本文是一篇對於當今最先進的通用詞/句嵌入技術的簡介,包括對比基線: FastText、詞袋模型(Bag-of-Words);以及最先進的模型:ELMo、Skip-Thoughts、Quick-Thoughts、InferSent、MILA 研究組和微軟研究院提出的通用句子表徵,以及谷歌的通用句子編碼器。
詞語和句子的嵌入已經成爲了任何基於深度學習的自然語言處理系統必備的組成部分。
它們將詞語和句子編碼成稠密的定長向量,從而大大地提升通過神經網絡處理文本數據的能力。
當前主要的研究趨勢是追求一種通用的嵌入技術:在大型語料庫中預訓練的嵌入,它能夠被添加到各種各樣下游的任務模型中(情感分析、分類、翻譯等),從而通過引入一些從大型數據集中學習到的通用單詞或句子的表徵來自動地提升它們的性能。
它是遷移學習的一種體現形式。
儘管在相當長的一段時間內,對句子的無監督表示學習已經成爲了一種行業規範。但在最近的幾個月裏,人們開始逐漸轉向監督學習和多任務學習,並且在 2017 年底/2018 年初提出了一些非常有趣的方案。
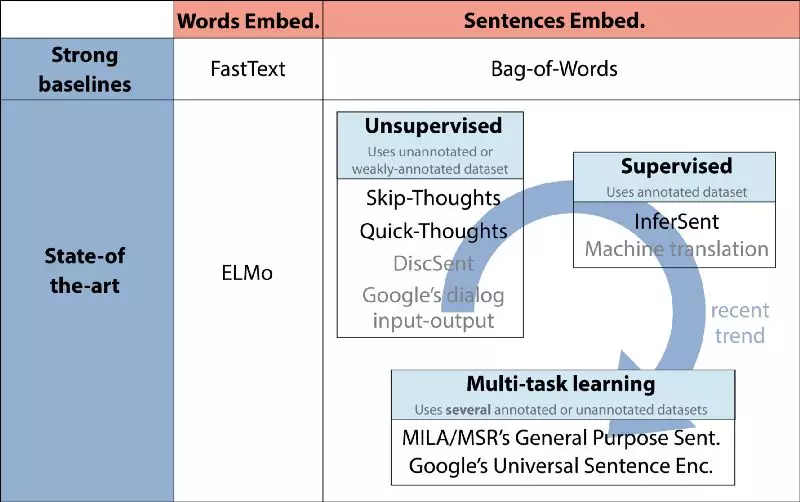 近期的通用詞/句嵌入的趨勢:在本文中,作者將介紹上圖中用黑體表示的模型。
近期的通用詞/句嵌入的趨勢:在本文中,作者將介紹上圖中用黑體表示的模型。
因此,本文是一篇對於當今最先進的通用詞/句嵌入技術的簡介,詳細討論了以下模型:
強大、快速的對比基線: FastText、詞袋模型(Bag-of-Words)
最先進的模型:ELMo、Skip-Thoughts、Quick-Thoughts、InferSent、MILA 研究組和微軟研究院提出的通用句子表徵,以及谷歌的通用句子編碼器。
讓我們從詞嵌入開始娓娓道來。
最近的詞嵌入研究進展
在過去的五年中,人們提出了大量可行的詞嵌入方法。目前最常用的模型是 word2vec 和 GloVe,它們都是基於分佈假設(在相同的上下文中出現的單詞往往具有相似的含義)的無監督學習方法。
儘管此後有一些研究(https://arxiv.org/abs/1805.04032)通過引入語義或者句法的監督信息來增強這些無監督方法,但是純粹的無監督學習方法在 2017 年到 2018 年得到了令人關注的提升,最著名的是「FastText」(word2vec 的一種拓展)以及「ELMo」(目前最先進的基於上下文的詞嵌入技術)。
FastText 由 Tomas Mikolov 的團隊提出,他曾在 2013 年提出了著名的 word2vec 框架,引發了通用詞嵌入技術的研究浪潮。
FastText 相對於原始的 word2vec 向量最主要的提升是它引入了 n 元字符(n-gram),這使得對沒有在訓練數據中出現的單詞(詞彙表外的單詞)計算單詞的表徵成爲了可能。
FastText 向量的訓練速度非常快,並且可以在 GitHub 上獲取通過「Wikipedia」和「Common Crawl」數據集上預訓練好的版本。它們是非常棒的對比基線。
深度上下文單詞表徵(ELMo)在很大的程度上提高了目前最先進的詞嵌入模型的性能。它們由 Allen 人工智能研究所研發,並將在 6 月初的 NAACL 2018(https://arxiv.org/abs/1802.05365)中展示。
 ELMo 能感知到豐富的單詞的上下文知識
ELMo 能感知到豐富的單詞的上下文知識
ELMo 模型會爲每一個單詞分配一個表徵,該表徵是它們所屬的整個語料庫中的句子的一個函數。詞嵌入將從一個兩層的雙向語言模型(LM)的內部狀態中計算出來,因此該模型被命名爲「ELMo」: Embeddings from Language Models(E 代表「嵌入」,LM 代表「語言模型」)。
ELMo 模型的特點:
ELMo 模型的輸入是字符而不是單詞。因此,它們可以利用子詞單元的優勢來計算有意義的單詞表示,即使這些單詞可能在詞彙表之外(就像 FastText 一樣)。
ELMo 是在雙向語言模型中的一些層上的激勵函數的串接。一個語言模型的不同層會對一個單詞的不同類型的信息進行編碼(例如,詞性標註(Part-Of-Speech tagging)由雙向 LSTM(biLSTM)的較低層很好地預測,而詞義排歧則由較高層更好地進行編碼)。將所有的層串接起來使得自由組合各種不同的單詞表徵成爲了可能,從而在下游任務中得到更好的模型性能。
現在讓我們轉而討論通用句子嵌入。
通用句子嵌入的興起

目前有許多相互競爭的學習句子嵌入的方案。儘管像平均詞嵌入這樣簡單的基線也能夠一直給出很好的實驗結果,但一些新的類似於無監督和監督學習以及多任務學習的方法,在 2017 年底 2018 年初出現在了人們的視野中,並且取得了令人矚目的性能提升。
讓我們快速瀏覽一下目前研究出來的四種嵌入方法吧:從簡單的詞向量平均的基線到無監督/監督學習方法,以及多任務學習方案(如上文所述)。
在這個領域有一個廣泛的共識(http://arxiv.org/abs/1805.01070),那就是:直接對句子的詞嵌入取平均(所謂的詞袋模型(Bag-of-Word,BoW))這樣簡單的方法可以爲許多下游任務提供一個很強大的對比基線。
Arora 等人在 ICLR 2017 上提出了「A Simple but Tough-to-Beat Baseline for Sentence Embeddings」(https://openreview.net/forum?id=SyK00v5xx),這是一個很好的能夠被用於計算這個基線(BoW)的算法,算法的大致描述如下:選擇一個流行的詞嵌入方法,通過詞向量的線性的加權組合對一個句子進行編碼,並且刪除共有的部分(刪除它們的第一個主成分上的投影)。這種通用的方法有更深刻和強大的理論動機,它依賴於一個生成模型,該生成模型使用了一個語篇向量上的隨機遊走生成文本。(這裏不討論理論細節。)
 「HuggingFace」對話的詞袋模型的示意圖。詞袋模型弱化了詞語的順序關係,但保留了大量的語義和句法的信息。在 ACL 2018 上,Conneau 等人對此提出了有趣的見解(http://arxiv.org/abs/1805.01070)。
「HuggingFace」對話的詞袋模型的示意圖。詞袋模型弱化了詞語的順序關係,但保留了大量的語義和句法的信息。在 ACL 2018 上,Conneau 等人對此提出了有趣的見解(http://arxiv.org/abs/1805.01070)。
除了簡單的詞向量平均,第一個主要的提議是使用無監督學習訓練目標,這項工作是起始於 Jamie Kiros 和他的同事們在 2015 年提出的「Skip-thought vectors」(https://arxiv.org/abs/1506.06726)。
無監督方案將句子嵌入作爲通過學習對一個句子中一致且連續的短句或從句進行預測的副產品來學習句子嵌入。理論上,這些方法可以利用任何包含以一致的方式並列的短句/從句的文本數據集。
「Skip-thoughts vector」是一個典型的學習無監督句子嵌入的案例。它可以被認爲相當於爲詞嵌入而開發的「skip-gram」模型的句子向量,我們在這裏試圖預測一個給定的句子周圍的句子,而不是預測一個單詞周圍的其他單詞。該模型由一個基於循環神經網絡的編碼器—解碼器結構組成,研究者通過訓練這個模型從當前句子中重構周圍的句子。
Skip-Thoughts 的論文中最令人感興趣的觀點是一種詞彙表擴展方案:Kiros 等人通過在他們的循環神經網絡詞嵌入空間和一個更大的詞嵌入空間(例如,word2vec)之間學習一種線性變換來處理訓練過程中沒有出現的單詞。
「Quick-thoughts vectors」(https://openreview.net/forum?id=rJvJXZb0W)是研究人員最近對「Skip-thoughts vectors」的一個改進,它在今年的 ICLR 上被提出。在這項工作中,在給定前一個句子的條件下預測下一個句子的任務被重新定義爲了一個分類問題:研究人員將一個用於在衆多候選者中選出下一個句子的分類器代替瞭解碼器。它可以被解釋爲對生成問題的一個判別化的近似。
該模型的運行速度是它的優點之一(與 Skip-thoughts 模型屬於同一個數量級),使其成爲利用海量數據集的一個具有競爭力的解決方案。
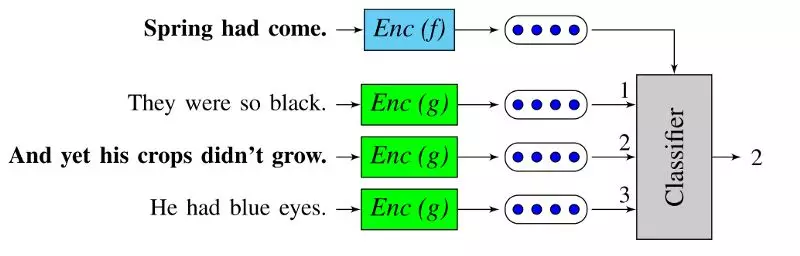 「Quick-thoughts」分類任務示意圖。分類器需要從一組句子嵌入中選出下一個句子。圖片來自 Logeswaran 等人所著的「An efficient framework for learning sentence representations」。
「Quick-thoughts」分類任務示意圖。分類器需要從一組句子嵌入中選出下一個句子。圖片來自 Logeswaran 等人所著的「An efficient framework for learning sentence representations」。
在很長一段時間內,人們認爲監督學習技術比無監督學習技術得到的句子嵌入的質量要低一些。然而,這種假說最近被推翻了,這要部分歸功於「InferSent」(https://arxiv.org/abs/1705.02364)的提出。
與之前詳細討論的無監督學習不同,監督學習需要一個帶標籤的數據集,爲一些像自然語言推理(例如:有蘊含關係的句子對)或者機器翻譯(例如:翻譯前後的句子對)這樣的任務進行標註。監督學習提出了以下兩個問題:(1)如何選擇特定任務?(2)若要獲得高質量的嵌入,所需的數據集大小應該如何確定?在本文的下一節和最後一節,作者將會對多任務學習進行進一步的討論。但在這之前,讓我們一起來看看 2017 年發佈的 InferSent 背後的原理。
InferSent 具有非常簡單的架構,這使得它成爲了一種非常有趣的模型。它使用 Sentence Natural Language Inference(NLI)數據集(該數據集包含 570,000 對帶標籤的句子,它們被分成了三類:中立、矛盾以及蘊含)訓練一個位於句子編碼器頂層的分類器。兩個句子使用同一個編碼器進行編碼,而分類器則是使用通過兩個句子嵌入構建的一對句子表徵訓練的。Conneau 等人採用了一個通過最大池化操作實現的雙向 LSTM 作爲編碼器。
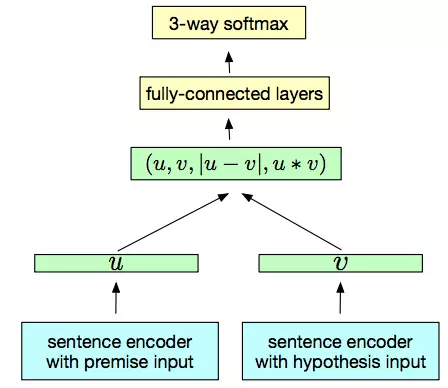 一個用於對 Sentence Natural Language Inference 進行學習的有監督的句子嵌入模型(InferSent)。此圖來自 A.Conneau 等人所著的「Supervised Learning of Universal Sentence Representations from Natural Language Inference Data」。
一個用於對 Sentence Natural Language Inference 進行學習的有監督的句子嵌入模型(InferSent)。此圖來自 A.Conneau 等人所著的「Supervised Learning of Universal Sentence Representations from Natural Language Inference Data」。
InferSent 的成功不僅導致了對選擇最佳的神經網絡模型的探索,它還引發了對以下問題的研究:
哪種監督訓練任務能夠學到能更好地泛化到下游任務中去的句子嵌入呢?
多任務學習可以被視爲對 Skip-Thoughts、InferSent,以及其他相關的無監督/監督學習方案的一種泛化,它通過試着將多個訓練目標融合到一個訓練方案中來回答這個問題(上文提到的問題)。
在 2018 年初,研究人員發佈了一系列最新的多任務學習的方案。讓我們快速的瀏覽一下 MILA 和微軟研究院提出的「通用目的句子表徵」和谷歌的「通用句子編碼器」。
在 ICLR 2018 上發表的描述 MILA 和微軟蒙特利爾研究院的工作的論文《Learning General Purpose Distributed Sentence Representation via Large Scale Multi-Task Learning》(https://arxiv.org/abs/1804.00079)中,Subramanian 等人觀察到,爲了能夠在各種各樣的任務中泛化句子表徵,很有必要將一個句子的多個層面的信息進行編碼。
因此,這篇文章的作者利用了一個一對多的多任務學習框架,通過在不同的任務之間進行切換去學習一個通用的句子嵌入。被選中的 6 個任務(對於下一個/上一個句子的 Skip-thoughts 預測、神經機器翻譯、組別解析(constituency parsing),以及神經語言推理)共享相同的由一個雙向門控循環單元得到的句子嵌入。實驗表明,在增添了一個多語言神經機器翻譯任務時,句法屬性能夠被更好地學習到,句子長度和詞序能夠通過一個句法分析任務學習到,並且訓練一個神經語言推理能夠編碼語法信息。
谷歌在 2018 年初發布的的通用句子編碼器(https://arxiv.org/abs/1803.11175)也使用了同樣的方法。他們的編碼器使用一個在各種各樣的數據源和各種各樣的任務上訓練的轉換網絡,旨在動態地適應各類自然語言理解任務。該模型的一個預訓練好的版本可以在 TensorFlow 獲得。
以上就是我們對於通用的詞語和句子嵌入的簡要總結。
在過去的短短的幾個月中,這個領域取得了很多令人矚目的發展,並且在評價和探索這些嵌入的性能以及其內在的偏差/公平性的方面(這是討論通用的嵌入時的一個真實存在的問題)有了很大的進步。
原文鏈接:https://medium.com/huggingface/universal-word-sentence-embeddings-ce48ddc8fc3a