作者:Hojjat Salehinejad等
近日,來自多倫多大學和滑鐵盧大學的研究者撰文介紹循環神經網絡的基礎知識、近期發展和面臨的挑戰。我們對該論文進行了編譯介紹,重點介紹了論文第二部分循環神經網絡的基礎與第四部分循環神經網絡架構,其中我們概覽了該論文所討論的11種RNN架構。其它部分的詳細內容和推導過程請見原論文。

人工神經網絡(ANN)由多層互相連接的稱爲人工神經元的單元構成。「淺層網絡」指的是沒有循環連接,且只有一個輸入層、一個輸出層,並至多隻有一個隱藏層的 ANN。隨着網絡層數增加,複雜度也增加。層數或循環連接數的增加通常會增加網絡的深度,從而使網絡能提供多層次的數據表徵以及特徵提取,即「深度學習」。一般而言,這些網絡由非線性的、簡單的單元構成,其中更高的層提供數據的更抽象表徵,並壓制不需要的可變性 [1]。由於每個層的非線性構成帶來的優化困難 [2],直到 2006 年出現重大研究進展之前 [2][3],關於深度網絡架構的研究工作很少。結合了循環連接的 ANN 被稱爲循環神經網絡(RNN),可以對序列數據建模,用於序列識別和預測 [4]。RNN 隱藏狀態的結構以循環形成記憶的形式工作,每一時刻的隱藏層的狀態取決於它的過去狀態 [6]。這種結構使得 RNN 可以保存、記住和處理長時期的過去複雜信號。RNN 可以在當前時間步將輸入序列映射到輸出序列,並預測下一時間步的輸出。
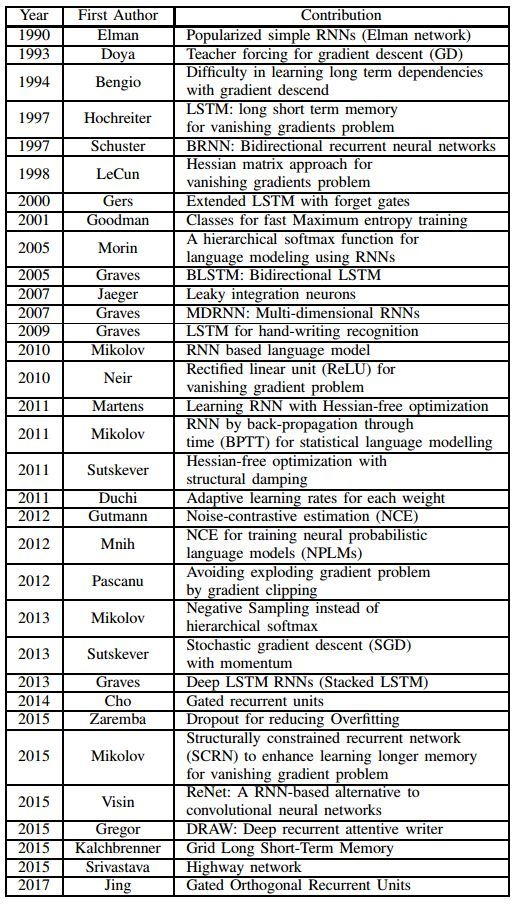
從架構設計到應用開發,關於 RNN 的文獻已經有大量的論文發表。在本文中,作者重點討論了離散時間的 RNN 和該領域的最新研究進展,並在表 1 中列出了 RNN 的長期主要進展。反向傳播和梯度下降方法的開發使得訓練 RNN 變得很高效,加快了開發 RNN 的實際成就 [5]。然而,對長期依賴的序列數據還存在一些挑戰,例如梯度消失和梯度爆炸問題,本文將討論這些問題。
我們重點介紹了第二部分循環神經網絡的基礎與第四部分循環神經網絡的架構。該論文的第三部分重點解釋了循環神經網絡的訓練方法,如基於梯度的方法與沿時間反向傳播等,我們並不詳細探討這一部分的具體方法。後面第四部分討論了循環神經網絡的正則化方法,限於篇幅,我們也不會過多描述。
論文:Recent Advances in Recurrent Neural Networks

論文鏈接:https://arxiv.org/pdf/1801.01078.pdf
