選自:arXiv
參與:李澤南、蔣思源

深度學習的模型正在變得越來越複雜,所需要的計算資源也越來越多,在開發更加強大的硬件的同時,很多人也在致力於改進算法。最近,百度和英偉達共同提出了一種混合精度訓練的新方法,研究者稱,通過使用半精度浮點數部分代替單精度,令多種深度學習模型在訓練時的內存佔用量減少了接近一半,同時訓練速度也有所提升。
深度學習已經在很多領域裏展現了自己的實力,從圖像識別、語言建模、機器翻譯到語音識別。目前,技術的發展主要遵從兩大方向:使用更大的數據集進行訓練或增加模型的複雜度。例如,Hannun 等人在 2014 年提出的語音識別模型經過了 5000 小時的訓練,而更最近的聲學模型則經過了接近 12,000 小時的訓練(Amodei 等人,2016),Soltau 等人則使用了更大的數據集,訓練了 125,000 小時。與此同時,Hannun 等人在 2014 年使用了 1100 萬個參數,而在 2016 年 Amodei 等人的研究中,雙向 RNN 模型增長到了 6700 萬個參數,最近的門控循環單元(GRU)模型則更是增加到了 1.16 億個參數。
越大的模型通常需要在訓練時消耗更多的計算資源和內存。這些需求可以通過減少精度表示和計算量來縮減。任何程序的表現(速度),包括神經網絡訓練和推斷都受到三種條件的限制:運算帶寬、內存帶寬和延遲。降低精度可以解決其中的兩個問題。通過使用較少位的數值表示,在處理同樣數據時我們需要讀/寫的內容就更短,內存帶寬的壓力就變得更小了。與此同時,計算時間也會因爲數據的簡化而減少。在最近的研究中,半精度(half-precision)方法可以讓 GPU 效能提升 2-8 倍(相對於單精度)。在提升速度以外,低精度的格式也減少了訓練時的內存使用量。
現代深度學習訓練系統通常使用單精度(FP32)格式。在百度和英偉達最近發表的論文中,研究人員試圖在降低精度的同時保證模型的準確性。具體來說,研究人員使用 IEEE 半精度格式(FP16)訓練了多種神經網絡。相對於 FP32 來說,FP16 的動態範圍(dynamic range)更窄。爲了防止準確度降低,研究人員引入了兩種新技術:以 FP32 格式保留原版權重;loss-scaling,將梯度最小化逼近零。使用這些技術,該研究證明了新的方法可以在多種網絡架構和應用中訓練出準確度和 FP32 格式相同的模型。
