐層訓練:
那上面我們就得到第一層的code,我們的重構誤差最小讓我們相信這個code就是原輸入信號的良好表達了,或者牽強點說,它和原信號是一模一樣的(表達不一樣,反映的是一個東西)。那第二層和第一層的訓練方式就沒有差別了,我們將第一層輸出的code當成第二層的輸入信號,同樣最小化重構誤差,就會得到第二層的參數,並且得到第二層輸入的code,也就是原輸入信息的第二個表達了。其他層就同樣的方法炮製就行了(訓練這一層,前面層的參數都是固定的,並且他們的decoder已經沒用了,都不需要了)。
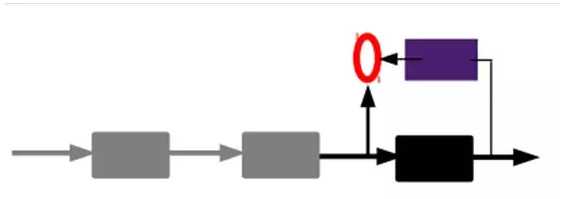
3)有監督微調:
經過上面的方法,我們就可以得到很多層了。至於需要多少層(或者深度需要多少,這個目前本身就沒有一個科學的評價方法)需要自己試驗調了。每一層都會得到原始輸入的不同的表達。當然了,我們覺得它是越抽象越好了,就像人的視覺系統一樣。
到這裏,這個AutoEncoder還不能用來分類數據,因爲它還沒有學習如何去連結一個輸入和一個類。它只是學會了如何去重構或者復現它的輸入而已。或者說,它只是學習獲得了一個可以良好代表輸入的特徵,這個特徵可以最大程度上代表原輸入信號。那麼,爲了實現分類,我們就可以在AutoEncoder的最頂的編碼層添加一個分類器(例如羅傑斯特迴歸、SVM等),然後通過標準的多層神經網絡的監督訓練方法(梯度下降法)去訓練。
也就是說,這時候,我們需要將最後層的特徵code輸入到最後的分類器,通過有標籤樣本,通過監督學習進行微調,這也分兩種,一個是隻調整分類器(黑色部分):
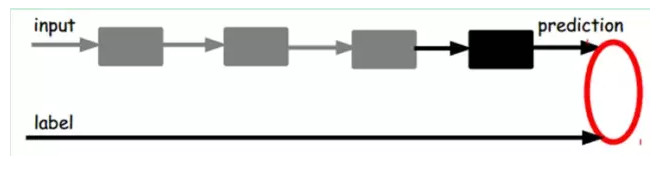
另一種:通過有標籤樣本,微調整個系統:(如果有足夠多的數據,這個是最好的。end-to-end learning端對端學習)
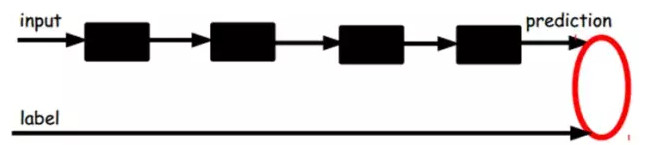
一旦監督訓練完成,這個網絡就可以用來分類了。神經網絡的最頂層可以作爲一個線性分類器,然後我們可以用一個更好性能的分類器去取代它。在研究中可以發現,如果在原有的特徵中加入這些自動學習得到的特徵可以大大提高精確度,甚至在分類問題中比目前最好的分類算法效果還要好!
AutoEncoder存在一些變體,這裏簡要介紹下兩個:
Sparse AutoEncoder稀疏自動編碼器:
當然,我們還可以繼續加上一些約束條件得到新的Deep Learning方法,如:如果在AutoEncoder的基礎上加上L1的Regularity限制(L1主要是約束每一層中的節點中大部分都要爲0,只有少數不爲0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder法。
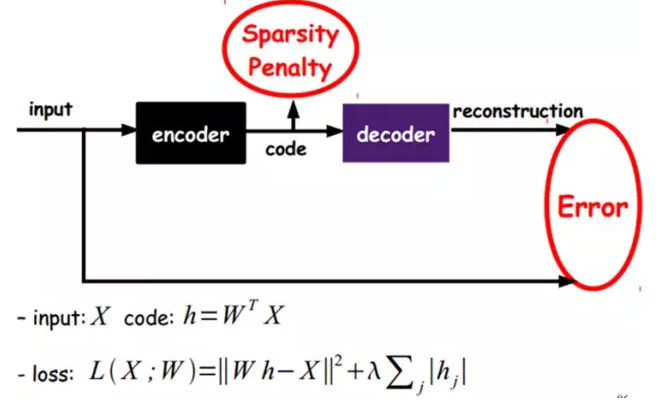
如上圖,其實就是限制每次得到的表達code儘量稀疏。因爲稀疏的表達往往比其他的表達要有效(人腦好像也是這樣的,某個輸入只是刺激某些神經元,其他的大部分的神經元是受到抑制的)。
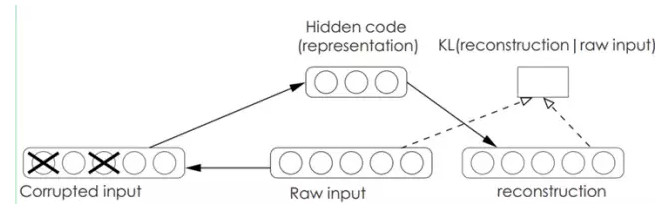
Denoising AutoEncoders降噪自動編碼器:
降噪自動編碼器DA是在自動編碼器的基礎上,訓練數據加入噪聲,所以自動編碼器必須學習去去除這種噪聲而獲得真正的沒有被噪聲污染過的輸入。因此,這就迫使編碼器去學習輸入信號的更加魯棒的表達,這也是它的泛化能力比一般編碼器強的原因。DA可以通過梯度下降算法去訓練。
9.2、Sparse Coding稀疏編碼
如果我們把輸出必須和輸入相等的限制放鬆,同時利用線性代數中基的概念,即O = a1*Φ1 + a2*Φ2+….+ an*Φn, Φi是基,ai是係數,我們可以得到這樣一個優化問題:
Min |I – O|,其中I表示輸入,O表示輸出。
通過求解這個最優化式子,我們可以求得係數ai和基Φi,這些係數和基就是輸入的另外一種近似表達。
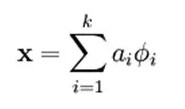
因此,它們可以用來表達輸入I,這個過程也是自動學習得到的。如果我們在上述式子上加上L1的Regularity限制,得到:
Min |I – O| + u*(|a1| + |a2| + … + |an |)
這種方法被稱爲Sparse Coding。通俗的說,就是將一個信號表示爲一組基的線性組合,而且要求只需要較少的幾個基就可以將信號表示出來。「稀疏性」定義爲:只有很少的幾個非零元素或只有很少的幾個遠大於零的元素。要求係數 ai 是稀疏的意思就是說:對於一組輸入向量,我們只想有儘可能少的幾個係數遠大於零。選擇使用具有稀疏性的分量來表示我們的輸入數據是有原因的,因爲絕大多數的感官數據,比如自然圖像,可以被表示成少量基本元素的疊加,在圖像中這些基本元素可以是面或者線。同時,比如與初級視覺皮層的類比過程也因此得到了提升(人腦有大量的神經元,但對於某些圖像或者邊緣只有很少的神經元興奮,其他都處於抑制狀態)。
稀疏編碼算法是一種無監督學習方法,它用來尋找一組「超完備」基向量來更高效地表示樣本數據。雖然形如主成分分析技術(PCA)能使我們方便地找到一組「完備」基向量,但是這裏我們想要做的是找到一組「超完備」基向量來表示輸入向量(也就是說,基向量的個數比輸入向量的維數要大)。超完備基的好處是它們能更有效地找出隱含在輸入數據內部的結構與模式。然而,對於超完備基來說,係數ai不再由輸入向量唯一確定。因此,在稀疏編碼算法中,我們另加了一個評判標準「稀疏性」來解決因超完備而導致的退化(degeneracy)問題。
比如在圖像的Feature Extraction的最底層要做Edge Detector的生成,那麼這裏的工作就是從Natural Images中randomly選取一些小patch,通過這些patch生成能夠描述他們的「基」,也就是右邊的8*8=64個basis組成的basis,然後給定一個test patch, 我們可以按照上面的式子通過basis的線性組合得到,而sparse matrix就是a,下圖中的a中有64個維度,其中非零項只有3個,故稱「sparse」。
這裏可能大家會有疑問,爲什麼把底層作爲Edge Detector呢?上層又是什麼呢?這裏做個簡單解釋大家就會明白,之所以是Edge Detector是因爲不同方向的Edge就能夠描述出整幅圖像,所以不同方向的Edge自然就是圖像的basis了……而上一層的basis組合的結果,上上層又是上一層的組合basis……(就是上面第四部分的時候咱們說的那樣)
Sparse coding分爲兩個部分:
1)Training階段:給定一系列的樣本圖片[x1, x 2, …],我們需要學習得到一組基[Φ1, Φ2, …],也就是字典。
稀疏編碼是k-means算法的變體,其訓練過程也差不多(EM算法的思想:如果要優化的目標函數包含兩個變量,如L(W, B),那麼我們可以先固定W,調整B使得L最小,然後再固定B,調整W使L最小,這樣迭代交替,不斷將L推向最小值。
訓練過程就是一個重複迭代的過程,按上面所說,我們交替的更改a和Φ使得下面這個目標函數最小。
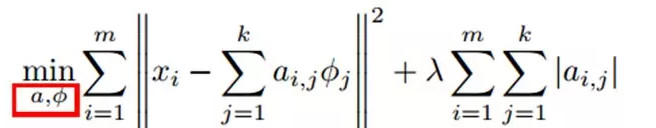
每次迭代分兩步:
a)固定字典Φ[k],然後調整a[k],使得上式,即目標函數最小(即解LASSO問題)。
b)然後固定住a [k],調整Φ [k],使得上式,即目標函數最小(即解凸QP問題)。
不斷迭代,直至收斂。這樣就可以得到一組可以良好表示這一系列x的基,也就是字典。
2)Coding階段:給定一個新的圖片x,由上面得到的字典,通過解一個LASSO問題得到稀疏向量a。這個稀疏向量就是這個輸入向量x的一個稀疏表達了。
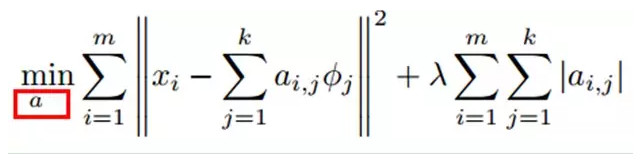
例如:

9.3、Restricted Boltzmann Machine (RBM)限制波爾茲曼機
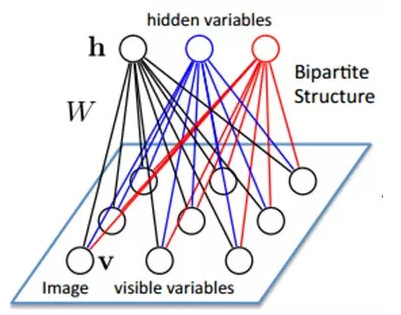
假設有一個二部圖,每一層的節點之間沒有鏈接,一層是可視層,即輸入數據層(v),一層是隱藏層(h),如果假設所有的節點都是隨機二值變量節點(只能取0或者1值),同時假設全概率分佈p(v,h)滿足Boltzmann 分佈,我們稱這個模型是Restricted BoltzmannMachine (RBM)。
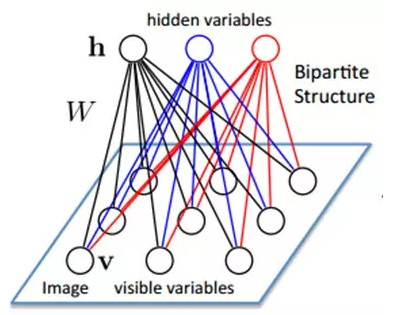
下面我們來看看爲什麼它是Deep Learning方法。首先,這個模型因爲是二部圖,所以在已知v的情況下,所有的隱藏節點之間是條件獨立的(因爲節點之間不存在連接),即p(h|v)=p(h1|v)…p(hn|v)。同理,在已知隱藏層h的情況下,所有的可視節點都是條件獨立的。同時又由於所有的v和h滿足Boltzmann 分佈,因此,當輸入v的時候,通過p(h|v) 可以得到隱藏層h,而得到隱藏層h之後,通過p(v|h)又能得到可視層,通過調整參數,我們就是要使得從隱藏層得到的可視層v1與原來的可視層v如果一樣,那麼得到的隱藏層就是可視層另外一種表達,因此隱藏層可以作爲可視層輸入數據的特徵,所以它就是一種Deep Learning方法。
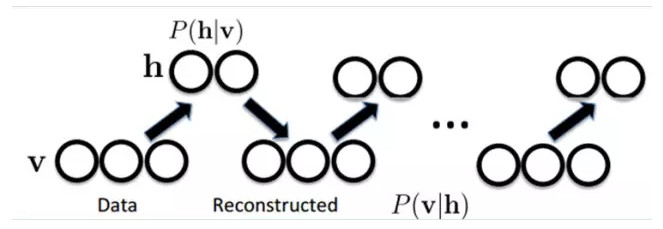
如何訓練呢?也就是可視層節點和隱節點間的權值怎麼確定呢?我們需要做一些數學分析。也就是模型了。
聯合組態(jointconfiguration)的能量可以表示爲:
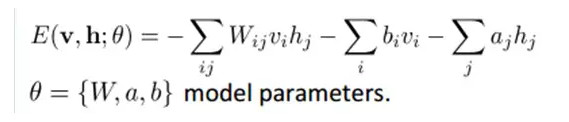
而某個組態的聯合概率分佈可以通過Boltzmann 分佈(和這個組態的能量)來確定:

因爲隱藏節點之間是條件獨立的(因爲節點之間不存在連接),即:
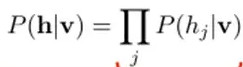
然後我們可以比較容易(對上式進行因子分解Factorizes)得到在給定可視層v的基礎上,隱層第j個節點爲1或者爲0的概率:
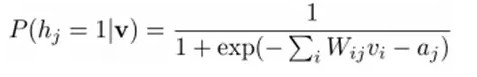
同理,在給定隱層h的基礎上,可視層第i個節點爲1或者爲0的概率也可以容易得到:
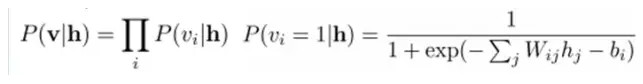
給定一個滿足獨立同分布的樣本集:D={v(1), v(2),…, v(N)},我們需要學習參數θ={W,a,b}。
我們最大化以下對數似然函數(最大似然估計:對於某個概率模型,我們需要選擇一個參數,讓我們當前的觀測樣本的概率最大):
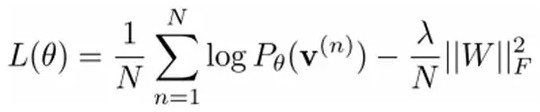
也就是對最大對數似然函數求導,就可以得到L最大時對應的參數W了。
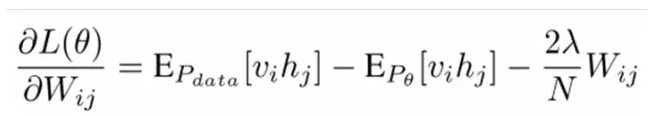
如果,我們把隱藏層的層數增加,我們可以得到Deep Boltzmann Machine(DBM);如果我們在靠近可視層的部分使用貝葉斯信念網絡(即有向圖模型,當然這裏依然限制層中節點之間沒有鏈接),而在最遠離可視層的部分使用Restricted Boltzmann Machine,我們可以得到DeepBelief Net(DBN)。
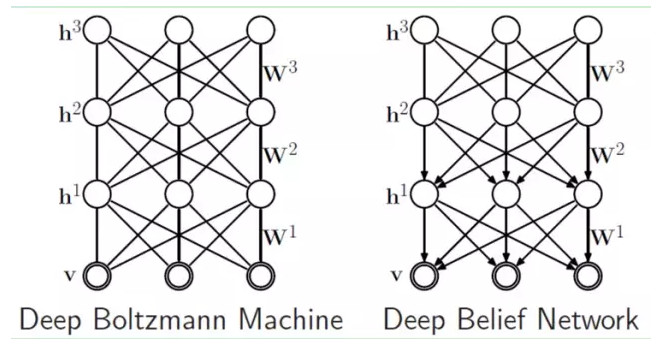
9.4、Deep Belief Networks深信度網絡
DBNs是一個概率生成模型,與傳統的判別模型的神經網絡相對,生成模型是建立一個觀察數據和標籤之間的聯合分佈,對P(Observation|Label)和 P(Label|Observation)都做了評估,而判別模型僅僅而已評估了後者,也就是P(Label|Observation)。對於在深度神經網絡應用傳統的BP算法的時候,DBNs遇到了以下問題:
(1)需要爲訓練提供一個有標籤的樣本集;
(2)學習過程較慢;
(3)不適當的參數選擇會導致學習收斂於局部最優解。
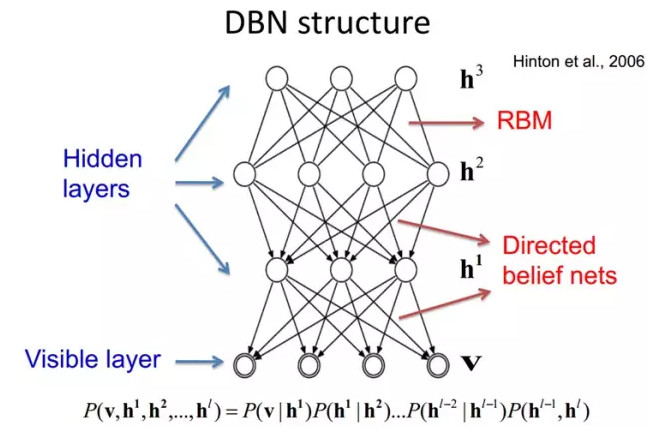
DBNs由多個限制玻爾茲曼機(Restricted Boltzmann Machines)層組成,一個典型的神經網絡類型如圖三所示。這些網絡被「限制」爲一個可視層和一個隱層,層間存在連接,但層內的單元間不存在連接。隱層單元被訓練去捕捉在可視層表現出來的高階數據的相關性。
首先,先不考慮最頂構成一個聯想記憶(associative memory)的兩層,一個DBN的連接是通過自頂向下的生成權值來指導確定的,RBMs就像一個建築塊一樣,相比傳統和深度分層的sigmoid信念網絡,它能易於連接權值的學習。
最開始的時候,通過一個非監督貪婪逐層方法去預訓練獲得生成模型的權值,非監督貪婪逐層方法被Hinton證明是有效的,並被其稱爲對比分歧(contrastive divergence)。
在這個訓練階段,在可視層會產生一個向量v,通過它將值傳遞到隱層。反過來,可視層的輸入會被隨機的選擇,以嘗試去重構原始的輸入信號。最後,這些新的可視的神經元激活單元將前向傳遞重構隱層激活單元,獲得h(在訓練過程中,首先將可視向量值映射給隱單元;然後可視單元由隱層單元重建;這些新可視單元再次映射給隱單元,這樣就獲取新的隱單元。執行這種反覆步驟叫做吉布斯採樣)。這些後退和前進的步驟就是我們熟悉的Gibbs採樣,而隱層激活單元和可視層輸入之間的相關性差別就作爲權值更新的主要依據。
訓練時間會顯著的減少,因爲只需要單個步驟就可以接近最大似然學習。增加進網絡的每一層都會改進訓練數據的對數概率,我們可以理解爲越來越接近能量的真實表達。這個有意義的拓展,和無標籤數據的使用,是任何一個深度學習應用的決定性的因素。
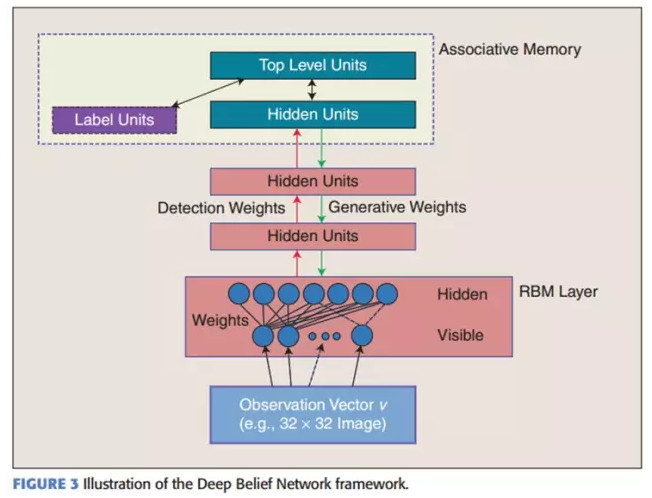
在最高兩層,權值被連接到一起,這樣更低層的輸出將會提供一個參考的線索或者關聯給頂層,這樣頂層就會將其聯繫到它的記憶內容。而我們最關心的,最後想得到的就是判別性能,例如分類任務裏面。
在預訓練後,DBN可以通過利用帶標籤數據用BP算法去對判別性能做調整。在這裏,一個標籤集將被附加到頂層(推廣聯想記憶),通過一個自下向上的,學習到的識別權值獲得一個網絡的分類面。這個性能會比單純的BP算法訓練的網絡好。這可以很直觀的解釋,DBNs的BP算法只需要對權值參數空間進行一個局部的搜索,這相比前向神經網絡來說,訓練是要快的,而且收斂的時間也少。
DBNs的靈活性使得它的拓展比較容易。一個拓展就是卷積DBNs(Convolutional Deep Belief Networks(CDBNs))。DBNs並沒有考慮到圖像的2維結構信息,因爲輸入是簡單的從一個圖像矩陣一維向量化的。而CDBNs就是考慮到了這個問題,它利用鄰域像素的空域關係,通過一個稱爲卷積RBMs的模型區達到生成模型的變換不變性,而且可以容易得變換到高維圖像。DBNs並沒有明確地處理對觀察變量的時間聯繫的學習上,雖然目前已經有這方面的研究,例如堆疊時間RBMs,以此爲推廣,有序列學習的dubbed temporal convolutionmachines,這種序列學習的應用,給語音信號處理問題帶來了一個讓人激動的未來研究方向。
目前,和DBNs有關的研究包括堆疊自動編碼器,它是通過用堆疊自動編碼器來替換傳統DBNs裏面的RBMs。這就使得可以通過同樣的規則來訓練產生深度多層神經網絡架構,但它缺少層的參數化的嚴格要求。與DBNs不同,自動編碼器使用判別模型,這樣這個結構就很難採樣輸入採樣空間,這就使得網絡更難捕捉它的內部表達。但是,降噪自動編碼器卻能很好的避免這個問題,並且比傳統的DBNs更優。它通過在訓練過程添加隨機的污染並堆疊產生場泛化性能。訓練單一的降噪自動編碼器的過程和RBMs訓練生成模型的過程一樣。
|十、總結與展望
1)Deep learning總結
深度學習是關於自動學習要建模的數據的潛在(隱含)分佈的多層(複雜)表達的算法。換句話來說,深度學習算法自動的提取分類需要的低層次或者高層次特徵。高層次特徵,一是指該特徵可以分級(層次)地依賴其他特徵,例如:對於機器視覺,深度學習算法從原始圖像去學習得到它的一個低層次表達,例如邊緣檢測器,小波濾波器等,然後在這些低層次表達的基礎上再建立表達,例如這些低層次表達的線性或者非線性組合,然後重複這個過程,最後得到一個高層次的表達。
Deep learning能夠得到更好地表示數據的feature,同時由於模型的層次、參數很多,capacity足夠,因此,模型有能力表示大規模數據,所以對於圖像、語音這種特徵不明顯(需要手工設計且很多沒有直觀物理含義)的問題,能夠在大規模訓練數據上取得更好的效果。此外,從模式識別特徵和分類器的角度,deep learning框架將feature和分類器結合到一個框架中,用數據去學習feature,在使用中減少了手工設計feature的巨大工作量(這是目前工業界工程師付出努力最多的方面),因此,不僅僅效果可以更好,而且,使用起來也有很多方便之處,因此,是十分值得關注的一套框架,每個做ML的人都應該關注瞭解一下。
當然,deep learning本身也不是完美的,也不是解決世間任何ML問題的利器,不應該被放大到一個無所不能的程度。
2)Deep learning未來
深度學習目前仍有大量工作需要研究。目前的關注點還是從機器學習的領域借鑑一些可以在深度學習使用的方法特別是降維領域。例如:目前一個工作就是稀疏編碼,通過壓縮感知理論對高維數據進行降維,使得非常少的元素的向量就可以精確的代表原來的高維信號。另一個例子就是半監督流行學習,通過測量訓練樣本的相似性,將高維數據的這種相似性投影到低維空間。另外一個比較鼓舞人心的方向就是evolutionary programming approaches(遺傳編程方法),它可以通過最小化工程能量去進行概念性自適應學習和改變核心架構。
Deep learning還有很多核心的問題需要解決:
(1)對於一個特定的框架,對於多少維的輸入它可以表現得較優(如果是圖像,可能是上百萬維)?
(2)對捕捉短時或者長時間的時間依賴,哪種架構纔是有效的?
(3)如何對於一個給定的深度學習架構,融合多種感知的信息?
(4)有什麼正確的機理可以去增強一個給定的深度學習架構,以改進其魯棒性和對扭曲和數據丟失的不變性?
(5)模型方面是否有其他更爲有效且有理論依據的深度模型學習算法?
探索新的特徵提取模型是值得深入研究的內容。此外有效的可並行訓練算法也是值得研究的一個方向。當前基於最小批處理的隨機梯度優化算法很難在多計算機中進行並行訓練。通常辦法是利用圖形處理單元加速學習過程。然而單個機器GPU對大規模數據識別或相似任務數據集並不適用。在深度學習應用拓展方面,如何合理充分利用深度學習在增強傳統學習算法的性能仍是目前各領域的研究重點。