循環神經網絡(RNN)能夠從序列和時序數據中學習特徵和長期依賴關係。RNN 具備非線性單元的堆疊,其中單元之間至少有一個連接形成有向循環。訓練好的 RNN 可以建模任何動態系統;但是,訓練 RNN 主要受到學習長期依賴性問題的影響。本論文對 RNN 進行研究,爲該領域的新人和專業人員展示多項新的進展。本文介紹了 RNN 的基礎知識、近期進展和研究挑戰。
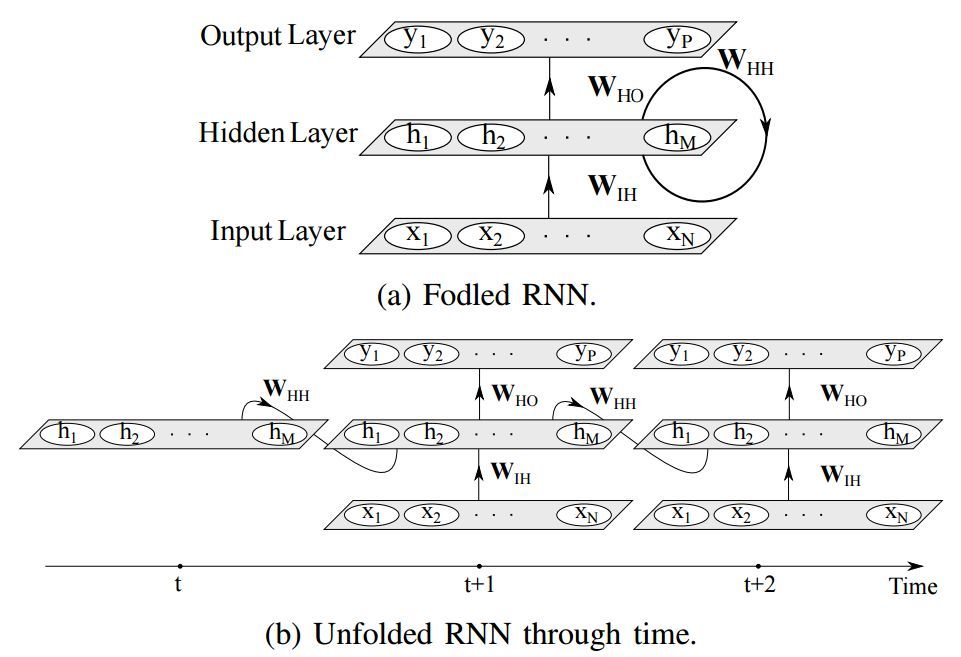
圖 1:簡單的循環神經網絡(RNN)及其沿時間 t 的展開結構。每一個箭頭代表層之間單元間的全連接。爲簡潔起見,本圖未顯示偏置項。
II. 循環神經網絡基礎
RNN 是一類監督式機器學習模型,由人工神經元和一或多個反饋循環構成 [7]。反饋循環指時間或序列(本文以下使用「時間」)的循環週期 [8],如圖 1 所示。以監督式方法訓練 RNN 需要一個輸入-目標對的訓練數據集。其目的在於通過優化網絡權重最小化輸出和目標對(即損失值)的差。
A. 模型架構
簡單 RNN 有三層:輸入層、循環隱藏層和輸出層,如圖 1a 所示。輸入層中有 N 個輸入單元。該層的輸入是一系列沿時間 t 的向量 {..., x_t−1, x_t, x_t+1, ...},其中 x_t = (x_1, x_2, ..., x_N)。全連接 RNN 中的輸入單元與隱藏層中的隱藏單元連接,該連接由權重矩陣 W_IH 定義。隱藏層有 M 個隱藏單元 h_t = (h_1, h_2, ..., h_M),它們通過網絡定義的循環結構沿時間彼此連接,如圖 1b。使用較小非零元素的隱藏單元初始化能夠提升網絡的整體性能和穩定性 [9]。隱藏層將狀態空間或系統的「memory」定義爲:
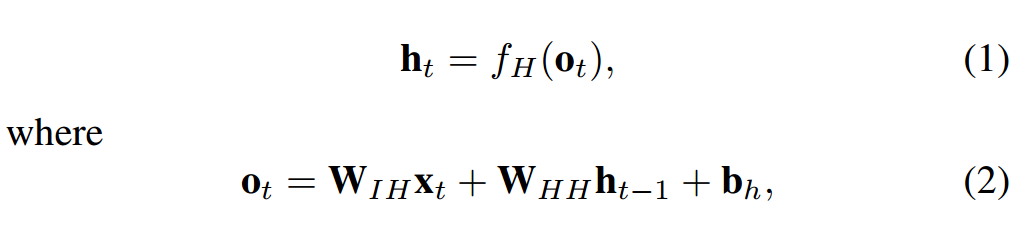
其中 f_H(·) 是隱藏層激活函數,b_h 是隱藏單元的偏置向量。隱藏單元與輸出層連接,連接權重爲 W_HO。輸出層有 P 個單元 y_t = (y_1, y_2, ..., y_P ),可以計算爲:
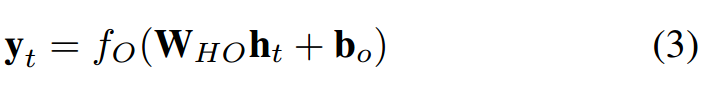
其中 f_O(·) 是激活函數,b_o 是輸出層的偏置向量。由於輸入-目標對是沿時間的序列,因此上述步驟隨着時間 t = (1, ..., T ) 重複。公式 (1) 和 (3) 展示了 RNN 由特定非線性狀態公式構成,該公式沿時間迭代。在每個時間步中,隱藏狀態根據輸入向量預測輸出。RNN 的隱藏狀態是一組值的集合(除去任何外部因素的影響),該集合總結了與該網絡在之前很多時間步上的狀態相關的必要信息。該整合信息可定義該網絡的未來行爲,作出準確的輸出預測 [5]。RNN 在每個單元中使用一個簡單的非線性激活函數。但是,如果此類簡單結構沿時間步經過良好訓練,則它能夠建模豐富的動態關係。
B. 激活函數
線性網絡中,多個線性隱藏層充當單個線性隱藏層 [10]。非線性函數比線性函數強大,因爲它們可以繪製非線性邊界。RNN 中一個或多個連續隱藏層中的非線性是學習輸入-目標關係的關鍵。
圖 2 展示了一些最流行的激活函數。近期 Sigmoid、Tanh 和 ReLU 得到了更多關注。Sigmoid 函數是常見選擇,它將真值歸一化到 [0, 1] 區間。該激活函數常用語輸出層,其中交叉熵損失函數用於訓練分類模型。Tanh 和 Sigmoid 激活函數分別被定義爲:
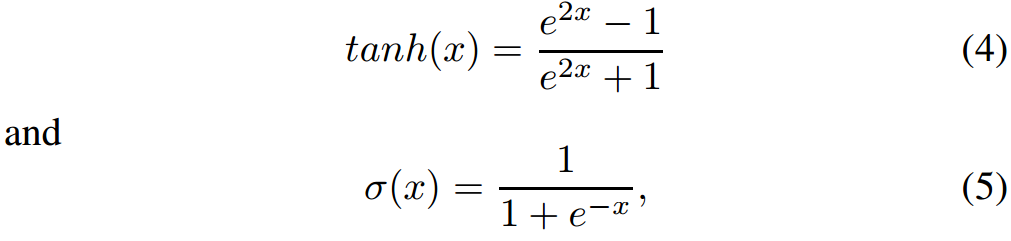
Tanh 激活函數實際上是縮放的 Sigmoid 函數,如:
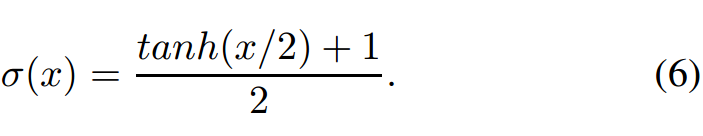
ReLU 是另一個常用激活函數,向正輸入值開放 [3],定義爲 y(x) = max(x, 0)。
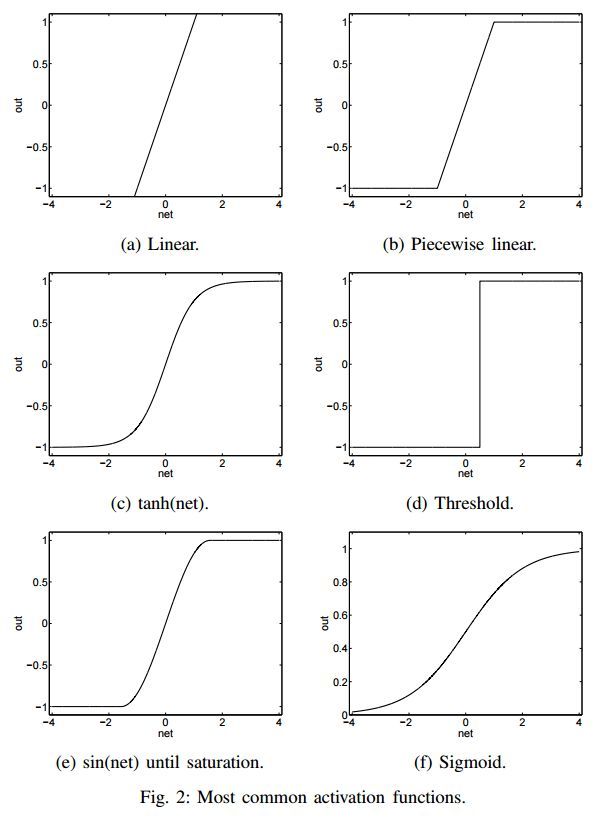
激活函數的選擇主要取決於具體問題和數據的本質。例如,Sigmoid 函數適合輸出區間爲 [0, 1] 的網絡。而 Tanh 和 Sigmoid 函數會使神經元快速飽和,並導致梯度消失。Sigmoid 的輸出不以零爲中心會導致不穩定的權重梯度更新。與 Sigmoid 和 Tanh 函數相比,ReLU 激活函數導致更加稀疏的梯度,並大幅加快隨機梯度下降(SGD)的收斂速度 [11]。ReLU 函數的計算成本低廉,因其可通過將激活值二值化爲零來實現。但是,ReLU 無法抵抗大型梯度流(gradient flow),隨着權重矩陣增大,神經元可能在訓練過程中保持未激活狀態。
C. 損失函數
損失函數通過對比輸出 y_t 和目標 z_t 之間的差距而評估了神經網絡的性能,它可以形式化表達爲:
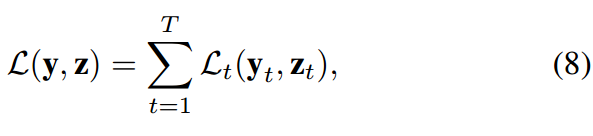
該表達式對每一個時間步 [12] 上的損失進行求和而得出最終的損失函數。損失函數的挑選一般與具體問題相關,一般比較流行的損失函數包括預測實數值的歐幾里德距離和 Hamming 距離,和用於分類問題 [13] 的交叉熵損失函數。
III. 訓練循環神經網絡
有效地訓練 RNN 一直是重要的話題,該問題的難點在於網絡中難以控制的權重初始化和最小化訓練損失的優化算法。這兩個問題很大程度上是由網絡參數之間的關係和隱藏狀態的時間動態而引起 [4]。本論文文獻綜述所展現的關注點很大程度上都在於降低訓練算法的複雜度,且加速損失函數的收斂。然而,這樣的算法通常需要大量的迭代來訓練模型。訓練 RNN 的方法包括多表格隨機搜索、時間加權的僞牛頓優化算法、梯度下降、擴展 kalman 濾波(EKF)[15]、Hessian-free、期望最大化(EM)[16]、逼近的 Levenberg-Marquardt [17] 和全局優化算法。在這一章節中,本論文具體討論了這樣一些方法。
該論文具體介紹了基於梯度的方法,下表展示了 GD 算法各種變體的優勢缺點,其中 N 爲神經網絡的結點數、O(.) 爲每個數據點的複雜度:
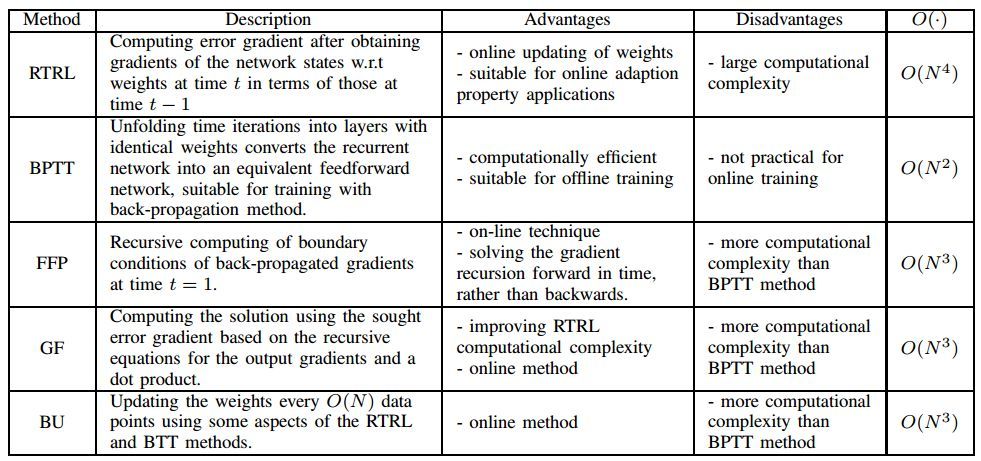
其中 BPTT 可能是非常流行的算法,如下所示,當網絡隨時間推移接收到新的輸入,沿時間反向傳播將重寫激活函數中的隱藏單元。
該論文還討論了其它非常流行的 SGD 優化策略和二階梯度優化,如下展示了一般動量法和 Nesterov 加速梯度法之間的差異。
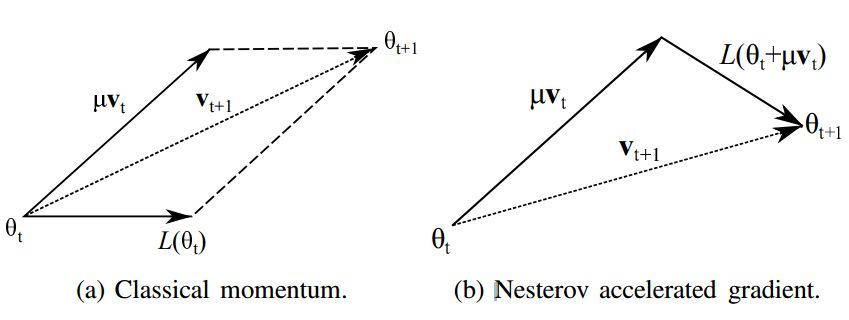
如上所示,左圖爲一般的動量法,它相當於歷史梯度方向和當前梯度方向的加權求和而得到當前最終的下降方向。而右圖的 Nesterov 加速梯度法先嚐試性地在累積梯度方向上前進一大步,然後再使用當前位置的梯度修正累積梯度而得到最終的下降方向。
這一部分還包含很多優化方法與策略,更詳細的內容請查看原論文。
IV. 循環神經網絡架構
在該論文中,作者描述了 11 種循環神經網絡架構,而且每一種可能還包括一些變體,例如 LSTM 就有八種變體。但限於文章的篇幅,我們只簡要介紹了這 11 種循環神經網絡架構的基本概念,並且根據我們的理解和往期文章來介紹一般的 LSTM 與 GRU 結構,因此這兩部分和論文中所描述的有一些不同。
A. 深度 RNN 結合多層感知機
神經網絡的深層架構相比淺層架構可以指數量級高效地表徵函數。雖然由於每個隱藏狀態都是所有過去隱藏狀態的函數,使得循環神經網絡在時間上就是內在的深度網絡,但是人們已證明其內在運算實際上是很淺層的 [44]。在文獻 [44] 中表明,在 RNN 的轉換階段添加一個或多個非線性層可以更好地理解初始輸入的潛在變化,從而提升網絡的整體性能。結合了感知機層的 RNN 的深度結構可以分成三類:輸入到隱藏、隱藏到隱藏,以及隱藏到輸出 [44]。
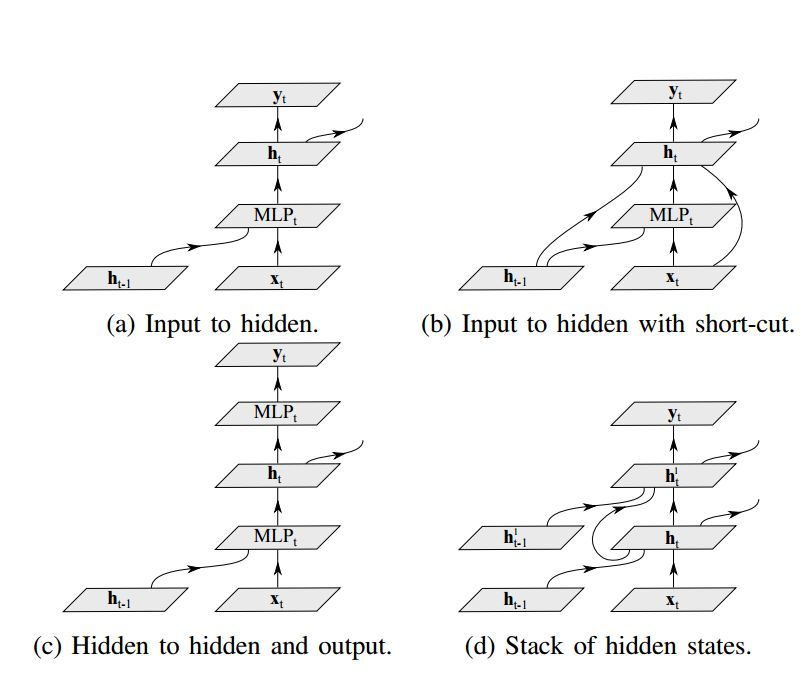
圖 5:幾種結合多層感知機的深度循環神經網絡的架構。
(1)深度輸入到隱藏:其基本思想之一是將多層感知機(MLP)結構引入轉換和輸出階段,分別稱爲深度轉換 RNN 和深度輸出 RNN。
(2)深度隱藏到隱藏和輸出:深度 RNN 重點關注於隱藏層的構造。在隱藏層中,來自過去數據抽象和新輸入的數據抽象與/或隱藏狀態結構都是高度非線性的。
(3)隱藏狀態的堆疊:另一種構造深度 RNN 的方法是如圖 5d 所示的方式堆疊隱藏層。這種類型的循環結構可以使網絡在不同的時間尺度上工作,並允許網絡處理多種時間尺度的輸入序列 [44]。
B. 雙向 RNN(Bidirectional RNN)
傳統的 RNN 在訓練過程中只考慮數據的過去狀態。雖然在很多應用中只考慮過去狀態已經充分有效(例如語音識別),但是探索未來的狀態也是很有用的 [43]。之前,人們嘗試通過對輸出延遲確定時間幀數,以在 RNN 的基礎架構上利用未來狀態作爲當前預測的環境。然而,這種方法需要在所有的實現中手動優化延遲時間。而雙向 RNN(BRNN)利用了過去和未來的所有可用輸入序列評估輸出向量 [46]。其中,需要用一個 RNN 以正向時間方向處理從開始到結束的序列,以及用另一個 RNN 處理以反向時間方向處理從開始到結束的序列,如圖 6 所示。
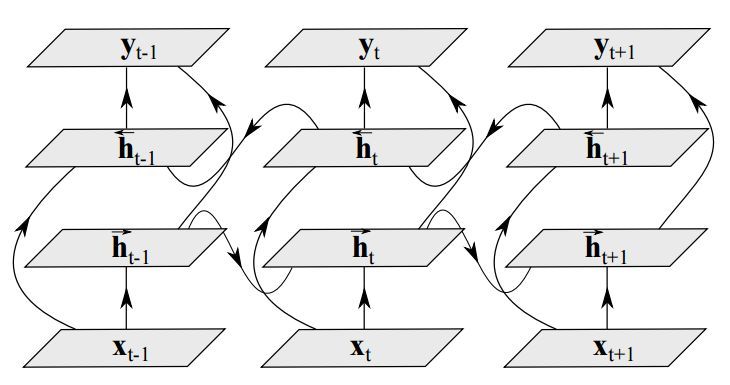
圖 6:雙向 RNN 按時間展開。
C. 循環卷積神經網絡
然而,RNN 中仍然缺乏在多個維度對上下文依賴關係的理解。其中最流行的網絡架構使用了卷積神經網絡(CNN)解決這些問題。
將循環連接整合到每個卷積層中,可以構成循環卷積神經網絡(RCNN)[47]。RCNN 單元的激活值依賴於近鄰的單元而隨時間變化。這種方法可以整合上下文信息,對於目標識別任務很重要。這種方法可以增加模型的深度,而參數數量通過層間的權重共享保持不變。使用從隱藏層中從輸出到輸入的循環連接使網絡可以建模標籤依賴關係,並基於它的過去輸出平滑輸出 [48]。這種 RCNN 方法可以將大量輸入上下文饋送到網絡中去,同時限制模型的容量。這個系統可以用較低的推理成本建模複雜的空間依賴關係。
D. 多維循環神經網絡
多維循環神經網絡(MDRNN)是 RNN 的高維序列學習的另一種實現。這種網絡在每個維度使用循環連接以學習數據內的關係。
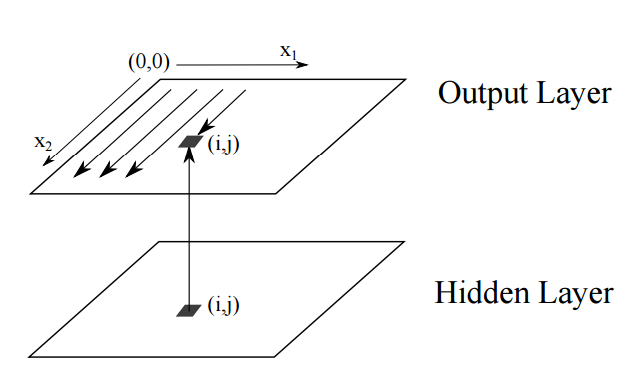
圖 7:二維 RNN 的序列排序的前向傳遞。隱藏層平面的連接是循環的。沿 x_1 和 x_2 的線展示了(從左上角開始)被訪問的過去狀態的掃描帶。
E. 長短期記憶(LSTM)
使用傳統的通過時間的反向傳播(BPTT)或實時循環學習(RTTL/Real Time Recurrent Learning),在時間中反向流動的誤差信號往往會爆炸(explode)或消失(vanish)。但LSTM可以通過遺忘和保留記憶的機制減少這些問題。
LSTM 單元一般會輸出兩種狀態到下一個單元,即單元狀態和隱藏狀態。記憶塊負責記憶各個隱藏狀態或前面時間步的事件,這種記憶方式一般是通過三種門控機制實現,即輸入門、遺忘門和輸出門。
以下是 LSTM 單元的詳細結構,其中 Z 爲輸入部分,Z_i、Z_o 和 Z_f 分別爲控制三個門的值,即它們會通過激活函數 f 對輸入信息進行篩選。一般激活函數可以選擇爲 Sigmoid 函數,因爲它的輸出值爲 0 到 1,即表示這三個門被打開的程度。
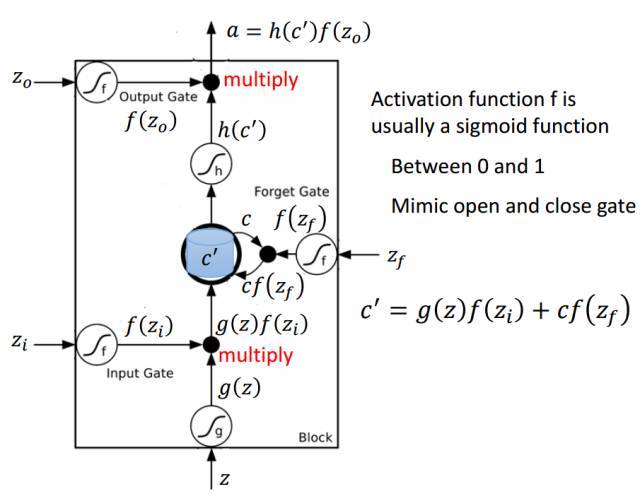
圖片來源於李弘毅機器學習講義。
若我們輸入 Z,那麼該輸入向量通過激活函數得到的 g(Z) 和輸入門 f(Z_i ) 的乘積 g(Z) f(Z_i ) 就表示輸入數據經篩選後所保留的信息。Z_f 控制的遺忘門將控制以前記憶的信息到底需要保留多少,保留的記憶可以用方程 c*f(z_f)表示。以前保留的信息加上當前輸入有意義的信息將會保留至下一個 LSTM 單元,即我們可以用 c' = g(Z)f(Z_i) + cf(z_f) 表示更新的記憶,更新的記憶 c' 也表示前面與當前所保留的全部有用信息。我們再取這一更新記憶的激活值 h(c') 作爲可能的輸出,一般可以選擇 tanh 激活函數。最後剩下的就是由 Z_o 所控制的輸出門,它決定當前記憶所激活的輸出到底哪些是有用的。因此最終 LSTM 的輸出就可以表示爲 a = h(c')f(Z_o)。
F. 門控循環單元(GRU)
GRU 背後的原理與 LSTM 非常相似,即用門控機制控制輸入、記憶等信息而在當前時間步做出預測,表達式由以下給出:
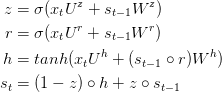
GRU 有兩個有兩個門,即一個重置門(reset gate)和一個更新門(update gate)。從直觀上來說,重置門決定了如何將新的輸入信息與前面的記憶相結合,更新門定義了前面記憶保存到當前時間步的量。如果我們將重置門設置爲 1,更新門設置爲 0,那麼我們將再次獲得標準 RNN 模型。
爲了解決標準 RNN 的梯度消失問題,GRU 使用了更新門(update gate)與重置門(reset gate)。基本上,這兩個門控向量決定了哪些信息最終能作爲門控循環單元的輸出。這兩個門控機制的特殊之處在於,它們能夠保存長期序列中的信息,且不會隨時間而清除或因爲與預測不相關而移除。以下展示了單個門控循環單元的具體結構。
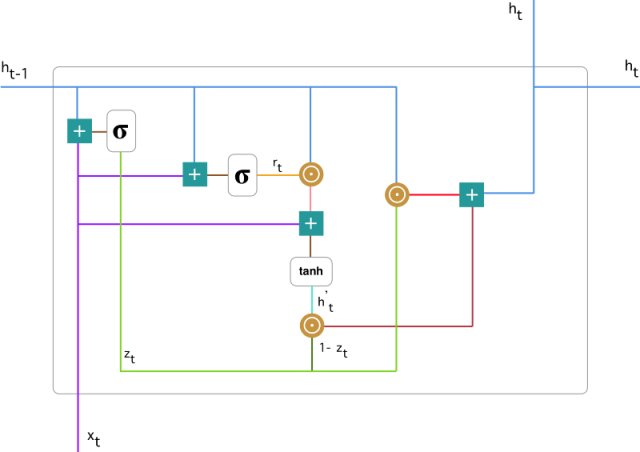
門控循環單元
1. 更新門
在時間步 t,我們首先需要使用以下公式計算更新門 z_t:
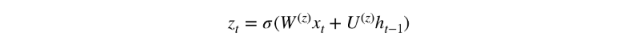
其中 x_t 爲第 t 個時間步的輸入向量,即輸入序列 X 的第 t 個分量,它會經過一個線性變換(與權重矩陣 W(z) 相乘)。h_(t-1) 保存的是前一個時間步 t-1 的信息,它同樣也會經過一個線性變換。更新門將這兩部分信息相加並投入到 Sigmoid 激活函數中,因此將激活結果壓縮到 0 到 1 之間。以下是更新門在整個單元的位置與表示方法。
2. 重置門
本質上來說,重置門主要決定了到底有多少過去的信息需要遺忘,我們可以使用以下表達式計算:
3. 當前記憶內容
現在我們具體討論一下這些門控到底如何影響最終的輸出。在重置門的使用中,新的記憶內容將使用重置門儲存過去相關的信息,它的計算表達式爲:
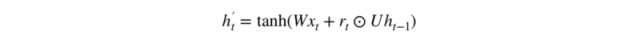
輸入 x_t 與上一時間步信息 h_(t-1) 先經過一個線性變換,即分別右乘矩陣 W 和 U。
計算重置門 r_t 與 Uh_(t-1) 的 Hadamard 乘積,即 r_t 與 Uh_(t-1) 的對應元素乘積。因爲前面計算的重置門是一個由 0 到 1 組成的向量,它會衡量門控開啓的大小。例如某個元素對應的門控值爲 0,那麼它就代表這個元素的信息完全被遺忘掉。該 Hadamard 乘積將確定所要保留與遺忘的以前信息。
4. 當前時間步的最終記憶
在最後一步,網絡需要計算 h_t,該向量將保留當前單元的信息並傳遞到下一個單元中。在這個過程中,我們需要使用更新門,它決定了當前記憶內容 h'_t 和前一時間步 h_(t-1) 中需要收集的信息是什麼。這一過程可以表示爲:
z_t 爲更新門的激活結果,它同樣以門控的形式控制了信息的流入。z_t 與 h_(t-1) 的 Hadamard 乘積表示前一時間步保留到最終記憶的信息,該信息加上當前記憶保留至最終記憶的信息就等於最終門控循環單元輸出的內容。
G. 記憶網絡