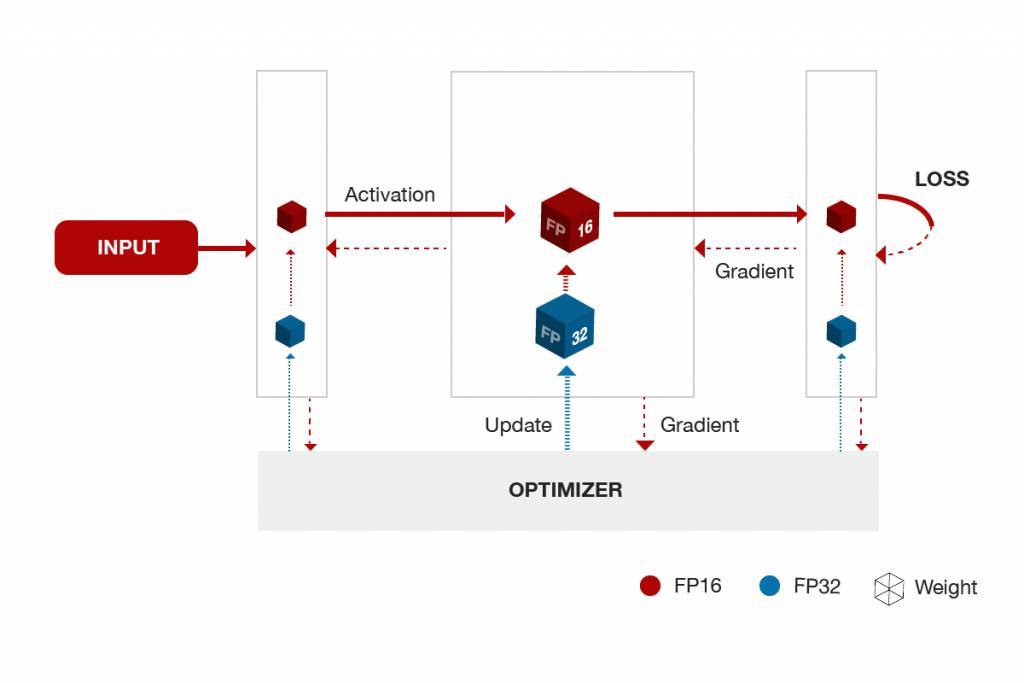
深度學習模型的混合精度訓練
實驗結果包含使用卷積和循環神經網絡架構,並訓練分類、迴歸和生成的任務。應用包含圖像分類、圖像生成、物體檢測、語言模型、機器翻譯和語音識別。此外,使用新的技術無需改變模型和訓練超參數。
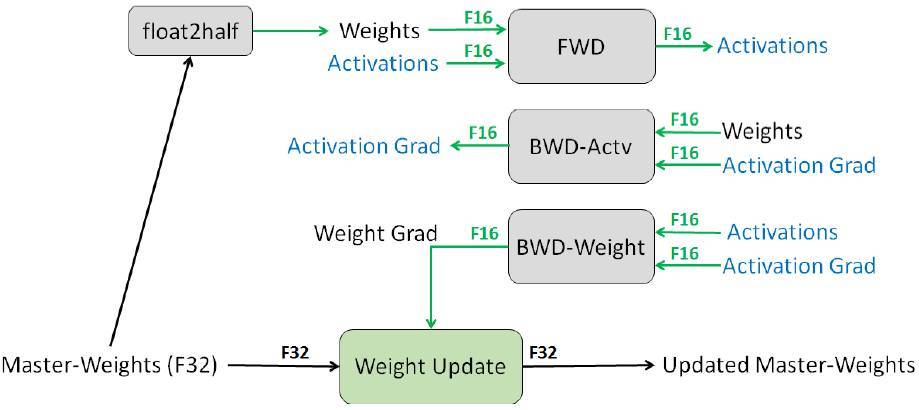
圖 1. 混合精度(Mixed precision)訓練在單層中的迭代。
研究人員在多種深度學習模型上運行了新方法,並與常用方法進行了對比:
基線(FP32):單精度(Single-precision)存儲用於激活、權重和梯度。計算也使用單精度單元。
混合精度(Mixed Precision/MP):FP16 用於存儲和計算。權重、激活和梯度使用 FP16,FP32 原版用於權重更新。5 個 Loss-scaling 用於一些應用。使用 FP16 算法的實驗應用了英偉達新一代芯片中的 Tensor Core,將 FP16 運算累加到 FP32 上,並用於卷積、全連接層和循環層中的矩陣乘法。
基線實驗在英偉達 Maxwell 或 Pascal 架構的 GPU 上運行。混合精度實驗則使用了最新的 Volta V100 來將 FP16 結果累加至 FP32。其中,混合精度語音識別實驗在 FP16 精度上只使用了 Maxwell GPU 以模擬非 Volta 架構上的 Tensor Core 操作。研究人員在這種模式下訓練了多種神經網絡,以確保模型準確度與 Volta V100 GPU 訓練混合精度的結果相同。
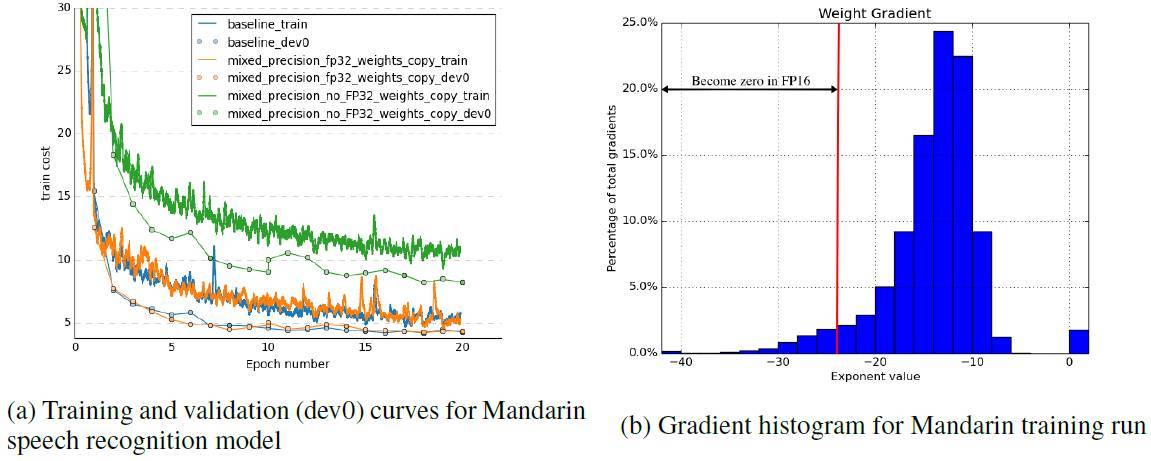
圖 2. 左圖顯示了三個實驗的結果:基線(FP32)、帶 FP32 原版權重的擬 FP16、無 FP32 原版權重的擬 FP16。右圖顯示了 FP32 漢語語音識別訓練權重的直方圖。在模型所有層的訓練期間,每 4000 次迭代採樣一次梯度。
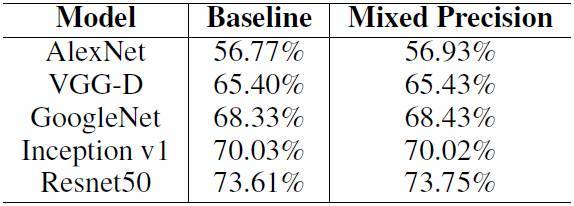
表 1. ILSVRC12 分類任務上,基線與混合精度方法的準確率對比。
研究人員表示,在未來,他們計劃將這一方向擴展至生成模型如文本-語音系統和深度強化學習應用。此外,自動 loss-scaling 係數選擇也可以進一步簡化混合精度訓練方法的複雜度。Loss-scaling 係數可由權重梯度的溢出、跳過更新來進行增減。
論文:Mixed Precision Training

論文鏈接:https://arxiv.org/abs/1710.03740
摘要:深度神經網絡已經在各類應用場景中取得了成功。通常,越大的神經網絡可以獲得越準確的結果。但隨着模型尺寸的增長,用於訓練的內存和計算資源的需求也隨之增加。在本論文中,我們介紹了一種使用半精度浮點數(half precision floating point numbers)訓練深度神經網絡的新技術。在我們的技術中,權重、激活值和梯度都被以 IEEE 半精度格式存儲。與單精度數字相比,半精度浮點數具有較小的數值範圍。
我們提出了兩種新技術來解決信息丟失的問題。首先,我們提出在每個優化器步之後維護累加梯度權重的單精度原版(FP32)。這種單精度原版在訓練中可以轉變爲半精度格式。其次,我們提出適當減小損失以處理半精度梯度信息丟失的方法。我們證明了這種方法適用於多種模型,包括卷積神經網絡、循環神經網絡和生成對抗網絡。這種技術在超過 1 億參數,被大數據集訓練的大規模模型上非常有效。使用這種方式,我們可以在深度學習模型上減少近乎一半的內存消耗。在未來,我們可以期待半精度硬件單元(half-precision hardware units)帶來更多的計算加速效果。
原文鏈接:
http://research.baidu.com/mixed-precision-training/
https://www.nextplatform.com/2017/10/11/baidu-sheds-precision-without-paying-deep-learning-accuracy-cost/
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: