選自offconvex.org
作者:Sanjeev Arora
近年來的深度神經網絡研究進展往往都重方法而輕理論,但理論研究能夠幫助我們更好地理解深度學習成功背後的真正原因,並有望爲進一步的研究指明方向。近日,普林斯頓大學計算機科學教授 Sanjeev Arora 發表博文介紹了在深度網絡泛化上的理論,我們對本文進行了編譯介紹。
深度學習的理論還存在諸多神祕之處。近來很多機器學習理論研究者都在關注神祕的泛化(generalization):爲什麼訓練後的深度網絡能在之前並未見過的數據上取得良好的表現,即便它們的自由參數的數量遠遠超過了數據點的數量(經典的「過擬合」情況)?張馳原等人的論文《理解深度學習需要重新思考泛化(Understanding Deep Learning requires Rethinking Generalization)》爲這一難題帶來了一些關注。論文地址:https://arxiv.org/abs/1611.03530。他們的主要實驗發現是:如果你在帶有隨機標籤的圖像上訓練一個經典的卷積網絡架構(比如 Alexnet),那麼你仍然可以在這些訓練數據上實現非常高的準確度。(此外,人們認爲有助於實現更好的泛化的常見正則化策略其實幫助不大。)不用說,這個訓練後的網絡之後並不能預測仍未見過的圖像的(隨機)標籤,這就意味着它不能泛化。這篇論文指出將分類器與帶有隨機標籤的數據進行擬合的能力也是機器學習領域內的一種傳統方法,該方法被稱爲 Rademacher 複雜度(後面我們會討論),因此 Rademacher 複雜度在樣本複雜度上並沒有有意義的邊界。我覺得這篇論文寫得很有意思,推薦閱讀。該論文獲得了 ICLR 2017 最佳論文獎,恭喜作者。
但在 2017 年春季關於理論機器學習的 Simons Institute 課程上,泛化理論專家表達了對這篇論文的不滿,尤其是其標題。他們認爲相似的問題已經在更簡單的模型上得到過廣泛的研究了,比如 kernel SVM(核支持向量機)(老實說,這篇論文裏也明確提到過)。設計具有很高 Rademacher 複雜度同時又能在真實數據上很好地訓練和泛化的支持向量機架構是很簡單的。此外,用於解釋這種泛化行爲的理論也已經得到了發展(而且還適用於 boosting 等相關模型)。在一個相關的說明中,Behnam Neyshabur 及其聯合作者的幾篇更早期的論文已經提出了與張弛原等人對深度網絡的看法相當相似的觀點。
但不管這些吐槽抱怨,張弛原等人的論文讓人們關注起這個核心的理論難題了,我們應該感到高興。實際上,在 Simons Institute 課程上的熱情討論者自己也組成了小組來解決這個難題,這帶來了多篇論文(其中後兩篇出現在了 NIPS' 17 上):
Dzigaite 和 Roy 的論文《Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data》:https://arxiv.org/abs/1703.11008
Bartlett、Foster 和 Telgarsky 的論文《Spectrally-normalized margin bounds for neural networks》https://arxiv.org/abs/1706.08498
Neyshabur、Bhojapalli、MacAallester 和 Srebro 的論文《A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks》:https://arxiv.org/abs/1707.09564
在解讀這些研究結果之前,我先說明一下對張弛原等人論文的標題的部分爭議源自一些基本的困惑,即當前的泛化理論是規範性的還是僅僅是描述性的。這些困惑由源自課程和教科書對泛化理論的標準對待方式,我在我的研究生課程上教授最近的進展時也發現了這一點。

規範性理論還是描述性理論
爲了闡釋兩者的差異,假設有一位病人對其醫生說:「醫生,我晚上常常醒來而且一天都很累。」
醫生 1(沒有進行任何身體檢查):「哦,你患了失眠症。」
我將這種診斷稱爲描述性的(deive),因爲這只是給該病人的問題分配一個標籤,而沒有給出如何解決該問題的任何見解。與之相反:
醫生 2(經過仔細的身體檢查後):「你的鼻竇增生導致睡眠呼吸暫停。移除它可以解決你的問題。」
這樣的診斷是規範性的(preive)。
泛化理論:描述性還是規範性?
比如 VC 維、Rademacher 複雜度和 PAC-Bayes 邊界等泛化理論概念是爲缺乏泛化的基本現象賦予一個描述性標籤。對於今天覆雜的機器學習模型來說,它們很難計算,更不要說用來指導學習系統的設計了。
想一下如果假設/分類器 h 不能泛化,會意味着什麼。假設訓練數據是由 m 個樣本 S=(x1,y1),(x2,y2),…,(xm,ym) 構成的,這些樣本來自於分佈 D。損失函數 ℓ描述了假設 h 分類數據點的水平:如果該假設在 x 上不能得到接近的標籤 y,那麼損失 ℓ(h,(x,y)) 就高;如果接近,則損失就低。(舉個例子,迴歸損失是
,現在我們用表示 S 中樣本點的平均損失,用表示在來自分佈 D 的樣本上的預期損失。如果假設 h 對於隨機樣本 S 都能得到最小的,並且在全分佈上也能實現非常近似的損失,那麼這個訓練就是泛化的。如果沒有得到這樣的結果,我們就說:
缺乏泛化:
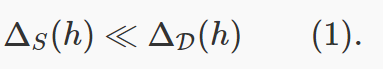
在實踐中,缺乏泛化是通過從 D 中取另一個大小爲 m 的樣本(「留存集」)S2 來檢測的。通過 concentration bounds,h 在這第二個樣本上的預期損失近似接近於,讓我們可以總結得到:
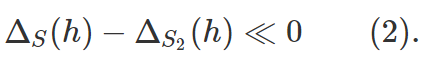
泛化理論:描述性部分
我們現在討論 Rademacher 複雜度,本文中的討論會有所簡化。詳情可參閱我的課程筆記:https://www.cs.princeton.edu/courses/archive/fall17/cos597A/lecnotes/generalize.pdf。在這裏的討論中,爲了方便起見,假設標籤和損失是 0 和 1,並且假設泛化能力糟糕的 h 在訓練樣本 S 上的表現完美但在留存集 S2 上的完全錯誤,也就是說:
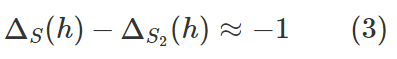
Rademacher 複雜度涉及到下面的思想實驗。從 D 中取大小爲 2m 的單個樣本集,然後將其分成兩半,其中一半是 S,另一半是 S2。翻轉 S2 中點的標籤。現在嘗試尋找能最好地描述這些新樣本的分類器 C,也就是說最小化
爲什麼呢?因爲翻轉點的標籤可以將好的分類變成糟糕的分類,或反過來,因此 S2 的損失函數是 1 減去翻轉前的損失。如果這個量有很高的概率很小(比如接近於 0),那麼我們就說這個分類器的類別的 Rademacher 複雜度高。
但 (3) 式表明 Rademacher 複雜度高的情況是:S、S2 是來自 D 的大小爲 m 的隨機樣本,所以它們的總大小是 2m;當泛化失敗時,我們就成功找到了使
非常小的假設 h。
換句話說,繼續用醫療的例子類比,醫生只需聽到「泛化沒有發生」就得到結論「Rademacher 複雜度高」。所以我說這個結果是描述性的。
類似地,VC 維邊界也是描述性的。如果存在一個大小爲 k 的集合使得下面的結果成立,那麼 VC 維至少是 k+1。如果我們檢查類別中的所有可能的分類器,並且該標籤序列中每一個標籤都給了樣本中的 k 個數據點,那麼我們可以找到 0 和 1 構成的所有可能的 2^k 個序列。
如果泛化確實如 (2) 或 (3) 式中那樣發生了,那麼這就說明對於一些 ϵ>0 而言,VC 維至少是在 ϵm 附近。原因是當將 2m 個數據點隨機分割成 S 和 S2 時,存在種分割方式。當泛化錯誤是 Ω(1) 時,這就說明我們可以使用所有可能的分類器得到 2m 個數據點的個標籤。現在可以使用經典的 Sauer 引理(參閱:https://www.cs.princeton.edu/courses/archive/spring14/cos511/scribe_notes/0220.pdf)來證明對於一些常量 ϵ>0,VC 維至少爲 ϵm/log m。
因此,再次類比一下,醫生只需聽到「泛化沒有在樣本大小爲 m 的情況下實現」就得到結論「VC 維高於Ω(m/logm)」。
我們也可以類似地證明 PAC-Bayes 邊界也是描述性的,你可以在我的課程筆記中看到:http://www.cs.princeton.edu/courses/archive/fall17/cos597A/lecnotes/generalize.pdf
爲什麼學生搞不清楚,認爲這樣的泛化理論工具能爲機器學習算法的設計提供一些強有力的技術呢?
答案:也許是因爲教學筆記和教科書中的標準演示就像是在假設我們在計算上是萬能的——好像我們可以計算 VC 維和 Rademacher 複雜度並因此能在可實現泛化的訓練所需的樣本規模上達到有意義的邊界。儘管之前在使用簡單的分類器的時候也許能辦到,但現在我們的複雜分類器具有數以百萬計的變量,而且這些變量還是反向傳播等非凸優化技術的產物。爲了降低這種複雜學習架構的 Rademacher 複雜度的邊界,實際上唯一的方法是在訓練分類器後通過留存集檢測泛化的缺乏。這一領域的每個實踐者都在這樣做(卻沒有意識到),張弛原等人強調了現在的理論毫無助益,這一點值得稱讚。
尋找規範性泛化理論:新論文
在我們的醫學類比中,我們看到醫生至少需要做一次身體檢查才能得到規範性的診斷。這些新論文的作者也直觀地把握住了這一點並且試圖確定可能實現更好泛化的真實神經網絡的性質。幾十年前有人在簡單的 2 層網絡上進行過這樣的分析(與「邊際(margin)」相關),其中的難點是尋找與多層網絡的類比。Bartlett 等人和 Neyshabur 等人都深入研究了深度網絡的層的權重舉證的穩定秩(stable rank)。這些可被看作是「flat minimum」的一個實例,多年來神經網絡方面的文獻一直在討論這個問題。我將在未來的文章中給出我對這些結果的理解和一些改進。注意,這些方法目前還未給出任何有關訓練網絡所需數據點數量的不尋常的邊界。
Dziugaite 和 Roy 選擇了稍有不同的方向。他們的工作始於 McAllester 的 1999 PAC-Bayes 邊界,也即:如果該算法在假設上的先驗分佈是 P,那麼對於在該假設上的每個後驗分佈 Q(可能取決於數據),根據 Q 所選擇的平均分類器的泛化誤差的上界如下,其中 D() 表示 KL 散度:
這使得可以通過 Langford 和 Caruana 之前的論文((Not) Bounding the True Error)中類似的過程爲泛化誤差設置上界,其中 P 是均勻高斯,Q 是訓練後的深度網絡的有噪聲版本(我們想要解釋它的泛化)。具體來說,如果 w_ij 是該訓練後網絡中邊 i,j 的權重,那麼爲權重 w_ij 增加高斯噪聲 η_ij 就構成了 Q。因此根據 Q 所得到的隨機分類器不過是該訓練後網絡的一個有噪聲版本而已。現在我們看到關鍵了:使用非凸優化來尋找 η_ij 的方差的一個選擇,使之能在兩個不相容的指標上找到平衡:(a)源自 Q 的平均分類器的訓練誤差不比原來的訓練後的網絡多很多(同樣,這是通過優化找到的極小值的「平坦度」的量化);(b)上面表達式的右邊儘可能小。假設(a)和(b)都可以適當地確定邊界,那麼源自 Q 的平均分類器可以在未曾見過的數據上表現得相當好。(注意這種方法只是證明了訓練後的分類器的有噪聲版本的泛化能力。)
將這種方法應用到在 MNIST 數據集上訓練的簡單全連接神經網絡上,他們可以證明這種方法可在 MNIST 上實現 17% 的誤差(實際誤差要低得多,在 2% 到 3% 之間)。他們的論文也由此得名,承諾有非空虛(nonvacuous)的泛化邊界。對於這個結果,我覺得最有意思的是它使用了非凸優化的能力(在上面被用來尋找一個合適的噪聲分佈 Q)來闡釋有關非凸優化的一個元問題,即深度學習不過擬合的原因是什麼。
原文鏈接:http://www.offconvex.org/2017/12/08/generalization1/