卷積 RNN 可用於儲存過去輸入特徵的記憶容量較小 [71] [72]。記憶神經網絡(MemNN)利用成功的學習方法和可讀、可寫的存儲器進行推斷。MemNN 是一個對象數組,包括輸入、響應、泛化和輸出特徵圖 [71] [73]。它將輸入轉換成內部特徵表示,然後根據新的輸入更新記憶。之後使用輸入和更新後的記憶計算輸出特徵,並將其解碼來生成輸出 [71]。使用 BPTT 訓練該網絡並不簡單,每一層都需要監督 [74]。
循環記憶網絡(RMN)利用 LSTM 和 MemNN [75]。RMN 中的記憶模塊採用 LSTM 的隱藏狀態,並使用注意力機制將它和最近的輸入進行對比。RMN 算法分析已訓練模型的注意力權重,並按時間從 LSTM 的保留信息中提取知識 [75]。
H. 結構受限循環神經網絡
另一個解決梯度消失問題的模型是結構受限循環神經網絡(structurally constrained recurrent neural network,SCRN)。這種網絡基於隱藏狀態在訓練過程中快速變化的觀察現象而設計,如圖 12 所示 [6]。在這種方法中,SCRN 結構通過添加等價於單位長期依賴性關係的特定循環矩陣進行擴展。
圖 12:帶有語境特徵(更長記憶)的循環神經網絡
I. 酉循環神經網絡
減緩梯度消失與梯度爆炸的一個簡單方法是使用 RNN 中的酉矩陣(unitary matrices)。梯度消失與梯度爆炸問題歸因於隱藏到隱藏權重矩陣的特徵值之一的偏離。因此,爲了防止這些特徵值偏離,可用酉矩陣取代網絡中的一般矩陣。
J. 門控正交循環單元(Gated Orthogonal Recurrent Unit)
門控正交循環單元使用正交矩陣取代隱藏狀態循環矩陣(loop matrix),並引入了對 ReLU 激活函數的增強,使得它能夠處理複數值輸入 [77]。這種單元能夠使用酉矩陣捕捉數據的長期依賴關係,同時還能利用 GRU 架構中的遺忘機制。
k. 層級子採樣循環神經網絡
層級子採樣循環神經網絡(HSRNN) 旨在通過使用固定的窗口大小進行每個層級的子採樣,從而更好地學習長序列 [78]。訓練這種網絡遵循常規 RNN 訓練的流程,然後根據每個層級的窗口大小進行略微修改。
以上是循環神經網絡的 11 中架構,這一部分其實有詳細的解釋,但我們並沒有深入討論。該論文後面還討論了 RNN 中的正則化技術,包括 L1 和 L2 正則化、Dropout、激活值穩定歸一化和其它正則化方法。我們只是簡要介紹了該論文的基本結構與概念,很多詳細的推導與實現都需要讀者深入閱讀原論文。儘管如此,但本文從 RNN 的基礎到循環架構還是全面概述了近年來 RNN 的研究與進步。
責任編輯: